资料:https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/
1. 执行计划解析
从SQL语句到Spark中RDD的执行需要经过两大阶段,分别是逻辑计划(LogicalPlan)和物理计划(PhysicalPlan)。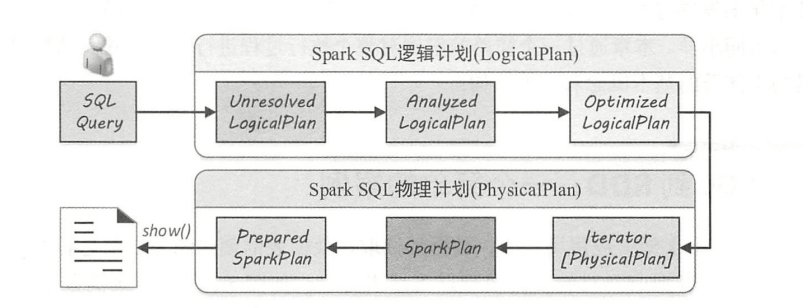
图1.1 SQL执行全过程概览
逻辑计划阶段:
- 未解析的逻辑算子树(Unresolved LogicaPlan)
- 解析后的逻辑算子树(Analyzed LogicalPlan)
- 优化后的逻辑算子树(Optimized LogicalPlan)
物理计划阶段:
- 物理算子树列表(Iterator[PhysicalPlan])
- 按照策略选取最优的物理算子树(SparkPlan)
对选取的物理算子树准备提交执行(Prepared SparkPlan)
经过逻辑计划和物理计划的构建后,物理算子树生成的RDD执行action算子即可执行。上述转换过程都在Spark集群的 Driver 端进行,不涉及分布式环境。SparkSession 类的 sql 方法调用 SessionState 中的各种对象,包括上述不同阶段对应的SparkSqlParser类、 Analyzer 类、 Optimizer类和SparkPlan类等,最后封装成QueryExecution对象。因此,在进行 Spark SQL 开发时,可以很方便地将每一步生成的计划单独剥离出来分析。
2. 编译器(Parser)
如果不算存储过程等扩展功能,则 SQL 可以被看作是种领域特定语言(Domain Specific Language ,简称 DSL)。
DSL 的构建与通用编程语言的构建类似,主要的过程仍然是指定语法和语义,然后实现编译器或解释器。通常情况下,一个系统中 DSL 模块的实现需要涉及两方面的工作
- 设计语法和语义,定义 DSL 中具体的元素
- 实现词法分析器(Lexer )和语法分析器(Parser ),完成对 DSL 的解析,最终转换为底层逻辑来执行。
ANTLR (Another Tool for Language Recognition )是目前非常活跃的语法生成工具,用 Java 语言编写,ANTLR 可以用来产生词法分析器、语法分析器和树状分析器(Tree Parser )等各个模块,ANTLR 本身使用 switch-case 逻辑来匹配字符(Token ),形成记号序列流。Hive、Presto、Spark SQL 等大数据引擎的 SQL 编译模块也都是基于 ANTLR构建的。
Spark SQL中, Catalyst提供了直接面向用户的 Parselnterface 接口,该接口中包含了对 SQL 语句、 Expression 表达式和 Table Identifier 数据表标识符的解析方法 。 AbstractSqlParser 是实现了 Parselnterface 的虚类,其中定义了返回 AstBuilder 的函数。
整个 SQL 解析中 CatalystSqlParser 仅用于 Catalyst 内部,而 SpakSqlParser 用于外部调用。其中,比较核心的是 AstBuilder ,它继承了 ANTLR4 生成的默认 SqlBaseBase Visitor ,用于生成 SQL 对应的抽象语法树 AST (Unresolved LogicalPlan); SparkSqlAstBuilder 继承 AstBuilder ,并在其基础上定义了 DDL 语句的访问操作,主要在SparkSqlParser中调用。AstBuilder 中的操作遵循后序遍历方式(首先会生成子节点的 LogicalPlan ,然后生成当前节点的 LogicalPlan ,AstBuilder 左右子节点的访问 顺序也不固定)。
当面临开发新的语法支持时,首先需要改动的是 ANTLR4 文件(在 Sq1Base.g4 中添加文法), 重新生成词法分析器(SqlBaseLexer )、语法分析器(SqlBaseParser )和访问者类(SqlBase Visitor接口与 SqlBaseBaseVisitor 类),然后在 AstBuilder 等类中添加相应的访问逻辑,最后添加执行逻辑。
生成的抽象语法树AST")
从语法树可以看到, SingleStatementContext 是根节点,但是在访问该节点时一般什么都不做,只递归访问子节点。整个遍历访问操作中比较重要的是包含多个子节点的节点 。例如 QuerySqecificationContext节点,一般将数据表和具体的查询表达式整合在一起,左边的一系列节点对应 select 表达式中选择的列,中间的 FromClauseContext 为根节点的系列节点对应数据表,右边的一系列节点则对应 where 条件中的表达式。生成的AST")
加入排序操作后生成的新语法树在QueryOrganizationContext 节点下面加入了 SortltemContext 节点,代表数据查询之后所进行的排序操作。
一般来讲,QueryOrganizationContext 为根节点所代表的子树中包含了各种对数据组织的操作,例如 Sort 、Limit、Window 算子等。 from student group by id)生成的AST")
可以看到,加入聚合操作后生成的语法树根节点周围结构没有改变,变化的主要是 QuerySpecificationContext 节点所包含的子树。
在上述聚合查询中,除 id 外,还有对 name列 count 操作所产生的新列,所以
NamedExpressionSeqContext 节点包含两个子节点, FromClauseContext 子树代表的数据表信息没有变化,仍然是 QuerySpecificationContext 的第二个子节点 ,加入聚合操作后的语法树最重要的元素是 FunctionCallContext 节点和 AggregationContext 节点 SqlBase.g4 文法文件中表示聚合操作的关键字是 group by、 grouping sets、 rollup、cube,反映在语法树中就是QuerySpecificationContext节点下的 AggregationContext节点,表示聚合函数的FunctionCallContext节点很好理解,其子节点QualifiedNameContext代表函数名, ExpressionContext 表示函数的参数表达式(对应 SQL 语句中的 name 列)。
3. 逻辑计划(Logic Plan)
LogicalPlan 作为数据结构记录了对应逻辑算子树节点的基本信息和基本操作,包括输入输出和各种处理逻辑等。LogicalPlan 属于 TreeNode 体系,继承自Query Plan 父类。逻辑计划阶段在整个流程中起着承前启后的作用,在此阶段,字符串形态的 SQL 语句转换为树结构形态的逻辑算子树, SQL 中所包含的各种处理逻辑(过滤、剪裁等)和数据信息都会被整合在逻辑算子树的不同节点中。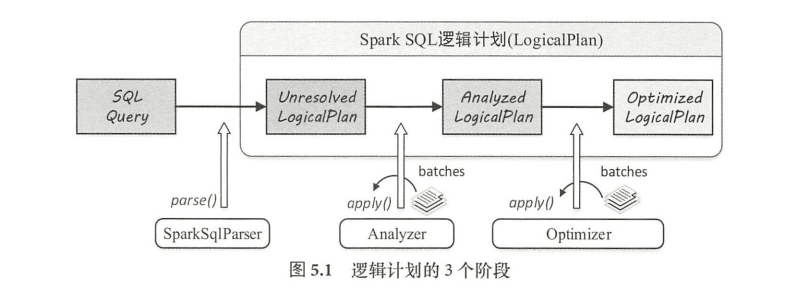
Spark SQL 逻辑计划在实现层面被定义为 LogicalPlan类, SQL 语句经过 SparkSqlParser 解析生成 UnresolvedLogicalPlan ,到最终优化成为 Optimized LogicalPlan ,这个流程主要经过3个阶段,其中 OptimizedLogicalPlan 传递到下个阶段用于物理执行计划的生成。
具体来讲,这个阶段可以分为三个步骤:
- 由 SparkSqlParser 中的 AstBuilder 执行节点访问,将语法树的各种 Context 节点转换成对应的 LogicalPlan 节点,从而成为棵未解析的逻辑算子树(Unresolved LogicalPlan ),此时的逻辑算子树是最初形态,不包含数据信息与列信息等。
- 由 Analyzer 系列的规则作用在 Unresolved LogicalPlan 上,对树上的节点绑定各种数据信息,生成解析后的逻辑算子树(Analyzed LogicalPlan)
- 由 Spark SQL 中的优化器( Optimizer )将 系列优化规则作用到上步生成的逻辑算 子树中,在确保结果正确的前提下改写其中的低效结构,生成优化后的逻辑算子树( Optimized LogicalPlan)。
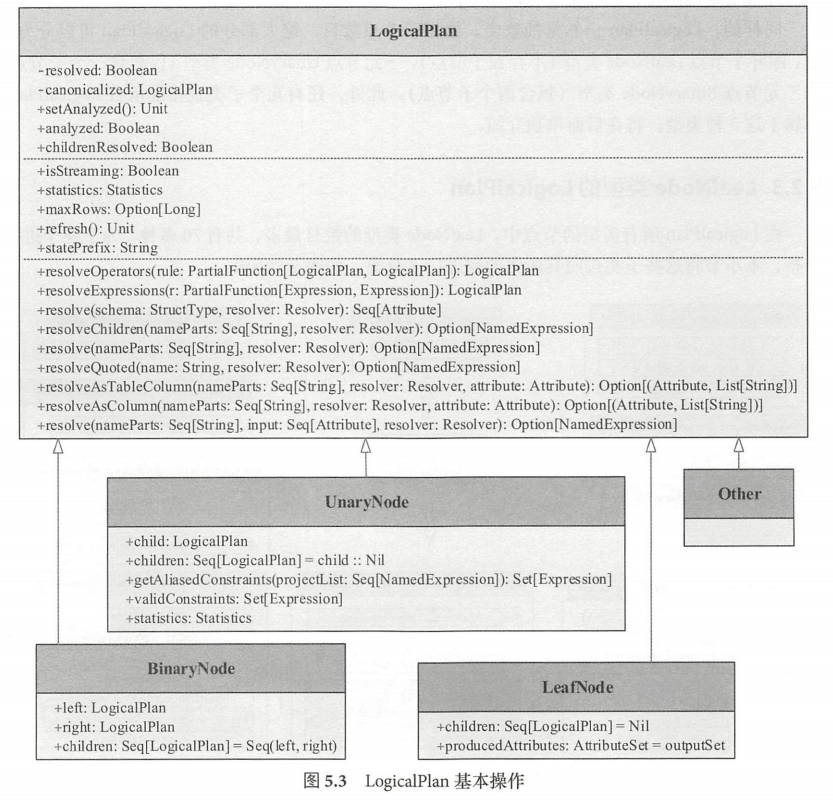
LogicalPlan 仍然是抽象类,根据子节点数目,绝大部分的 LogicalPlan 可以分为 3类,即叶子节点 LeafNode 类型(不存在子节点)、一元节点 UnaryNode 类型(仅包含1个子节点) 、二元节点 BinaryNode 类型(包含两个子节点)。此外,还有几个直接继 LogicalPlan, 不属于上述3种类型。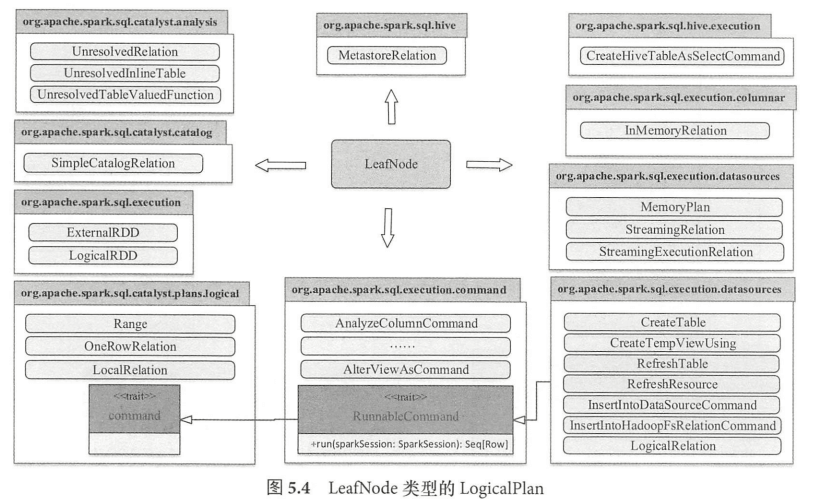
- LeafNode 类型的 LogicalPlan节点对应数据表和Command相关的逻辑, 其中RunnableCommand 是直接运行的命令,主要涉及包括 Database 相关命令、 Table相关命令、 View 相关命令 、DDL相关命令、 Function 相关命令和 Resource 相关命令等。
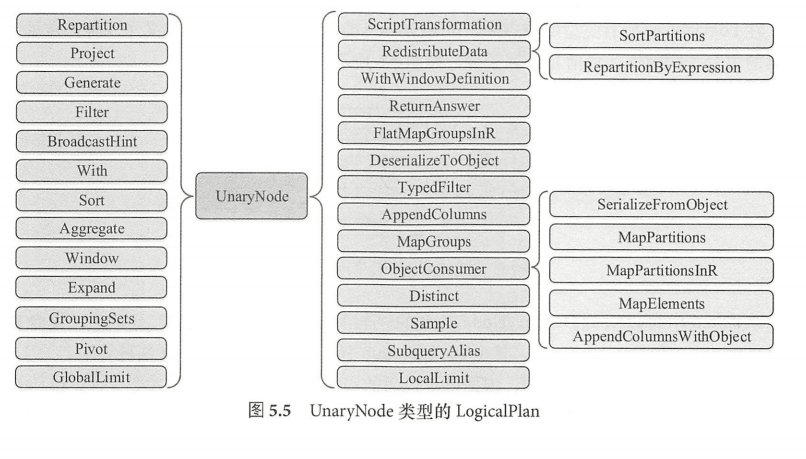
- UnaryNode 类型的节点常见于对数据的逻辑转换操作,包括过滤、排序等。
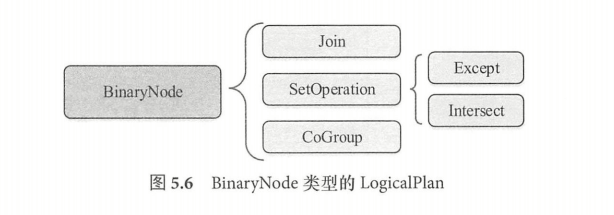
- BinaryNode 类型的节点常见于对数据的组合关联操作,包括连接 (Join )、集合操作(SetOperation )和 CoGroup 3种,其中 SetOperation 包括差集(Except)和交集(Intersect) 两种算子。
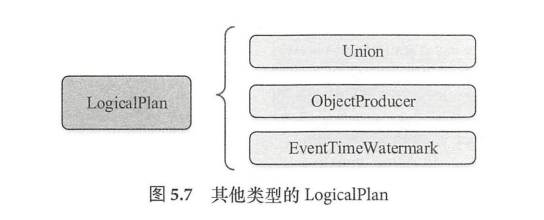
- 3种直接继承自LogicalPlan 的逻辑算子节点。EventTimeWatermark 主要针对 Spark Streaming 中的 watermark 机制; objectProducer 为特质(Trait ),用于产生只包含object列的行数据; Union 算子的使用场景比较多,其子节点数目不限,是一系列 LogicalPlan 的列表。
4. AstBuilder 机制: Unresolved LogicalPlan 生成
Spark SQL 首先会在 Parser Driver 中通过调用语法分析器中的 singleStatement ()方法构建整棵语法树,然后通过 AstBuilder 访问者类对语法树进行访问。根据 AstBuilder 中的逻辑,其访问入口即是 visitSingleStatement 方法,该方法也是访问整棵抽象语法树的启动接口。
org.apache.spark.sql.catalyst.parser.AstBuilder
从逻辑上来看,对根节点的访问操作会递归访问其子节点(ctx.statement ,默认为 Statement DefaultContext 节点,即AST图的根节点的子节点)这样逐步向下递归调用,直到访问某个子节点时能够构造LogicalPlan ,然后传递给父节点。
总的来看,生成 Unresolved LogicalPlan的过程,从访问 uerySpecificationContext
节点开始,分为以下3个步骤: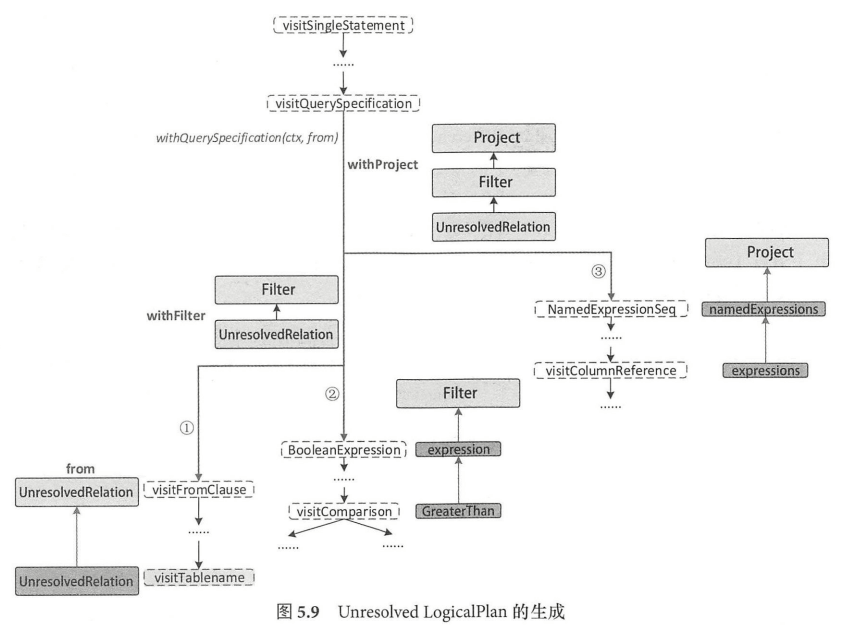
- 生成数据表对应的LogicalPlan :访问 FromClauseContext 并递归访问, 直到匹配 TableNameContext 节点(visitTableName )时,直接根据 TableNameContext 中的数据信息生成 UnresolvedRelation ,此时不再继续递归访问子节点,构造名为 from的LogicalPlan 并返回。
- 生成加入了过滤逻辑的 LogicalPlan :过滤逻辑对应 SQL 中的 where 语句,在 QuerySpecificationContext 中包含了名称为 where的BooleanExpressionContext 类型,对应AST图中的 BooleanDefaultContext 节点 ,AstBuilder 会对该子树进行递归访问,生成 expression 并返回作为过滤条件,然后基于此过滤条件表达式生成 Filter LogicalPlan 节点。最后,由此 Logical Plan 和第1步中的 UnresolvedRelation 构造成名称为 withFilter的LogicalPlan ,其中Filter节点为根节点 。
