6. 语义分割
6.1 新方法—傅里叶域自适应
题目:FDA: Fourier Domain Adaptation for Semantic Segmentation(FDA:用于语义分割的傅里叶域自适应)
问题:最新方法过于复杂化
办法:采用简单的傅里叶变换及其逆运算
6.2 新方法—super-BPD
题目:Super-BPD: Super Boundary-to-Pixel Direction for Fast Image Segmentation(Super-BPD:超级 边界到像素 方向,用于快速图像分割)
方法:提出一种基于新型超边界像素方向的快速图像分割方法+基于超边界像素方向的定制分割算法;将每个像素上的BPD定义为从其最近边界指向像素的二维单位向量。在BPD中,来自不同区域的附近像素具有彼此相反的方向,并且同一区域中的相邻像素具有彼此指向的方向(即在中间点附近)。我们利用这种特性将图像划分为超级BPD。
6.3 新训练模型
题目:Single-Stage Semantic Segmentation from Image Labels(图像标签的单阶段语义分割)
问题:新方法提高了在弱监督环境下提高语义分割的准确性能力,但是以增加复杂性和复杂的多阶段训练程序作为代价的;
弱监督方法的三个理想属性:局部一致性、语义保真度、完整性
办法:以三个理想属性为指导,开发基于分段的网络模型和自我监督的训练方案,以在单个阶段中训练来自图像级别注释的语义蒙版。
6.4 分割前后的处理方式
题目:Learning Texture Invariant Representation for Domain Adaptation of Semantic Segmentation(为语义分割的领域匹配学习纹理不变表示法)
问题:为语义分割注释像素级标签很费力
解决方案:利用合成数据
新问题:合成域和真实域之间有域差距,使用合成数据训练的模型推广到真实数据具有挑战性
办法:考虑到两个域之间的基本差异作为纹理,提出一种适应目标域纹理的方法
流程:首先使用样式转移算法使合成图像的纹理多样化;生成的图像的各种纹理可防止分割模型过度适合一种特定的合成纹理;然后通过自我训练对模型进行微调,以直接监督目标纹理
6.5 新合成数据集——对分类法和注释进行操作
题目:MSeg: A Composite Dataset for Multi-domain Semantic Segmentation(MSeg:用于多域语义分割的复合数据集)
MSeg(一种组合数据集):一个可以统一来自不同领域的语义细分数据集
调和分类法和注释操作并带来像素级,重新标记多个注释来对齐图像的对象蒙版,组合的数据集可训练单个语义细分模型
6.6 基于新分割方法的某网络结构
题目:CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement(CascadePSP:通过全局和局部优化实现与类无关和非常高分辨率的细分)
问题:先进的语义分割方法只针对固定分辨率范围内的图像进行训练,这对于高分辨率图像是不够准确的
解决方案:提出一种无需使用任何高分辨率训练数据即可解决高分辨率分割问题的方法,使用CascadePSP网络,该网络会完善和纠正局部边界
6.7 对CNN方法的改进
题目:Unsupervised Intra-domain Adaptation for Semantic Segmentation through Self-Supervision(通过自我监督实现语义分割的无监督域内适应)
问题1:基于卷积神经网络的方法在语义分割方面严重依赖劳动密集型的带注释数据
解决方案1:把从图形引擎生成的自动注释数据用于训练分割模型
问题2:从合成数据训练的模型很难转换为真实图像
方案2:考虑将模型从源数据直接适配到未标记的目标数据以减少域间差距
方案2的局限性:未考虑目标数据本身之间的较大分配差距(域内差距)
方案3:提出了两步自监督域自适应方法以最小化域间和域内的间隙
方案3的流程:首先进行模型的域间适配,使用基于熵的排名功能将目标划分为容易和困难;为减少域内间隙,从易分割到硬分割采用自监督自适应技术
6.8 基于CAM的改进
题目:Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation(自监督等变注意机制用于弱监督语义分割)
大问题:图像级弱监督语义分割
解决方案1:类激活图(CAM)
方案1的局限性:由于全面监督与弱监督之间的差距,CAMs几乎不能用作目标遮挡
本文解决方案(1)+(2)结合:
(1)提出一种自我监督的等变注意机制(SEAM);等方差是完全监督语义分割中的隐式约束,在数据扩充过程中,其像素级标签的空间变换与输入图像的空间变换相同。但是,这种约束在通过图像级监督训练的CAM上丢失了。因此对来自各种变换图像的预测CAM进行一致性正则化
(2)提出了一种像素相关模块(PCM),该模块利用上下文外观信息并通过其相似邻居细化当前像素的预测,从而进一步提高CAM的一致性
测试数据集:PASCAL VOC 2012
6.9 新网络结构——TDNet
题目:Temporally Distributed Networks for Fast Video Segmentation(临时分布式网络用于快速视频语义分割)
提出一个为快速准确地进行视频语义分割而设计的临时分布式网络——TDNet.
