本题解析的主要来源:https://zhuanlan.zhihu.com/p/48612853
10月11日,Google AI Language 发布了论文BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding,提出的 BERT 模型在 11 个 NLP 任务上的表现刷新了记录,包括问答 Question Answering (SQuAD v1.1),推理 Natural Language Inference (MNLI) 等:
GLUE :General Language Understanding Evaluation
MNLI :Multi-Genre Natural Language Inference
SQuAD v1.1 :The Standford Question Answering Dataset
QQP : Quora Question Pairs
QNLI : Question Natural Language Inference
SST-2 :The Stanford Sentiment Treebank
CoLA :The Corpus of Linguistic Acceptability
STS-B :The Semantic Textual Similarity Benchmark
MRPC :Microsoft Research Paraphrase Corpus
RTE :Recognizing Textual Entailment
WNLI :Winograd NLI
SWAG :The Situations With Adversarial Generations
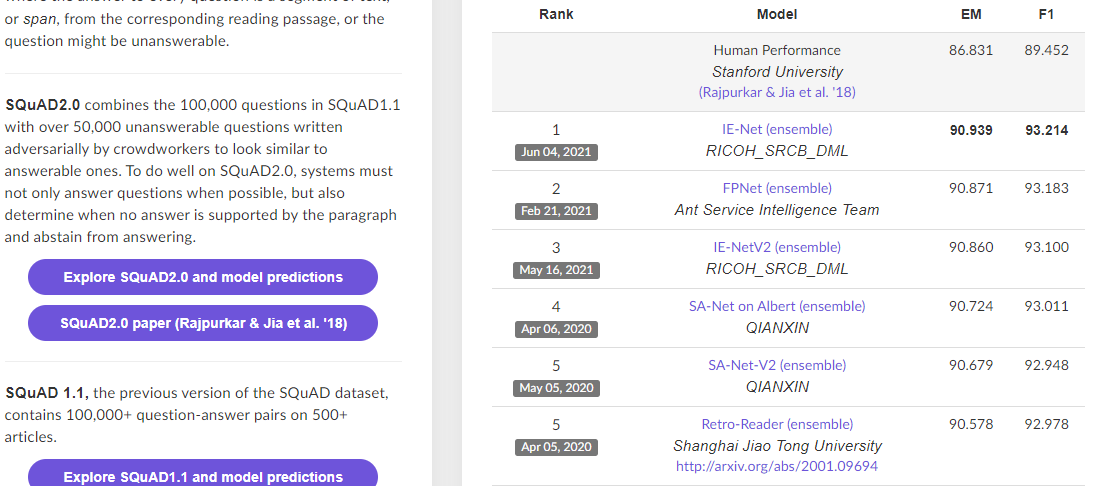
让我们先来看一下 BERT 在 Stanford Question Answering Dataset (SQuAD) 上面的排行榜吧:
https://rajpurkar.github.io/SQuAD-explorer/
1.BERT 可以用来干什么?
BERT 可以用于问答系统,情感分析,垃圾邮件过滤,命名实体识别,文档聚类等任务中,作为这些任务的基础设施即语言模型,
BERT 的代码也已经开源:
https://github.com/google-research/bert
我们可以对其进行微调,将它应用于我们的目标任务中,BERT 的微调训练也是快而且简单的。
例如在 NER 问题上,BERT 语言模型已经经过 100 多种语言的预训练,这个是 top 100 语言的列表:
