
一、数据库简介:
1.数据库就是存储数据的仓库,其本质是一个文件系统,数据按照特定的格式将数据存储起来,用户可以对数据库中的数据进行增加,修改,删除及查询操作。
2.数据库管理系统(DataBase Management System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中表内的数据
二、SQL语句:
2.1 SQL分类:
1.数据定义语言:简称DDL(Data Definition Language),用来定义数据库对象:数据库,表,列等。关键字:create,alter,drop等
2.数据操作语言:简称DML(Data Manipulation Language),用来对数据库中表的记录进行更新。关键字:insert,delete,update等
3.数据控制语言:简称DCL(Data Control Language),用来定义数据库的访问权限和安全级别,及创建用户。
4.数据查询语言:简称DQL(Data Query Language),用来查询数据库中表的记录。关键字:select,from,where等
2.2 数据库的数据类型:
| 分类 | 类型名称 | 说明 |
|---|---|---|
| 整数类型 | tinyInt | 很小的整数,1字节 |
| smallint | 小的整数,2字节 | |
| mediumint | 中等大小的整数,3字节 | |
| int(integer) | 普通大小的整数,4字节 | |
| bigint | 大整数,8字节 | |
| 小数类型 | float | 单精度浮点数,4字节 |
| double | 双精度浮点数,8字节 | |
| decimal(m,d) | 压缩严格的定点数, m表示数字总位数,d表示保留到小数点后d位,不足部分就添0,如果不设置m、d,默认保存精度是整型 | |
| 日期类型 | year | 年份 YYYY 1901~2155,1字节 |
| time | 时间 HH:MM:SS -838:59:59~838:59:59,3字节 | |
| date | 日期 YYYY-MM-DD 1000-01-01~9999-12-3,3字节 | |
| datetime | 日期时间 YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00~ 9999-12-31 23:59:59,8字节 | |
| timestamp | 时间戳 YYYY-MM-DD HH:MM:SS 1970~01~01 00:00:01 UTC~2038-01-19 03:14:07UTC,4字节 | |
| 文本、二进制类型 | CHAR(M) | M为0~255之间的整数,固定长度为M,不足后面补全空格 |
| VARCHAR(M) | M为0~65535之间的整数 | |
| BLOB | 允许长度0~65535字节 | |
| TINYTEXT | 允许长度0~255字节(0 ~ 2^8 - 1) | |
| TEXT | 允许长度0~65535字节(0 ~ 2^16 - 1) | |
| LONGTEXT | 允许长度0~4294967295字节(2^32 - 1) |
三、数据库操作:
3.1 创建数据库语法:
1.#创建数据库 数据库中数据的编码采用的是安装数据库时指定的默认编码 utf8
CREATE DATABASE day21_1;
2.#创建数据库 并指定数据库中数据的编码
CREATE DATABASE day21_2 CHARACTER SET utf8;
3.#修改数据库编码
ALTER DATABASE day21_2 CHARACTER SET=utf8;
4.查询所有数据库
show databases
5.删除数据库(慎用)
drop database day21_2;
6.进入指定数据库
use day21_1;
7.查看正在使用的数据库
select database();
3.2 表结构语法:
3.2.1 创建表结构
格式:
create table 表名(
字段名 类型(长度) 约束,
字段名 类型(长度) 约束
);
CREATE TABLE sort (sid INT, #分类IDsname VARCHAR(100) #分类名称);
3.2.2 查看数据库中所有表
查询数据库中的所有表
show tables;
3.2.3 查看指定表的结构
方法一: desc 表名;
方法二: SHOW COLUMNS FROM 表名;
DESC student;SHOW COLUMNS FROM student;

3.2.4 删除表
格式:drop table 表名;
DROP TABLE student;
3.4.4 修改表结构格式(添加列)
语法:alter table 表名 add 列名 类型(长度) 约束;
