机器翻译是语言理解的经典测试。它由语言分析和语言生成组成。大型机器翻译系统具有巨大的商业用途,给你一些值得注意的例子:
- 谷歌翻译每天翻译1000亿字;
- Facebook使用机器翻译自动翻译帖子和评论中的文字,以打破语言障碍,让世界各地的人们相互交流;
- 阿里巴巴使用机器翻译技术来实现跨境贸易,连接世界各地的买家和卖家;
- 微软为Android、iOS和Amazon Fire上的最终用户和开发人员提供基于人工智能的翻译,无论他们是否可以访问互联网。
在传统的机器翻译系统中,我们必须使用平行语料库:一组文本,每个文本都被翻译成一种或多种不同于原文的其他语言。
例如,给定源语言f(例如法语)和目标语言e(例如英语),我们需要建立多个统计模型,包括使用贝叶斯规则的概率公式,训练的翻译模型p(f | e)平行语料库和语言模型p(e)在纯英文语料库上训练。这种方法跳过了数百个重要细节,需要大量的手工特征工程,整体而言它是一个非常复杂的系统。
神经机器翻译是通过一个称为递归神经网络(RNN)的大型人工神经网络对整个过程进行建模的方法。RNN是一个有状态的神经网络,它通过时间连接过去。神经元的信息不仅来自前一层,而且来自更前一层的信息。

标准的神经机器翻译是一种端到端神经网络,其中,源语句由称为编码器的RNN 编码,目标词使用另一个称为解码器。RNN编码器一次读取一个源语句,然后在最后隐藏状态汇总整个源句子。RNN解码器使用反向传播学习这个汇总并返回翻译后的版本。
神经机器翻译从2014年的一项边缘研究领域发展到2016年广泛采用的领先机器翻译方式,那么,使用神经机器翻译的最大成功是什么?
- 端到端训练:NMT中的所有参数同时被优化,以最大限度地减少网络输出的损耗性能。
- 分布式表示的优势:NMT更好地利用单词和短语的相似性。
- 更好地探索上下文:NMT可以使用更多的上下文——源文本和部分目标文本以此进行更准确地翻译。
- 更流利的文本生成:深度学习文本生成质量高于平行语料库。
RNN的一个大问题是梯度消失(或爆炸)问题,其中取决于所使用的激活函数,随着时间的推移信息会迅速丢失。
直观地说,这不会成为一个很大问题,因为这些只是权重而不是神经元状态,但是时间的权重实际上是存储过去的信息的地方,如果权重达到0或1,000,000的值,那么以前的状态将不会提供很多信息。
因此,RNNs在记忆序列中的前几个单词时会表现的很困难,并且只能根据最近的单词进行预测。
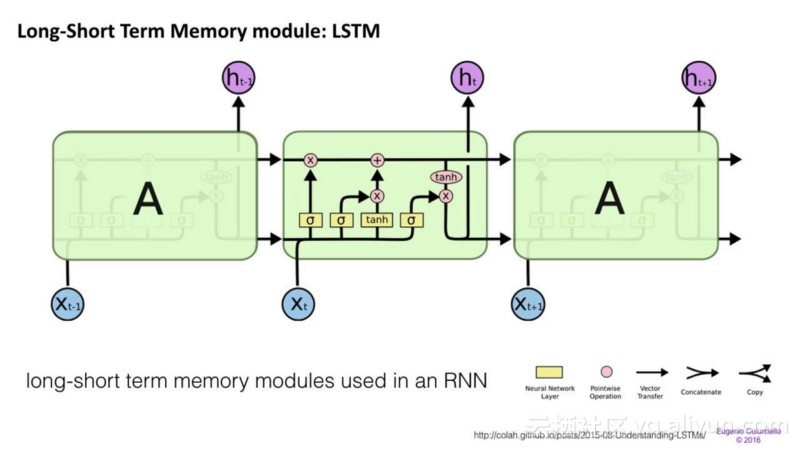
长期/短期记忆(LSTM)网络试图通过引入门和明确定义的存储器单元来对抗梯度消失/爆炸问题。每个神经元都有一个存储单元和三个门:输入、输出和忘记。这些门的功能是通过停止或允许信息流来保护信息。
