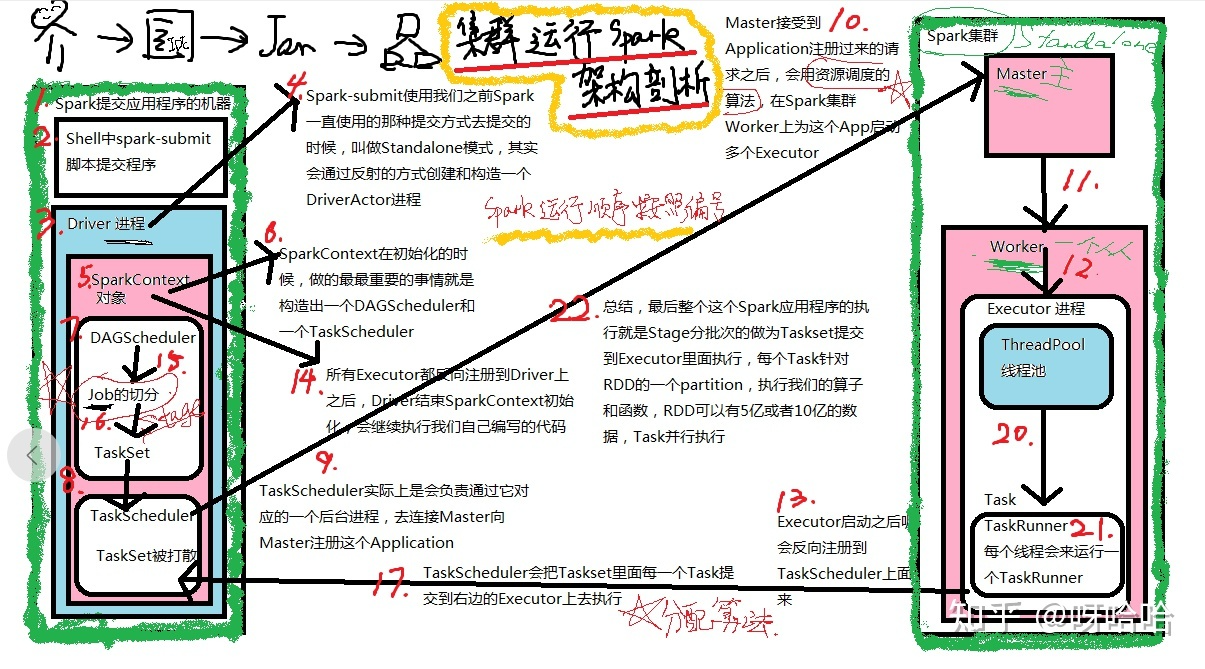
spark提交流程
什么是RDD
弹性分布式数据集(RDD)。
无论是DataFrame还是Dataset,运行的所有Spark代码都将编译成一个RDD。
RDD的单个记录只是原始的Java/Scala/Python对象。
每个RDD具有以下五个主要内部属性:
• 数据分片(Partition)列表。
• 作用在每个数据分片的计算函数。
• 描述与其他RDD的依赖关系列表。
• (可选)为key-value RDD配置的Partitioner(分片方法,如hash分片)。
• (可选)优先位置列表,根据数据的本地特性,指定了每个Partition分片的处理位置偏好
(例如,对于一个HDFS文件来说,这个列表就是每个文件块所在的节点)spark重分区
我们常认为coalesce不产生shuffle会比repartition 产生shuffle效率高,而实际情况往往要根据具体问题具体分析,coalesce效率不一定高,有时还有大坑,大家要慎用。 coalesce 与 repartition 他们两个都是RDD的分区进行重新划分,repartition只是coalesce接口中shuffle为true的实现(假设源RDD有N个分区,需要重新划分成M个分区)
- 如果N<M。一般情况下N个分区有数据分布不均匀的状况,利用HashPartitioner函数将数据重新分区为M个,这时需要将shuffle设置为true(repartition实现,coalesce也实现不了)。
- 如果N>M并且N和M相差不多,(假如N是1000,M是100)那么就可以将N个分区中的若干个分区合并成一个新的分区,最终合并为M个分区,这时可以将shuff设置为false(coalesce实现),如果M>N时,coalesce是无效的,不进行shuffle过程,父RDD和子RDD之间是窄依赖关系,无法使文件数(partiton)变多。 总之如果shuffle为false时,如果传入的参数大于现有的分区数目,RDD的分区数不变,也就是说不经过shuffle,是无法将RDD的分区数变多的
- 如果N>M并且两者相差悬殊,这时你要看executor数与要生成的partition关系,如果executor数 <= 要生成partition数,coalesce效率高,反之如果用coalesce会导致(executor数-要生成partiton数)个excutor空跑从而降低效率。如果在M为1的时候,为了使coalesce之前的操作有更好的并行度,可以将shuffle设置为true。
分布式共享变量
分布式共享变量包括两种类型:广播变量(broadcast variable)和累加器(accumulator)。<br />广播变量是共享的、不可修改的变量,它们缓存在集群中的每个节点上,而不是在每个任务中都反复序列化。<br />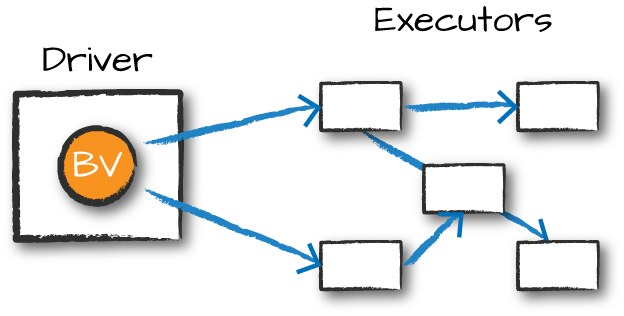<br /> 图:广播变量
累加器用于将转换操作更新的值以高效和容错的方式传输到驱动节点。
Spark提供对数字类型累加器的原生支持,程序员可以自行添加对新类型的支持。
自定义累加器:继承并实现 import org.apache.spark.util.AccumulatorV2 提供的抽象方法
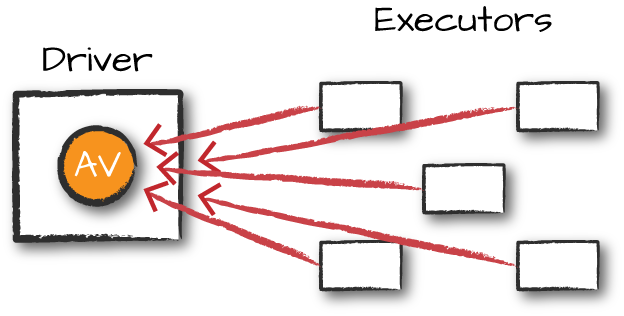
图:累加器

若有收获,就点个赞吧
0 人点赞
