设想一个场景:
比如说我们有一个服务集群,有三个 Pod 直接通过 Nginx 的反向代理实现负载均衡,这三个 Pod 都是由 Deployment 管理,如果某一天其中一个 Pod 发生异常挂掉了,我们知道 Deployment 会再启动一个新的 Pod ,以满足 Pod 数量为 3 的期望值。那么问题来了,新创建的 Pod 的 IP 肯定跟之前不一样,也即 Deployment 控制的这三个 Pod 的 IP 地址是会改变的,那么 Nginx 的 upstream 区里的 IP 跟真实环境就不一致了,那 Nginx 就会出现错误。
那是不是需要再写一个监控脚本去监听 Pod 的 IP 地址变化,如果有变化再同步到 Nginx 呢?
如果真要这样的话,管理成本会很大,那 K8s 根本没有我们想象中的那么优秀了
那 K8s 到底有没有机制去解决这种问题呢?
答案肯定是有的,K8s 提供了 Service ,Service 负责去检测它所匹配的 Pod 的状态信息,并把 Pod 的 IP 信息记录到负载队列,在 Nginx 里面只需要配置指向 Service 的地址即可。后续 Pod 的状态信息有变化会自动同步到 Service 里,由 Service 完成负载均衡,Nginx 是不需要做任何修改的。
一旦引入 Service 以后,后端的 Pod 不管是扩容还是更新,都不会对 Nginx 的反向代理(或者上一层服务)造成影响
Service对象的IP地址也称为Cluster IP,它位于为Kubernetes集群配置指定专用的IP地址范围之内,是一种虚拟的IP地址,它在Service对象创建之后保持不变,并且能够被同一集群中的Pod资源所访问。Service端口用于接受客户端请求,并将请求转发至后端的Pod应用的相应端口,这样的代理机制,也称为端口代理,它是基于TCP/IP 协议栈的传输层。
Service的概念
Service 是一个通过 Label Selector(标签选择)匹配一组 Pod 对外访问服务的一种机制,每一个 Service 可以理解成一个微服务。
Service 能够提供负载均衡的能力,但是在使用上有以下限制:
- 只提供 4 层负载均衡能力,没有 7 层功能,也即不能通过主机名或域名的方案做负载均衡。
这里说的是默认 Service 没有 7 层负载能力,后面可以添加一个 Ingress 的方案可以为它增加 7 层负载的能力。
Service 的类型
Service 在 k8s 中有以下四种类型:
- ClusterIP:默认类型,自动分配一个仅 Cluster 内部可以访问的虚拟 IP
- NodePort:在 ClusterIP 的基础为 Service 在每台机器上绑定一个端口,这样就可以通过 : 来访问该服务(在第一篇入门文章中有简单使用过)
- LoadBalancer:在 NodePort 的基础上,借助 Cloud Provider 创建一个外部负载均衡器,并将请求转发到 :
- ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建。(比如外部有一个 MySql 集群,可以创建一个 ExternalName 类型的 Service 去指向这个 MySql 集群,K8s 系统 Pod 直接指向这个 Service 即可,外部集群改变只需要更改 这个 Service,其它 Pod 无须修改)
userspace代理模式
这种模式,当客户端Pod请求内核空间的service iptables后,把请求转到给用户空间监听的kube-proxy 的端口,由kube-proxy来处理后,再由kube-proxy将请求转给内核空间的 service ip,再由service iptalbes根据请求转给各节点中的的service pod。
由此可见这个模式有很大的问题,由客户端请求先进入内核空间的,又进去用户空间访问kube-proxy,由kube-proxy封装完成后再进去内核空间的iptables,再根据iptables的规则分发给各节点的用户空间的pod。这样流量从用户空间进出内核带来的性能损耗是不可接受的。在Kubernetes 1.1版本之前,userspace是默认的代理模型。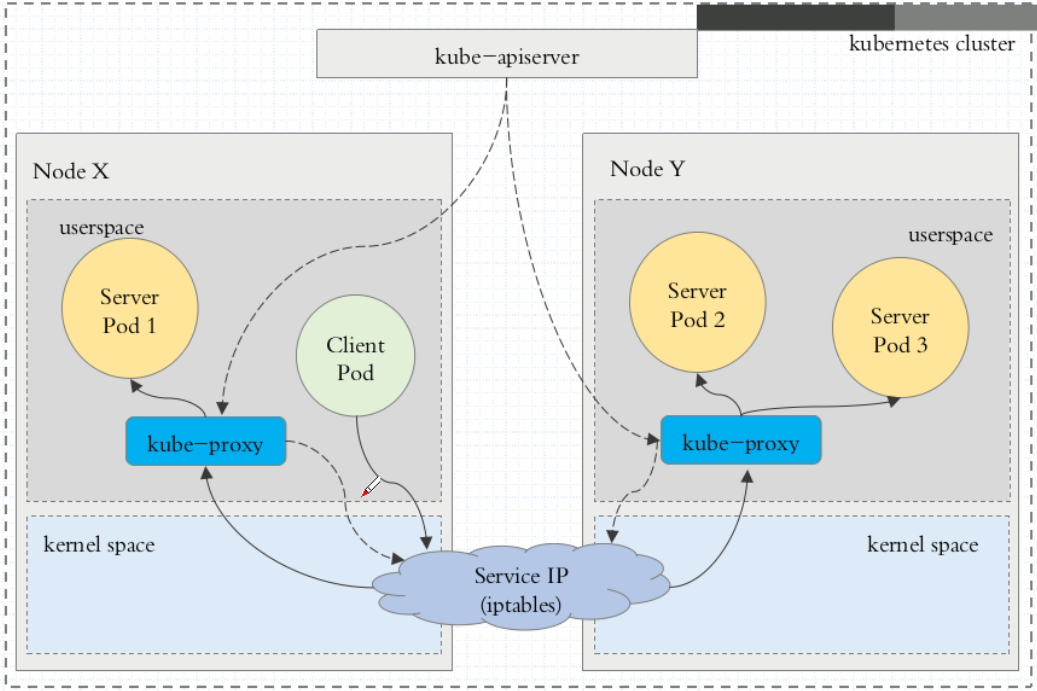
iptables代理模式
