前置知识
我们知道,函数组件的相关信息都存储在对应的Fiber节点当中,而与函数组件 状态相关的内容 则是存储在Fiber节点的 memoizedState 属性当中。而由于一个函数组件是可以含有 多个状态 的,这就决定了 memoizedState 属性是一个 关于状态信息的集合 ,React使用了 单链表 作为这个集合的数据结构,这个链表的每个节点,我们称之为 hook ,一个 hook 对应着一个状态的信息。而对于每个 hook 来说,一次渲染可能会有多次的更新,这些更新信息存储在 hook.queue.pending 属性当中,这个属性为一个 环链表 ,链表节点称之为 update 。
上面出现了多个概念,总结一下关系:
- Fiber.memoizedState:存储着函数组件的所有状态信息,数据结构为单链表
- hook:Fiber.memoizedState单链表的节点,存储着单个状态的信息
- hook.queue.pending:为一个环状链表,存储着状态更新的操作,单个节点称为Update
下面是这几个数据结构的详细描述:
type Hook = {memoizedState: any, // 对应的状态值baseState: any, // 保存上一轮中断时的状态baseQueue: Update<any, any> | null, // 保存上一轮中剩余的更新操作queue: UpdateQueue<any, any> | null, // 保存当前的更新操作next: Hook | null, // 指向下一个hook};type Update<S, A> = {|lane: Lane, // 优先级相关,暂时忽略action: A, // 更新操作或者数据eagerReducer: ((S, A) => S) | null,eagerState: S | null,next: Update<S, A>,priority?: ReactPriorityLevel, // 优先级相关,暂时忽略|};type UpdateQueue<S, A> = {|pending: Update<S, A> | null, // Update的环状链表dispatch: (A => mixed) | null, // 对应的dispatcherlastRenderedReducer: ((S, A) => S) | null, // 保存着上次渲染的reducerlastRenderedState: S | null, // 优化相关,保存着上一次渲染的state|};
了解了上面几个概念后,我们分别从mount阶段和update阶段来理解useState的运行流程
mount阶段
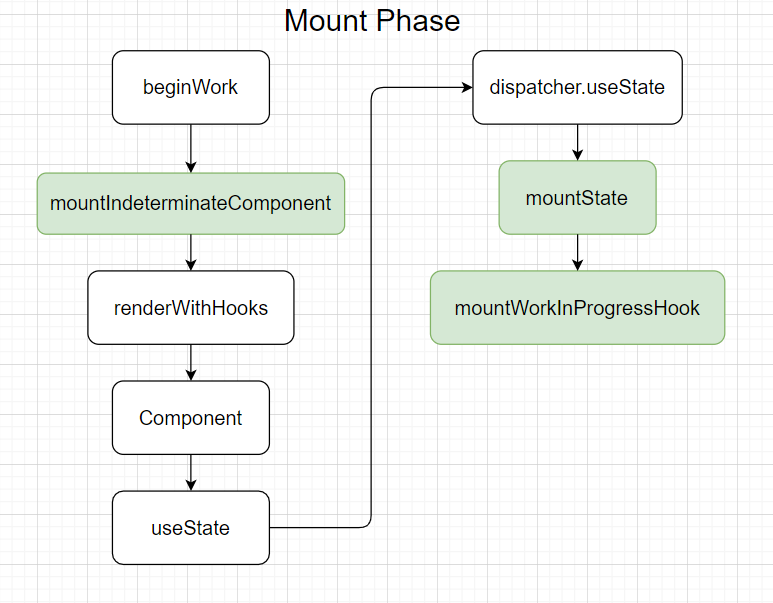
上面是useState的调用流程图:
useState的调用是在render阶段,其调用从本函数组件的Fiber节点的 beginWork 开始,随后进入 mountIndeterminateComponent ,此函数会同时处理类组件和函数组件的相关操作,然后通过 renderWithHooks 调用 Component 即函数组件本身得到JSX节点。
useState函数会通过调用 dispatcher.useState 进入到真正的useState流程当中,这一步的目的是建立一个中间层,根据不同的情况(挂载,更新等等)对应着不同的dispatcher,从而获取不同的useState函数。
来到 mountState 中就是mount阶段的 核心逻辑 ,这部分主要做了两件事:
- 生成当前状态对应的hook,并挂载到workInProgress Fiber节点的
memoizedState链表上 - 返回状态(initialState)和dispatcher(用于更新状态,后面会介绍)数组
而对于 useReducer 来说,mount阶段的核心逻辑跟useState几乎一致,不同的只不过是在计算初始值的时候可能需要调用一下初始化函数。
update阶段
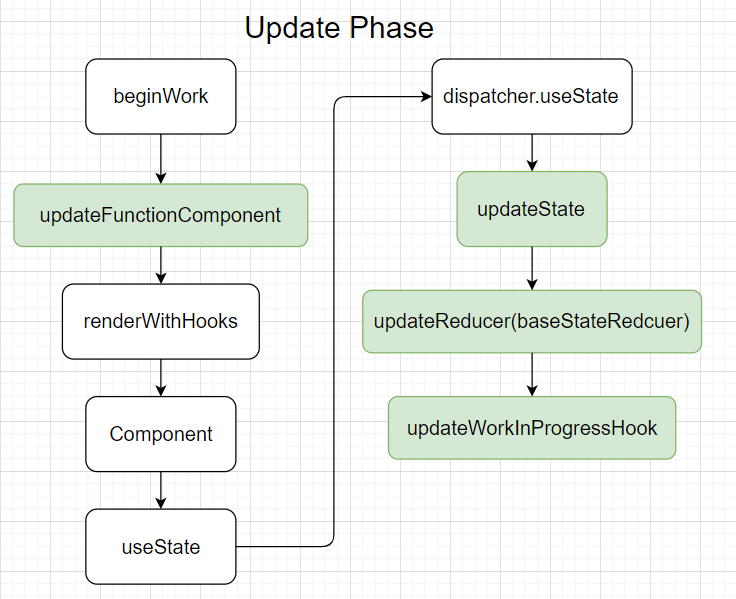
前面部分与mount阶段大致相同,可以看到updateState不过是调用了 updateReducer(baseStateReducer ,也就是说更新阶段的useState是一个特殊的updateReducer。
因此这一部分的核心逻辑在函数updateReducer里面,主要操作可以概括为三步:
- 获取当前状态的hook(
updateWorkInProgressHook) - 根据hook的内容得到最新的状态
- 返回state和dispatcher
updateWorkInProgressHook
顾名思义,此函数的目的是 更新workInProgressHook
此阶段中current Fiber中的hook链表(memoizedState)是 完整的 ,因为它是在上一个render阶段构建的,而workInProgress Fiber的hook链表是 不完整的 ,需要依托current Fiber的链表进行构建,最终的构建结果两条hook链表 结构一致 ,这也是为什么React不允许useState放在条件语句等地方,因为需要保证两条hook链表的结构的一致性。
因此更新workInProgressHook的方法就是 通过获取current Fiber的下一个hook来构建workInProgress Fiber的下一个hook,并将此hook赋值给workInProgressHook
由此对应着四个变量
- currentHook:current Fiber 当中与workInProgressHook(未被更新)对应的hook
- nextCurrentHook:current FIber 中的下一个hook
- workInProgressHook:在此函数中等待被更新