- 生成加入列剪裁后的 LogicalPlan :列剪裁逻辑对应 SQL中select 语句对 name 列的选择操作,即AST图中的最后1步操作 。AstBuilder 在访问过程中会获取 QuerySpecificationContext 节点所包含的 NamedExpressionSeqContext 成员,并对其所有子节点对应的表达式进行转换,生成 NameExpression 列表(namedExpressions ),然后,基于 namedExpressions 生成 Project LogicalPlan; 最后,由此 LogicalPlan 和第2步中的 withFilter 构造成名称为 withProject 的LogicalPlan 。其中 Proect 最终成为整棵逻辑算子树的根节点。
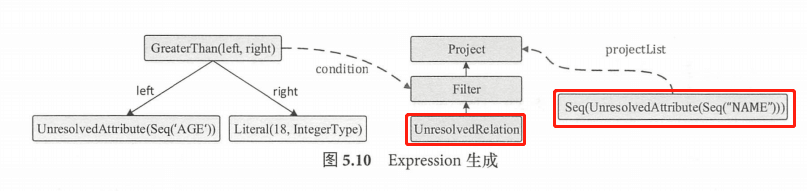
最终生成逻辑算子 Filter 节点的 condition 构造参数 GreaterThan 表达式,其树型结构如图左所示;
最终生成逻辑算子树 Project 节点的构造参数表达式,如图右所示。
总的来看,最终生成的 Unresolved LogicalPlan 完整地涵盖了 SQL 语句中的信息。首先是 UnresolvedRelation 叶子节点,对应未绑定元数据信息的 student 数据表,只返回 student 表名字符串。过滤节点filter,会将 condition 表达式中的谓词逻辑与子节点中的约束整合。列剪裁节点 Project Project ,会将 projectList 对应的别名约束与子节点中的约束整合。
5. 解析器(Analyzer)
经过上个阶段 AstBuilder 的处理,已经得到了unresolved LogicalPlan。从最后生成表达式中看出, 该逻辑算子树中未被解析的有unresolvedRelation和UnresolvedAttribute两种对象。实际上, Analyzer 的主要作用就是将这两种节点或表达式解析成有类型的(Typed )对象。此过程中,需要用到 Catalog 的相关信息 。
介绍下Spark SQL 中随处都会用到的 Catalog 体系和 Rule 体系。
5.1 Catalog体系
在关系数据库中, Catalog 是个宽泛的概念,通常可以理解为一个容器或数据库对象命名空间中的一个层次。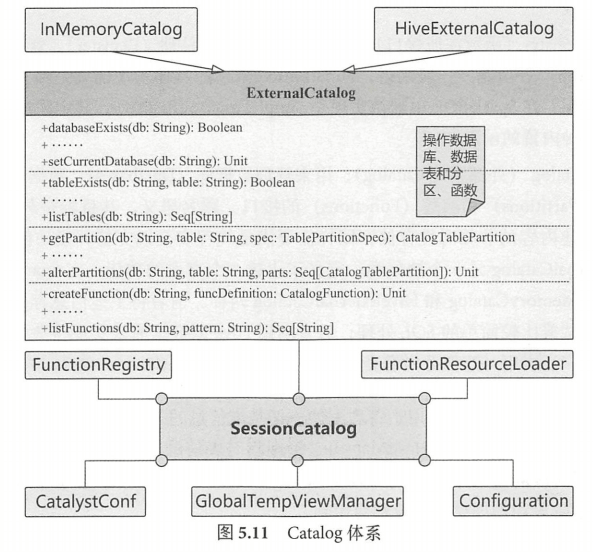
Spark SQL 中的 Catalog 体系实现以 SessionCatalog 为主体,通过 SparkSession提供给外部调用。一般一个SparkSession 对应一个SessionCatalog 。本质上,SessionCatalog 起到代理的作用,对底层的元数据信息、临时表信息、视图信息和函数信息进行了封装。
SessionCatalog 的构造参数包括6部分,除传入SparkSQL、Hadoop 配置信息的CatalystConf 和Configuration 外,还涉及以下4个方面的内容
• GlobalTempViewManager(全局临时视图管理):对应 DataFrame 中常用的 createGlobalTempView 方法,进行跨 Session 的视图管理。GlobalTempViewManager是一个线程安全类,提供了对全局视图的原子操作,包括创建、更新、删除和命名等。GlobalTempViewManager 内部实现中, 主要功能依赖 mutable 类型的 HashMap 来对视图名和数据源进行映射,其中的 key 是视图名的字符串, value 是视图所对应的 LogicalPlan(一般在创建该视图时生成)。需要注意的是,GlobalTempViewManager 对视图名是大小写敏感的。
• FunctionResourceLoader (函数资源加载器):在 SparkSQL 中除内置实现的各种函数外,还支持用户自定义函数和 Hive 中的各种函数 ,这些函数往往通过 Jar 包或文件类型提供, FunctionResourceLoader 主要就是用来加载这两种类型的资源以提供函数的调用。需要注意的是,对于 Archive 类型的资源,目前仅支持在 YARN 模式下以 spark-submit 方式提交时进行加载 。
• FunctionRegistry (函数注册接口):用来实现对函数的注册 (Register )、查找( Lookup )和 删除(Drop )等功能。一般来讲, FunctionRegistry 具体实现需要是线程安全的,以支持并发访问。 Spark SQL 中默认实现是 SimpleFunctionRegistry ,其中采用 Map 数据结构注册了各种内置的函数。
• ExternalCatalog (外部系统 Catalog ):用来管理数据库(Databases )、数据表( Tables )、数据分区( Partitions )和函数(Functions )的接口 。其目标是与外部系统交互, Spark SQL 中,具体实现有 InMemoryCatalog 和HiveExternalCatalog 两种 ,前者将上述信息存储在内存中, 一般用于测试或比较简单的 SQL 处理;后者利用 Hive 原数据库来实现持久化的管理,在生产环境中广泛应用。
总体来看, SessionCatalog 是用于管理上述一切基本信息的入口。除上述的构造参数外,其 内部还包括一个 mutable 类型的 HashMap 用来管理临时表信息,以及 currentDb 成员变量用来指代当前操作所对应的数据库名称。
5.2 Rule体系
在Unresolved LogicalPlan 逻辑算子树的操作(绑定、解析、优化等)中,主要方法都是基于规则(Rule )的,通过 Scala 语言模式匹配机制(Pattern-match )进行树结构的转换或节点改写。
有了各种具体规则后,还需要驱动程序来调用这些规则,在 Catalyst 中这个功能由 RuleExecutor 提供 。凡是涉及树型结构的转换过程(Analyzer 逻辑算子树分析过程、 Optimizer 逻辑算子树的优化过程和后续物理算子树的生成过程等),都要实施规则匹配和节点处理,都继承自 RuleExecutor。
RuleExecutor 内部提供了 Seq[Batch ],里面定义的是该 RuleExecutor 的处理步骤。每个Batch 代表一套规则,配备一个策略,该策略说明了迭代次数( 一次还是多次)。
RuleExecutor的apply方法会按照 batches 顺序和 batch 内的 Rules 顺序,对传入的 plan里的节点进行迭代处理,处理逻辑由具体 Rule 子类实现。
5.3 Analyzed LogicalPlan的生成过程
类定义:org.apache.spark.sql.catalyst.analysis.Analyzer
Analyzer继承自 RuleExecutor 类,所以 Analyzer 执行过程会调用其父类中实现的run 方法,analyzer 定义了一系列规则,即 RunExecutor 类中的成员变量batches。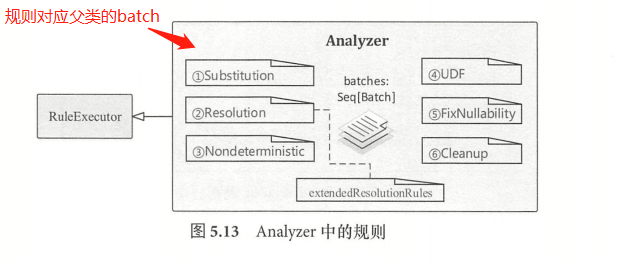
注:Spark 2.1 版本中, Analyzer 默认定义了6种Batch ,共有 34 条内置的规则外加额外实现的扩展规则(extendedResolutionRules)。
简单介绍一下这几种batch:
- Substitution
Substitution 含义是替换,因此这个Batch 对节点的作用类似于替换操作。 目前 包含4条规则,分别是 CTESubstitution、WindowsSubstitution、EliminateUnions、 和SubstituteUnresolvedOrdinals 。
- CTESubstitution : CTE 对应的是With语句,在 SQL 中主要用于子查询模块优化,因此该规则也就是用来处理 With 语旬的。 在遍历逻辑算子树的过程中,当匹配到With( child, relations )节点时,将子 LogicalPlan 替换成解析后的 CTE。 由于 CTE 的存在, SparkSqlParser 对SQL 语句从左向右解析后会 产生多个LogicalPlan ,这条规则的作用是将多个 LogicalPlan 合并成一个LogicalPlan。- WindowsSubstitution :对当前的逻辑算子树进行查找,当匹配到
WithWindowDefinition(windowDefinitions, child )表达式时,将其子节点
中未解析的窗口函数表达式(Unresolved-WindowExpression )转换成窗口
函数表达式(WindowExpression)。
- EliminateUnions :在 Union 算子节点只有一个子节点时, Union 操作实际上并没有起到作用,这种情况下需要消除该 Union 节点,该规则在遍历逻辑 子树过程中,匹配到Union( children )且 children 的数目只有一个时,将 Union(children)换为 children.head。- SubstituteUnresolvedOrdinals: 在Order By和Group By语句中支持用常数来表示列的下标,这种特性通过配置参数 spark.sql.orderByOrdinal 和spark.sql.groupByOrdinal 进行设置 ,默认都为 true 。这条规则的作用就根据这两个配置将下标替换成 UnresolvedOrdinal 达式,以映射到对应的列。
- Resolution
该Batch 中包含了 Analyzer 中最多同时也最常用的解析规则。表中规则从上到下被 RuleExecutor 执行。Resolution 中加入了 25 条分析规则,以及一个extendedResolutionRules扩展规则列表,扩展规则用来支持 Analyzer 子类添加新的分析规则。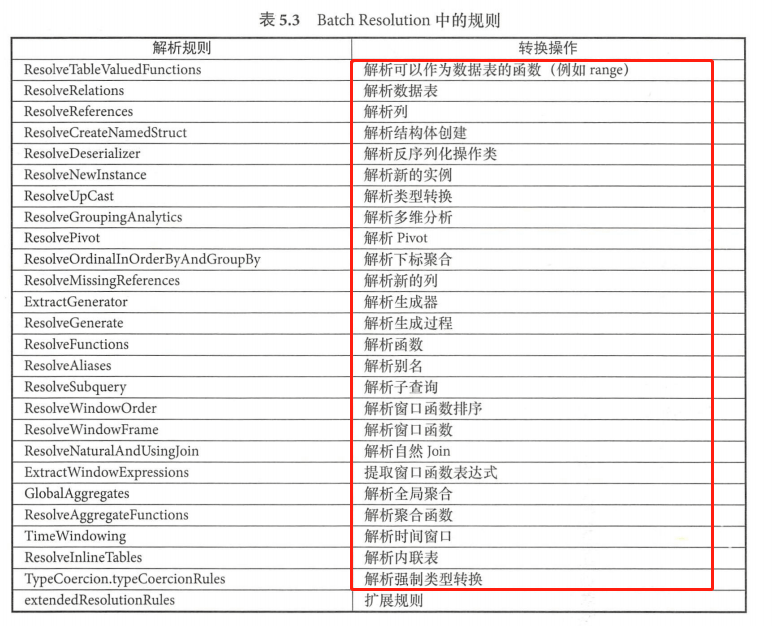
- Nondeterministic
该Batch 中仅包含 PullOutNondeterministic 这一条规则, 主要 将LogicalPlan 中非 Project或非 Filter 算子的 nondeterministic(不确定的)表达式提取出来,然后将这些表达式放在内层Project 算子中或最终的 Project 子中。
- UDF
该Batch 主要用来对用户自定义函数进行特别处理,该 Batch在Spark2.1 版本中仅有 HandlerNullinputsForUDF这一条规则,用来处理输入数据为 Null 的情形,其主要思想是从上至下进行表达式的遍历(transformExpressionsUp) , 当匹配到 ScalaUDF 类型的表达式时,会创建 If 表达式来进行 Null 值的检查。
- FixNullability
该Batch仅包含 FixNullability 这一条规则,用来统一设定 LogicalPlan 中表达式的 nullable属性。DataFrame 、Dataset 等编程接口中,用户代码对于某些列(AttribtueReference )可能会改变其 nullability 属性,导致后续的判断逻辑(如 isNull 过滤等)中出现异常结果。该规则对解析后的 LogicalPlan 执行 transformExpressions 操作,如果某列来自于其子节点,则其 nullability 值根据子节点对应的输出信息进行设置。
- Cleanup
该Batch 中仅包含 CleanupAliases 这一条规则,用来删除 LogicalPlan 中无用的别名信息。一般情况下,逻辑算子树中仅 Project 、Aggregate 、Window 算子的最高层表达式(分别对应 project list 、 aggregate expressions 和window expressions )才需要别名。 该规则通过 trimAliases 方法对表达式执行中的别名进行删除。
接下来介绍Analyzer 对Unresolved LogicalPlan进行分析的详细流程: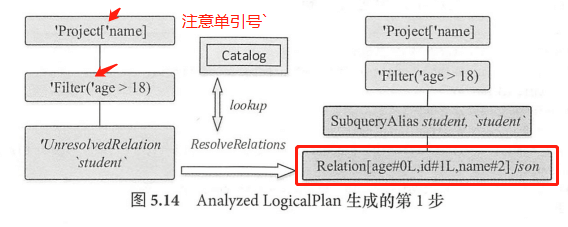