客户端IP请求时,直接请求本地内核service ip,根据iptables的规则直接将请求转发到到各pod上,因为使用iptable NAT来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存在上万的Service/Endpoint,那么Node上的iptables rules将会非常庞大,性能还会再打折扣。iptables代理模式由Kubernetes 1.1版本引入,自1.2版本开始成为默认类型。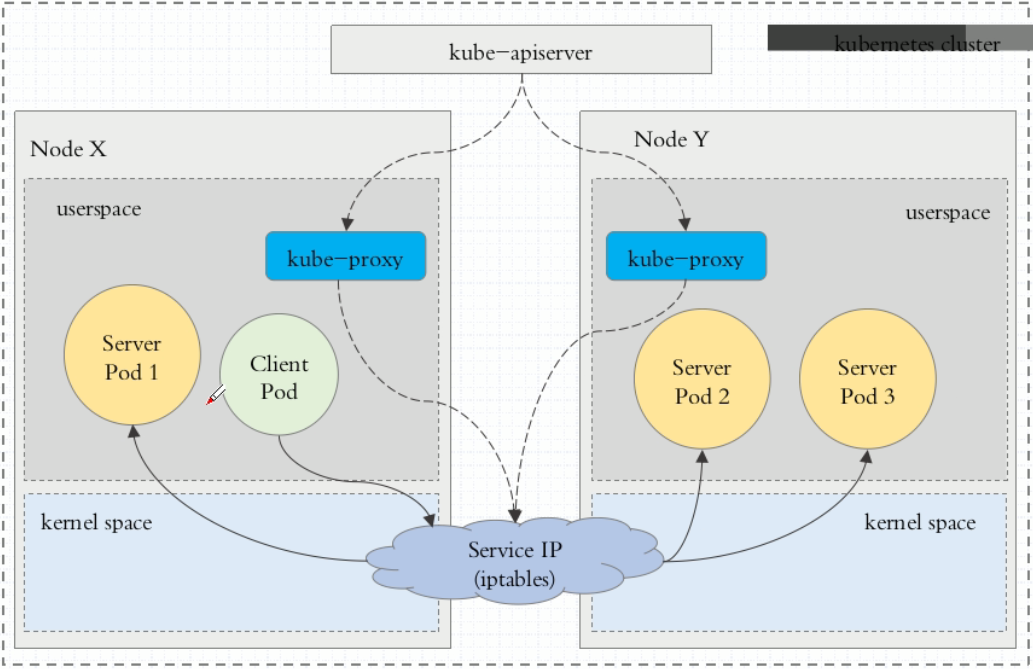
ipvs代理模式
Kubernetes自1.9-alpha版本引入了ipvs代理模式,自1.11版本开始成为默认设置。客户端IP请求时到达内核空间时,根据ipvs的规则直接分发到各pod上。kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs基于netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
- rr:
轮询调度 - lc:最小连接数
dh:目标哈希sh:源哈希sed:最短期望延迟nq:不排队调度
注意: ipvs模式假定在运行kube-proxy之前在节点上都已经安装了IPVS内核模块。当kube-proxy以ipvs代理模式启动时,kube-proxy将验证节点上是否安装了IPVS模块,如果未安装,则kube-proxy将回退到iptables代理模式。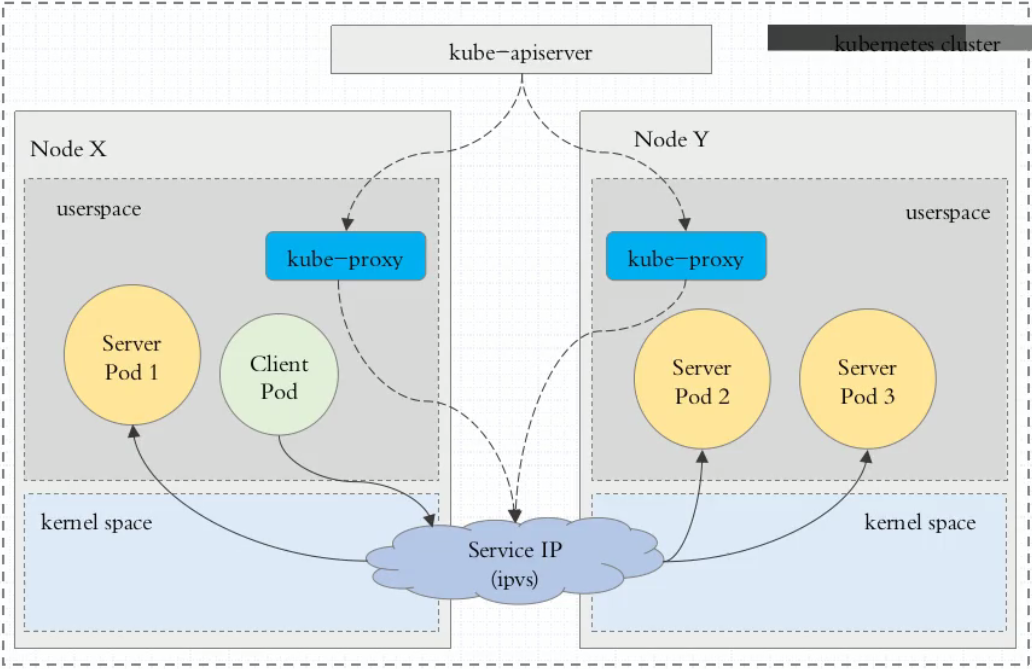
如果某个服务后端pod发生变化,标签选择器适应的pod有多一个,适应的信息会立即反映到apiserver上,而kube-proxy一定可以watch到etc中的信息变化,而将它立即转为ipvs或者iptables中的规则,这一切都是动态和实时的,删除一个pod也是同样的原理。如图: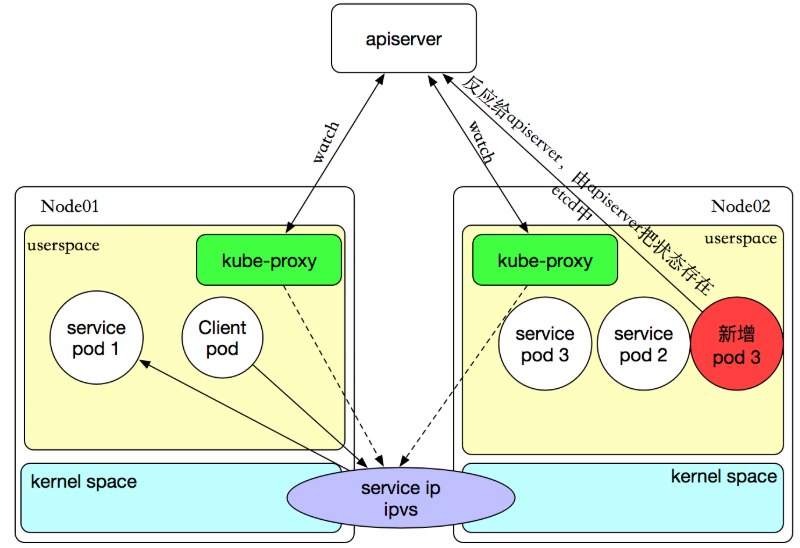
VIP 和 Service 代理
在 K8s 集群中,每个 Node 运行一个 kube-proxy 进程,kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP )的形式,而不是 ExternalName 的形式。在 Kubernetes v1.0 版本代理使用 userspace ,在 v1.1 版本新增了 iptables 代理,但不是默认的运行模式,从 v1.2 开始默认使用 iptables 代理,在 v1.8.0 中添加了 ipvs 代理。在 v1.14 版本开始默认使用 ipvs 代理。
在 v1.0 版本,Service 是 “ 4 层 “(TCP/UDP over IP)概念,在 v1.1 版本,新增了 Ingress API ,用来表示 “ 7 层 “(HTTP)服务。
思考:为什么不使用 round-robin DNS 作负载均衡呢? 最大的一个原因就是 DNS 域名解析后会在客户端缓存。
:::warning
需要注意的是 ipvs 模式假定在运行 kube-proxy 之前在节点上都已安装了 IPVS 内核模块。当 kube-proxy 以 ipvs 代理模式启动时,kube-proxy 将验证节点上是否安装了 IPVS 模块,如果未安装,则 kube-proxy 将回退到 iptables 代理模式。
:::
kube-proxy 这个组件始终监视着apiserver中有关service的变动信息,获取任何一个与service资源相关的变动状态,通过watch监视,一旦有service资源相关的变动和创建,kube-proxy都要转换为当前节点上的能够实现资源调度规则(例如:iptables、ipvs)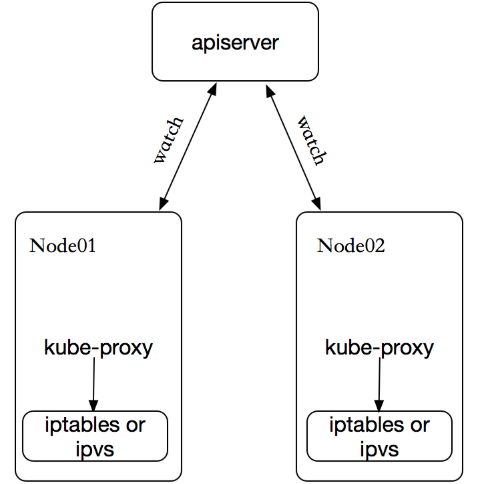
ClusterIP
ClusterIP 主要在每个 node 节点使用 iptables (或 ipvs) ,将发向 ClusterIP 对应端口的数据转发到 kube-proxy 中,然后 kube-proxy 自己内部实现负载均衡,并可以查询到这个 Service 下对应 Pod 的地址和端口,进而把数据转发给对应的 Pod 地址和端口。
还是以 Nginx 反向代理三个 Pod 为例,为了实现此功能,主要需要以下三个组件的协同工作:
- api-server:用户通过 kubectl 命令向 api-server 发送创建 server 命令,api-server 接收到请求后将数据存储到 etcd 中
- Kube-proxy:Kubernetes 每个节点中都有一个叫做 kube-proxy 的进程,这个进程负责感知 service 、pod 的变化,并将变化的信息写入本地的 iptables 规则中
- iptables:使用 NAT 等技术将 virtual ip 的流量转至 endpoint 中
下面演示一下:
svc-deployment.yaml
apiVersion: apps/v1kind: Deploymentmetadata:name: myapp-deploynamespace: defaultspec:replicas: 3selector:matchLabels:app: myapprelease: stabeltemplate:metadata:labels:app: myapprelease: stabelenv: testspec:containers:- name: myappimage: heqingbao/k8s_myapp:v2imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80
上面 Deployment 部署了 3 个 Pod 副本
下面部署它:
[root@master01 ~]# kubectl apply -f svc-deployment.yaml
[root@master01 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy-dfdb77dfd-l8mt8 1/1 Running 0 2m48s 172.16.196.180 node01 <none> <none>
myapp-deploy-dfdb77dfd-lhdqs 1/1 Running 0 2m48s 172.16.140.117 node02 <none> <none>
myapp-deploy-dfdb77dfd-x9vsq 1/1 Running 0 2m48s 172.16.196.181 node01 <none> <none>
# 通过Pod IP访问Pod
[root@master01 ~]# curl 172.16.196.180
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
如上,我们可以直接使用 Pod 的 IP 来访问每个 Pod 。
下面来创建 Service
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: ClusterIP
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80
注意里面的 selector 选择器,就是匹配前面创建的 3 个 Pod 。另外 targetPort 表示后端真实服务的端口,即上面 Pod 定义的端口。
部署 Service :
[root@master01 ~]# kubectl apply -f svc.yaml
service/myapp created
[root@master01 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13d
myapp ClusterIP 10.100.8.189 <none> 80/TCP 5s
[root@master01 ~]# curl 10.100.8.189
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
# 查看Pod信息
[root@master01 ~]# curl 10.100.8.189/hostname.html
myapp-deploy-dfdb77dfd-l8mt8
[root@master01 ~]# curl 10.100.8.189/hostname.html
myapp-deploy-dfdb77dfd-x9vsq
[root@master01 ~]# curl 10.100.8.189/hostname.html
myapp-deploy-dfdb77dfd-lhdqs