- nextWorkInProgressHook:workInProgress Fiber中的下一个hook
一般情况下,nextWorkInProgressHook是不存在的,因为还没被构建出来,但是如果是 在render阶段进行的更新,那么就有可能出现复用之前构建好的workInProgressHook的情况 ,譬如以下情况:**
function App() {const [num, setNum] = useState(0)const onClick = () => {setNum(state => state + 1)}setNum(state => state + 1)return (<div className="App" onClick={onClick}>{num}</div>);}
对于不是复用的情况,则会根据currentHook来新建workInProgressHook:
const newHook: Hook = {memoizedState: currentHook.memoizedState,baseState: currentHook.baseState,baseQueue: currentHook.baseQueue,queue: currentHook.queue,next: null,};
总结一下,更新workInProgressHook分为三步:
- 获取current Fiber的下一个hook(nextCurrentHook)
- 获取workInProgressHook的下一个Hook(nextWorkInProgressHook)
判断nextWorkInProgressHook是否存在
将上一轮 未完成的update(baseQueue) 与 当前新增的update(queue.pending) 合并
- 逐个遍历链表的每个update的action,获得最终的结果
备注:上述步骤先不考虑调度相关,只从完全的状态更新出发
其中上述的合并是 两个环链表的合并 ,相关逻辑如下:
const baseFirst = baseQueue.next; // baseQueue的头部const pendingFirst = pendingQueue.next; // pendingQueue的头部baseQueue.next = pendingFirst; // baseQueue的尾部指向pendingQueue的头部pendingQueue.next = baseFirst; // pendingQueue的尾部指向baseQueue的头部
遍历的逻辑如下(忽略调度相关的):
do {if (update.eagerReducer === reducer) {// 优化相关// If this update was processed eagerly, and its reducer matches the// current reducer, we can use the eagerly computed state.newState = ((update.eagerState: any): S);} else {const action = update.action;newState = reducer(newState, action);}update = update.next;} while (update !== null && update !== first);
其中重点说一下上面的 eagerState ,在dispatchAction时,如果当前的hook的queue为空,那么就会提前计算当前Update的结果,如果与之前保存的结果(queue.lastRenderedState)一致的话就不会进入到更新程序直接返回,避免不必要的更新。上面的情况是结果不一致,但是可以复用在dispatchAction中已经计算好的结果。
const currentState: S = (queue.lastRenderedState: any);const eagerState = lastRenderedReducer(currentState, action);update.eagerReducer = lastRenderedReducer;update.eagerState = eagerState;if (is(eagerState, currentState)) {return;}
其次可以看到上述的状态更新使用的是 reducer(newState, action) ,对于useState来说,此reducer是 baseStateReducer ,对于useReducer来说则为用户自定义的reducer。baseStateReducer的内容如下:
function basicStateReducer(state, action) {return typeof action === 'function' ? action(state) : action;}
逻辑非常简单,如果action是函数,则传入state进行调用,否则直接返回action的值。
dispatchAction
此函数的定义如下:
function dispatchAction<S, A>(fiber: Fiber,queue: UpdateQueue<S, A>,action: A,) {}
上面说到无论mount阶段还是update阶段都会返回一个dispatcher,这个dispatcher就是一个 绑定了fiber和状态hook对应的updateQueue的dispatchAction函数 。
dispatchAction的操作分为两步:
- 根据传入的action 构建Update对象
- 将此Update对象 拼接 到queue.pending环链表当中
- 就是上面提到过的相关性能优化工作
- 调度fiber进行更新

若有收获,就点个赞吧
0 人点赞