Analyzer 中首先匹配的是 ResolveRelations 规则,当遍历逻辑算子树的过程中匹配到 UnresolvedRelation 节点时,对于本例会直接调用lookupTableFromCatalog 方法从 SessionCatalog中查表。实际上,该表在上一步中就已经以 LogicalPlan 类型存储在InMemoryCatalog 中,因此 lookupTableFromCatalog 方法直接根据其表名即可得到分析后的 LogicalPlan。在 Catalog 查表后, Relation 节点上会插入一个别名节点。此外, Relation列后面的数字表示下标,注意其数据类型,age和id列都默认设定为 Long 类型(”L”字符)。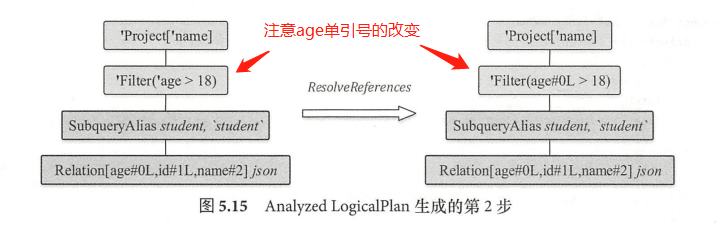
第二步执行 ResolveReferences 规则,得到的逻辑算子树如图 5.15 所示,可以看到,其他节点都不发生变化,主要是 Filter 节点中的 age 信息从 Unresolved 状态变成了Analyzed 状态(表示 Unresolved 状态的前缀字符单引号已经被去掉)。当碰到 UnresolvedAttribute 时,会调用 LogicalPlan 中定义的 resolve Children 方法对该表达式进行分析。需要注意的是, resolveChildren 并不能确保一次分析成功,在分析对应表达式时,需要根据该表达式所处LogicalPlan 节点的子节点输出信息进行判断。在对 Filter 表达式中的 age 属性进行分析时,Filter 的子节点Relation 已经处于 resolved 状态,因此可以成功;而在对 Project 中的表达式 name 属性进行分析时,因为 Project 的子节点filter此时仍然处于 unresolved 状态(注:虽然 age 列完成了分析,但是整个 Filter 节点中还有”18” 这个 Literal 常数表达式未被分析),因此解析操作无法成功,留待下一轮规则调用时再进行解析。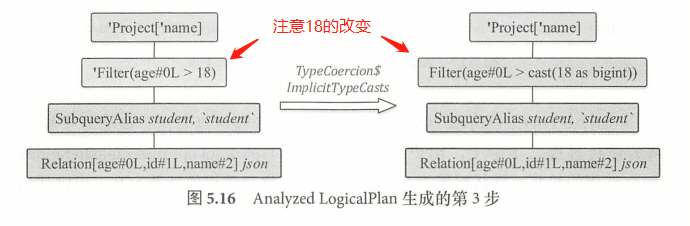
第三步调用 TypeCoercion 规则集中的 ImplicitTypeCasts 规则,对表达式中的数据类型进行隐式转换。如图 5.16 所示 ,因为在 Relation 中, age 列的数据类型为 Long ,而 Filter 中的数值 “18” 在 UnresolvedLogicalPlan 中生成的类型 IntegerType ,所以需要将 “18” 这个常数转换为 Long类型。
图中可以看到常数表达式 “18” 转换为 “cast( l8 as bigint )” 表达式(注:在 Spark SQL 类型系统中, Biglnt 对应Java中的 Long 类型) 。ImplicitTypeCasts 规则会匹配BinaryOperator表达式,该规则会调
findTightestCommonTypeOfTwo 找到对于左右表达式节点来讲最佳的共同数据类型 。经过该规则的解析操作 ,可以看到图中Filter节点已经变为 Analyzed 状态,节点字符前缀单引号已经被去掉。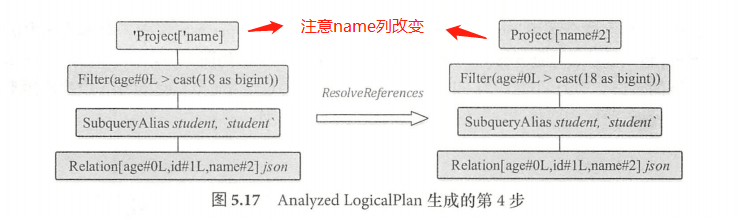
此时逻辑算子树中仍然存在 Project 节点未被解析,接下来会进行ResolveReferees 规则。Filter 节点已经处于 resolved 状态,因此逻辑算子树中的 Project节点能够完成解析。project节点的”name”被解析为 “name#2”,其中2表示 name 在所有列中的下标。
至此, Analyzed LogicalPlan 就完全生成了。可以看出,逻辑算子树的解析是一个不断的迭代的过程。实际上,用户可以通过参数(spark.sql.optimizer.maxIterations )设定RuleExecutor 迭代的轮数,默认配置为 50 轮,对于某些嵌套较深的特殊 SQL ,可以适当地增加轮数。
6. 优化器(Optimizer)
经过 Analyzer 的处理, UnresolvedLogicalPlan 已经解析成为 Analyzed LogicalPlan 。
Analyzed LogicalPlan 中自底向上节点分别对应 Relation, SubqueryAlias, Filter, Project 算子。 Analyzed LogicalPlan 基本上是根据 Unresolved LogicalPlan 一对一转换过来的,对于 SQL语句中的逻辑能够很好地表示。在实际应用中,很多低效的写法会带来执行效率的问题, 需要进一步对 Analyzed LogicalPlan 进行处理,得到更优的逻辑算子树,于是针对 SQL 逻辑算子树的优化器 Optimizer 应运而生。
6.1 Optimizer概述
Optimizer 同样继承自 RuleExecutor 类,与Analyzer 类似, Optimizer 的主要机制也依赖重新定义的系列规则,同样对应 RuleExecutor 类中的成员变量 batches ,因此在 RunExecutor 执行 execute 方法时会直接利用这些规则Batch。
SparkOptimizer 继承自 Optimizer ,Optimizer 本身定义了 12 个规则 Batch ,在 SparkOptimizer 类中又添加了4个 Batch。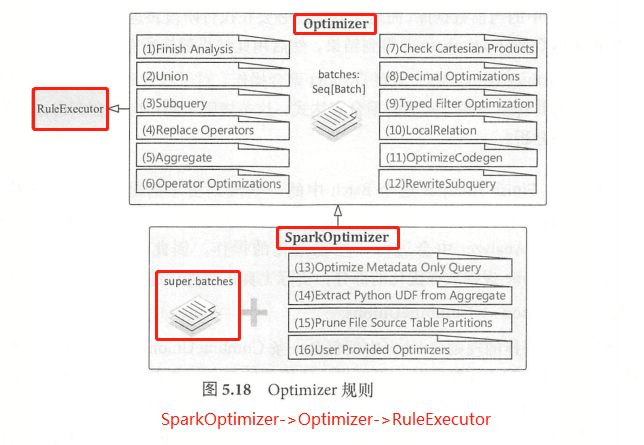
6.2 Optimizer规则体系
- Batch Finish Analysis
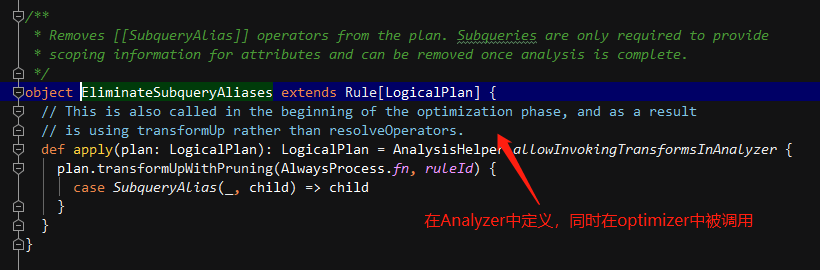
该Batch 包含5条优化规则,分别是 EliminateSubqueryAliases、ReplaceExpressions 、
ComputeCurrentTime、GetCurrentDatabase、RewriteDistinctAggregates,这些只执行一次。
- EliminateSubqueryAliases :消除子查询别名,对应逻辑算子树中的 SubqueryAlias 节点 。一般来讲,Subqueries 仅用于提供查询的视角范围(Scope)信息, 一旦 Analyzer 阶段结束, 该节点就可以被移除,该优化规则直接将 SubqueryAlias 替换为其子节点。- ReplaceExpressions :表达式替换,在逻辑算子树中查找匹配 RuntimeReplaceable 表达式并将其替换为能够执行的正常表达式。这条规则通常用来对其他类型的数据库提供兼容的能力,例如,可以用"coalesce"来替换支持"nvl"的表达式。- ComputeCurrentTime :计算与当前时间相关的表达式,在同一条 SQL 语句中可能包含多个计算时间的表达式,即 CurrentDate 和 CurrentTimestamp ,且该表达式出现在多个语句中,为避免不一致, ComputeCurrentTime 对逻辑算子树中的时间函数计算一次后,将其他同样的函数替换成该计算结果。- GetCurrentDatabase :获取当前数据库,在 SQL中可能会调用 CurrentDatabase 函数来获取Catalog 中的当前数据库,而这个方法没必要在执行阶段再进行计算。GetCurrentDatabase规则执行 CurrentDatabase 并得到结果,然后用此结果替换所有的 CurrentDatabase 表达式。- RewriteDistinctAggregates :重写 Distinct 聚合操作,对于包含Distinct 算子的聚合语句,这条规则将其转换为两个常规的聚合表达式 ,这条规则主要面向聚合查询。
严格来讲, Finish Analysis 这个Batch中的一些规则更多的是为了得到正确的结果(例如ComputeCurrentTime),并不涉及优化操作,实际上真正的优化过程从以下 Batch 开始。
- Batch Union => CombineUnions
针对 Union 操作的规则 Batch ,中间包含一条 CombineUnions 优化规则。在逻辑算子树中,当相邻的节点都是 Union 算子时,可以将这些相邻的 Union 节点合并为一个 Union 节点 。在该 规则中, flattenUnion 是核心方法,用栈实现了节点的合井。需要注意的是,后续的优化操作可能会将原来不相邻的 Union 节点变得相邻,因此在后面的规则 Batch 中又加入CombineUnions 这条规则。
- Batch Subquery => OptimizeSubqueries
该Batch目前只包含 OptimizeSubqueries 这一条规则,SQL 包含子查询时,会在逻辑算子树上生成 SubqueryExpression 表达式 。OptimizeSubqueries 优化规则在遇到 SubqueryExpression 表达式时,进一步递归调用 Optimizer 对该表达式的子计划并进行优化。
- Batch Replace Operators
该Batch 中的优化规则主要用来执行算子的替换操作,SQL 语句中,某些查询算子可以直接改写为已有的算子,避免进行重复的逻辑转换,主要针对的是集合类型的操作算子。
Replace Operators 中包含ReplacelntersectWithSemiJoin、 ReplaceExceptWithAntiJoin、ReplaceDistinctWithAggregate 这三条优化规则:
- ReplacelntersectWithSemiJoin :将 Intersect 操作算子替换为Left Semi Join 操作算子,从逻辑上来看,这两种算子是等价的。需要注意的是, ReplacelntersectWithSemiJoin 优化规则仅适用于 INTERSECT DISTINCT 类型的语句,而不适用于 INTERSECT ALL 语句。此外,该优化规则执行之前必须消除重复的属性,避免生成的 Join 条件不正确。- ReplaceExceptWithAntiJoin :将 Except 操作算子替换为 Left Anti Join 操作算子,从逻辑上来看,这两种算子是等价的。ReplaceExceptWithAntiJoin 优化规则仅适用于 EXCEPT DISTINCT 类型的语句,而不适用于 EXCEPT ALL 语句。此外,该优化规则执行之前必须消除重复的属性,避免生成的 Join 条件不正确。- ReplaceDistinctWithAggregate :该优化规则会将 Distinct 算子转换为 Aggregate 语句。在SQL 语句中,Select 直接进行 Distinct 操作,这种情况下可将其直接转换为聚合操作。 ReplaceDistinctWithAggregate 规则会将 Distinct 算子替换为对应的 Group By 语句。
- Batch Aggregate
该Batch主要用来处理聚合算子中的逻辑,包括 RemoveLiteralFromGroupExpressions 、
RemoveRepetitionFromGroupExpressions 两条规则。RemoveLiteralFromGroupExpressions 优化规则用来删除 Group By 语句中的常数,这些常数对于结果无影响,但是会导致分组数目变多。 此外,如果 Group By 语句中全部是常数,则会将其替换为一个简单的常数 0 表达式。RemoveRepetitionFromGroupExpressions 优化规则将重复的表达式从 Group By 话句中删除,同样对结果无影响。
- Batch Operator Optimizations
类似 Analyzer 中的 Operator 解析规则,该Batch包含了 Optimizer 中数量最多同时也是最常用的各种优化规则,共 31 条优化规则,可分为三个模块:算子下推( Operator Push Down )、算子组合( Operator Combine )、常量折叠与长度削减 (Constant Folding and Strength Reduction)。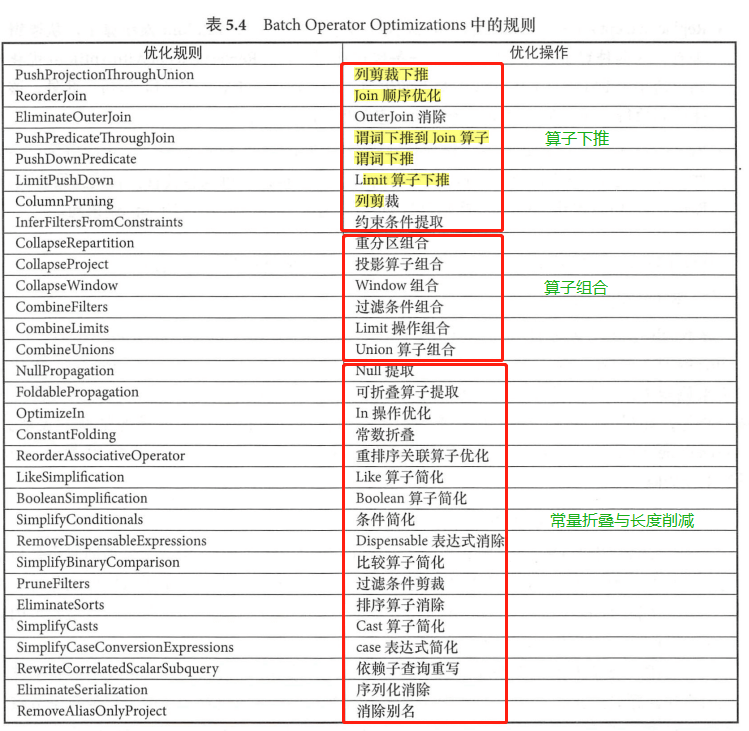