Headless Service
有时不需要或不想要负载均衡,以及单独的 Service IP,遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)的值为 None 来创建 Headless Service 。这类 Service 并不会分配 Cluster IP,kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡。
Headless Service 也是后面讲 StatefulSet 的基础。
演示一下
svc-none.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp-headless
namespace: default
spec:
selector:
app: myapp
clusterIP: "None"
ports:
- port: 80
targetPort: 80
指定了 clusterIP: "None"
[root@master01 ~]# kubectl apply -f svc-none.yaml
service/myapp-headless created
[root@master01 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13d
myapp ClusterIP 10.96.16.55 <none> 80/TCP 96s
myapp-headless ClusterIP None <none> 80/TCP 4s
可以看到 myapp-headless 的 IP 地址是 None 。那要怎样访问这个服务呢?
对于 Service 一旦创建成功会写入到 CoreDNS 中去:
[root@master01 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6b9d4c8765-t2rw8 1/1 Running 11 13d
calico-node-4f5sr 1/1 Running 11 13d
calico-node-pzcv7 1/1 Running 4 9d
calico-node-wm6ch 1/1 Running 6 9d
coredns-6955765f44-jr5mk 1/1 Running 11 13d
coredns-6955765f44-tw67g 1/1 Running 11 13d
etcd-master01 1/1 Running 11 13d
kube-apiserver-master01 1/1 Running 12 13d
kube-controller-manager-master01 1/1 Running 11 13d
kube-proxy-9k8tk 1/1 Running 11 13d
kube-proxy-lh9bm 1/1 Running 5 9d
kube-proxy-lmwfv 1/1 Running 4 9d
kube-scheduler-master01 1/1 Running 11 13d
即上面的:coredns-6955765f44-jr5mk 和 coredns-6955765f44-tw67g
通过 kubectl get pod -o wide -n kube-system 找到这两个 Pod 的 IP 地址,比如我这里是 :
- coredns-6955765f44-jr5mk : 172.16.241.98
- coredns-6955765f44-tw67g : 172.16.241.99
如果dig命令没有,通过如下命令进行安装
yum -y install bind-utils
我们使用第一个 dns 来解析下 myapp-headless:
[root@master01 ~]# dig -t A myapp-headless.default.svc.cluster.local. @172.16.241.98
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-9.P2.el7 <<>> -t A myapp-headless.default.svc.cluster.local. @172.16.241.98
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19378