如下给表添加一个列字段:
ALTER TABLE sort ADD sdesc VARCHAR(20);
如下是一条语句添加多条列字段:
/*添加多个列方法一*/ALTER TABLE studentADD address VARCHAR(200) NOT NULL,ADD home_tel CHAR(11) NOT NULL;/*add语句之间用逗号分隔,最后用分号结束*//*添加多个列方法二*/ALTER TABLE studentADD (address VARCHAR(200) NOT NULL,home_tel CHAR(11) NOT NULL);
ps:如果添加多列的情况下 只要是一个添加出现错误,则所有的添加都无效
语法:alter table 表名 add 列名 类型(长度) 约束 after 某个字段;(表示在哪个字段后面添加列)
语法:alter table 表名 modify 列名 类型(长度) 约束;(表示给列添加约束,modify)
3.4.5 修改表的列信息
语法:alter table 表名 change 旧列名 新列名 类型(长度) 约束;
ALTER TABLE sort CHANGE sname snamename VARCHAR(30);
3.4.6 删除表中的字段
语法:alter table 表名 drop 列名;
/*删除一列*/ALTER TABLE sort DROP snamename;/*删除多列*/ALTER TABLE studentDROP home_address,DROP home_tel;
3.4.7 修改表名
语法:rename table 表名 to 新表名;
RENAME TABLE sort TO category;
3.4.8 修改表的字符集
语法:alter table 表名 character set 字符集;
ALTER TABLE student CHARACTER SET utf8;
3.4.9 DOS操作数据乱码解决
我们在dos命令行操作中文时,会报错
insert into user(username,password) values(‘张三’,’123’);
ERROR 1366 (HY000): Incorrect string value: ‘\xD5\xC5\xC8\xFD’ for column ‘username’ at row 1
原因:因为mysql的客户端编码的问题我们的是utf8,而系统的cmd窗口编码是gbk
如果想要永久修改,通过以下方式:
1.在mysql安装目录下有my.ini文件
default-character-set=gbk 客户端编码设置
character-set-server=utf8 服务器端编码设置
2.注意:修改完成配置文件,重启服务
3.3 表的约束:
3.3.1 主键约束
创建约束的目的就是保证数据的完整性和一致性。
主键对应的字段中的数据必须唯一,且不能为NULL, 一旦重复,数据操作失败(增和改)
3.3.1.1 给表中的字段添加主键约束
语法:Alter table 表名 add primary key(字段列表) auto_increment;
Alter table student add primary key(sid);
3.3.1.2 删除表中的主键
语法:Alter table 表名 drop primary key;
Alter table student drop primary key;
3.3.2 唯一键约束
1.一张表往往有很多字段需要具有唯一性,数据不能重复: 但是一张表中只能有一个主键: 唯一键(unique key)就可以解决表中有多个字段需要唯一性约束的问题.
2.唯一键的本质与主键差不多: 唯一键默认的允许自动为空,而且可以多个为空(空字段不参与唯一性比较)
3.3.3 外键约束
3.3.3.1 添加外键
语法:Alter table 表名 add [constraint 外键名字] foreign key(外键字段) references 父表(主键字段);
3.3.3.2 删除外键约束
语法:Alter table 表名 drop foreign key 外键名; — 一张表中可以有多个外键,但是名字不能相同
3.3.3.3 外键的作用:
1.对子表约束: 子表数据进行写操作(增和改)的时候, 如果对应的外键字段在父表找不到对应的匹配: 那么操作会失败.(约束子表数据操作)
2.对父表约束: 父表数据进行写操作(删和改: 都必须涉及到主键本身), 如果对应的主键在子表中已经被数据所引用, 那么就不允许操作
3.3.3.4 创建外键所需的条件:
1.外键要存在: 首先必须保证表的存储引擎是innodb(默认的存储引擎): 如果不是innodb存储引擎,那么外键可以创建成功,但是没有约束效果.
2.外键字段的字段类型(列类型)必须与父表的主键类型完全一致.
