- 正则表达式在线测试:http://tool.chinaz.com/regex/
正则规则
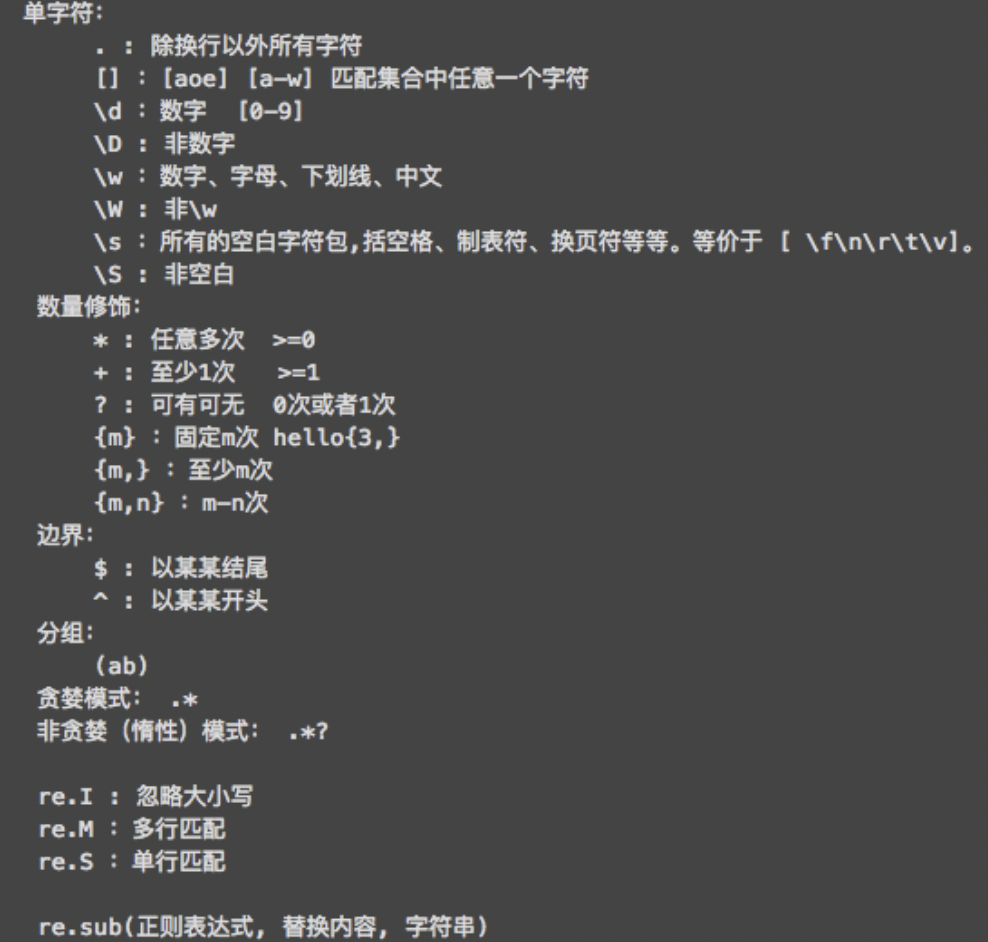
元字符
\d(digit):(一个)数字\w(word):(一个)字母、数字、下划线\s(space):空白(空格、换行符、制表符)\t(table):制表符\n(next):换行符\D,\W,\S:表示非……(小写所代表的含义)- [\d],[0-9],\d:没有区别,都是匹配一位数字
- [\d\D],[\w\W],[\S\s]:匹配所有一切字符
.:表示除了换行符以外所有字符[]字符组:只要在由括号内的所有字符都是符合规则的字符[^]非字符组:之只要在中括号