;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;myapp-headless.default.svc.cluster.local. IN A
;; ANSWER SECTION:
myapp-headless.default.svc.cluster.local. 30 IN A 172.16.196.182
myapp-headless.default.svc.cluster.local. 30 IN A 172.16.140.119
myapp-headless.default.svc.cluster.local. 30 IN A 172.16.140.118
;; Query time: 125 msec
;; SERVER: 172.16.241.98#53(172.16.241.98)
;; WHEN: 六 3月 07 17:01:41 CST 2020
;; MSG SIZE rcvd: 237
可以看到指向了 172.16.196.182、172.16.140.119、172.16.140.118 这三个 IP 地址,而这三个地址就是上面创建的三个 Pod 的 IP:
[root@master01 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy-dfdb77dfd-5tq9p 1/1 Running 0 17m 172.16.140.118 node02 <none> <none>
myapp-deploy-dfdb77dfd-cp2r4 1/1 Running 0 17m 172.16.140.119 node02 <none> <none>
myapp-deploy-dfdb77dfd-dpcjn 1/1 Running 0 17m 172.16.196.182 node01 <none> <none>
也就是说在 Headless Service 中,它虽然没有自己的 IP ,但是它可以使用访问域名的方式仍然可以访问到这几个 Pod
NodePort
NodePort 的原理在于在 node 上开了一个端口,将向该端口的流量导入到 kube-proxy ,然后由 kube-proxy 进一步给到对应的 Pod 。
演示一下
nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: NodePort
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80
不解释了,唯一需要注意的就是 type: NodePort
下面来部署这个 Service :
[root@master01 ~]# kubectl apply -f nodeport.yaml
service/myapp configured
[root@master01 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-deploy-dfdb77dfd-5tq9p 1/1 Running 0 22m
myapp-deploy-dfdb77dfd-cp2r4 1/1 Running 0 22m
myapp-deploy-dfdb77dfd-dpcjn 1/1 Running 0 22m
[root@master01 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13d
myapp NodePort 10.96.16.55 <none> 80:30459/TCP 21m
myapp-headless ClusterIP None <none> 80/TCP 20m
注意一组 Pod 是可以对应到多个 Service 的,只要 Service 的 label 标签跟 Pod 的标签一致就可以关联。
可以在外部浏览器上访问:http://192.168.0.114:30459 ,应该是可以访问的。并且在每个 node 上都开启了 30459 端口。
LoadBalancer
LoadBalancer 和 NodePort 其实是同一种方式,区别在于 LoadBalancer 比 NodePort 多了一步,就是可以调用 Cloud Provider 去创建 LB来向节点导流。
