前言
终于,学习和运用了大部分大数据组件,对它们的作用也有一定的认知,也逐渐明白大数据生态图的含义了。结合业务会有下面这张图。每个组件的作用也很清晰,但对于刚入门的同学来说,是一脸懵的。所以我将逐步撕开这个图来讲述大数据组件的关系,但只涉及基本逻辑而不涉及具体逻辑。最后回头看看这个图,就很清晰了。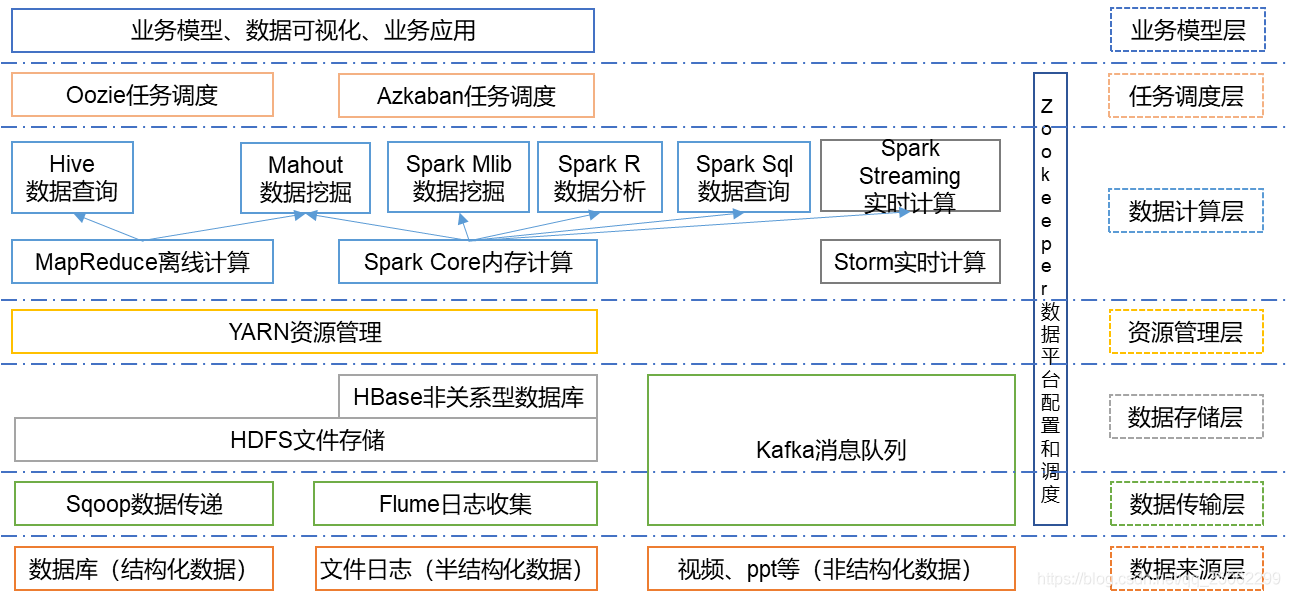
大数据基本问题
我们先将目光聚焦于下图
大数据生态中每一个组件的产生都是为了解决一个痛点。解决问题也是有次序的,依次为:
- hdfs:解决分布式存储问题。【有数据难计算】
- mapreduce:解决分布式计算问题。【差劲的资源调度和计算速度慢】
- yarn:解决资源调度问题(这里为了串线可以先理解成解决mapreduce计算任务资源调度。其实解决了依赖hadoop的所有任务的资源调度问题。)
- zookeeper:动物管理员,高可用基石。解决集群服务调度管理问题。
- hive:解决mapreduce编写困难问题。【实时查询慢】
- hbase:解决mapreduce/hive实时查询速度慢问题。
- spark:解决mapreduce/hive计算速度慢问题,同时引入机器学习。【距离实时还差一点】
- flink:解决实时任务问题。
- spooq:解决传统数据库和hdfs之间数据迁移问题。
- flume:解决日志系统收集问题。
- kakfa:解决组件间数据传输问题。
Hadoop1.0 VS Hadoop2.0
为什么要将hadoop分成两个版本对比?这是因为涉及了yarn的来源。
历史知识:
- hadoop是一个工具箱名称,里面包含了hdfs、mapreduce和yarn这三个组件
- hadoop1.0只有 hdfs和mapreduce
- hadoop2.0才增加了yarn
HDFS(分布式文件系统,解决数据存储问题)
HDFS:分布式文件系统
分布式文件系统出来之前,各大公司都是用单机来存储数据的,当然是几台单机独立存储。哪些数据存储在哪台机,需要人去维护,非常麻烦。尤其是有计算任务的时候,需要连接这几台机器,维护也很难。
HDFS就是来解决存储这个问题的,将这几台机器组成一个集群,由hdfs来统一管理这几台机器,解决了数据存储问题。这样就不用人去维护数据存储了。
从图中可以看到HDFS是在最底层的,也意味这它的上层组件都依赖它,HDFS非常重要。
MapReduce(分布式计算框架,解决数据计算问题)
mapreduce解决离线计算问题。是一种基于磁盘的分布式并行批处理计算模型,用于处理大数据量的计算。
数据存储问题解决了,而数据只存储不利用是很浪费的。这就涉及到计算问题,mapreduce就是解决分布式计算的问题。基本逻辑是:每台机器都接收到相同的一条计算指令,在本机独立计算结果(map过程),然后将这个结果上传做汇总(reduce过程),整个过程结合起来就是mapreduce。
Yarn(分布式资源管理器,解决资源调度问题)
计算是需要资源的,cpu、内存等等,作为计算组件的mapreduce自然也需要资源。但是,即使是集群,其计算资源是有限的,当有多个mapreduce任务一起执行时,该怎么管理调度集群的资源呢,每个任务该给多少计算资源呢。yarn就是负责解决集群资源调度问题的,给计算任务分配计算资源。
每个计算任务在启动时,先向yarn申请计算资源。yarn根据集群资源情况,决定给计算任务分配或不分配资源。计算任务得不到资源就排队,直到yarn给予资源。
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。
Zookeeper(分布式资源管理器)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
Hive/Impala(基于Hadoop的数据仓库)
Hive是基于Hadoop的一个数据分析工具,可以将结构化的数据文件映射为一张表,并提供类sql查询功能。
如果写过mapreduce,会发现很困难,毕竟只有map和reduce算子。显然,困难的东西就意味着不适合大部分人,这不利于发展,需要放开生产力才行。
我们知道,会SQL的人比会java的人要多。那么要使更多的人使用大数据,就需要一个可以提供SQL查询的工具给到人们使用。这时候Hive就出现了,它提供类sql查询功能。实际上它会将sql语句转化成mapreduce任务执行,但我们不再需要写mapreduce,只要写写sql语句就可以完成任务了。解放了生产力。
注意,hive利用了mapreduce,也就意味着它只能用作离线分析,实时性不够。因为mapreduce每个中间结果都会存储在磁盘,意味着读写磁盘io很耗时,不适合实时处理。