算子下推 :算子下推是数据库中常用的优化方式,表中所列的前 8 条规则都属于算子下推的模块 。算子下推所执行的优化操作主要是将逻辑算子树中上层的算子节点尽量下推 ,使其靠近叶子节点,这样能够在不同程度上减少后续处理的数据量甚至简化后续的处理逻辑。 以常见的列剪裁(ColumnPruning)为例,假设数据表中有A、B、C三列,但是查询语句中只涉及两列,那么 ColumnPruning 将会在读取数据后剪裁出这两列 。又如LimitPushDown 优化规则,能够将 LocalLimit 算子下推到 Union All 和 Outer Join 操作算子的下方,减少这两种算子在实际计算过程中需要处理的数据量。
算子组合 :算子组合类型的优化规则将逻辑算子树中能够进行组合的算子尽量整合在一起, 避免多次计算,以提高性能 。表中间 6条规则(从 CollapseRepartition 到 CombineUnions )都属于算子组合类型的优化 。这些规则主要针对的是重分区算子(repartition )、投影算子 (Project )、过滤算子( Filter )、 Window 算子、 Limit 算子和 Union 算子,其中CombineUnions在之前已经提到过。需要注意的是,这些规则主要针对的是算子相邻的情况。
常量折叠与长度削减:对于逻辑算子树中涉及某些常量的节点,可以在实际执行之前就完成静态处理,表后 17 条优化规则都属于这种类型。 例如,在 ConstantFolding 规则中,对于能够 foldable (可折叠 )的表达式会直接 EmptyRow 上执行 evaluate 操作,从而构造新的 Literal 表达式; PruneFilters 规则会详细地分析过滤条件,对总是能够返回 true或false 的过滤条件进行特别的处理。
- Batch Check Cartesian Products =>CheckCartesianProducts
该Batch 只有 CheckCartesianProducts 这一条优化规则,用来检测逻辑算子树中是否存在笛 卡儿积类型的 Join 操作 。如果有,而 SQL 语句中没有显示地使用 cross join 表达式,则会抛出异常 。CheckCartesianProducts 规则必须在 ReorderJoin 规则执行之后才能执行,确保所有的 Join 条件收集完毕。当”spark.sql.crossJoin.enabled”参数设置为 true时,该规则会被忽略。
- Batch Decimal Optimizations => DecimalAggregates
该Batch 只有 DecimalAggregates 这一条优化规则,用于处理聚合操作中与 Decimal 类型相 关的问题。一般情况下,如果聚合查询中涉及浮点数的精度处理,性能就会受到很大的影响。 对于固定精度的 Decimal 类型, DecimalAggregates 规则将其当作 unscaled Long 类型来执行,这 样可以加速聚合操作的速度。
- Batch Typed Filter Optimization => CombineTypedFilters
该Batch仅包含 CombineTypedFilters 这一条优化规则,用来对特定情况下的过滤条件进行合并。当逻辑算子树中存在两个 TypedFilter 过滤条件且针对相同类型的对象条件时, CombineTypedFilters 优化规则会将它们合并到同一个过滤函数中。
- Batch LocalRelation =>ConvertToLocalRelation I PropagateEmptyRelation
该Batch主要用来优化与 LocalRelation 相关的逻辑算子树,包含 ConvertToLocalRelation 和PropagateEmptyRelation 两条优化规则 。ConvertToLocalRelation 将 LocalRelation 上的本地操作 (不涉及数据交互)转换为另一个 LocalRelation ,目前该规则实现较为简单,仅处理 Project 投影操作 。PropagateEmptyRelation 优化规则会将包含空的 LocalRelation 进行折叠。
- Batch OptimizeCodegen => OptimizeCodegen
该Batch只有OptimizeCodegen一条优化规则,用来对生成的代码进行优化。代码生成技术会在Tungsten 章节中介绍。 OptimizeCodegen 规则主要针对的是 case when 语句,当 case when 语句中的分支数目不超过配置中的最大数目时,该表达式才能执行代码生成 。
- Batch RewriteSubquery => RewritePredicateSubquery I CollapseProject
该Batch 主要用来优化子查询,目前包含RewritePredicateSubquery和CollapseProject 两条优化规则。RewritePredicateSubquery 将特定的子查询谓词逻辑转换为 left semi/anti join 操作。其中, EXISTS 和 NOT EXISTS 算子分别对应 semi 和 anti 类型的 Join ,过滤条件会被当作 Join 的条件; IN 和 NOT IN 也分别对 semi 和 anti 类型的 Join ,过滤条件和选择的列都会被当作 join条件。 CollapseProject 优化规则比较简单,会将两个相邻的Project 算子组合在一起并执行别名替换,整合成一个统一的表达式。
- Batch Optimize Metadata Only Query OptimizeMetadataOnlyQuery
该Batch 仅执行一次,只有OptimizeMetadataOnlyQuery 这一条规则,用来优化执行过程中只需查找分区级别元数据的语句。该优化规则适用于扫描的所有列都是分区列且包含聚合算子的情形,而且聚合算子需要满足以下情况之一 :
聚合表达式是分区列;
分区列的聚合函数有 DISTINCT 算子;
分区列的聚合函数中是否有 DISTINCT算子不影响结果;
- Batch Extract Python UDF from Aggregate => ExtractPyhonUDFFromAggregate
该Batch 仅执行一次,只有 ExtractPythonUDFFromAggregate 这一条规则,用来提取出聚合操作中的 Python UDF 函数。该规则主要针对的是采用 PySpark 提交查询的情形,将参与聚合的 Python 自定义函数提取出来,在聚合操作完成之后再执行。
- Batch Prune File Source Table Partitions PruneFileSourcePartitions
该Batch 仅执行一次,只有 PruneFileSourcePartitions 这一条规则,用来对数据文件中的分区进行剪裁操作。当数据文件中定义了分区信息且逻辑算子树中的 LogicalRelation 节点上方存在过滤算子时, PruneFileSourcePartitions 优化规则会尽可能地将过滤算子下推到存储层,这样可以避免读入无关的数据分区。
- Batch User Provided Optimizers ExperimentalMethods.extraOptimizations
该 Batch 用于支持用户自定义的优化规则,其中 ExperimentalMethods的extraOptimizations 队列默认为空。可以看到, Spark SQL 在逻辑算子树的转换阶段是高度可扩展的,用户只需要继承 Rule [LogicalPlan ]虚类,实现相应的转换逻辑就可以注册到优化规则队列中应用执行。
6.3 Optimized LogicalPlan 的生成过程
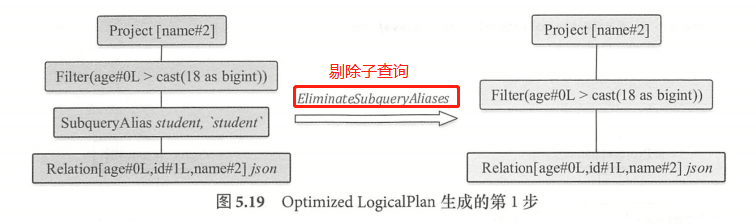
对于之前案例生成的 Analyzed LogicalPlan ,首先执行的是 Finish Analysis 这个 Batch 中的
EliminateSubqueryAliases 优化规则,用来消除子查询别名的情形,该规则直接将 SubqueryAlias 逻辑算子树节点替换为其子节点 。经过 EliminateSubqueryAliases 规则优化后,SubqueryAlias 节点被删除,Filter 节点直接作用Relation 节点 。
第二步优化将匹配 OperatorOptimizations 这个 Batch 中的 InferFiltersFromConstraints 优化规则,用来增加过滤条件。 该优化规则会对当前节点的约束条件进行分析,生成额外的过滤条件列表,这些过滤条件不会与当前算子或其子节点现有的过滤条件重复。
该规则针对上步生成的逻辑算子树中的 Filter 节点,会构造新的过滤条件(newFilter ),当新的过滤条件不为空时,会与现有的过滤条件进行整合,构造新的 Filter 逻辑算子节点 。如图 所示, Filter 逻辑算子 树节点中多了 “isnotnull(age#OL)” 这个过滤条件 ,该过滤条件来自于 Filter 中的约束信息,用来
确保筛选出来的数据 age 字段不为 null 。
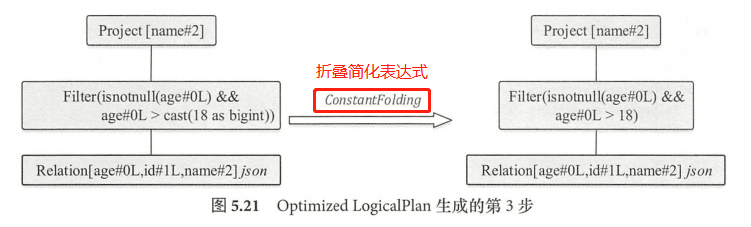
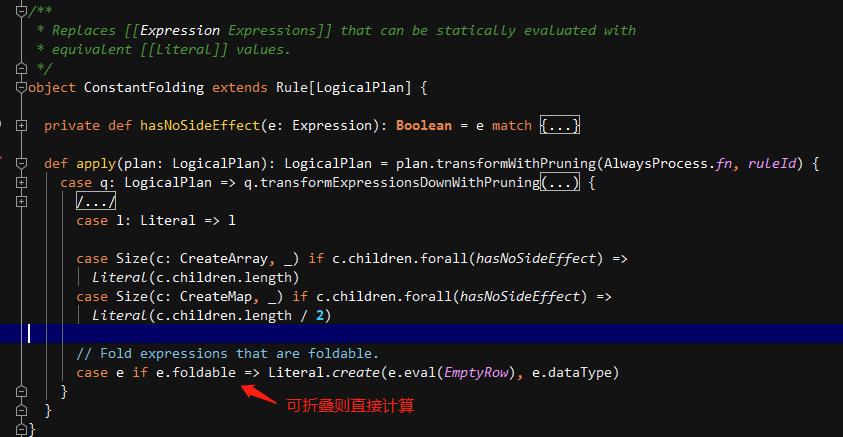
最后一步,逻辑算子树会匹配 OperatorOptimizations 这个 Batch 中的 ConstantFolding优化规则,对 LogicalPlan 中可以折叠的表达式进行静态计算直接得到结果,简化表达式。ConstantFolding 规则中,如果 LogicalPlan 中的表达式可以折叠(foldable true ),那么会将 EmptyRow 作为参数传递到其 eval 方法中直接计算,然后根据计算结果构造 Literal 常量表达式。
可见, Filter 过滤条件中的 “cast(18 as bigint)” 表达式经过计算成为 “Literal(l8,bigint )” 表达式,即输出的结果为 18 。在原来的 Cast 表达式中,其子节点 Literal 表达式的 foldable 值为 true,因此 Cast 表达式本身的 foldable 值也为 true ,在匹配该优化规则时, Cast 表达式会被直接计算 。
经过上述步骤, SparkSQL 逻辑算子树生成、分析与优化的整个阶段都执行完毕 ,最终生成的逻辑算子树包含 Relation 节点、 Filter 点和 Project 节点 ,同时每个节点中又包含了由对应表达式构成的树 。这棵逻辑算子树将作为 Spark SQL 中生成物理算子树的输入,并开始物理计划的阶段。
7. 物理计划(PhysicalPlan/SparkPlan)
物理计划阶段是 Spark SQL 整个查询处理流程的最后一个阶段,不同于逻辑计划(LogicalPlan)的平台无关性,物理计划(PhysicalPlan )是与底层平台紧密相关的。 在此阶段, Spark SQL 会对生成的逻辑算子树进一步处理,得到物理算子树,并将 LogicalPlan 节点及其所包含的各种信息映射成 Spark Core 计算模型的元素,如 RDD 、Transformation和Action 等,以支持其提交执行。
7.1 SparkPlan概述
SparkSQL 中,物理计划用 SparkPlan 表示,从 Optimized LogicalPlan 传入到 SparkSQL 物理计划提交并执行,主要经过3个阶段,分别产生 Iterator [PhysicalPlan]、SparkPlan、PreparedSparkPlan ,其中 Prepared SparkPlan 可以直接提交并执行(注:这里的PhysicalPlan和SparkPlan均表示物理计划)。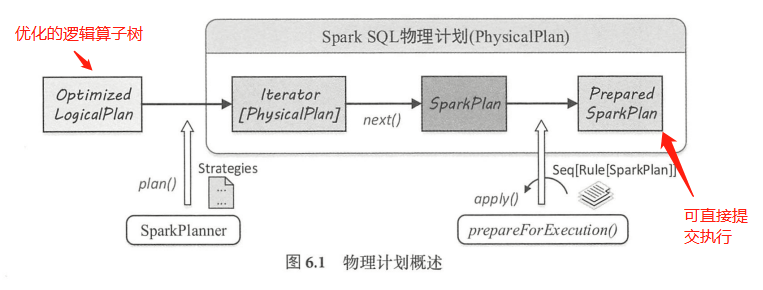
- SparkPlanner 将各种物理计划策略(Strategy )作用于对应的 LogicalPlan 节点上,生成SparkPlan 列表(注:一个LogicalPlan 可能产生多种 SparkPlan)。
- 选取最佳的 SparkPlan ,在 Spark2.1 版本中的实现较为简单,在候选列表中直接用 next() 方法获取第一个。
提交前进行准备工作,进行一些分区排序方面的处理,确保 SparkPlan 各节点能够正确执行,这一步通过 prepareForExecution方法调用若干规则(Rule )进行转换。
7.2 SparkPlan简介
