一、ES的生态
ES主要用于搜索、日志分析、指标分析、安全分析
开源组件包括:
可视化:Kibana
存储\计算:Elasticsearch
数据抓取:Logstash、Beat()
商业化组件包括:
X-Pack:安全、告警、监控、图查询、机器学习
二、ES安装
1、文件目录说明
bin:脚本文件,包括启动脚本、安装插件、运行统计数据config:elasticsearch.yml 集群配置文件JDK:java运行环境,从7版本开始内置了JDKdata:数据文件lib:Java类库logs:日志modules:包含所有的ES模块plugins:包含所有的已按照插件
JVM配置:建议Xmx、Xms一样;内存不要设置超过机器内存一半;不要超过30GB。
启动脚本:/bin/elasticsearch 或者 /bin/elasticsearch -d 后台启动
默认浏览器端口:9200
需要配置远程访问,按照如下操作修改elasticsearch.yml文件:
bootstrap.memory_lock: falsebootstrap.system_call_filter: false #关闭支持SecCompnode.name: node-1network.host: 0.0.0.0 ##设置任意网络均可访问cluster.initial_master_nodes: ["node-1"]
启动过程中可能会有如下报错:
1、max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决方法:找到文件 /etc/security/limits.conf,编辑,在i文件的最后追加如下配置:
用户名 soft nofile 65535用户名 hard nofile 65537
2、max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方法:在 /etc/sysctl.conf(配置内存映射最大数量)文件最后添加如下一行即可永久修改,需要重启或者使用sysctl -p 使配置生效
vm.max_map_count=262144
查看已经安装的插件:/bin/elasticsearch-plugin list
安装插件:/bin/elasticsearch-plugin install 插件名称
在网页查看已安装插件 http://ip:9200/_cat/plugins
在同一个机器运行多个Elasticsearch实例,如下是启动三个ES实例,实例名称不同,指定集群名称为geektime,数据路径:
/bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data -d
/bin/elasticsearch -E node.name=node2 -E cluster.name=geektime -E path.data=node2_data -d
/bin/elasticsearch -E node.name=node3 -E cluster.name=geektime -E path.data=node3_data -d
在网页查看集群的节点:http://ip:9200/_cat/nodes
2、安装Kibana
第一步:下载解压Kibana
第二步:在config/kibana.yml设置 elasticsearch.url指向 ES的实例
第三步:运行 /bin/kibana (window上运行 /bin/kibana.bat)
第四步:使用浏览器访问 http://localhost:5601
kibana安装插件:/bin/kibana-plugin install 插件名称
查看kibana已安装插件: /bin/kibana-plugin list
删除: /bin/kibana remove
3、安装Logstash
第一步:下载解压缩Logstash
第二步:配置logstash.conf 文件,如下基本包括input、output和filter三个元素,指定数据的输入源、输出源等。