3.一张表中的外键名字不能重复.
4,增加外键的字段(数据已经存在),必须保证数据与父表主键要求对应.
3.4 索引:
索引: 系统根据某种算法, 将已有的数据(未来可能新增的数据),单独建立一个文件: 文件能够实现快速的匹配数据, 并且能够快速的找到对应表中的记录.
3.4.1 在创建表的时候添加索引:
语法:CREATE TABLE 表名称(
……,
INDEX [索引名称] (字段),
……
);
CREATE TABLE t_message(id INT UNSIGNED PRIMARY KEY,content VARCHAR(200) NOT NULL,type ENUM("公告", "通报", "个人通知") NOT NULL,create_time TIMESTAMP NOT NULL,INDEX idx_type (type));
3.4.2 在建表后创建索引:
3.4.2.1 创建普通索引:
语法一:CREATE INDEX 索引名称 ON 表名(字段);
语法二:ALTER TABLE 表名 ADD INDEX 索引名称(字段);
3.4.2.2 创建唯一索引
语法:CREATE UNIQUE INDEX 索引名 ON 表名(字段)
3.4.2.3 创建联合索引
语法:CREATE INDEX 索引名称 ON 表名(字段1,字段2,字段3)
-- 普通索引:CREATE INDEX idx_type ON t_message(type); /*添加索引方式1*/ALTER TABLE t_message ADD INDEX idx_type(type);/*添加索引方式2*/-- 唯一索引:CREATE UNIQUE INDEX uidx_type ON t_message(type);-- 联合索引CREATE INDEX idx_type1_type2 ON t_message(type1, type2);
3.4.3 查询表中的索引
语法:SHOW INDEX FROM 表名
SHOW INDEX FROM student

3.4.4 删除表中的索引
语法:DROP INDEX 索引名称 ON 表名;
/* 在t_message表中删除idx_type索引 */DROP INDEX idx_type ON t_message;
3.4.4 创建索引的原则