Spark SQL 最终将 SQL 语句经过逻辑算子树转换成物理算子树。在物理算子树中,叶子类型的 SparkPlan 节点负责 “从无到有” 的创建 RDD ,每个非叶子类型的 SparkPlan 节点等价于在RDD 上进行一次 Transformation ,即通过调用 execute 函数转换成新的 RDD ,最终执行 collect 操作触发计算,返回结果给用户。
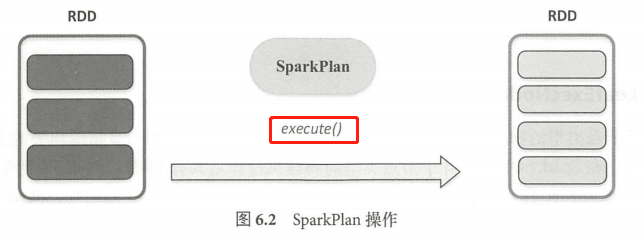
SprkPlan 在对RDD执行Transformation 的过程中,除对数据进行操作外,还可能对 RDD 的分区做调整 。此外, SparkPlan 除实现 execute 方法外,还有一种情况是直接执行 executeBroadcast 方法,将数据广播到集群上。
SparkPlan 的主要功能可以划分为3大块 。首先,每个 SparkPlan 节点必不可少地会记录其元数据(Metadata )与指标(Metric )信息,这些信息以 Key-Value 的形式保存在 Map 数据结构中,统称为 SparkPlan Metadata Metric 体系 。其次,在对 RDD 进行 Transformation 操作时,会涉及数据分区(Partitioning )与排序( Ordering )处理,称为 SparkPlan PartitioningOrdering 体系;最后,SparkPlan 作为物理计划,支持提交到 Spark Core 去执行,即 SparkPlan 的执行操作部分,以 execute 及executeBroadcast 方法为主。
Spark 2.1 版本中, Spark SQL 大约包含 65 种具体的 SparkPlan 实现,涉及数据源 RDD
创建和各种数据处理等 。根据 SparkPlan 的子节点数目,可以大致将其分为4类,分别为 LeafExecNode、UnaryExecNode、binaryExecNode 和其他不属于这3种子节点的类型。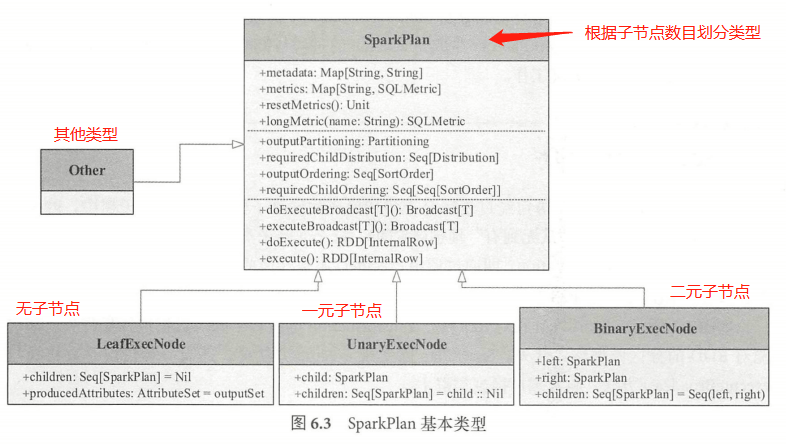
LeafExecNode(叶子执行节点)
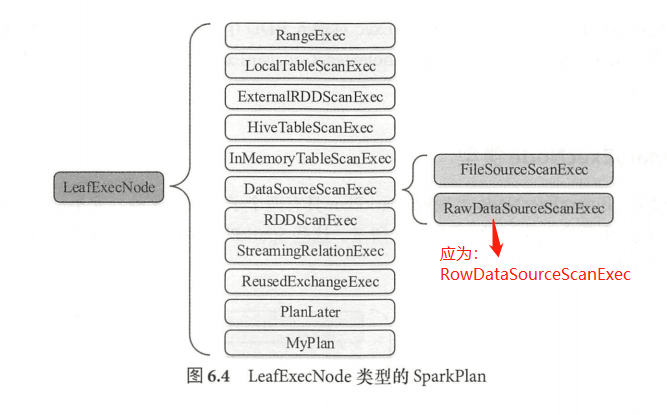
叶子节点类型的物理执行计划不存在子节点。物理执行计划中与数据源相关的节点都属于该类型。 Spark SQL 中,叶子节点类型的物理执行计划共有 13 种,如图示, DataSourceScanExec 作为基类,具体的实现包括 FileSourceScanExec 、RawDataSourceScanExec 两种。 LeafExecNode 类型的 SparkPlan 负责对初始 RDD 的创建 。例如, RangeExec 会利用 SparkContext 中的 parallelize 方法生成给定范围内的 64 位数据的 RDD, HiveTableScanExec 会根据 Hive 数据表存储的 HDFS 信息直接生成 HadoopRDD, FileSourceScanExec 根据数据表所在的源文件生成 FileScanRDD。
- UnaryExecNode(一元执行节点)
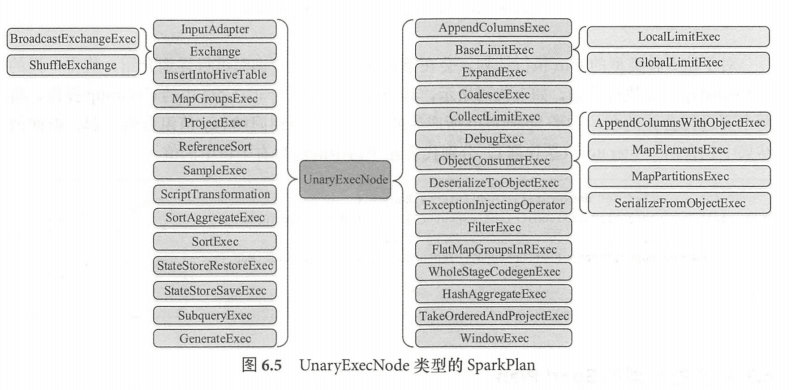
UnaryExecNode 类型的物理执行计划的节点是一元的, 只包含一个子节点 ,该类型的物理计划也是数量最多的。UnaryExecNode 节点的作用主要是对 RDD 进行转换操作。 例如,生成的物理算子树中, ProjectExec 、FilterExec 分别对子节点产生的 RDD 进行列剪裁与行过滤操作。Exchange 负责对数据进行重分区, SampleExec 对输入 RDD 中的数据进行采样, SortExec 按照一定条件对输入 RDD 中数据进行排序, WholeStageCodegenExec 类型的 SparkPlan 将生成的代码整合成单个 Java 函数。
- BinaryExecNode(二元执行节点)
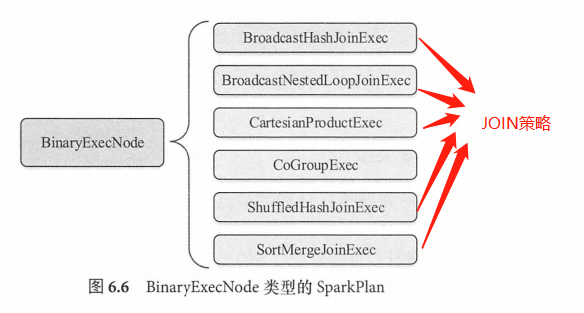
BinaryExecNode 类型的 SparkPlan 具有两个子节点,这些 SparkPlan 中除 CoGroupExec 外,其余的
种都是不同类型的 Join 执行计划。CoGroupExec 执行计划,其处理逻辑类似 SparkCore 中的 CoGroup算子,将要进行合并的左、右两个子SparkPlan 所产生的 RDD ,按照相同的 key 值组合一起,返回的结果中包含两个Iterator (迭代器),分别代表左子树中的值与右子树中的值。
- Other(其他类型节点)
SparkSQL 中还有 11 个其他类型的物理执行计划 ,除 CodeGenSupport (向量支持)、UnionExec (union操作)外,其他几种用到的场景并不多见。
7.3 Metadata 及 Metrics 体系
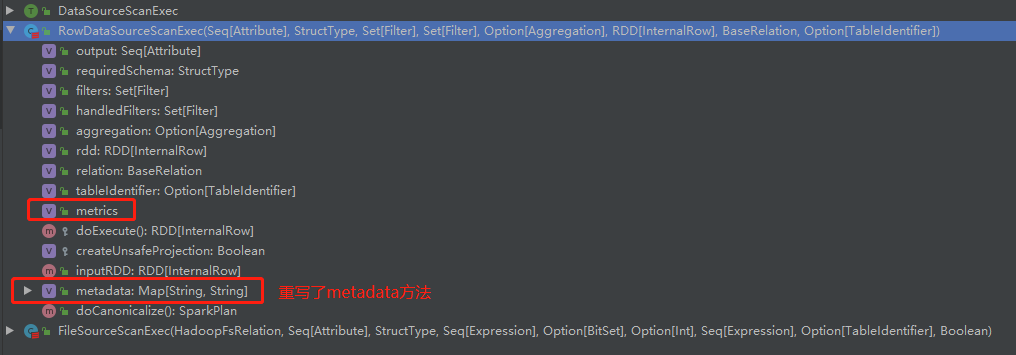
元数据和指标信息是性能优化的基础, SparkPlan 提供了 Map 类型的数据结构来存储相关信息,以便更加详细地刻画 SparkPlan 的细节。默认情况下, SparkPlan 中这两个 Map 的值均为空。Metadata 对应的Map 中的 key-value 都为字符串类型。一般情况下,元数据主要用于描述数据源的一些基本信息,例如数据文件的格式、存储路径等。目前只有FileSourceScanExec和RowDataSourceScanExec 两种。叶子节点类型的 SparkPlan 对其进行了重写实现。Metrics 对应 Map 中的 key 为字符串类型,而 value 部分是 SQLMetrics 类型。在Spark 执行过程中, Metrics 能够记录各种信息,为应用的诊断和优化提供基础,目前, SparkSQL 中共有 27 SparkPlan 重载实现了该方法。例如, FilterExec 中添加了numOutputRows指标, 记录输出的数据数目,该指标会随着对应的 SparkPlan 执行而计算; ShuffieExchange 中添加了
dataSize指标,能够记录进行重新分区操作过程中的数据总量。
7.4 Partitioning 及 Ordering 体系
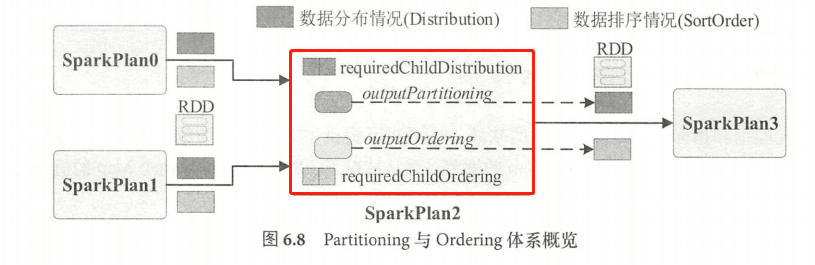
RDD 开发的中的分区( Partitioning )和排序( Ordering )相关的操作一直都是较为重要的内容。除涉及正确性外,分区的策略还对集群资源和应用性能有着重要的影响。
如图所示, Partitioning及Ordering 体系可以概括为”承前启后”,”承前”体现在对输入数据特性的需求上, requiredChildDistribution 及requiredChildOrdering 分别规定了当前 SparkPlan所需的数据分布和数据排序方式列表,本质上是对所有子节点输出数据(RDD )的约束。 假设图中的 SparkPlan2为Hash 类型的 Join ,那么SparkPlan0及SparkPlan1 就都是基于相同 key 的哈希分布;如果是 Broadcast 类型的 Join ,那么其中必有1个为广播变量数据分布。”启后”体现在对输出数据的操作上, outputPartitioning 定义了当前 SparkPlan 对输出数据(RDD) 的分区操作, outputOrdering 则定义了每个数据分区的排序方式。
7.4.1 Distribution及Partitioning 的概念
在SparkPlan 分区体系实现中,Partitioning 表示对数据进行分区的操作, Distribution 则表示数据的分布。 SparkSQL的Distribution及Partitioning 均被定义为接口,其有不同的具体实现。
- Distribution
Distribution 定义了查询执行时,同1个表达式下的不同数据元组(Tuple )在集群各个节点上的分布情况。具体来讲, Distribution 可以用来描述以下两种不同粒度的数据特征:
- 节点间(Inter-node )分区信息,即数据元组在集群不同的物理节点上是如何分区的。这个特性可以用来判断某些算子(例如 Aggregate )能否进行局部计算( Partial operation ),避免全局操作的代价。
- 分区数据内(Intra-partition )排序信息,即单个分区内数据是如何分布的。具体实现如下:
- UnspecifiedDistribution :未指定分布,无需确定数据元组之间的位置关系。
- AllTuples :只有一个分区,所有的数据元组存放在一起( Co-located)。例如,选取全局前K条数据的 GlobalLimit 算子, requiredChildDistribution 得到的列表就是[AllTuples ],表示执行该算子需要全部的数据参与。
- BroadcastDistribution :广播分布,数据会被广播到所有节点上,构造参数 mode 为广播模式 (BroadcastMode ),广播模式可以为原始数据( IdentityBroadcastMode )或转换为 HashedRelation 对象(HashedRelationBroadcastMode)。 例如,如果是 Broadcast 类型的 Join 操作,假设左表做广播,那么 requiredChildDistribution 得到的列表就是[BroadcastDistribution(mode) , UnspecedDistribution ],表示左表为广播分布。
- ClusteredDistution :构造参数 clustering是Seq [Expression ]类型,起到了哈希函数的效果, 数据经过 clustering 计算后,相同 value 的数据元组会被存放在 起( Co-located )。如果有多个分区的情况,则相同数据会被存放在同一个分区中;如果只能是单个分区,则相同的数据会在分区内连续存放。例如, SortMerge 类型的 Join 操作中 requiredChildDistribution 列表就是[ClusteredDistribution(leftKeys ), ClusteredDistribution(rightKeys )], 表示左表数据根据 leftKeys 表达式计算分区,右表数据根据 rightKeys 表达式计算分区。
- OrderedDistribution :构造参数 ordering是Seq[SortOrder]类型,该分布意味着数据元组根据 ordering 计算后的结果排序。例如,全局排序的 Sort 算子中的requiredChildDistribution 得到的列表是[OrderedDistribution( sortOrder)] ,其中 sortOrder 是排序表达式。OrderedDistribution 相对 ClusteredDistribution 来讲要强一些,相同的数据 ordering 计算结 果相同,因此能够保持连续性并被划分到相同分区中。
- Partitioning
定义了一个物理算子输出数据的分区方式,具体包括子Partitioning 之间、目标Partitioning 和Distribution 之间的关系。具体来讲, Partitioning 描述了 SparkPlan 中进行分区的操作,类似直接采用 API 进行 RDD repartition 操作。Partitioning 接口中包含1个成员变量和 3个函数来进行分区操作。
- numPartitions :指定该 SparkPlan 输出 RDD 的分区数目。
- satisfies(required: Distribution):当前Partitioning操作能否得到所需数据分布(Required)。 当不满足时(结果为 false ), 一般需要进行 repartition 操作,对数据进行重新组织。
- compatibleWith(other: Partitioning):当存在多个子节点时,需要判断不同的子节点的分区操作是否兼容。直观地看,只有当两个 Partitioning 能够将相同 key 的数据分发到相同的分区时,才能够兼容。
guarantees(other: Partitioning):如果A.guarantees(B) 为真,那么任何A进行分区操作所产生的数据行也能够被B产生。这样, 就不需要再进行重分区操作。该方法主要用来避免冗余的重分区操作带来的性能代价。在默认情况下, 一个Partitioning 仅能够 gurantee(保证)等于它本身的 Partitioning (相同的分区数目和相同的分区策略等)。
