概述
为什么会出现这个技术?需要解决哪些问题?
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前段
请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败
是什么
Spring Cloud Sleuth提供了一套完整的服务跟踪的解决方案
在分布式系统中提供追踪解决方案并且兼容支持了zipkin
解决

Sleuth之 zipkin搭建安装
下载
SpringCloud从F版起已不需要自己构建Zipkin server了,只需要调用jar包即可
我下载的是zipkin-server-2.12.9-exec.jar
运行jar
运行控制台
http://localhost:9411/zipkin/
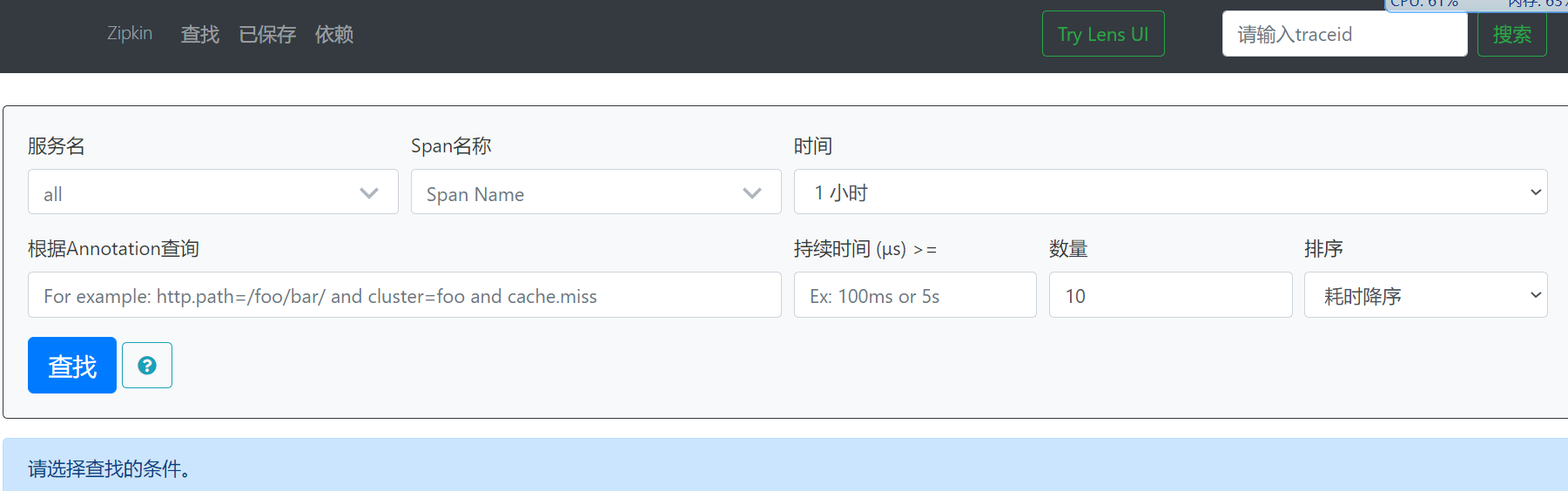
术语
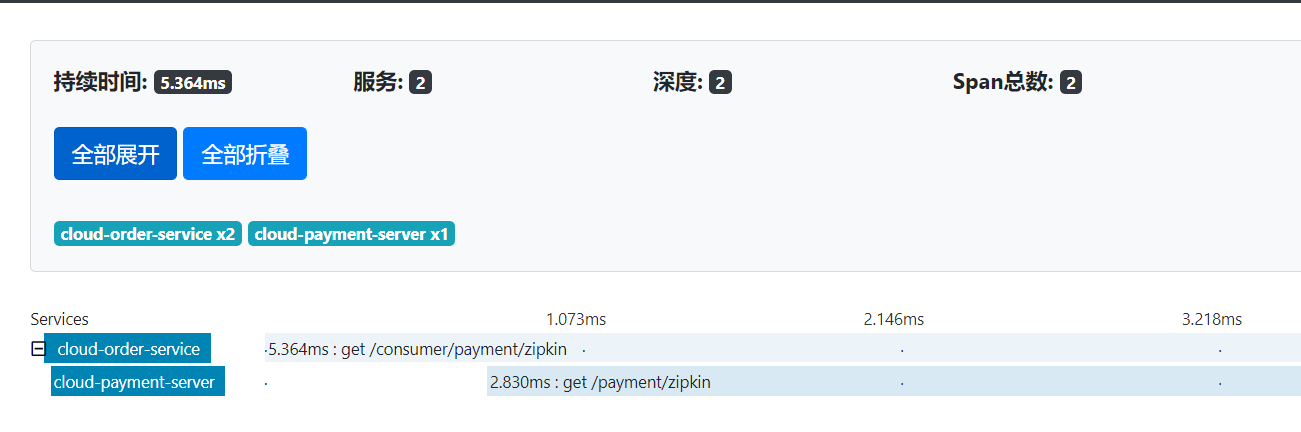
完整的调用链路
表示一请求链路,一条链路通过 Trace ld唯一标识,Span标识发起的请求信息,各span通过 parent id关联起来
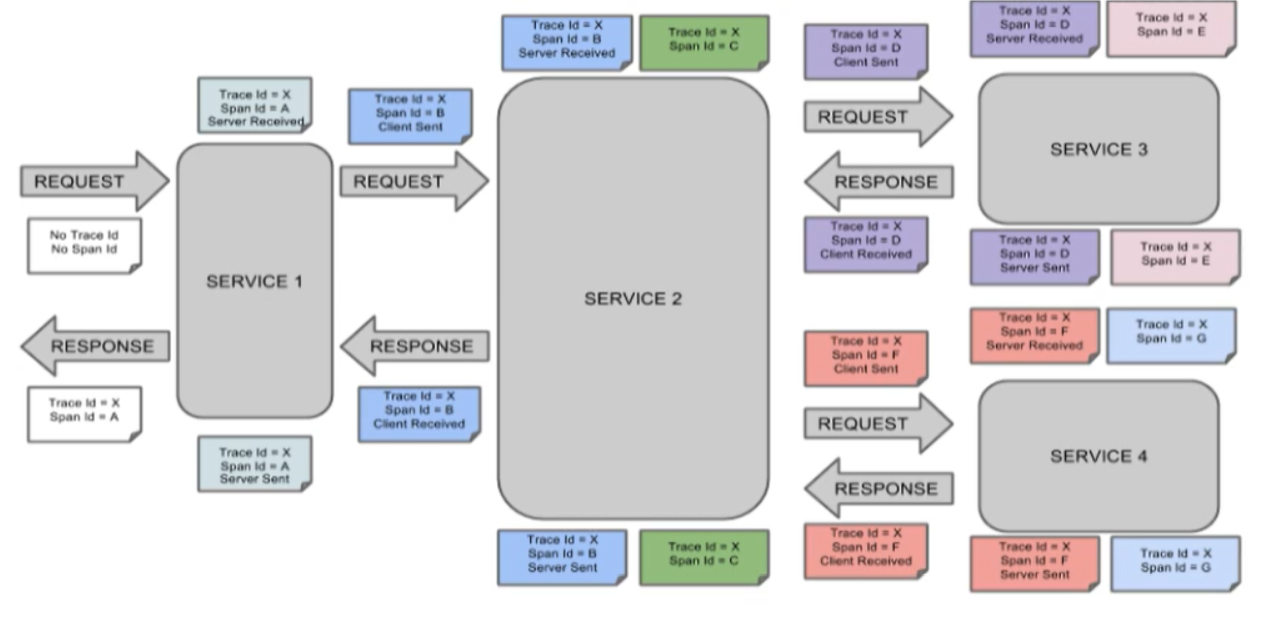
上图what
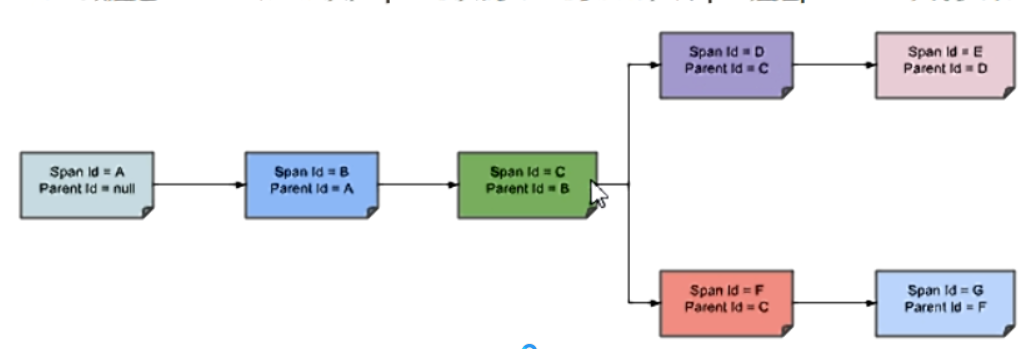
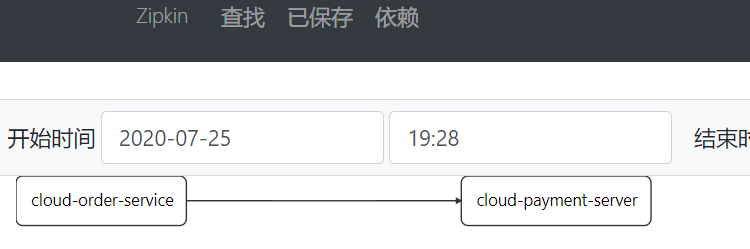
整个链路的依赖关系如下:

名词解释
Trace:类似于树结构的Span集合,表示一条调用链路,存在唯一标识
span:表示调用链路来源,通俗的理解span就是一次请求信息
服务提供者
cloud-provider-payment8091
pom
<!--包含了sleuth+zipkin--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId></dependency>
