spark-sql中特殊字符的问题
当写spark.sql(””)语句时,通过%s传参及同时使用like匹配规则有like ‘关键 词%’时,会发生冲突。
需要对like中%替换为%%,第一个%代表转义。
exp:
“””
|with middletable as
|(
| select date_time,case_id,action,data_json from %s
| where case_id != ‘0’ and date_format(date_time,’yyyy-MM-dd’) >= ‘2021-12-02’
|)
|select * from middle_table where action like ‘CASE:to%’
|”””.stripMargin.format(“dwdweb_case_audit_di”)
报错:
java.util.UnknownFormatConversionException: Conversion = ‘’’
解决:
“””
|with middle_table as
|(
| select date_time,case_id,action,data_json from %s
| where case_id != ‘0’ and date_format(date_time,’yyyy-MM-dd’) >= ‘2021-12-02’
|)
|select * from middle_table where action like ‘CASE:to%%’
|”””.stripMargin.format(dwd_web_case_audit_di)
spark-core及spark-sql中的union问题
SparkCore中也有union all , 只不过底层也是调的union。 并且在2.0以后废弃了,所以sparkCore中的union是不去重的,因为去重有distinct算子。 SparkSql中则有union和union all,对应去重及不去重。
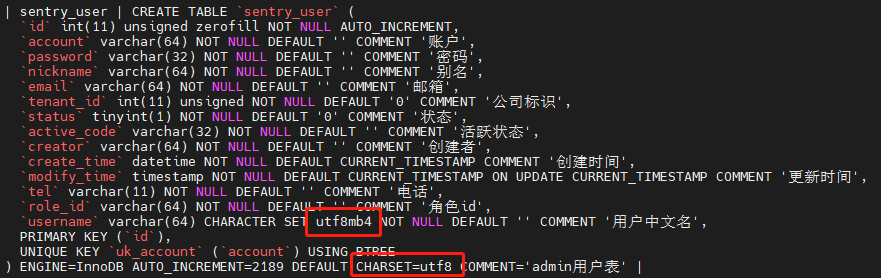
spark读取mysql中字符集编码为utf8mb4的问题:
mysql118的sentry库中的sentry_user表,表级别编为utf8,但是某列编码位utf8mb4,这时使用spark读取mysql写入hive时,该字段中文为null;
解决方法:
用mysql-jdbc读吧。。
spark-explode空数组时导致该行数据丢失:
当使用explode扁平化拆分数组时,如果数组为空,转换后会删除这行数据,
如果想保留纬度,则可使用explode_outer算子,会将数组置null,其他字段保留。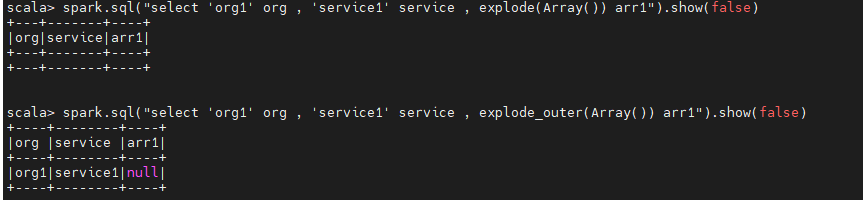
spark-submit中Executor heartbeat timed out:
设置spark-executor的心跳检测超时时间:
spark.executor.heartbeatInterval = 300s (默认10s)
spark.network.timeout = 360s (默认120s)
spark中想要获取分区字段
设置basePath并使用text读取,即可获取分区字段
spark.read.option(“basePath”,”/user/data/flume/online_offline/offline-bill”).text(“/user/data/flume/online_offline/offline-bill/*/serviceId=POST_RTASR”)
spark任务中邮件中文乱码问题
在submit脚本中添加编码配置:
—conf spark.driver.extraJavaOptions=”-Dfile.encoding=utf-8 -Dsun.jnu.encoding=UTF-8” \
—conf spark.executor.extraJavaOptions=”-Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8” \

若有收获,就点个赞吧
0 人点赞