- 数据量很大,且经常被查询的数据表可以设置索引 (即读多写少的表可以设置索引)
2. 索引只添加在经常被用作检索条件的字段上 (比如电子商城需要在物品名称关键字加索引)
3.不要在大字段上创建索引 (比如长度很长的字符串不适合做索引,因为查找排序时间变的很长)
四、数据库4大范式
4.1: 1NF(第一范式):
第一范式: 在设计表存储数据的时候, 如果表中设计的字段存储的数据,在取出来使用之前还需要额外的处理(拆分),那么说表的设计不满足第一范式。
第一范式要求字段的数据具有原子性: 不可再分.
第一范式是数据库的基本要求,不满足第一范式就不是关系型数据库
4.1.1 第一范式例子:
1NF—-原子性
eg1: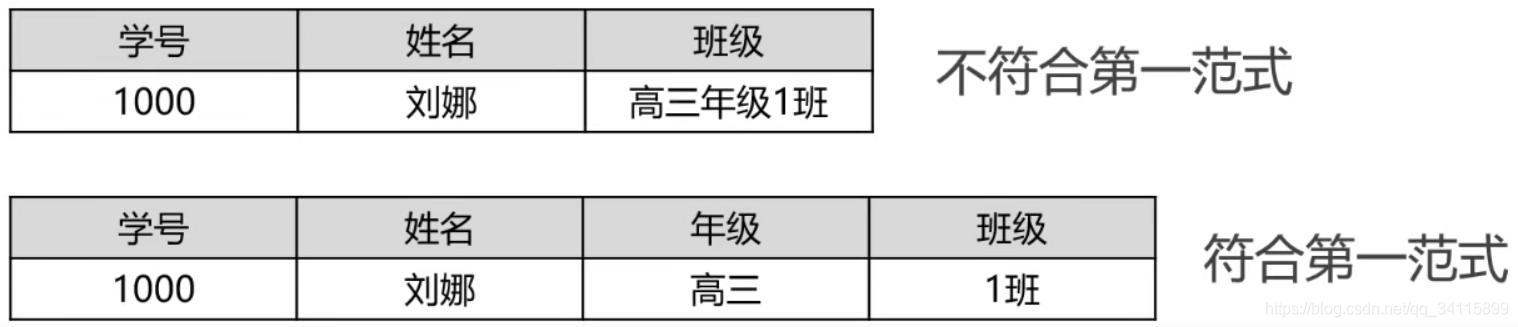
数据表的每一列都是不可分割的基本数据项,同一列中不能有多个值,也不能存在重复的属性。(年级和班级不可以分割)
4.2:2NF(第二范式):
2NF—-唯一性
数据表中的每条记录必须是唯一的。为了实现区分,通常要为表加上一个列来存储唯一标识,这个唯一属性列被称作主键列
4.2.1 第二范式例子:
eg1:
学号为230的学生在2018-07-15考试第一次58没及格,然后当天补考第二次还是58没及格,于是数据库就有了重复的数据。解决办法就是添加一个流水号,让数据变得唯一。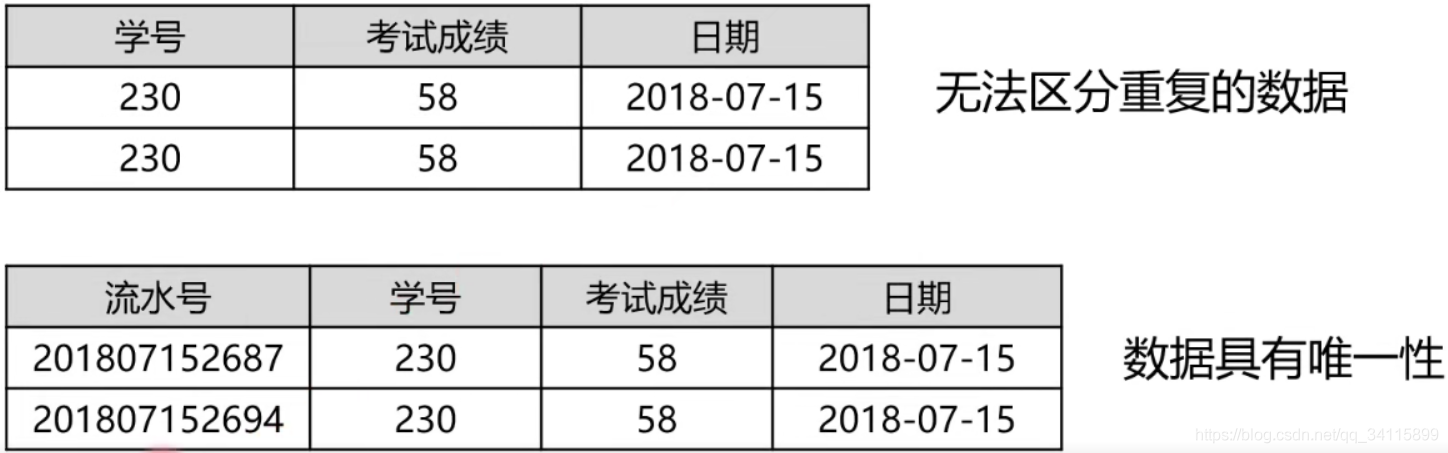
4.3:3NF(第三范式):
4.3.1 第三范式例子:
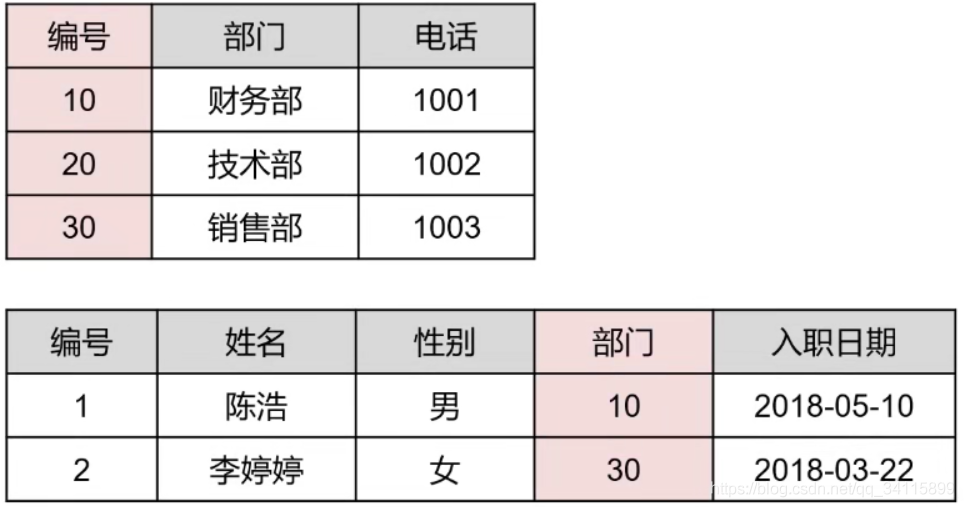
4.4:4NF(逆规范化):
有时候, 在设计表的时候,如果一张表中有几个字段是需要从另外的表中去获取信息. 理论上讲, 的确可以获取到想要的数据, 但是就是效率低一点. 会刻意的在某些表中,不去保存另外表的主键 , 而是直接保存想要的数据信息: 这样一来,在查询数据的时候, 一张表可以直接提供数据, 而不需要多表查询(效率低), 但是会导致数据冗余增加.
如讲师代课信息表
五、数据库高级(增删改查)
5.1 增加数据(INSERT):
语法:
插入一条数据:Insert [IGNORE] into 表名 [字段1,字段2,……] values (值1,值2,……);