yml
server:
port: 8091
spring:
application:
name: cloud-payment-server
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1
datasource:
username: blog
password: 123456
url: jdbc:mysql://192.168.200.10:3306/cloud?useUnicode=true&characterEncoding=utf8&characterSetResults=utf8&serverTimezone=GMT%2B8
driver-class-name: com.mysql.cj.jdbc.Driver
# 使用我们自己的druid数据源
type: com.alibaba.druid.pool.DruidDataSource
initialSize: 10 #初始化连接个数
minIdle: 5 #最小连接个数
maxActive: 500 #最大连接个数
maxWait: 60000 #最大等待时间
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
#defaultZone: http://eureka7002.com:7002/eureka,http://eureka7001.com:7001/eureka/ #集群版
defaultZone: http://eureka7001.com:7001/eureka/
instance:
instance-id: payment8091
prefer-ip-address: true #访问路径可以显示ip地址
mybatis:
# config-location和configuration不能同时配置,否则会抛出异常
# 一般只配置configuration即可,会自动找到mybatis全局配置文件
# config-location: classpath:mybatis/mybatis-config.xml
mapper-locations: classpath:mapper/*Mapper.xml
# 对应实体类的路径,只能指定具体的包,多个配置可以使用英文逗号隔开
type-aliases-package: com.sgy.payment
configuration:
# Mybatis SQL语句控制台打印
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 开启驼峰命名规则
# 在数据库中字段可以采用驼峰命名规则,mybatis会把 下划线去掉并把下划线后面的首字母认为是大写
map-underscore-to-camel-case: true
logging:
level:
# 注意注意注意 一定要修改成自己的包名
com.sgy: debug
file:
path: log/
name: log/com.sgy.payment-dev.log
clean-history-on-start: true
pattern:
console: "%d{yyyy-MM-dd} [%thread] %-5level %logger{50} ===> %msg%n"
file: "%d{yyyy-MM-dd} === [%thread] === %-5level === %logger{50} ===> %msg%n"
业务类
@Slf4j
@RestController
public class PaymentController {
@GetMapping("/payment/zipkin")
public String paymentZipkin() {
return "你好,我是链路跟踪测试";
}
}