内的所有字符都是不符合规则的字符^:以某字符开始$:以某字符结尾|:表示或,如果两个规则有重叠部分,总是长的在前,短的在后():表示分组,给一部分正则规定为一组,缩小作用域
量词
{m}:只能出现m次{m,}:至少出现m次{m,n}:至少m次,至多n次?:匹配0次或1次(表示可有可无,但只能有1个,比如小数点)+:匹配1次或多次*:匹配0次或多次(表示可有可无,但可以有多个,比如小数点后n位)贪婪匹配(默认):总是会在符合条件范围内尽量多匹配非贪婪匹配(惰性匹配):总是会在符合条件范围内尽量少匹配.*?x:匹配任意的内容多次,遇到x就停止
re模块
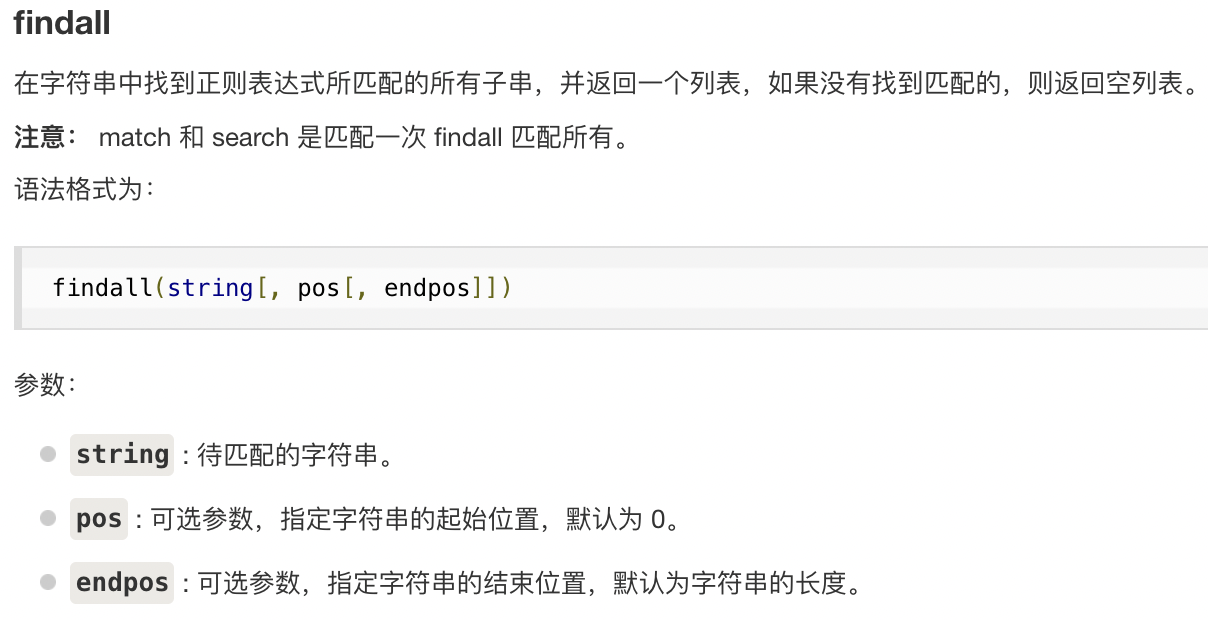