(1)通过组合从几个较浅的子网提取的特征来近似从深层CNN的某个高级层提取的特征;
(2)利用视频中固有的时间连续性,将这些子网分布在顺序的帧上;
(3)在每个时间步骤执行轻量级计算即可从单个子网中提取子功能组。
(4)然后,通过应用新颖的注意力传播模块来补偿用于分割的全部特征,该模块可以补偿帧之间的几何变形;
(5)还引入了分组知识蒸馏损失以进一步提高完整功能和子功能级别的表示能力。
6.10 改进上下文相关性方法
题目:Context Prior for Scene Segmentation(上下文优先用于场景分割)
好的上下文相关性能更准确的分割结果
问题:大多数方法很少区分不同类型的上下文依赖项
本文方法:直接监督特征聚合以清楚地区分类内和类间上下文;
(1)在亲和度损失的监督下开发上下文先验。
(2)给定输入图像和相应的基本事实,“亲和力损失”将构建理想的亲和力图来监督上下文先验的学习。
(3)所学习的上下文先验提取属于同一类别的像素,而相反的先验则专注于不同类别的像素;
(4)嵌入到传统的深层CNN中,提议的上下文先验层可以有选择地捕获类内和类间上下文相关性,从而实现健壮的特征表示。
6.11 空间池改进
题目:Strip Pooling: Rethinking Spatial Pooling for Scene Parsing(条带化池:重新考虑空间池以进行场景解析)
空间池作用:在捕获用于场景分析等像素级预测任务的远程上下文信息方面非常有效
方法:引入条带化池策略来重新考虑空间池化的公式
空间池化体系结构:
(1)引入一个新的条带池化模块,该模块使骨干网络能够有效地建模远程依赖关系
(2)提出一种以各种空间池化为核心的新颖构建基块
(3)系统地比较了建议的条带池和常规空间池技术的性能。两种新颖的基于池的设计都是轻量级的,并且可以在现有场景解析网络中用作有效的即插即用模块
6.12 针对城市场景的语义分割方法改进
题目:Cars Can’t Fly up in the Sky: Improving Urban-Scene Segmentation via Height-driven Attention Networks(汽车无法飞上蓝天:通过高度驱动的注意力网络改善城市场景分割)
方法:利用了城市场景图像的内在特征,并提出了一个通用的附加模块,称为高度驱动的注意力网络(HANet),用于改善城市场景图像的语义分割;根据像素的垂直位置选择性地强调信息性特征或类
6.13 分割新方式
题目:Learning Dynamic Routing for Semantic Segmentation(学习用于语义分割的动态路由)
老方法:在预定义的静态体系结构中处理各种规模的输入
新方法:动态路由——在概念上减轻语义表示中尺度差异的新方法。
提出的框架生成依赖于数据的路由,以适应每个图像的比例分布。
提出一种称为软条件门的可微分门控功能,以动态选择比例变换路径
7.实例分割

7.1 新检测方法——D2Det
题目:D2Det: Towards High Quality Object Detection and Instance Segmentation(D2Det:致力于高质量的对象检测和实例分割)
D2Det——新两阶段检测方法,解决了精确的定位和分类问题;
传统两阶段检测器使用传统回归和基于关键点的定位
(1)为了精确定位,引入密集局部回归,该回归可以预测对象提议的多个密集框偏移量;并且不限于固定区域内的一组量化关键点,并具有回归位置敏感实数密集偏移量的能力;通过二进制重叠预测策略进一步改善密集局部回归,该策略可以减少背景区域对最终盒回归的影响
(2)为了进行准确的分类,引入了判别式RoI pooling方案,该方案从提案的各个子区域进行采样,并执行自适应加权以获得判别式特征。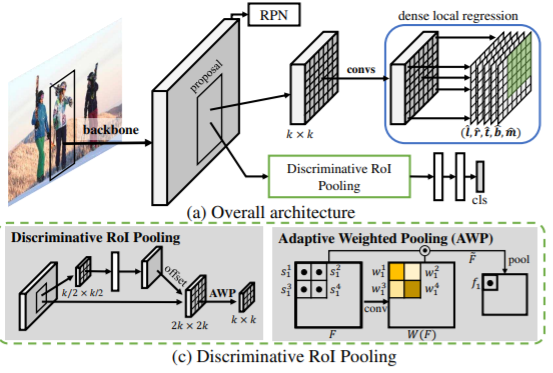