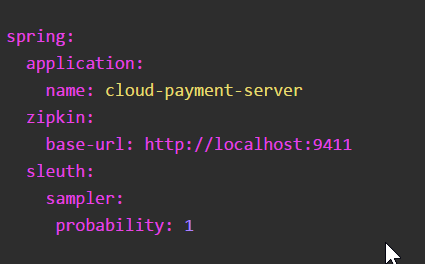
服务消费者(调用方)
pom跟服务提供者一样
yml
server:
port: 80
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://localhost:7001/eureka
#defaultZone: http://eureka7001.com:7001/eureka/
spring:
application:
name: cloud-order-service
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1
业务类
@Slf4j
@RestController
public class OrderController {
private final static String PATMEMT_URL = "http://CLOUD-PAYMENT-SERVER";
@Resource
RestTemplate restTemplate;
@GetMapping("/consumer/payment/zipkin")
public String paymentZipkin() {
log.info("分页查询");
return restTemplate.getForObject(PATMEMT_URL + "/payment/zipkin",String.class);
}
}
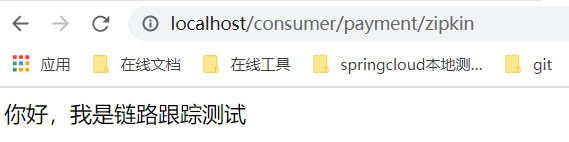
开始测试
依次启动eureka7001/8091/80
然后多次访问80
http://localhost/consumer/payment/zipkin
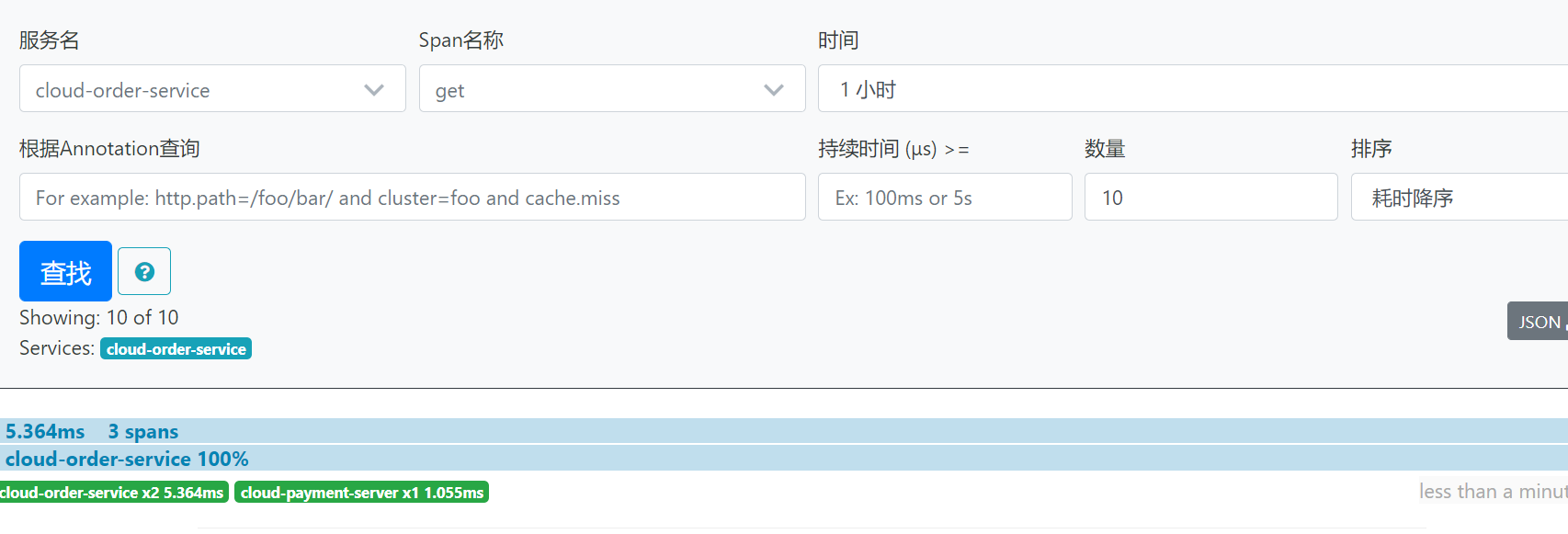
打开zipkin控制台
http:localhost:9411

若有收获,就点个赞吧
0 人点赞