7.4.2 SparkPlan 的常用分区排序操作
作为抽象类,在 SparkPlan 默认实现中,将 OutputPartitioning 设置为 UnknownPartitioning(0),将requiredChildDistribution设置为Seq[UnspecifiedDistribution ],且在数据有序性和排序操作方面不涉及任何动作。
数据文件扫描执行算子(FileSourceScanExec)
作为物理执行树中的叶子节点, FileSourceScanExec中分区排序信息会根据数据文件构造的初始的RDD进行设置。如果没有bucket信息,则分区与排序操作将分别为最简单的 UnknownPartitioning 与Nil;当且仅当输入文件信息中满足特定的条件(代码中的 sortColumns 非空等)时,才会构造HashPartitioning与SortOrder类。
- 过滤执行算子(FilterExec )与列剪裁执行算子(ProjectExec)
在过滤执行算子与列剪裁执行算子中 ,分区与排序的方式仍然沿用其子节点的方式,即不对 RDD 的分区与排序进行任何的重新操作。
通常情况, LeafExecNode 类型的 SparkPlan 会根据数据源本身特点(包括分块信息和数据有序性特征)构造 RDD 与对应的Partitioning和Ordering方式;UnaryExecNode 类型的SparkPlan 大部分会沿用其子节点的Partitioning和Ordering方式(SortExec 等本身具有排序操作的执行算子例外);BinaryExecNode 往往会根据两个子节点的情况综合考虑,具体可以参SortMergeJoinExec 等执行算子的源码实现。 SparkPlan的Partitioning 体系和 Exchange 节点息息相关,用于 SparkPlan 执行前的准备。
7.5 SparkPlan 生成
Spark SQL 中,当逻辑计划处理完毕后,会构造 SparkPlanner 并执行 plan() 方法对
LogicalPlan 进行处理,得到对应的物理计划 。实际上, 一个逻辑计划可能会对应多个物理计划,
因此, SparkPlanner 得到的是一个物理计划的列表 (Iterator[SparkPlan])。
SparkPlanner 继承自 SparkStrategie 类,而 SparkStrategies 类则继承自 QueryPlanner 基类,重要的 plan() 方法实现就在 QueryPlanner 类中。 SparkStrategies 类本身不提供任何方法,而是在内部提供一批
SparkPlanner 会用到的各种策略( Strategy)实现。最后 ,在 SparkPlanner 层面将这些策略整合在一起,通过 plan ()方法进行逐个应用。
类似逻辑计划阶段的 Anaylzer 和 Optimizer, SparkPlanner 本身只是一个逻辑的驱动。各种策略的 apply() 方法把逻辑执行计划算子映射成物理执行计划算子 。在SparkPlanner 的调用逻辑和各种策略中, PlanLater 随处可见。根据其实现, PlanLater 本身也是 SparkPlan 的一种,区别在于doExecute() 方法没有实现,表示不支持执行,所起到的作用仅仅是占位,等待后续处理。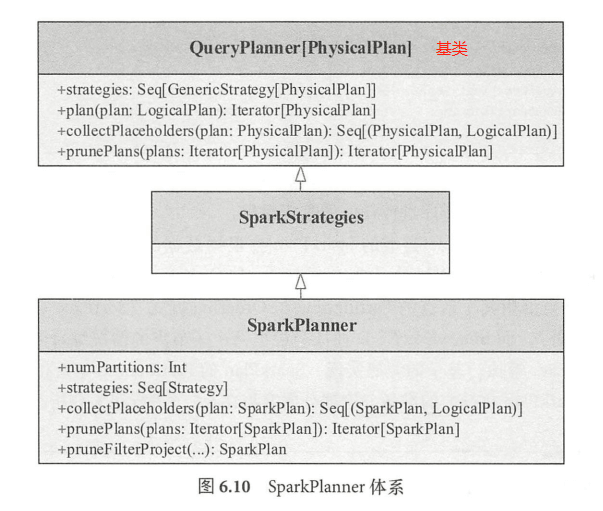
生成物理计划的实现如下, plan() 方法传入LogicalPlan 作为参数 ,将Strategies 应用到LogicalPlan ,生成物理计划候选集合(Candidates)。 如果集合存在 PlanLater 类型的SparkPlan,则通过 placeholder 中间变量取出对应的 LogicalPlan 后,递归调用 plan() 方法,将PlanLater 替换为子节点的物理计划。最后,对物理计划列表进行过滤,去掉一些不够高效的物理计划。
代码地址:org.apache.spark.sql.catalyst.planning.QueryPlanner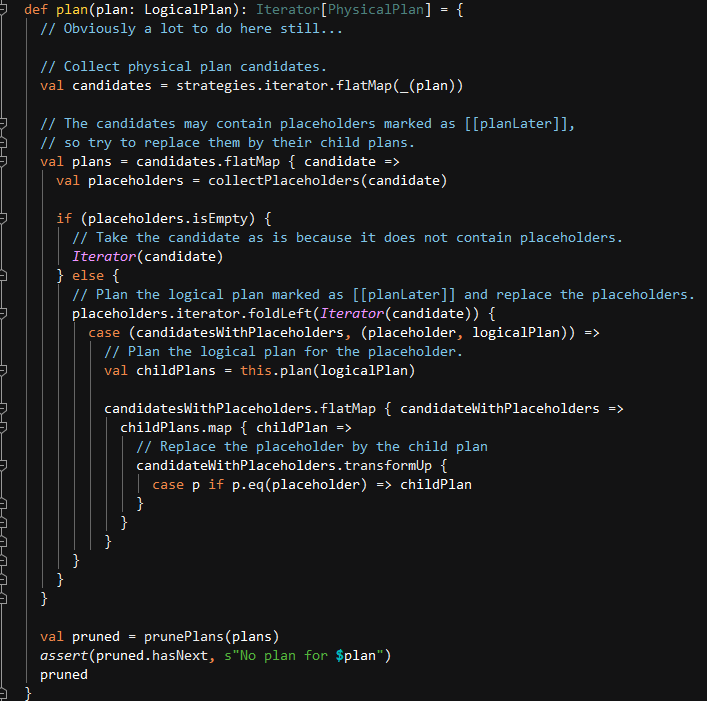
代码地址:org.apache.spark.sql.execution.QueryExecution 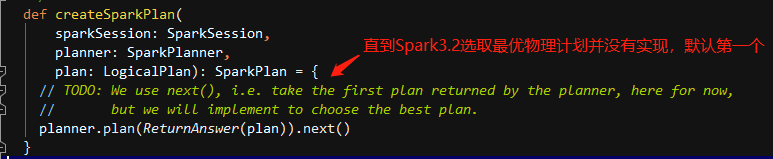
实际上, SparkSQL 在物理计划生成方面还有很多工作要做,例如,对生成的物理计划列表
进行过滤筛选(prunePlans )在当前版本中并没有实现,生成多个物理计划后,仅仅是直接选取
列表中的第一个作为最终结果。
7.5.1 物理计划 Strategy 体系

物理计划执行的所有策略都继承自 GenericStrategy 类,其中定义了planLater 和 apply 方法; SparkStrategy 继承自 GenericStrategy 类,对其中的 planLater 进行了实现,根据传入的 LogicalPlan 直接生成 PlanLater 节点。此外,在 Spark SQL 中,Strategy 是 SparkStrategy 类的别名。
最后,各种具体的 Strategy 都实现了 apply 方法,将传入的 LogicalPlan 转换为 sparkPlan列表。 如果当前的执行策略无法应用于该 LogicalPlan 节点,则返回的物理执行计划列表为空。因此,Strategy 是生成物理算子树的基础。
在实现上,各种 Strategy 会匹配传入的 LogicalPlan 节点,根据节点或节点组合的不同情形实行一对一的映射或多对一的映射。一对一的映射方式比较直观,以 BasicOperators 为例,该Strategy 实现了各种基本操作的转换, 其中列出了大量的映射关系,包括 Sort 对应 SortExec、Union 对应 UnionExec等。多对一的情况涉及对多个LogicalPlan 节点组合转换,这里称为逻辑算子树的模式匹配 。目前在 Spark SQL 中,逻辑算子树的节点模式共有4种。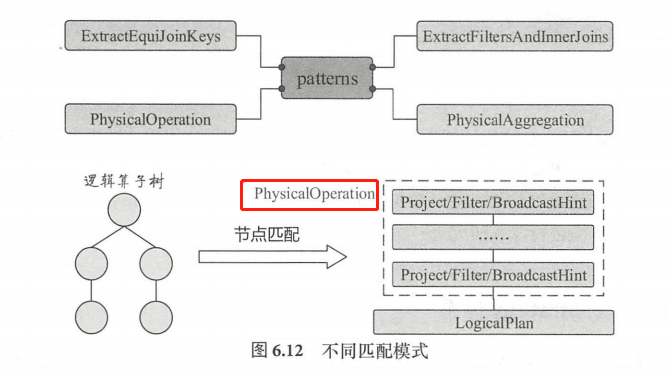
- ExtractEquiJoinKeys :等值Join 操作的算子集合,提取出其中的 Join 条件、左子节点、右子节点等信息。
- ExtractFiltersAndinnerJoins:Inner 类型 Join 操作中的过滤条件,目前仅支持对左子树进行处理。
- PhysicalAggregation :针对聚合操作,提取出聚合算子中的各个部分,并对一些表达式进行初步的转换。
- PhysicalOperation :匹配逻辑算子树中Project、Filter等节点,返回投影列、过滤条件集合和子节点。该模式如果匹配到 Project、Filter、BroadcastHint 这三种类型的 LogicalPlan 时,会递归查找子节点,若子节点是这种三种类型 ,则收集节点中的投影列或过滤条件,直到碰到其他类型 LogicalPlan 节点为止。
7.5.2 常见 Strategy 分析
SparkPlanner 中默认添加8种Strategy 来生成物理计划,如FileSourceStrategy、DataSourceStrategy 主要针对数据源; Aggregation、JoinSelection 分别针对聚合与关联操作;BasicOperators 涉及范围最广,包含了过滤、投影等各种操作。
- 文件数据源策略(FileSourceStrategy)
面向的是来自文件的数据源,该策略能够匹配 PhysicalOperation 的节点集合加上 LogicalRelation 节点,在这种情况下,该策略会根据数据文件信息构建 FileSourceScanExec 这样的物理执行计划,并在此物理执行计划后添加过滤(FilterExec )与列剪裁(ProjectExec )物理计划。
- 内存数据表扫描策略 (InMemoryScans)
该策略主要针对是 InMemoryRelation 这个 LogicalPlan节点,逻辑同样是匹配PhysicalOperation 这个模式,最终生成 InMemoryTableScanExec ,并调用 SparkPlanner 中的 pruneFilterProject 方法对其进行过滤和列剪裁。
- DDL 操作策略(DDLStrategy)
该策略在 SparkSQL 中仅针对 CreateTable、CreateTempViewUsing 这两种类型的节点,这两种情况都直接生成 ExecutedCommandExec 类型的物理计划。
- 基本操作策略(BasicOperators)
该策略是专门针对各种基本操作类型的LogicalPlan 节点,例如排序、过滤等。一般情况下, 一对一地进行映射即可(例如:Sort 逻辑节点映射为 SortExec 物理计划)。
案例讲解:
如图所示 ,Project 节点加上 Filter 节点对应 PhysicalOperation 模式,加上 LogicalRelation 节点,正好匹配到 FileSourceStrategy 策略。因此,整个转换逻辑都在 FileSourceStrategy 中完成,最终的物理计划包括ProjectExec、FilterExec、FileSourceScanExec 这三个节点。
7.5.3 执行前的准备
物理计划的生成意味着用户的 SQL 语句已经成功转换为 SparkPlan 物理算子树,然而,在通常情况下,到了这一步仍然不能直接提交给 Spark 系统执行。应用提交前有必要从 Spark 系统本身的角度来考虑代码的正确性和高效性。因此,得到 SparkPlan 后,还需要完成若干的准备工作,对树型结构的物理计划进行全局的整合处理或优化。
代码项目:Spark-sql_2.12
代码地址:org.apache.spark.sql.execution.QueryExecution
在QueryExection 中,最后阶段由 prepareforExecution 方法对传入的 SparkPlan 进行处理而生成 executedPlan,处理过程基于若干规则,主要包括对 Python-UDF提取、子查询的计划生成等。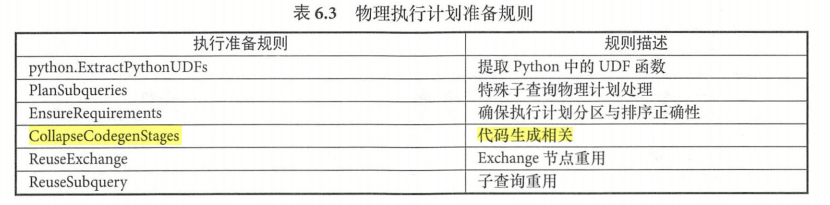
需要特别注意:CollapseCodegenStages 规则会根据 SparkPlan 的逻辑生成最终的 Java 执行代码。与Tungsten计划有关。
- PlanSubqueries规则
子查询是指嵌套在一个查询内部的完整查询,常见的子查询通常作为数据源出现在From 关键字之后。 Spark 2.0 及以上版本能够支持Scalar 类型和Predicate 类型的子查询。
Scalar 类型的子查询返回单个值,具体又分为相关的(Correlate )类型和不相关的(Uncorrelated )类型。Uncorrelated 意味着子查询和主查询不存在相关性, Uncorrelated 类型的 Scalar 子查询对于所有的数据行都返回相同的值。因此,在主查询执行之前, Uncorrelated子查询会首先执行。
Correlated 类型的 Scalar 子查询意味着该子查询中包含了外层主查询中的相关属性,在SparkSQL 中会等价转换为 LeftJoin 算子。
Predicate 类型的子查询表示子查询作为过滤谓词,在 SparkSQL 中出现在EXISTS、 IN 语句中。
PlanSubqueries规则就是处理物理计划中这两种特殊的子查询,该规则遍历物理算子树中的所有表达式,碰到 ScalarSubquery 或 PredicateSubquery 表达式时,进入子查询中的逻辑,递归得到子查询的物理执行计划 ( executedPlan),然后封装为 ScalarSubquery 或 InSubquery 表达式。