测试:MS COCO test-dev、应用于实例分割中
7.2 PolarMask:一阶段实例分割新思路
题目:PolarMask: Single Shot Instance Segmentation with Polar Representation(利用极坐标表示的单发实例分割)
PolarMask的方法:用作实例分割的模板预测模块方法;将实例分割问题公式化为实例中心分类和极坐标中的密集距离回归
PolarMask特点:
(1)anchor free and bbox free,不需要出检测框
(2)fully convolutional network,相比FCOS把四根射线散发到36根射线,将instance segmentaion和object detection用同一种建模方式来表达
实例分割建模方法:像素级建模+轮廓建模
相比较于Mask R-CNN的像素级建模方式,本文的PolarMask属于轮廓建模
直角坐标缺乏固定角度先验,基于极坐标系的方式已经将固定角度设为先验,网络只需回归固定角度的长度即可。
另外补充新方法:Polar CenterNess用于优化high-quality正样本采样;Polar loU Loss用于dense distance regression的损失函数优化。没使用任何trick(多尺度训练,延长训练时间等)
7.3 方法改进——spatial attention-guided mask branch
题目:CenterMask : Real-Time Anchor-Free Instance Segmentation(CenterMask:实时地anchor-free实例分割)
创新点1:CenterMask通过Mask R-CNN在同一条静脉中向anchor-free一阶目标检测(FCOS)添加了一个新的空间注意力导向蒙版(SAG)分支;
效果:被插入FCOS对象检测后SAG-Mask分支将使用空间关注图预测每个框上的分割蒙版,以关注信息像素并抑制噪声。
创新点2:提出一种改进的骨干网络VoVNetV2,有两种有效的策略;
(1)剩余连接以缓解较大的VoVNet的优化问题
(2)有效地挤压激励(eSE)处理原始SE的信道信息丢失问题
7.4 对蒙版精度改进
题目:BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation(BlendMask:自顶向下与自下而上的实例分割)
目前新方法:全卷积实例分割法;特点:比Mask R-CNN的两阶段方法更简单,有效
问题:当模型计算复杂度相似时,几乎很多这样的新方法在蒙版精度上都落后于二阶段的Mask R-CNN方法
解决方案:将实例级信息与具有较低级细粒度的语义信息结合起来,实现改进的蒙版预测
主要贡献:Blender模块——从自顶向下和自下而上的实例分割法中获取的灵感
BlenderMask功能:通过很少的通道有效地预测每个像素密集的位置敏感实例特征,并且仅使用一个卷积层就可以为每个实例学习注意力图,进而快速推理
优势:BlendMask可以与最新的一阶检测框架结合使用,相同的训练情况下性能优于Mask R-CCC
7.5 轮廓描绘新方法
题目:Deep Snake for Real-Time Instance Segmentation(用于实时实例分割的Deep Snake算法)
Deep Snake:基于轮廓的方法;使用神经网络迭代变形初始轮廓以匹配对象边界;使用圆形卷积,以更好的利用轮廓的循环图结构
基于Deep Snake开发了一个两阶段的管道用于实例分割:初始轮廓方案和轮廓形变,可处理对象定位中的错误
其他方法:直接从图形中回归对象边界点的坐标
7.6 新单发分割框架