--配置mysql读取input {jdbc {jdbc_driver_library => "/usr/local/logstash/mysql/mysql-connector-java-5.1.47.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://xxx:xxx/data"jdbc_user => "xxx"jdbc_password => "xxx"parameters => { "id" => 666 }statement => "SELECT * FROM xxx_t_job_function_net_bak20140828 WHERE id > :id"}}output {stdout {}}
第三步:运行 /bin/logstash -f logstash.conf
三、基本概念
文档:ES是面向文档的,文档是所有可搜索数据的最小单位,文档会被序列化成json格式的数据保存在ES中,每个文档都有一个UniqueID。
索引:所以是文档的容器,是一类文档的结合
- Index体现了逻辑空间的概念,每个索引都有自己的Mapping定义,用于定义包含的文档的字段名和字段类型。
- Shard体现了物理空间的概念,索引中的数据分散在Shard上。
索引的Mapping定义了文档字段的类型,Setting定义了不同数据的分布。
Mapping:
- 定义index下的字段名
- 定义字段类型,比如数值型、浮点型、布尔型等
- 定义倒排索引相关的设置,比如是否索引、记录position等
Type:在7.0之前,一个索引可以被设置多个Type;7.0以后只能设置一个为“_doc”。查看mapping:GET /[index_name]/_mapping语法:PUT index_name{"mappings":{ ##关键字"doc":{ ##type的名称"properties":{ ##从此开始定义字段的类型"title":{"type":"text" ##text表示可以分词的},"name":{"type":"keyword" ##keyword表示不可分词,一般精确匹配,常常被用来过滤、排序和聚合。},"age":{"type":"integer"}}}}}
对比关系型数据库的一些概念:
| RDBMS | Elasticsearch |
|---|---|
| Tabel | Index(Type) |
| Row | Document |
| Column | Filed |
| Schema | Mapping |
| SQL | DSL |
ES的分布式架构**
- 不同的集群通过集群名来区分,默认”elasticsearch”
- 通过配置文件修改或者在运行时指定,-E cluster.name=geektime
- 一个集群可以有一个或者多个节点,一个机器可以运行多个节点
节点:节点就是一个ES实例,不同的节点会负责不同的职责,测试环境每个节点的职责可以聚合在一起,生产环境应该对每个节点分配不同的职责,TODO详解
- 本质是一个java进程
- 集群内每一个节点都有唯一名字,通过配置文件配置,或者使用 -E node.name=node1指定
- 每个节点启动后会分配一个UID,保存在data目录下
配置节点类型:
| 节点类型 | 配置参数 | 默认值 | 备注 |
|---|---|---|---|
| maste eligible | node.master | true | 只有master节点保存了集群状态,并负责修改 |
| data | node.data | true | 负责保存分片的数据 |
| ingest | node.ingest | true | |
| coordinating only | 无 | 每个节点默认为coordinating节点 | 负责接收Client请求,将请求分发到合适的节点 |
| machine learning | node.ml | true | 负责跑机器学习的Job,用来做异常检测 |