https://github.com/google-research/bert/blob/master/multilingual.md
只要在这 100 种语言中,如果有 NER 数据,就可以很快地训练 NER。
2. BERT 原理简述
BERT(Bidirectional Encoder Representations from Transformers)近期提出之后,作为一个Word2Vec的替代者,其在NLP领域的11个方向大幅刷新了精度,可以说是近年来自残差网络最优突破性的一项技术了。论文的主要特点以下几点:
- 使用了双向Transformer作为算法的主要框架,之前的模型是从左向右输入一个文本序列,或者将 left-to-right 和 right-to-left 的训练结合起来,实验的结果表明,双向训练的语言模型对语境的理解会比单向的语言模型更深刻;
- 使用了Mask Language Model(MLM)和 Next Sentence Prediction(NSP) 的多任务训练目标;
- 使用更强大的机器训练更大规模的数据,使BERT的结果达到了全新的高度,并且Google开源了BERT模型,用户可以直接使用BERT作为Word2Vec的转换矩阵并高效的将其应用到自己的任务中。
Transformer由论文《Attention is all you need》中提出,其最大的特点是抛弃了传统的RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1,有效的解决了NLP中棘手的长期依赖问题。Transformer的结构在NLP领域中已经得到了广泛应用,并且作者已经发布在TensorFlow的tensor2tensor库中。
Transformer是一个encoder-decoder的结构,由若干个编码器,和解码器堆叠形成。
如下图所示,左侧部分为编码器,负责接收文本作为输入,由Multi-Head Attention和一个全连接组成,用于将输入语料转化成特征向量;
右侧部分是解码器,其输入为编码器的输出以及已经预测的结果,由Masked Multi-Head Attention, Multi-Head Attention以及一个全连接组成,用于输出最后结果的条件概率。
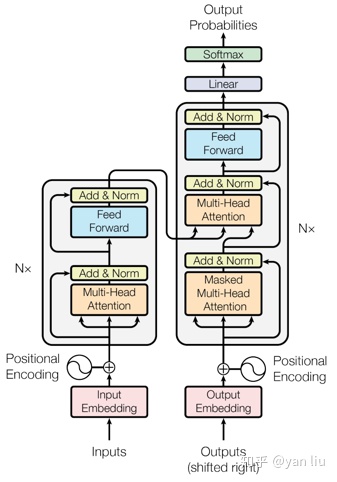
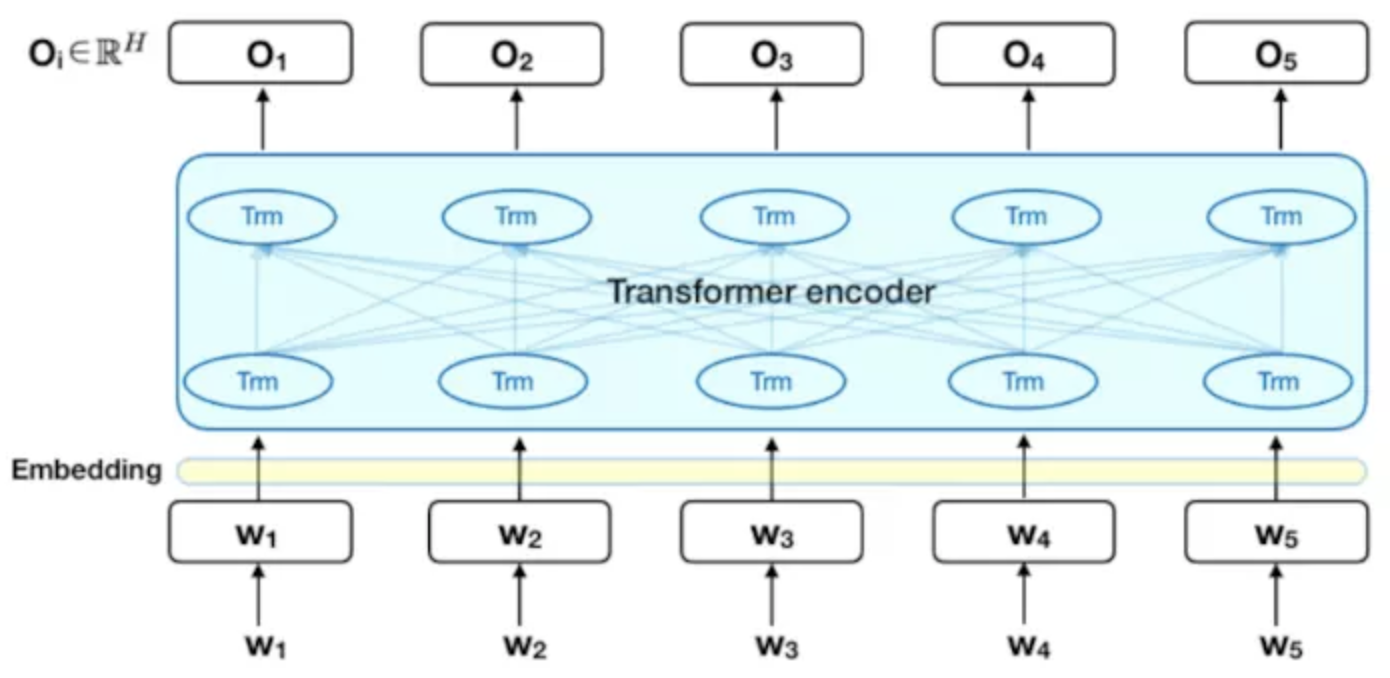
不过,BERT 只利用了 Transformer 的 encoder 部分。因为BERT 的目标是生成语言模型,所以只需要 encoder 机制。