题目:Mask Encoding for Single Shot Instance Segmentation(单镜头实例分割的蒙版编码(MEInst))
问题:Mask R-CNN主导了实例分割,一级的替代品无法与Mask R-CNN竞争,是因为一级方法难以紧凑地表示蒙版
方案:单发实例分割框架,是基于蒙版编码的;MEInst不是直接预测二维蒙版,而是将其提炼为紧凑且固定的维数表示向量,这样实例分割任务可以合并到一级边界框检测中
8.全景分割
- 全景分割相当于语义分割和实例分割的结合;目的:同时对前景进行实例分割和对背景素材进行语义分割
- 全景分割的常见公开数据集包括:MSCOCO、Vistas、ADE20K 和 Cityscapes
- 传统的场景理解(Scene Understanding)的任务主要解决了物体是什么、在哪里(目标检测, Object Detection),物体更加精细的轮廓是怎样的(实例分割, Instance Segmentation),整个场景中环境信息是怎样的(语义分割, Semantic Segmentation),怎样对整个场景进行统一的感知(全景分割, Panoptic Segmentation)……
8.1 视频全景分割
题目:Video Panoptic Segmentation(视频全景分割)
视频全景分割任务需要生成一致的全景分割以及跨视频帧的实例ID的关联
两种类型的视频全景数据集:
(1)将合成VIPER数据集重新组织为视频全景格式,利用其大规模像素注释
(2)在Cityscapes val上的时间扩展,通过提供新的视频全景注释进行设置
视频全景分割网络(VPSNet):可以预测视频帧中的对象类别、边界框、mask、实例ID跟踪和语义分割
指标:视频全景质量(VPQ)指标
8.2 新全景分割方式
题目:BANet: Bidirectional Aggregation Network with Occlusion Handling for Panoptic Segmentation(BANet:用于全景分割的具有遮挡处理的双向聚合网络)
自顶向下的管道的两个关键问题:
(1)如何有效地建模语义分割和实例分割之间的内在相互作用
(2)如何正确处理全景分割的遮挡
存在的不足:检测/mask评分不足以解决遮挡问题
解决方案:提出一种基于双向学习流管道的新型深度全景分割方案;引入即插即用遮挡处理算法来处理不同对象实例之间的遮挡
9. 视频目标分割
9.1 新型标签传播方法
题目:A Transductive Approach for Video Object Segmentation(视频对象分割的传导性方式)
存在问题:大多数流行方法都利用了在其他领域(如光流和实例分割)中受过训练的其他模块中的信息,因此,这些方法无法在共同的基础上与其他方法竞争
解决方案:需要一种简单而强大的传导方法;采用标签传播方式,其中像素标签基于嵌入空间中的特征相似性向前传递,并且是以整体方式传播时间信息,同时考虑长时间出现的物体。
10. 超像素分割
10.1 全卷积应用于超像素分割方式
题目:Superpixel Segmentation with Fully Convolutional Networks(完全卷积网络的超像素分割)
问题:标准卷积运算时在规则的网格上定义的,当应用到超像素时效率低下
灵感启发:传统超像素算法经常采用的初始化策略
解决方案:简单的全卷积网络来预测规则图像网格上的超像素
11.交互式图像分割
11.1
题目:Interactive Object Segmentation with Inside-Outside Guidance(内外指导的交互式对象分割)
解决的问题:如何在最小化人机交互成本的同时获取精确的对象分割蒙版;

若有收获,就点个赞吧
0 人点赞