集群状态(包括所有节点信息、索引相关的mapping和setting、分片路由信息)
分片—主分片:用以解决数据水平扩展的问题,通过分片,可以将数据分布到集群内所有的节点之上
- 一个分片是一个运行Luence实例
- 主分片数在索引创建时指定,后续不允许修改,除非reindex
分片—副本:**用于提高数据的高可用问题,分片是主分片的拷贝
- 副本分片数,可以随时调整
- 增加副本数,可以在一定程度上提高服务的可用性
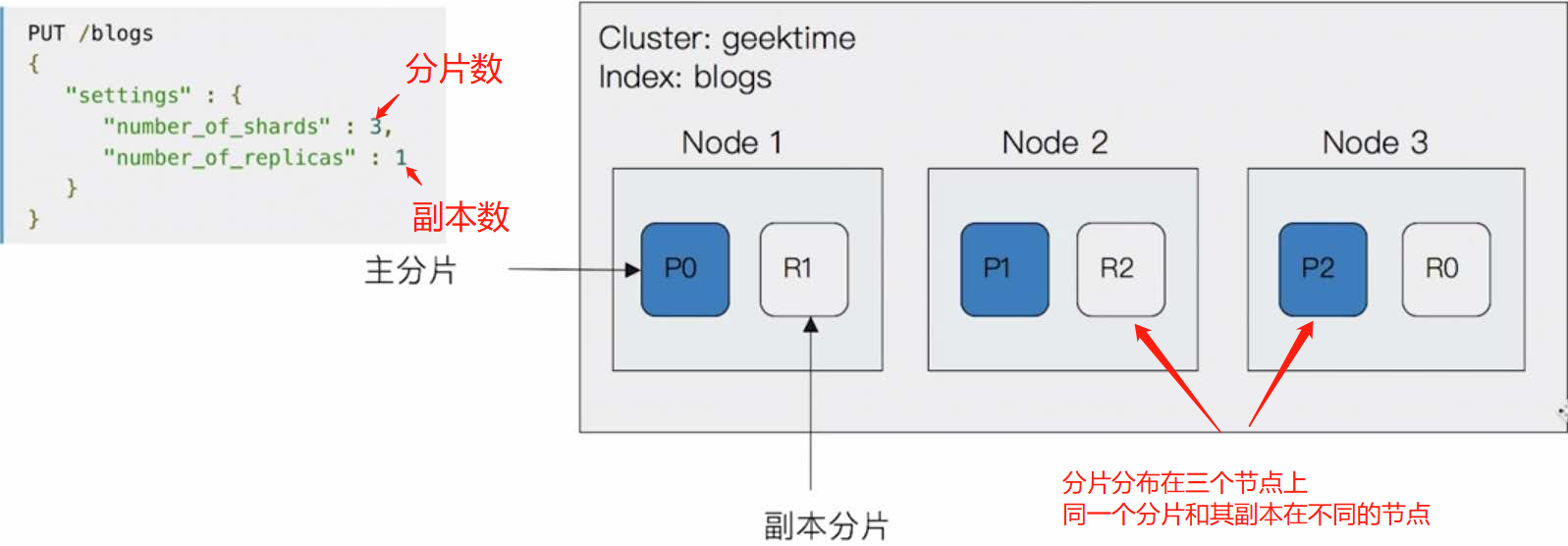
四、ES基本命令
CRUD命令
1、创建空索引:PUT /haoke{"settings":{"index":{"number_of_shards":"2", #分片数"number_of_replicas":"0" #副本数}}}2、删除索引:DELETE /haoke3、插入数据:id如果不指定将会默认一个POST /{索引}/{类型}/{id}{#json格式的数据}4、更新数据,此种方式会全量更新,即整个文档更新PUT /{索引}/{类型}/{id}{#更新的数据}5、更新数据,局部更新,多了_update标识符(包括了四个步骤:从旧的文档索引JSON->修改它->删除旧的文档-索引新的文档>)POST /{索引}/{类型}/{id}/_update{#更新json的数据,原文档的其他数据不会更新}6、删除数据: DELETE /{索引}/{类型}/{id}如果删除一个不存在的数据将会返回404,数据不会马上删除而是标记为删除状态,等待一个时机再去删除7、搜索数据根据id搜索: GET /{索引}/{类型}/{id}查询全部数据(默认返回10条):GET /{索引}/{类型}/_search根据条件查询:GET /{索引}/{类型}/_search?q=key1:value1,key2=value28、DSL(Domain Specific Language)搜索,以json请求体的形式出现:POST /{索引}/{类型}/_search{#json请求体}
五、倒排索引
在搜索引擎中,每个文档都有一个对应的文档 ID,文档内容被表示为一系列关键词的集合。例如,文档 1 经过分词,提取了 20 个关键词,每个关键词都会记录它在文档中出现的次数和出现位置。那么,倒排索引就是**关键词到文档** ID 的映射,每个关键词都对应着一系列的文件,这些文件中都出现了关键词。<br />举个栗子,有以下文档:
| DocId | Doc |
|---|---|
| 1 | 谷歌地图之父跳槽 Facebook |
| 2 | 谷歌地图之父加盟 Facebook |
| 3 | 谷歌地图创始人拉斯离开谷歌加盟 Facebook |
| 4 | 谷歌地图之父跳槽 Facebook 与 Wave 项目取消有关 |
| 5 | 谷歌地图之父拉斯加盟社交网站 Facebook |
对文档进行分词之后,得到以下倒排索引。
| WordId | Word | DocIds |
|---|---|---|
| 1 | 谷歌 | 1, 2, 3, 4, 5 |
| 2 | 地图 | 1, 2, 3, 4, 5 |
| 3 | 之父 | 1, 2, 4, 5 |
| 4 | 跳槽 | 1, 4 |
| 5 | 1, 2, 3, 4, 5 | |
| 6 | 加盟 | 2, 3, 5 |
| 7 | 创始人 | 3 |
| 8 | 拉斯 | 3, 5 |
| 9 | 离开 | 3 |
| 10 | 与 | 4 |
| .. | .. | .. |
另外,实用的倒排索引还可以记录更多的信息,比如文档频率信息,表示在文档集合中有多少个文档包含某个单词。
那么,有了倒排索引,搜索引擎可以很方便地响应用户的查询。比如用户输入查询 Facebook ,搜索系统查找倒排索引,从中读出包含这个单词的文档,这些文档就是提供给用户的搜索结果。
要注意倒排索引的两个重要细节:
j

若有收获,就点个赞吧
0 人点赞