插入多条数据:Insert [IGNORE] into 表名 [字段1,字段2,……] values (值1,值2,……), (值1,值2,……);
ps:IGNORE 代表数据表中存在重复的数据时,数据库不会报错而不会吧重复的数据添加进去
INSERT INTO t_dept(deptno, dname, loc) VALUES(50, "技术部", "北京");#插入一条数据INSERT INTO t_dept(deptno, dname, loc) VALUES(50, "技术部", "北京"),(51,"开发部","成都");#插入多条数据
5.2 更新数据(UPDATE):
语法:
UPDATE [IGNORE] 表名 SET 字段1=值1, 字段2=值2, ……
[WHERE 条件1 ……]
[ORDER BY ……]
[LIMIT ……];
eg:把底薪低于公司平均底薪的员工,底薪增加150元
sql语句如下
UPDATE t_emp e JOIN(SELECT AVG(sal) avg FROM t_emp) tON e.sal<t.avgSET e.sal=e.sal+150;
5.3 删除语句(DELETE):
语法:
DELETE [IGNORE] FROM 表名
[WHERE 条件1, 条件2, …]
[ORDER BY …]
[LIMIT …];
子句执行顺序:FROM -> WHERE -> ORDER BY -> LIMIT -> DELETE
ps: ignore表示删除失败就直接忽略而不是报错。
eg1:删除10部门中,工龄超过20年的员工记录
DELETE from t_empWHERE deptno=10 AND DATEDIFF(NOW(),hiredate)/365 >20;
eg2:删除20部门中工资最高的员工记录
DELETE FROM t_empWHERE deptno=20ORDER BY sal+IFNULL(comm,0) DESCLIMIT 1;
5.4 查询数据(SELECT):
语法:
Select [字段别名] /*/All
from 表名
[where条件子句]
[group by子句]
[having子句]
[order by子句]
[limit 子句];
All或者*: 默认保留所有的结果
Distinct: 去重, 查出来的结果,将重复给去除(所有字段都相同)

若有收获,就点个赞吧
0 人点赞
