

调优建议
指定spark executor cores 数量的公式
executor 数量 = spark.cores.max/spark.executor.cores
- spark.cores.max 是指你的spark程序需要的总核数
- spark.executor.cores 是指每个executor需要的核数
—num-executors
该参数主要用于设置该应用总共需要多少executors来执行,Driver在向集群资源管理器申请资源时需要根据此参数决定分配的Executor个数,并尽量满足所需。在不带的情况下只会分配少量Executor。
spark-submit时若带了–num-executors参数则取此值, 不带时取自spark.executor.instances配置,若没配置则取环境变量SPARK_EXECUTOR_INSTANCES的值,若其未设置,则取默认值DEFAULT_NUMBER_EXECUTORS=2。
—executor-memory
spark.default.parallelism
指定并行的task数量
- 参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
—driver-memory
适当提高这个参数的值,性能翻几倍。
spark.memory.fraction
参数说明:默认0.75。堆内存中用于执行、混洗和存储(缓存)的比例。这个值越低,则执行中溢出到磁盘越频繁,同时缓存被逐出内存也更频繁。这个配置的目的,是为了留出用户自定义数据结构、内部元数据使用的内存。推荐使用默认值。
参数调优建议:如果申请的—executor-memory比较大,可以考虑提高这个值。相当于降低用户内存(User Memory)。用户内存:主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息。
spark.memory.storageFraction
参数说明:默认0.5。不会被逐出内存的总量,表示一个相对于 spark.memory.fraction的比例。这个越高,那么执行混洗等操作用的内存就越少,从而溢出磁盘就越频繁。
- 参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么建议调低这个参数的值。
spark.memory.offHeap.size
- 参数说明:默认0M。堆外内存大小,从—executor-memory中分出部分内存,用于shuffle传输。
- 参数调优建议:Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存。默认情况下,这个堆外内存上限默认是每一个executor的内存大小的10%;真正处理大数据的时候,这里都会出现问题,导致spark作业反复崩溃,无法运行;此时就会去调节这个参数,到至少1G(1024M),甚至说2G、4G。
内存模型(与调参相关)
参考:spark内存管理
默认情况下,Spark 仅仅使用了堆内内存。Executor 端的堆内内存区域大致可以分为以下四大块:
- Execution 内存:主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据
- Storage 内存:主要用于存储 spark 的 cache 数据,例如RDD的缓存、unroll数据;
- 用户内存(User Memory):主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息。
- 预留内存(Reserved Memory):系统预留内存,会用来存储Spark内部对象。
如下图所示: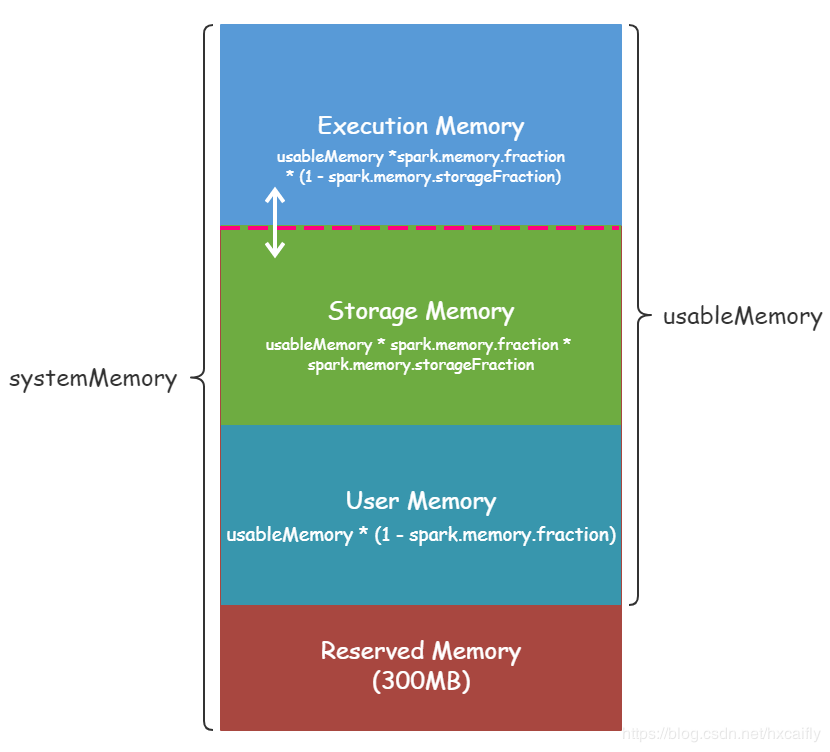
我们对上图进行以下说明:
- systemMemory = Runtime.getRuntime.maxMemory,其实就是通过参数spark.executor.memory 或 —executor-memory 配置的。
- reservedMemory 在 Spark 2.2.1 中是写死的,其值等于300MB,这个值是不能修改的(如果在测试环境下,我们可以通过 spark.testing.reservedMemory 参数进行修改);
- usableMemory = systemMemory - reservedMemory,这个就是 Spark可用内存;
仔细看图,用笔算算就了解上图的原理了,再回头看看参数spark.memory.fraction与spark.memory.storageFraction调整的建议:)。
总的思路是:
- 先设置systemMemory的值,这个值由—executor-memory来配置(原来这个值包含了那么多子模块)
- Reserve Memory是写死的300M,没得调。 (设置的内存就少了300M。。。)
- 对于User Memory(倒数第二个蓝色块),只是用于RDD转换所需的存储而已,可以不需要太多内存,尤其是—executor-memory很大的时候(毕竟增大这个参数值,是为了其他主要的操作)。
- 对于Storage Memory,能写进磁盘就写进磁盘吧,没必要占用执行内存(executor memory),反正数据量大了,也要写进磁盘的。
- 对于executor memory ,增大这个值是目标。这个值大了,core也就能多了,并行度也可以提高了,计算速度就上去了。

若有收获,就点个赞吧
0 人点赞
