广播变量
from pyspark.sql.functions import broadcastaliyunip = broadcast(spark.read.parquet(aliPath).select("ip","country","province","city"))cacExpand = aliyunip.join(cacInfo, "ip", "right").filter("rcpt is not null and rcpt!='' and sender is not null and sender!=''").cache()
窗口函数
可以参考
https://zhuanlan.zhihu.com/p/92654574
https://zhuanlan.zhihu.com/p/136363624
from pyspark.sql import WindowwinIP = Window.partitionBy("rcpt","sender").orderBy(desc("ipcnt"))comIp=cacExpand.groupby("rcpt","sender","ip").agg(count("ip").alias("ipcnt")).withColumn("tmp", row_number().over(winIP)).where("tmp=1").drop("tmp")
模拟count(case when)
参考
https://stackoverflow.com/questions/49021972/pyspark-count-rows-on-condition
import pyspark.sql.functions as Ftest = spark.createDataFrame([('bn', 12452, 221), ('mb', 14521, 330),('bn',2,220),('mb',14520,331)],['x','y','z'])cnt_cond = lambda cond: F.sum(F.when(cond, 1).otherwise(0))test.groupBy('x').agg(cnt_cond(F.col('y') > 12453).alias('y_cnt'),cnt_cond(F.col('z') > 230).alias('z_cnt')).show()+---+-----+-----+| x|y_cnt|z_cnt|+---+-----+-----+| bn| 0| 0|| mb| 2| 2|+---+-----+-----+
百分比与累加
核心思想是利用窗口函数,注意区分有没有orderBy,orderBy是区分求百分比还是累加的关键细节。
数据形式: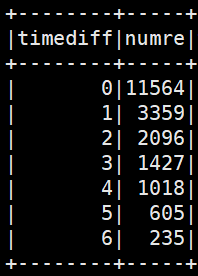
输出形式: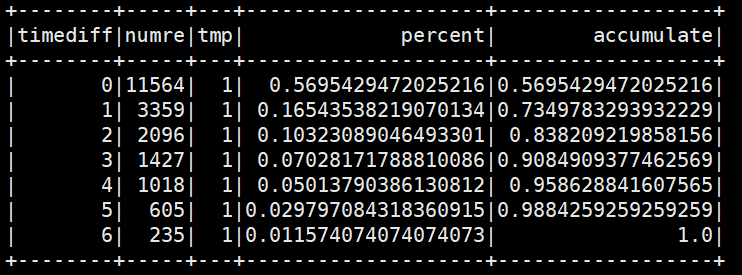
# 由于这个数据集没有分组,所以需要引入一个常数列作为分组依据win2 = Window.partitionBy('tmp') # 不排序,用sum会整列求和,目标为求百分比win3 = Window.partitionBy('tmp').orderBy('timediff') #排序,用sum累加之前所有结果,目标为求累加data.withColumn('tmp', F.lit(1))\.withColumn("percent", F.col('numre')/F.sum("numre").over(win2))\.withColumn('accumulate', F.sum('percent').over(win3))\.show()
时间处理
- current_date()获取当前日期
2021-10-21
- current_timestamp()/now()获取当前时间
2021-10-21 12:23:44.247
- 从日期时间中提取字段
- year,month,day/dayofmonth,hour,minute,second
Examples:> spark.sql(“SELECT day(‘2021-10-21’)”).show()
rertrun: 21
- dayofweek (1 = Sunday, 2 = Monday, …, 7 = Saturday),dayofyear
Examples:> spark.sql(“SELECT dayofweek(‘2021-10-21’)”).show()
return: 5
- weekofyear weekofyear(date) - 返回给定日期一年中的第几周。
- trunc截取某部分的日期,其他部分默认为01
spark.sql(“SELECT trunc(‘2021-10-21’, ‘MM’)”).show()
return 2021-10-01
- unix_timestamp返回当前时间的unix时间戳
SELECT unix_timestamp(); 1476884637
SELECT unix_timestamp(‘2016-04-08’, ‘yyyy-MM-dd’); 1460041200
- 数据类型转换
- 字符串转日期
to_timestamp将一个字符串转为(解析)日期,默认格式为yyyy-MM-dd HH:mm:ss
from pyspark.sql.functions import to_timestampdf1 = spark.createDataFrame([('15/02/2019 10:30:00',)], ['date'])df2 = df1.withColumn("new_date", to_timestamp("date", 'dd/MM/yyyy HH:mm:ss'))df2.show(2)# 将dd/MM/yyyy HH:mm:ss 格式的数据解析成spark可以识别的日期类型+-------------------+-------------------+| date| new_date|+-------------------+-------------------+|15/02/2019 10:30:00|2019-02-15 10:30:00|+-------------------+-------------------+
- to_date/date将字符串转化为日期格式
SELECT to_date(‘2016-12-31’, ‘yyyy-MM-dd’); 2016-12-31
- date_format将时间转化为某种格式的字符串
spark.sql(“SELECT date_format(‘2021-10-21’, ‘y’)”).show()
return 2021
- from_unixtime将时间戳换算成当前时间
SELECT from_unixtime(120, ‘yyyy-MM-dd HH:mm:ss’); 1970-01-01 08:02:00
- to_unix_timestamp将时间转化为时间戳
SELECT to_unix_timestamp(‘2016-04-08’, ‘yyyy-MM-dd’); 1460044800
- 日期计算
- months_between两个日期之间的月数
SELECT months_between(‘1997-02-28 10:30:00’, ‘1996-10-30’); 3.94959677
- add_months返回日期后n个月后的日期
SELECT add_months(‘2016-08-31’, 1); 2016-09-30
- last_day(date),next_day(start_date, day_of_week)
SELECT last_day(‘2009-01-12’); 2009-01-31
SELECT next_day(‘2015-01-14’, ‘TU’); 2015-01-20
- date_add,date_sub(减)
SELECT date_add(‘2016-07-30’, 1); 2016-07-31
- datediff(两个日期间的天数)
SELECT datediff(‘2009-07-31’, ‘2009-07-30’);_ _1
- 关于UTC时间
- to_utc_timestamp
SELECT toutc_timestamp(‘2016-08-31’, ‘Asia/Seoul’); _2016-08-30 15:00:0
2. from_utc_timestamp
SELECT from_utc_timestamp(‘2016-08-31’, ‘Asia/Seoul’); 2016-08-31 09:00:00

若有收获,就点个赞吧
0 人点赞