下图是 Transformer 的 encoder 部分,输入是一个 token 序列,先对其进行 embedding 称为向量,然后输入给神经网络,输出是大小为 H 的向量序列,每个向量对应着具有相同索引的 token。
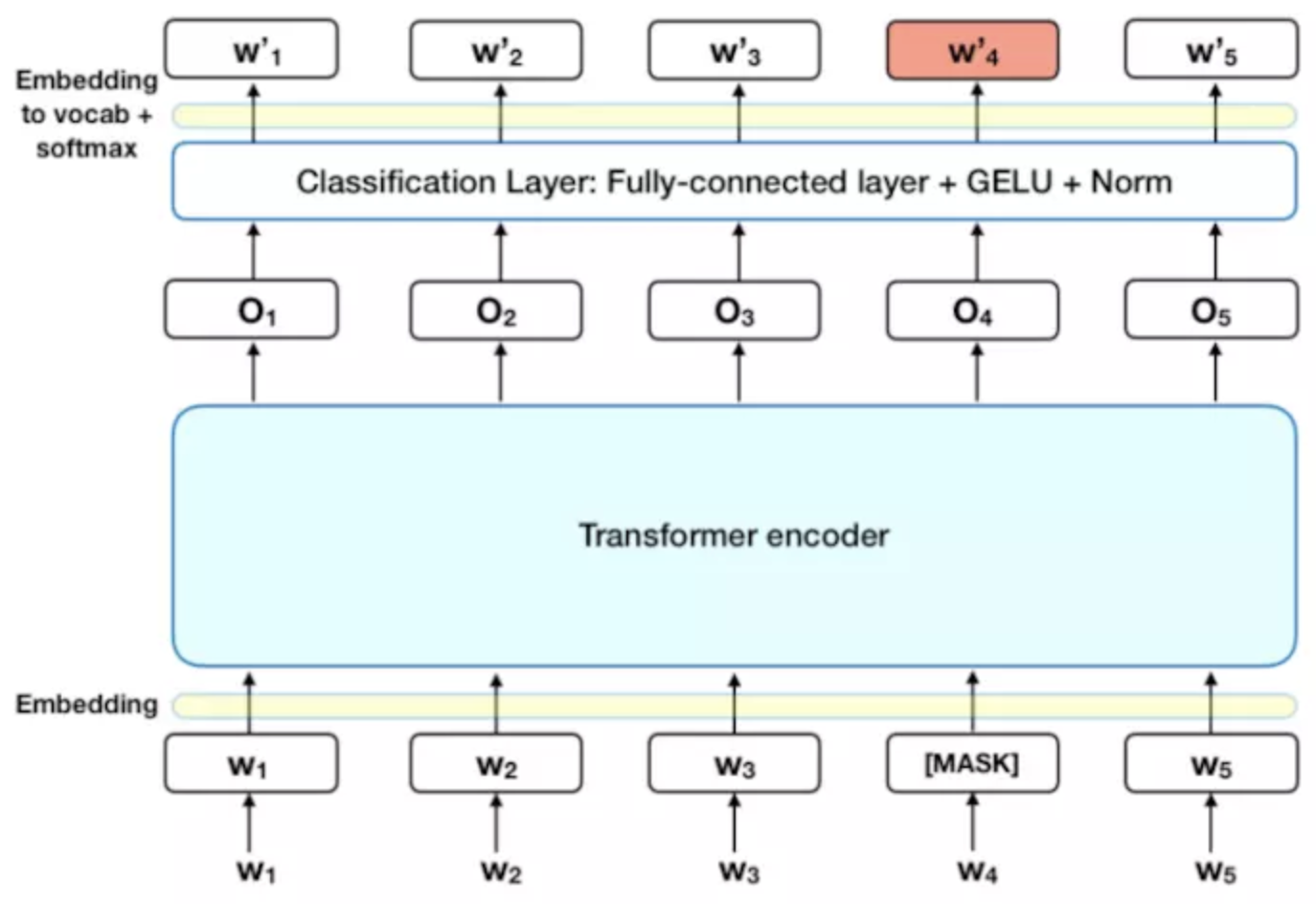
当我们在训练语言模型时,有一个挑战就是要定义一个预测目标,很多模型在一个序列中预测下一个单词,
“The child came home from _”
双向的方法在这样的任务中是有限制的,为了克服这个问题,BERT 使用两个策略:
- Masked LM (MLM)
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词。
这样就需要:
i)在 encoder 的输出上添加一个分类层
ii)用嵌入矩阵乘以输出向量,将其转换为词汇的维度
iii)用 softmax 计算词汇表中每个单词的概率
BERT 的损失函数只考虑了 mask 的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。
插注1:「 这个问题,有必要再进一步阐述下,实际上,“Masked Language Model(MLM)和核心思想取自Wilson Taylor在1953年发表的一篇论文。所谓MLM是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。正如传统的语言模型算法和RNN匹配那样,MLM的这个性质和Transformer的结构是非常匹配的。
在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,80%的概率会直接替换为[Mask],10%的概率将其替换为其它任意单词,10%的概率会保留原始Token。
80%:my dog is hairy -> my dog is [mask]
10%:my dog is hairy -> my dog is apple
10%:my dog is hairy -> my dog is hairy
这么做的原因是如果句子中的某个Token100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词。加入随机Token的原因是因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ’hairy‘。至于单词带来的负面影响,因为一个单词被随机替换掉的概率只有15%*10% =1.5%,这个负面影响其实是可以忽略不计的。