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。是一个用 C ++和Java编写的开源软件。 与Apache Hive不同,Impala不基于MapReduce算法。 它实现了一个基于守护进程的分布式架构,它负责在同一台机器上运行的查询执行的所有方面。因此执行效率高于Apache Hive。
HBase(一个列式数据库)
HBase,就是一个hadoop的数据库。
HBase建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
以上所讲的mapreduce和hive组件都是离线计算的,实时性不够。而Hbase非常适合用来进行大数据的实时查询。要注意区别Hive。hive只是一个语言转换工具,本身不存储数据,数据都在hdfs上。HBase基于hdfs构建自己的存储层。两者有本质区别。
Pig(分布式计算框架,离线分析)
Pig(ad-hoc脚本)由yahoo开源,其设计动机是提供一种基于MapReduce的ad-hoc(计算query时发生)数据分析工具。Pig定义了一种数据流语言——Pig Latin,它是MapReduce编程的复杂性抽象,Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Lain)。其编译器将Pig Lain翻译成MapReduce程序序列,将脚本转换为MapReduce任务在Hadoop任务在Hadoop上执行,通常用于进行离线分析。
Spark(分布式计算框架,机器学习)
mapreduce和hive计算慢,出现了基于内存计算的工具
Spark是一种基于内存的分布式并行计算框架,不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Flink(分布式计算框架,实时计算)
Flink是一个基于内存的分布式并行处理框架,类似于Spark,但在部分设计思想有较大出入。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。
Flink VS Spark
Spark中,RDD在运行时是表现为Java Object,而Flink主要表现为logical plan。所以在Flink中使用的类Dataframe api是被作为第一优先级来优化的。但是相对来说在spark RDD中就没有了这块的优化了。
Spark中,对于批处理有RDD,对于流式有DStream,不过内部实际还是RDD抽象;在Flink中,对于批处理有DataSet,对于流式我们有DataStreams,但是是同一个公用的引擎之上两个独立的抽象,并且Spark是伪流处理,而Flink是真流处理。
以上都是计算框架,关键的数据呢?从哪里来?大数据的存储有了,计算有了,现在该讲讲数据来源及工具了。
Sqoop(数据同步工具)
Sqoop(数据ETL/同步工具)是SQL-to-Hadoop的缩写,主要用于传统数据和Hadoop之前传输数据。数据的导入和导出本质上是MapReduce程序,充分利用了MR的并行化和容错性,Sqoop利用数据库技术描述数据架构,用于关系数据库、数据仓库和Hadoop之间转移数据。
Flume(日志收集工具)
Flume(日志收集工具)是Cloudera开源的日志系统收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统,当然也可以用于收集其他类型数据。
Kafka(分布式消息队列)
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。实现了主题、分区及其队列模式以及生产者、消费者架构模式。
生产者组件和消费者组件均可以连接到KafKa集群,而KafKa被认为是组件通信之间所使用的一种消息中间件。
KafKa内部氛围很多Topic(一种高度抽象的数据结构),每个Topic又被分为很多分区(partition),每个分区中的数据按队列模式进行编号存储。被编号的日志数据称为此日志数据块在队列中的偏移量(offest),偏移量越大的数据块越新,即越靠近当前时间。生产环境中的最佳实践架构是Flume+KafKa+Spark Streaming。
Oozie(工作流调度器)
比较少直接用,基本在HUE上使用。
Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。
Oozie使用hPDL(一种XML流程定义语言)来描述这个图。
ELK
ClickHouse

若有收获,就点个赞吧
0 人点赞