①输入门决定了来自上一层的多少信息存储在单元中;
②输出层在另一端获取任务,并确定下一层有多少单元知道该单元的状态。
③忘记门的作用起初看起来很奇怪,但有时候忘记门是个不错的设计:如果它正在学习一本书并开始新的一章,那么网络可能需要忘记前一章中的一些字符。
已经证明LSTM能够学习复杂的序列,例如像莎士比亚的写作或者创作原始音乐。请注意,这些门中的每一个都对前一个神经元中的一个单元具有权重,因此它们通常需要更多资源才能运行。
LSTM目前非常流行,并且在机器翻译中被广泛使用。除此之外,它是大多数序列标签任务的默认模型,其中有大量的数据。
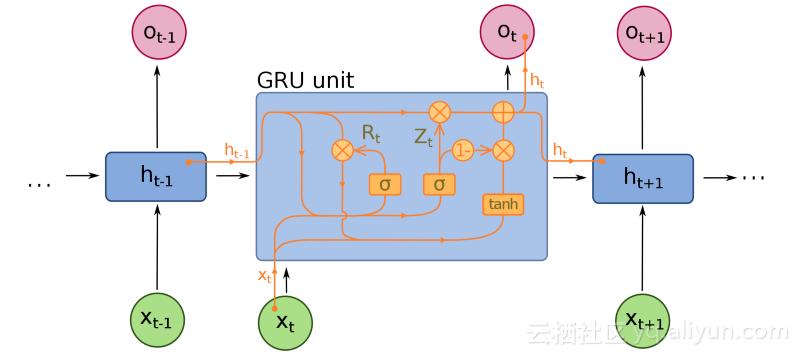
门控重复单元(GRU)是在LSTM的基础上变形得来的,也是神经机器翻译的扩展。它拥有更少的门,并且连接方式略有不同:它不是输入、输出和忘记门组成的,而是具有更新门。这个更新门决定了从最后一个状态开始保留多少信息以及从上一个层开始输入多少信息。
复位(reset)门的功能与LSTM的忘记(forget)门非常相似,但位置稍有不同。他们总是发出它们完整的状态因为他们没有输出门。在大多数情况下,它们的功能与LSTM非常相似,最大的不同之处在于GRUs稍快并且更容易运行(但表现力稍差)。
在实践中,这些往往会互相抵消,因为你需要一个更大的网络来重新获得一些表示能力,这反过来又抵消了性能的优势。在一些情况下,GRU可以胜过LSTM。
除了这三大体系结构之外,过去几年神经机器翻译系统还有进一步的改进。以下是最显着的发展:
- 用神经网络进行序列学习的序列证明了LSTM在神经机器翻译中的有效性。它提出了序列学习的一种通用的端到端方法,对序列结构进行了最少的假设。该方法使用多层Long Short Term Memory(LSTM)将输入序列映射为固定维度的向量,然后使用另一个深度LSTM从向量解码目标序列。
- 通过联合学习对齐和翻译的神经机器翻译引入了NLP中的注意机制(将在下一篇文章中介绍)。认识到使用固定长度矢量是提高NMT性能的瓶颈,作者建议通过允许模型自动(软)搜索与预测目标相关的源句子部分来扩展,而不必将这些部分明确地形成为一个固定的长度。
- 用于神经机器翻译的循环编码器上的卷积利用附加的卷积层增强NMT中的标准RNN编码器,以在编码器输出中捕捉更广泛的上下文。 谷歌的神经机器翻译,它解决了准确性和部署方便性的问题。该模型由一个深度LSTM网络组成,该网络包含8个编码器和8个解码器层,使用残余连接以及从解码器网络到编码器的注意力连接。
- Facebook AI研究人员不使用递归神经网络,而是使用卷积神经网络序列对NMT中的学习任务进行排序。

若有收获,就点个赞吧
0 人点赞