re.findall
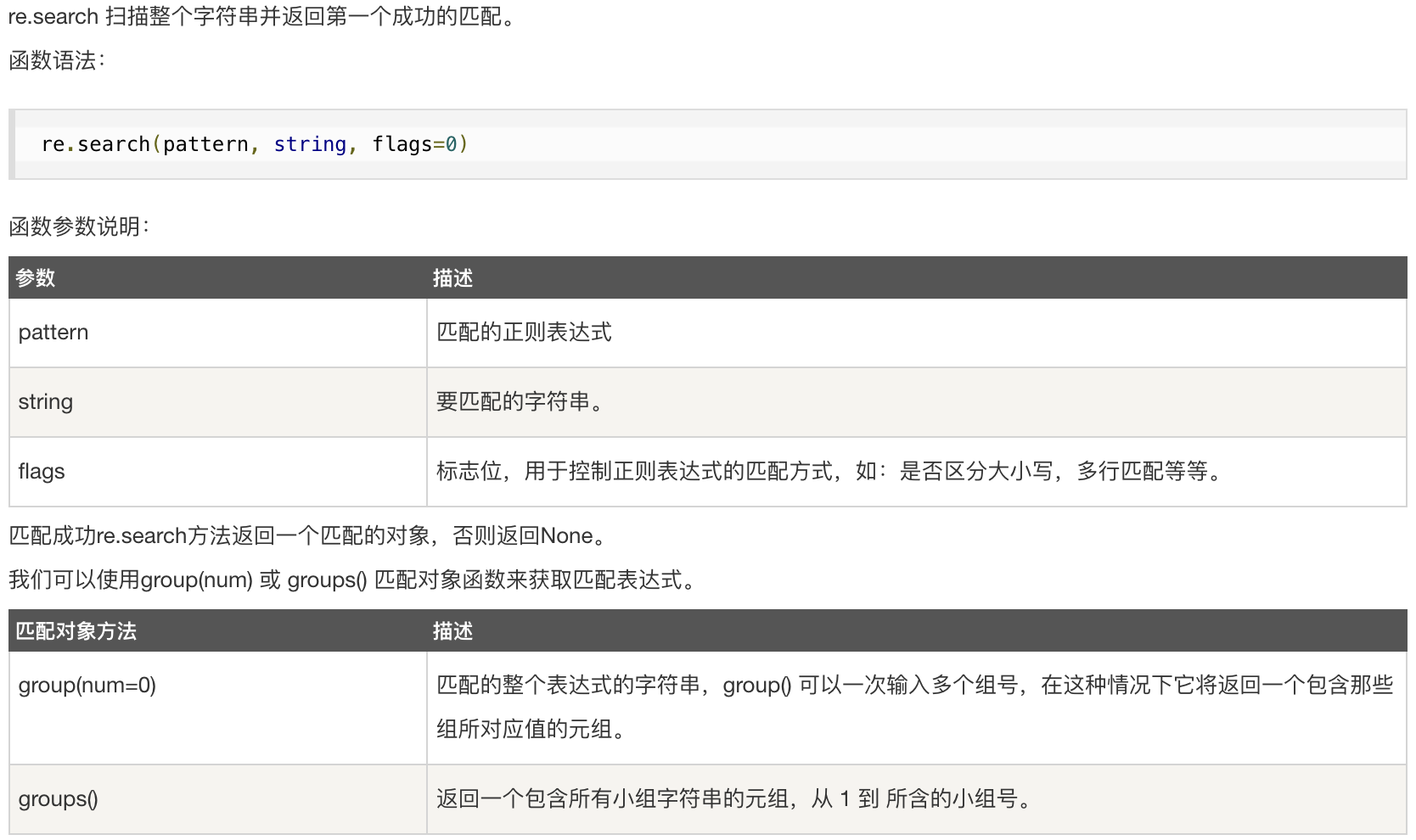
- `re.search`
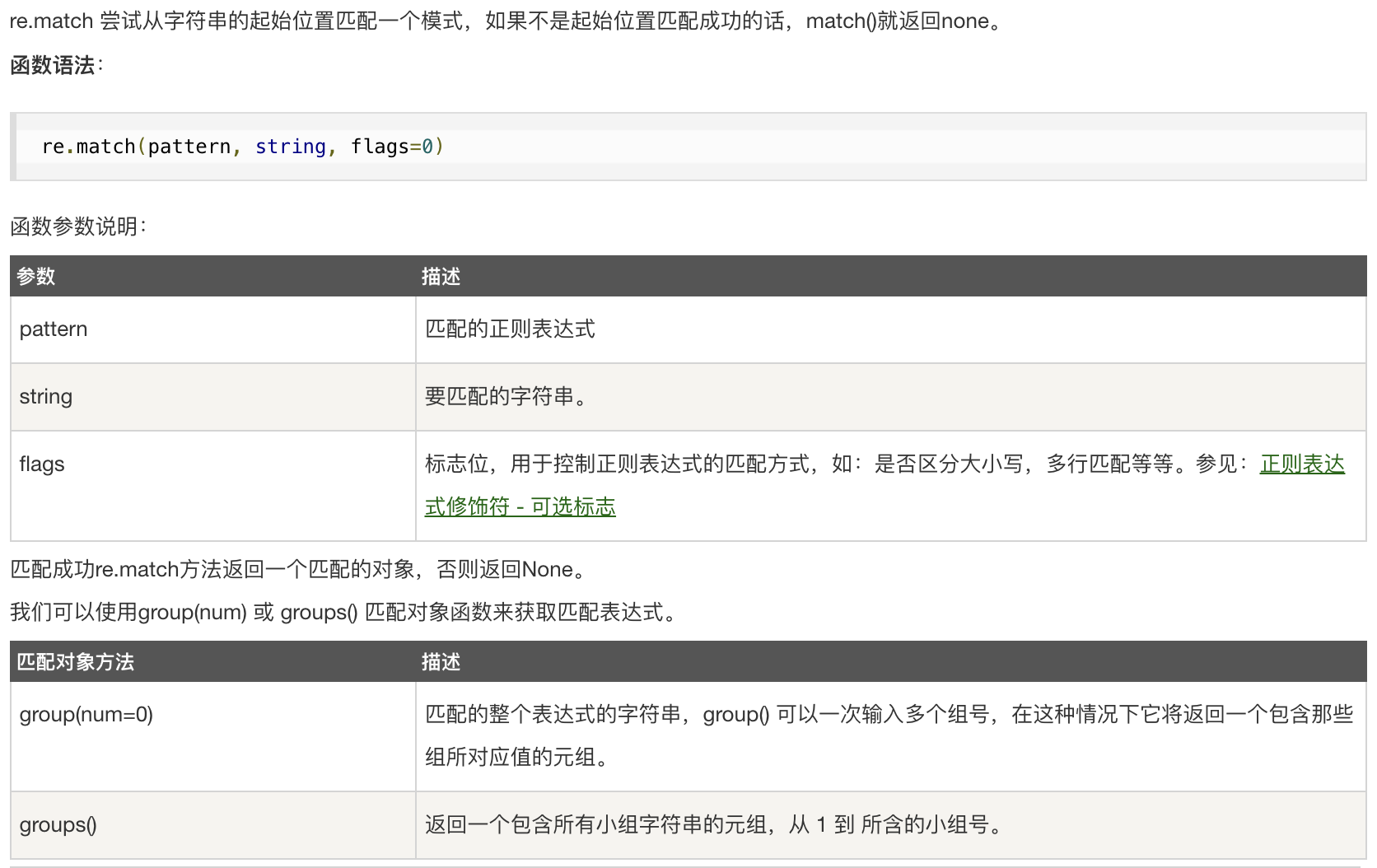
- `re.match`
# 提取出pythonkey = "javapythonc++php"print(re.findall('python', key)[0])# 提取出hello worldkey = "hello world"print(re.findall('(.*)', key)[0])# 提取170string = '我喜欢身高为170的女孩'print(re.findall('\d+', string)[0])# 提取出http://和https://key = 'http://www.baidu.com and https://boob.com'print(re.findall('https?://', key))# 提取出hellokey = 'lalalahellohahah'print(re.findall('hello', key))# 提取出hit.key = 'bobo@hit.edu.com'print(re.findall('h.*?\.', key))# 匹配sas和saaskey = 'saas and sas and saaas're.findall('sa{1,2}s', key)

若有收获,就点个赞吧
0 人点赞