另外文章指出每次只预测15%的单词,因此模型收敛的比较慢。”」
- Next Sentence Prediction (NSP)
在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。
在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。
为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:
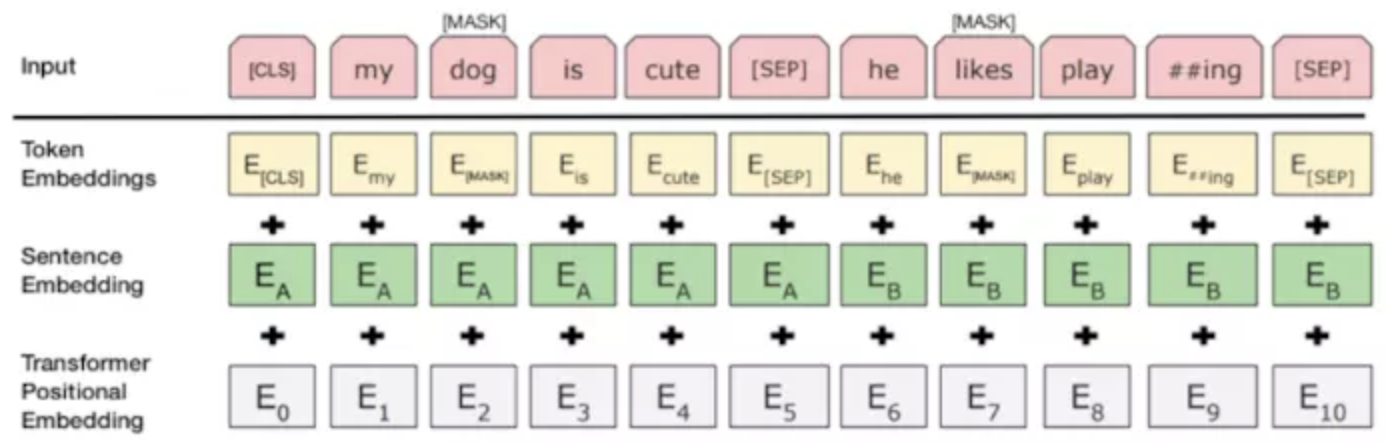
在第一个句子的开头插入 [CLS] 标记,表示该特征用于分类模型,对非分类模型,该符号可以省去,在每个句子的末尾插入 [SEP] 标记,表示分句符号,用于断开输入语料中的两个句子。
将表示句子 A 或句子 B 的一个句子 embedding 添加到每个 token 上。
给每个 token 添加一个位置 embedding,来表示它在序列中的位置。
为了预测第二个句子是否是第一个句子的后续句子,用下面几个步骤来预测:
- 整个输入序列输入给 Transformer 模型
- 用一个简单的分类层将 [CLS] 标记的输出变换为 2×1 形状的向量
- 用 softmax 计算 IsNextSequence 的概率
- 在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
插注2:「“换句话说,Next Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在BERT输入表示图中的[CLS]符号中。”
且BERT的输入的编码向量(长度是512)是3个嵌入特征的单位和,这三个词嵌入特征是:
- 位置嵌入(Position Embedding):位置嵌入是指将单词的位置信息编码成特征向量,位置嵌入是向模型中引入单词位置关系的至关重要的一环;
- WordPiece 嵌入:WordPiece是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。例如上图的示例中‘playing’被拆分成了‘play’和‘ing’;
- 分割嵌入(Segment Embedding):用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1。」
3. 如何使用 BERT?
