Oracle 官方提供的性能测试工具 JMH(Java Microbenchmark Harness,JAVA 微基准测试套件)来测试我们目标代码, 进行有针对的性能调优
在springboot-simplify-dev项目上进行开发: https://gitee.com/guangyang1314666/springboot-simplify-dev
添加依赖
核心组件中已经引入了jmh-core
<dependency><groupId>org.openjdk.jmh</groupId><artifactId>jmh-core</artifactId><version>1.33</version></dependency>
在任意模块下引入如下依赖:
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-generator-annprocess -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<scope>provided</scope>
</dependency>
编写测试代码
package com.simplifydev.test.rest;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.TimeUnit;
// 测试完成时间
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
// 预热 2 轮,每次 1s
@Warmup(iterations = 2, time = 1, timeUnit = TimeUnit.SECONDS)
// 测试 5 轮,每次 1s
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
// fork 1 个线程
@Fork(1)
// 每个测试线程一个实例
@State(Scope.Thread)
public class HashMapCycleTest {
static Map<Integer, String> map = new HashMap<>();
static {
// 添加数据
for (int i = 0; i < 1000; i++) {
map.put(i, "val:" + i);
}
}
public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
// 要导入的测试类
.include(HashMapCycleTest.class.getSimpleName())
// 输出测试结果的文件
.output("D:\\Git\\mnt\\data_disk_5000\\tmp\\jmh-map.log")
.build();
new Runner(opt).run(); // 执行测试
}
@Benchmark
public void entrySet() {
// 遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
Integer k = entry.getKey();
String v = entry.getValue();
}
}
@Benchmark
public void forEachEntrySet() {
// 遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
Integer k = entry.getKey();
String v = entry.getValue();
}
}
@Benchmark
public void keySet() {
// 遍历
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer k = iterator.next();
String v = map.get(k);
}
}
@Benchmark
public void forEachKeySet() {
// 遍历
for (Integer key : map.keySet()) {
Integer k = key;
String v = map.get(k);
}
}
@Benchmark
public void lambda() {
// 遍历
map.forEach((key, value) -> {
Integer k = key;
String v = value;
});
}
@Benchmark
public void streamApi() {
// 单线程遍历
map.entrySet().stream().forEach((entry) -> {
Integer k = entry.getKey();
String v = entry.getValue();
});
}
public void parallelStreamApi() {
// 多线程遍历
map.entrySet().parallelStream().forEach((entry) -> {
Integer k = entry.getKey();
String v = entry.getValue();
});
}
}
所有被添加了 @Benchmark 注解的方法都会被测试,因为 parallelStream 为多线程版本性能一定是最好的,所以就不参与测试了,其他 6 个方法的测试结果如下: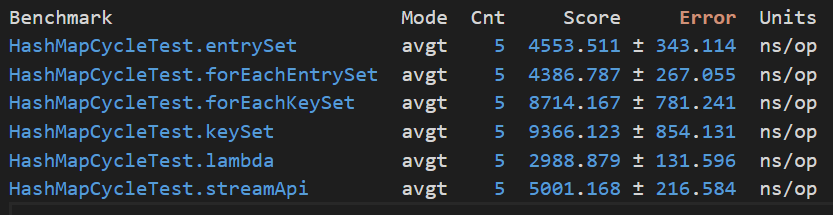
测试结果会被输出到指定的文件中, 并不会打印到控制台上
其中 Units 为 ns/op 意思是执行完成时间(单位为纳秒),而 Score 列为平均执行时间, ± 符号表示误差。从以上结果可以看出,两个 entrySet 的性能相近,并且执行速度最快,接下来是 stream ,然后是两个 keySet,性能最差的是 KeySet 。

若有收获,就点个赞吧
0 人点赞