ExternalName
这种类型的 Service 通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如:xxx.com)。ExternalName 是 Service 的特例,它没有 selector ,也没有定义任何的端口和 Endpoint ,相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
演示一下
externalname.yaml
apiVersion: v1
kind: Service
metadata:
name: my-service-1
namespace: default
spec:
type: ExternalName
externalName: baidu.com
当查询主机 my-service-1.default.svc.cluster.local (SVC_NAME.NAMESPACE.svc.cluster.local)时,集群的 DNS 服务将返回一个值 baidu.com 的 CNAME 记录,访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。
验证下:
[root@master01 ~]# kubectl apply -f externalname.yaml
service/my-service-1 created
[root@master01 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13d
my-service-1 ExternalName <none> baidu.com <none> 5s
解析一下这个 Service:
[root@master01 ~]# dig -t A my-service-1.default.svc.cluster.local. @172.16.241.98
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-9.P2.el7 <<>> -t A my-service-1.default.svc.cluster.local. @172.16.241.98
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 48206
;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;my-service-1.default.svc.cluster.local. IN A
;; ANSWER SECTION:
my-service-1.default.svc.cluster.local. 30 IN CNAME baidu.com.
baidu.com. 30 IN A 220.181.38.148
baidu.com. 30 IN A 39.156.69.79
;; Query time: 49 msec
;; SERVER: 172.16.241.98#53(172.16.241.98)
;; WHEN: 六 3月 07 17:30:26 CST 2020
;; MSG SIZE rcvd: 178
可以看到有个 CNAME 配置:my-service-1.default.svc.cluster.local. 30 IN CNAME baidu.com.
我们可以进入任意一个 Pod ping 一下这个域名:
[root@node01 ~]# kubectl exec -it myapp-deploy-dfdb77dfd-646s7 sh
/ # ping my-service-1.default.svc.cluster.local
PING my-service-1.default.svc.cluster.local (39.156.69.79): 56 data bytes
64 bytes from 39.156.69.79: seq=0 ttl=47 time=44.341 ms
64 bytes from 39.156.69.79: seq=1 ttl=47 time=54.839 ms
可以看到已经解析到了 39.156.69.79 ,而这正是 baidu.com 的IP。

若有收获,就点个赞吧
0 人点赞