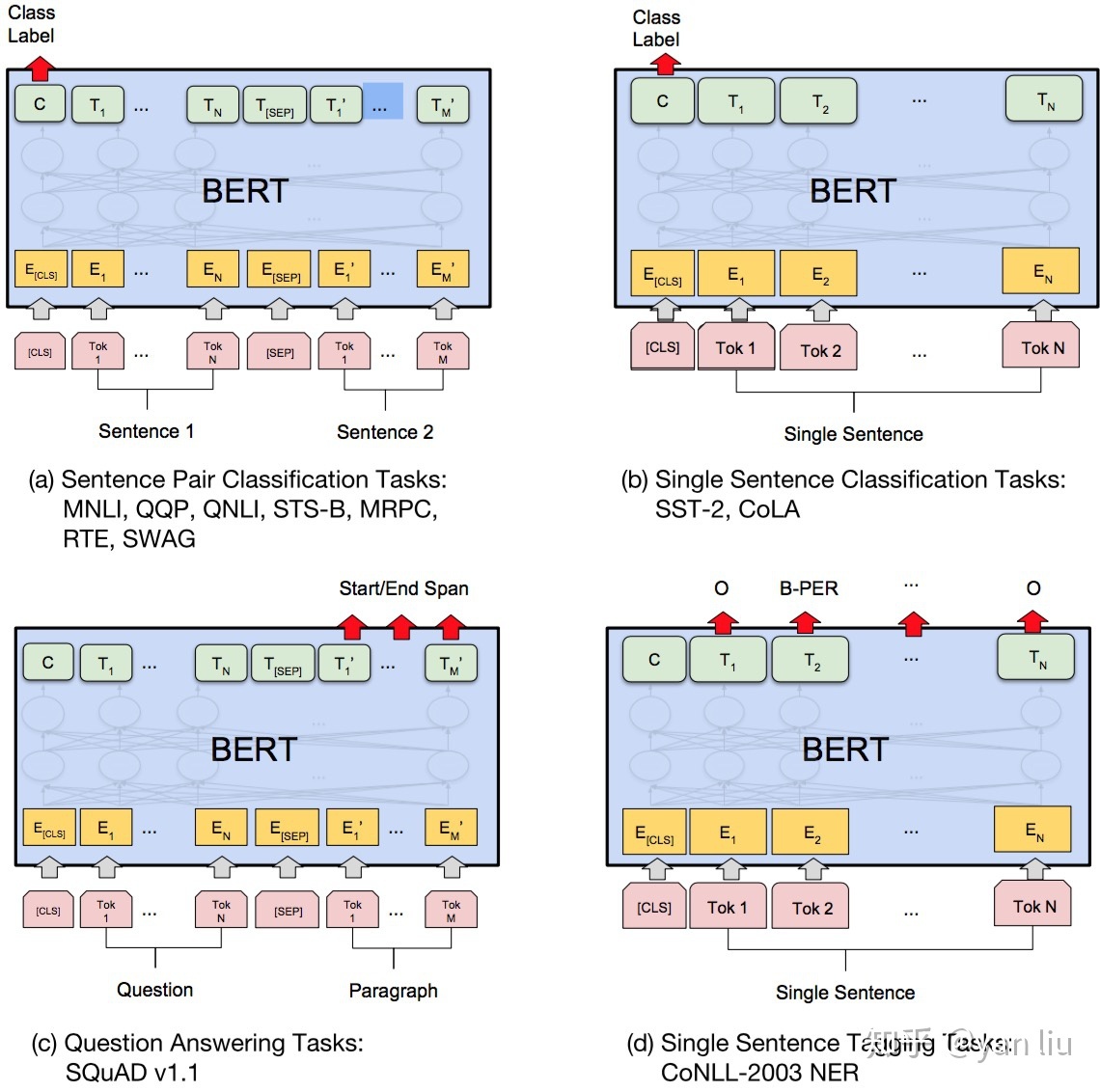
在海量单预料上训练完BERT之后,便可以将其应用到NLP的各个任务中了。对于NSP任务来说,其条件概率表示为,其中是BERT输出中的[CLS]符号,是可学习的权值矩阵。对于其它任务来说,我们也可以根据BERT的输出信息作出对应的预测。下图展示了BERT在11个不同任务中的模型,它们只需要在BERT的基础上再添加一个输出层便可以完成对特定任务的微调。这些任务类似于我们做过的文科试卷,其中有选择题,简答题等等。下图中其中Tok表示不同的Token,表示嵌入向量,表示第个Token在经过BERT处理之后得到的特征向量。
4. 微调的任务包括
4.1 基于句子对的分类任务:
MNLI:给定一个前提 (Premise) ,根据这个前提去推断假设 (Hypothesis) 与前提的关系。该任务的关系分为三种,蕴含关系 (Entailment)、矛盾关系 (Contradiction) 以及中立关系 (Neutral)。所以这个问题本质上是一个分类问题,我们需要做的是去发掘前提和假设这两个句子对之间的交互信息。
QQP:基于Quora,判断 Quora 上的两个问题句是否表示的是一样的意思。
QNLI:用于判断文本是否包含问题的答案,类似于我们做阅读理解定位问题所在的段落。
STS-B:预测两个句子的相似性,包括5个级别。
MRPC:也是判断两个句子是否是等价的。
RTE:类似于MNLI,但是只是对蕴含关系的二分类判断,而且数据集更小。
SWAG:从四个句子中选择为可能为前句下文的那个。
4.2 基于单个句子的分类任务
SST-2:电影评价的情感分析。
CoLA:句子语义判断,是否是可接受的(Acceptable)。
对于GLUE数据集的分类任务(MNLI,QQP,QNLI,SST-B,MRPC,RTE,SST-2,CoLA),BERT的微调方法是根据[CLS]标志生成一组特征向量,并通过一层全连接进行微调。损失函数根据任务类型自行设计,例如多分类的softmax或者二分类的sigmoid。SWAG的微调方法与GLUE数据集类似,只不过其输出是四个可能选项的softmax:
4.3 问答任务
SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本,输出这个问题的答案,类似于做阅读理解的简答题。如上图中(c)表示的,SQuAD的输入是问题和描述文本的句子对。输出是特征向量,通过在描述文本上接一层激活函数为softmax的全连接来获得输出文本的条件概率,全连接的输出节点个数是语料中Token的个数。
4.4 命名实体识别
CoNLL-2003 NER:判断一个句子中的单词是不是Person,Organization,Location,Miscellaneous或者other(无命名实体)。微调CoNLL-2003 NER时将整个句子作为输入,在每个时间片输出一个概率,并通过softmax得到这个Token的实体类别。
Reference
[1] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[2] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [C]//Advances in Neural Information Processing Systems. 2017: 5998-6008.
[3] Wilson L Taylor. 1953. cloze procedure: A new tool for measuring readability. Journalism Bulletin, 30(4):415–433.
[4] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning. Technical report, OpenAI.
[5] Matthew Peters, Waleed Ammar, Chandra Bhagavatula, and Russell Power. 2017. Semi-supervised sequence tagging with bidirectional language models. In ACL.
[6] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv:1609.08144.
[7] Wilson L Taylor. 1953. cloze procedure: A new tool for measuring readability. Journalism Bulletin, 30(4):415–433.
如果阅读此文,还没完全懂BERT,没事,可以继续看这篇全网最通俗的BERT详解:https://www.julyedu.com/question/big/kp_id/30/ques_id/3008

若有收获,就点个赞吧
0 人点赞