/*** Plans subqueries that are present in the given [[SparkPlan]].*/case class PlanSubqueries(sparkSession: SparkSession) extends Rule[SparkPlan] {def apply(plan: SparkPlan): SparkPlan = {plan.transformAllExpressionsWithPruning(_.containsAnyPattern(SCALAR_SUBQUERY, IN_SUBQUERY)) {case subquery: expressions.ScalarSubquery =>val executedPlan = QueryExecution.prepareExecutedPlan(sparkSession, subquery.plan)ScalarSubquery(SubqueryExec.createForScalarSubquery(s"scalar-subquery#${subquery.exprId.id}", executedPlan),subquery.exprId)case expressions.InSubquery(values, ListQuery(query, _, exprId, _, _)) =>val expr = if (values.length == 1) {values.head} else {CreateNamedStruct(values.zipWithIndex.flatMap { case (v, index) =>Seq(Literal(s"col_$index"), v)})}val executedPlan = QueryExecution.prepareExecutedPlan(sparkSession, query)InSubqueryExec(expr, SubqueryExec(s"subquery#${exprId.id}", executedPlan), exprId)}}}
- EnsureRequirements规则
该规则用来确保物理计划能够执行所需要的前提条件,包括对分区和排序逻辑的处理。在特定情形下, SparkPlan 对输入数据的分布 (Distribution )情况和排序( Ordering )特性有着一定的要求 例如, SortMergeJoin 类型的 Join , 要求输入数据已经按照 Hash 方式分区且处于有序状态。如果输入数据的分布或有序性无法满足当前节点的处理逻辑,则 EnsureRequirements 规则会在物理计划中添加一些 Shuffle 操作或排序操作来达到要求,体现在物理算子树上就是加入Exchange 节点或 SortExec 节点。此外,该过程还涉及依赖信息(ShuffleDependcency )的创建、 ShuffledRowRDD 的构造等,其处理逻辑可以算是整个物理计划阶段最为复杂的部分。
该规则的 apply 方法在遍历 SparkPlan 过程中,当匹配到 Exchange 节点(ShuffleExchange),且其子节点也是 Exchange 类型时,会检查两者的 Partitioning 方式,判断能否消除多余的 Exchange 节点。除此情况外,遍历过程中会逐个调用 ensureDistributionAndOrdering 方法来确保每个节点的分区与排序需求。因此, EnsureRequirements 规则的核心逻辑体现在 ensureDistributionAndOrdering 方法中,可以将其大致过程分为3步:
1. 添加Exchange节点
Exchange 本身也是 UnaryExecNode 类型的 SparkPlan ,在 Spark SQL 中被定义为抽象类,继承 Exchange 的子类有两种,ShuffleExchangeExec会通过 Shuffle 操作进行重分区处理,而 BroadcastExchangeExec 则对应广播操作。
Exchange节点是实现数据并行化的重要算子,用于解决数据分布(Distribution )相关问题,具体来讲,需要添加 Exchange 节点的情形分为以下两种:
1. 数据分布不满足:子节点的物理计划输出数据无法满足(Satisfies )当前物理计划处理逻 辑中对数据分布的要求,例如子节点输出数据分布为 UnspecifiedDistribution ,而当前物理计划对输入数据分布的需求是 OrderedDistribution。1. 数据分布不兼容:当前物理计划为 BinaryExecNode 类型,即存在两个子物理计划时,两 个子物理计划的输出数据可能不兼容(Compatile)。 例如, Hash 的方式不同,导致应该在同一个分区的数据最终落到不同的节点上。在这种情况下,也需要创建 Exchange 节点重新进行 Shuffle 操作。2. 应用ExchangeCoordinator 协调分区
ExchangeCoordinator 用来确定物理计划生成的 Stage 之间如何进行Shuffle。其作用在于协助 ShufileExchange 节点更好地执行,仅用于确定数据 Shuffle 后( Post-shuffle )的分区数目。
ExchangeCoordinator 针对的是一批 SparkPlan 节点,根据 withExchangeCoordinator 方法的逻辑,需要满足两个条件:
1. SparkSQL 的自适应机制开启,对应的参数(spark.sql.adaptive.enabled )设置为 true。1. 这批 SparkPlan 节点能够支持协调器,一种情况是至少存在 ShuffleExchange 类型的节点且所有节点的输出分区方式都是 HashPartition,另一种情况是节点数目大于1且每个节点输出数据的分布都是 ClusteredDistribution 类型。3. 添加SortExec节点
排序的处理在分区处理(创建完 Exchange )之后,其逻辑相对简单,不用考虑子节点彼此 之间的兼容问题,只需要对每个子节点单独处理。当所有子节点的输出数据的排序信息满足当前节点所需时,才不需要添加SortExec 节点;否则,需要在当前节点上添加 SortExec 为父节点。
9 . 钨丝计划(Tungsten Plan)
Tungsten 是开源社区专门用于提升Spark 性能的计划。Tungsten 的优化主要包括3个方面:内存管理机制(Memory management and binary processing )、缓存敏感计算(Cache-aware computation)和动态代码生成( Code generation)。
9.1 内存管理与二进制处理
Tungsten 设计了一套内存管理机制, Spark 可以直接操作二进制数据而不是 JVM 对象,使得内存使用效率大幅提升。
9.1.1 Spark内存管理基础
Driver和Executor都是JVM 进程,运行在 Worker (Standalone 模式)或 Container (YARN 模式)中,Driver 和每个 Executor 都有自己的内存空间,内存管理则由 MemoryManager 管理。Executor 内的任务都会调用 MemoryManager 接口中定义的方法来完成内存申请或释放资源等操作。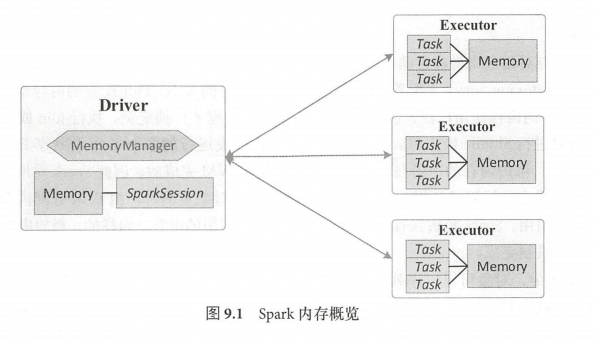
Spark 1.6 之前, Spark 采用的是静态内存管理(StaticMemoryManager )方式。1.6 开始, Spark默认采用统一内存管理(UnifiedMemoryManager )方式,但静态内存管理方式仍然保留(通过 spark.memory.useLegacyMode 参数配置)。相比静态内存管理方式,统一内存管理方式中存储内存和计算内存能够共享同一个空间,并且可以动态地使用彼此的空闲区域。
1. Spark 内存管理基本概念与内存管理器 MemoryManager
内存模式(MemoryMode):Spark系统运行在 JVM 上,因此其内存管理也建立在 JVM的内存管理之上。MemoryManager 将内存模式分为堆内(ON_HEAP )内存和堆外(OFF_HEAP) 内存。在实际 Spark 应用中使用参数(spark.driver.memory 、spark.executor.memory )来配置Driver和Executor 内存的大小,这里配置的就是指堆内内存。Executor 的内存使用广泛,例如,缓存 RDD 中的数据或广播变量、执行 Join、Aggregation计算任务时进行 Shuffle 操作等。Executor 中并发运行的多个 Task 会共享 Executor 进程JVM 内存,堆内内存的申请与释放在本质上都是由 JVM 完成的,因此 Spark 对堆内内存的管理只是在逻辑上进行记录和规划。例如, Spark 在创建对象实例时,由 JVM 分配内存空间并返回该对象的引用, Spark 负责保存该引用并记录该对象占用的内存。同样的,释放内存也由 JVM 的垃圾回收机制完成。
Spark 中序列化的对象是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得的,并不是每次新增的数据项都会计算一次占用的内存大小,这种方法降低了时间开销,但是有可能误差较大, 导致某时刻的实际内存有可能远远超出预期。此外,被 Spark 标记为释放的对象实例,实际上很有可能并没有被 JVM 回收,导致实际可用的内存大小小于 Spark 记录的可用内存大小。所以, Spark 并不能准确记录实际可用的堆内内存,也就无法完全避免内存溢出(Out of Memory) 的异常。
JVM 堆外内存管理的引入使得 Spark 可以很方便地直接在工作节点系统内存中分配空间, 能够进一步优化内存的使用,减少了不必要的内存开销(例如频繁的垃圾回收),提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,相对来讲,堆外内存比堆内内存更加容易管理。在默认情况下堆外内存并不启用,可通过参数 ( spark.memory.offHeap.enabled )开启,同样也可以通过参数(spark.memory.offHeap.size )控制堆外内存空间的大小。
内存池(MemoryPool) : MemoryManager 通过内存池机制管理内存。简单来讲,内存池就是内存空间中一段大小可以调节的区域。数据存储内存池包含 onHeapStorageMemoryPool (堆内)和offHeapStorageMemoryPool (堆外)两个,计算执行内存池包含 onHeapExecutionMemoryPool (堆内)和 offHeapExecutionMemoryPool (堆外)。
内存页(page): MemoryManager 中设定了内存页的大小(pageSizeBytes ),单位为字节。
最小的内存页大小为 lMB ,最大的 内存页大小为 64MB。
内存管理接口: MemoryManager 提供了 个方面的内存管理接口,包括内存申请接口、内存释放接口和获取内存使用情况的接口。Spark 2版本中,内存申请接口又包含存储内存申(acquireStorageMemory )、展开内存申请( acquireUnrollMemory)和执行内存申请
(acquireExecutionMemory )。Spark 将 RDD 中的数据分区由不连续的存储空间组织为连续存储空间的过程被称为 “展开”(Unroll ),展开内存即用于这个操作。
静态内存管理机制(StaticMemoryManager) : 1.6 版本之前唯一的内存管理器,当前版本中都默认设置为关闭状态。将其称为静态内存管理的主要原因在于数据存储与计算执行的内存占比和界限是固定的,彼此不能互相占用,且不支持堆外内存作为数据存储。
统一内存管理机制(UnifiedMemoryManager ):统一内存管理的内存分配机制新增了一个 300MB的固定保留的内存空问(Reserved ),这部分内存用户无法使用且大小不允许修改, 一般用于Spark 系统内部。 除这部分内存外,剩下的称为可用内存(usableMemory),可用内存中除了留给应用的内存(例如存储用户程序中的数据结构),就是数据存储与计算执行公用的内存区域,这部分内存的大小通过参数 spark.memory.fraction 设置,默认为 0.6 (注:设计文档中初始实现为 0.75 ,后来因为考虑到 GC ,在 2.0 版本中进行了调整)。此外,数据存储内存空间大小的初始比例也可以通过参数 spark.memory.storageFraction 设置,默认为 0.5 ,即各占一半。随着应用的执行,数据存储与计算执行间互相借用内存,可能会导致这个数值不断变化。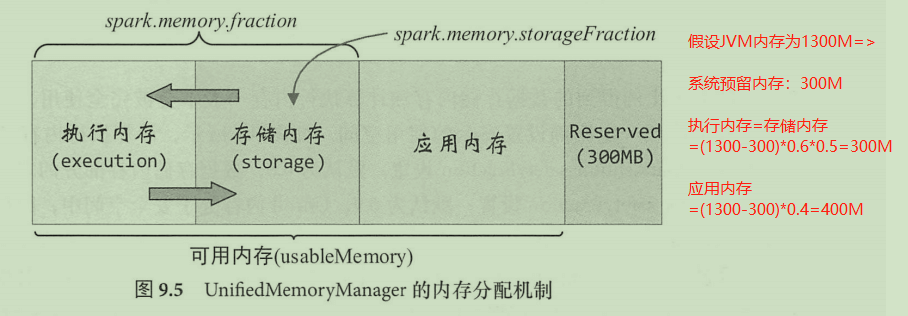
统一内存管理最大的特点在于动态占用机制,其规则如下:
1. 设定基本的存储内存和执行内存区域(使用 spark.storage.storageFraction 参数),该设定确定了双方各自拥有的空间范围。1. 双方的空间都不足时,则存储到硬盘,若己方空间不足而对方空间空余时,可借用对方的空间(注:存储空间不足是指不足以放下一个完整的Block)。1. 执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后归还借用的空间。1. 存储内存的空间被对方占用后,无法让对方归还,因为需要考虑 Shuffle 过程中的很多因素,实现起来较为复杂。2. 存储内存管理
存储内存管理的入口是 StorageMemoryPool,存储内存的主要使用者是 Spark 存储模块。Spark 的存储模块负责管理计算过程中产生的各种数据,并将内存、磁盘、本地、远程各种场景下数据的读写功能进行封装。对于 Spark 来讲,存储模块解藕了 RDD 与底层物理存储,并提供了 RDD 的持久化功能 ,StorageLevel 类中定义了持久化的不同维度,其构造参数是个五元组(_useDisk, _useMemory,useOffHeap, _deserialized, _replication ),除了replication为 int 类型(默认为1 )外, 其他都是 Boolean 类型。这种数据的存储方式包括磁盘、堆内内存和堆外内存3种,存储形式,可以是序列化和非序列化,副本数大于1时需要远程备份到其他节点。
存储模块的入口为 BlockManager 类,整体架构采用主从模式(Driver端BlockManager为主,Executor端的BlockManager为从)。数据存储的基本单位为Block,每个 Block 都会产生 Blockid 标识 。RDD 本身、 Shuffle、Broadcast 过程都会涉及数据存储,也都会产生对应 Blockid ,如RDD 中每个分区(Partition )唯一对应一个Block ,此时 Blockid 格式为”rdd_rddld_partitionld”。应用执行过程中, Driver端的BlockManager 负责对全部Block数据块的元数据信息进行管理和维护, Executor 端的BlockManager 将Block的更新等状态上报到 Driver 端,并接收主节点的相关操作命令。
RDD 在缓存到存储内存之前,每条数据的对象实例都处于 JVM 堆内内存的 Other 部分,即便同一个分区内的数据在内存空间中也是不连续的,具体分布由 JVM 管理,上层通过Scala 中的迭代器来访问 RDD。当持久化到存储内存之后, Partition 对应转换为Block ,此时数据在存储内存 空间(堆内或堆外)中将连续的存储。这里将Partition 由不连续的存储空间转换为连续的存储空间的过程,就是前面的”展开(Unroll )”操作。
根据定义的存储级别(StorageLevel), Block 也有序列化和非序列化两种存储格式。非序列化的Block用一个数组存储所有的对象实例;序列化的Block 则以字节缓冲区(ByteBuffer )存储二进制数据。每个Executor 的存储模块采用 LinkedHashMap 数据结构来管理堆内和堆外存储内存中所有的Block对象的实例,对该 LinkedHashMap 新增和删除间接记录了内存的申请和释放。
因为不能保证存储空间可一次容纳 Iterator 中所有的数据,所以当前的计算任务在执行UnRoll操作时需要 MemoryManager 申请足够的空间来临时占位, 空间不足则展开失败。对于序列化的Partition ,其所需的展开空间可以直接累加计算并一次申请;非序列化的 Partition 则要在遍历数据的过程中依次申请,即每读取一条 Record ,采样估算其所需的展开空间并进行申请,空间不足时可以中断,释放己占用的展开空间。如果最终展开成功, 则当前 Partition 所占用的展开空间被转换为正常的缓存 RDD 的存储空间。
同一个 Executor 的所有计算任务共享有限的存储内存空间,当有新的 Block 需要缓存但是剩余空间不足且无法动态占用时,就要对 LinkedHashMap 中的旧 Block 进行淘汰( Eviction)。对于被淘汰的 Block ,如果其存储级别中同时包含存储到磁盘的要求,则要对其进行落盘,否则直接删除该 Block 。存储内存的淘汰规则如下:
- 被淘汰的旧Block 要与新Block 的内存模式相同,即同属于堆外或堆内内存。- 新旧 Block 不能属于同 RDD ,避免循环淘汰。- 旧 Block 所属 RDD 不能处于被读状态,避免一致性问题。- 遍历 LinkedHashMap 中的 Block ,按照最近最少使用(LRU )的顺序淘汰,直到满足新 Block 所需的空间。其中, LRU机制是LinkedHashMap 的特性。落盘的流程比较简单,如果其存储级别符合 useDisk为 true 的条件,就根据其 _deserialized 判断序列化的形式, 若是则对其进行序列化,最后将数据存储到磁盘,在存储模块中更新其信息。3. 执行内存管理
执行内存管理的入口是ExecutionMemoryPool ,内部包括 poolName 、memoryForTask 两个变量 , poolName 是内存池的名称 (on-heap execution、 off-heap execution),memoryForTask 实际上是 HashMap 结构,记录了每个 Task 的内存使用量。
Executor 内运行的任务同样共享执行内存,假设当前 Executor 中正在执行的任务数目为n,那么每个任务可占用的执行内存大小的范围为[ 1/2n,1/n ]。每个任务在启动时,要向Memory Manager 申请最少 1/2n 的执行内存,如果不能满足要求, 该任务被阻塞,直到有其他任务释放了足够的执行内存,该任务才能被唤醒。在执行期间, Executor 中活跃的任务数目是不断变化的, Spark 采用 wait 和 notifyAll 机制同步状态并重新计算n的值。执行内存主要用于满足 Shuffle 、Join 、Sort、 Aggregation 等计算过程中对内存的需求。
首先回顾一下Spark-Shuffle 实现方式的演化历程,Spark-Shuffle经历了 Hash、Sort、 Tungsten Sort 三个重要的阶段:
- 在 1.1 之前的版本中,简单采用基于 Hash 方式的 Shuffle 实现,从 1.1 版本开始 Spark 参考Map Reduce 的实现,引入 SortShuffle 机制。自此Hash Shuffle、Sort Shuffle 共同存在,并在 1.2 版本时将 Sort Shuffle 设置为默认的 Shuffle方式 。- 发展到 1.4 版本时, Tungsten 引入了 UnSafe Shuffle 机制来优化内存和 CPU 的使用 ,并在1.6 版本中进行代码优化,统一实现到 Sort Shuffle 中,通过 Shuffle 管理器自动选择最佳Shuffle 方式。- 到 2.0 版本时, Hash Shuffle 的实现从 Spark 中删除,所有 Shuffle 方式全部统一到 Sort Shuffle 实现中。
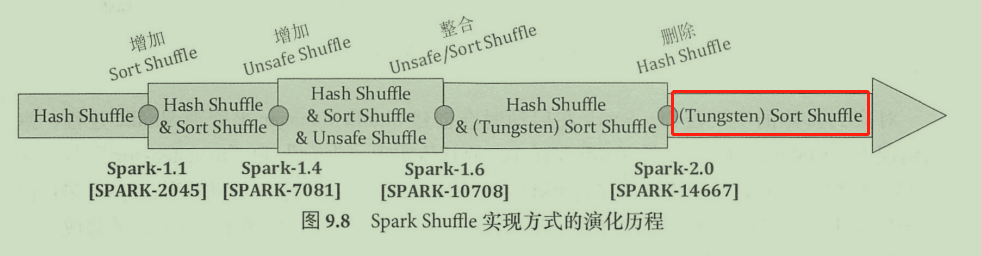
关于 Hash 方式的 Shuffle 实现,其主要思想是按照 Hash 方式在每个 map端(对应 shuffle write )的任务中为每个 reduce 端(对应 shuffle read )的任务生成 MR个文件。如果 有m个map 任务, n个reduce 任务,就会产生mn个文件,海量数据场景下会导致大量的磁盘 IO 操作与内存开销。
Sort Shuffle 的引入完美地解决了 Hash Shuffle 的问题,使得 Spark 能够有效处理大规模数据。Sort Shuffle 的原理如图所示,这里的 map 任务在 Spark中称为 ShuffleMapTask ,负责Shuffle-Write。ShuffleMapTask 中会根据(partition id, key) 对所有的 key-value 记录进行排序,并将所有分区的数据写在同一个文件中 ,在创建数据文件的同时, ShuffleMapTask 会创建一个索引文件 (index)来记录每个分区的大小和偏移量。所以,每个 ShuffleMapTask 只会产生两个文件,如果有m个任务,只会产生m个临时文件,有效地解决了 Hash Shuffle 实现中文件数目过多的问题。Sort Shuffle 的入口是SortShuffleManager, ShuffleMapTask从SortShuffleManager 中获取到 ShuffleWriter 对象来执行写操作,写操作会将数据写在本地目录中;对应的,在 Shuffle 执行读任务时,每个Task 会从 SortShuffleManager 中获得 ShuffleReader 对象,由该对象到特定的服务器节点上读取特定的数据。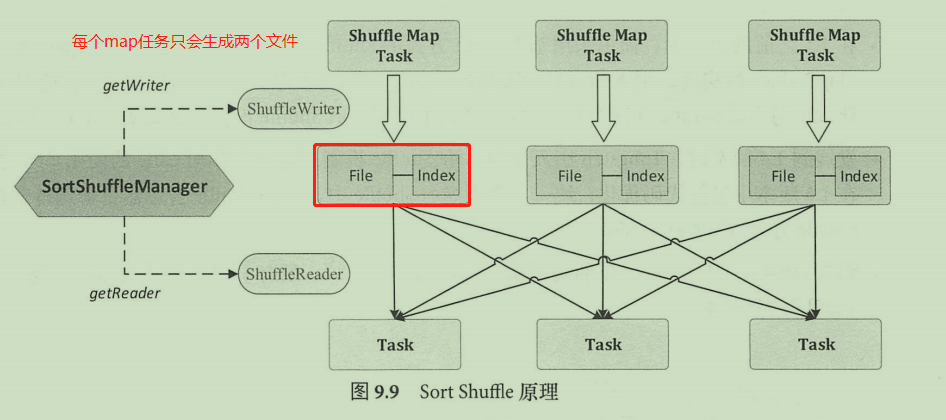
Spark 在启动时会创建 ShuffleManager 来管理 Shuffle 过程,默认情况下具体实现是SortShuffleManager,其创建过程在 SparkEnv 类中。SparkEnv 类中创建 ShuffieManager 采用的是单例模式,因此在Shuffle 读和写的任务中都是通过单例访问方式直接得到ShuffieManager对象的( SparkEnv.get.shuffieManager )。得到ShuffieManager 之后,可从中获取 ShuffieReader 、ShuffleWriter 对象来执行读和写操作。ShuffleWriter会根据相关信息自动选择一种。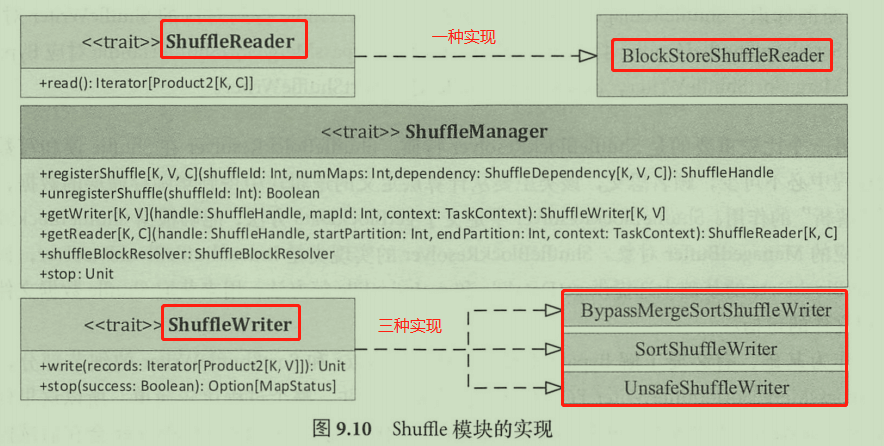
Shuffle 模块辅助类:ShuffleHandle类
当 ShuffieDependency 注册 Shuffle 时就会得到一个 ShuffleHandle 对象,该对象中保存了 Shuffleld、ShuffleMapTask个数和 ShuffleDependency 对象本身,ShuffieHandle共有三种实现:
- BypassMergeSortShuffieHandle :可以忽略掉聚合排序的 Shuffle 过程,本质上和 HashShuffle 机制类似。如果当前的依赖不需要进行 map 端的聚合,且 Partitioiner分区数目小于或等于阈值(spark.shuffie.sort.bypassMergeThreshold ,默认为 200 ),那么注册该Shuffle 就会得到 BypassMergeSortShuffleHandle 对象,这种情况下Shuffle 写操作内部不使用 MergeSort 方式处理数据,而是直接将每个分区写入单独的文件,并在最后做一个合并处理,并创建 index 索引文件来标记不同分区的位置信息。但是从 Shuffle 读任务看来,数据文件和索引文件的格式和内部是否做过聚合排序是完全相同的。这个可以看作 Sort Based Shuffle 在Shuffle 量比较小的时候对 Hash Based Shuffle 的一种折衷,也存在同时打开文件过多导致内存占用增加的问题。- SerializedShuffieHandle :对应 Tungsten 方式的 Shuffle 过程,这种情况下 ShuffieMapTask输出数据能够先序列化为二进制数据存储在内存中,再执行相关的操作,内存使用更高效。采用这种方式需要满足3个条件,即序列化框架 Serializer 支持对象重定位( Supports Relocation Of Serialized Objects )、依赖中没有定义聚合操作和分区数目不能超过阈值 (16777216)。- BaseShuffieHandle :在不满足上述要求的情况下,返回的是 BaseShuffleHandle 对象,意味着以反序列化的格式处理 Shuffle 输出数据。 实际上 ShuffieHandle 相当于判断的标识, ShuffieManager 根据具体是哪种 ShuffieHandle 得到对应的 ShuffleWriter 对象, SerializedShuffieHandle 对应 UnsafeShuffieWriter, BypassMergeSortShuffieHandle 对应 BypassMergeSortShuffieWriter, BaseShuffieHandle 对应 SortShuffieWriter o4. <br />

若有收获,就点个赞吧
0 人点赞
