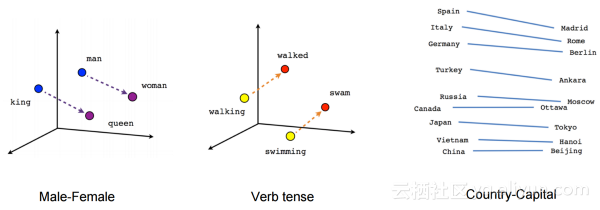
在传统的NLP中,我们将单词视为离散符号,然后可以用one-hot向量表示。向量的维度是整个词汇表中单词的数量。单词作为离散符号的问题在于,对于one-hot向量来说,没有自然的相似性概念。
因此,另一种方法是学习在向量本身中编码相似性。核心思想是一个词的含义是由经常出现在其旁边的单词给出的。
文本嵌入是字符串的实值向量表示。我们为每个单词建立一个密集的向量,选择它以便类似于类似上下文中出现的单词的向量。对于大多数NLP任务而言,词嵌入被认为是一个很好的起点。它们允许深度学习在较小的数据集上也是有效的,因为它们通常是深度学习体系的第一批输入,也是NLP中最流行的迁移学习方式。
在词嵌入中最流行的应该是Word2vec,它是由谷歌(Mikolov)开发的模型,另外一个是由斯坦福大学(彭宁顿,Socher和曼宁)开发的GloVe。
接着我们重点介绍这两种模型:
在Word2vec中,我们有一个庞大的文本语料库,其中固定词汇表中的每个词都由一个向量表示。然后,我们通过文本中的每个位置t,其中有一个中心词c和上下文词o。
接下来,我们使用字向量的相似性Ç和Ò计算的概率ø给出Ç(或反之亦然)。我们不断调整单词向量来最大化这个概率。为了有效地训练Word2vec,我们可以从数据集中去除无意义的单词。这有助于提高模型的准确性。
Word2vec有两个变体值得一提:
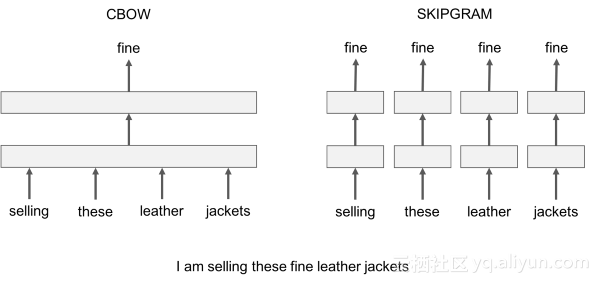
1.Skip-Gram:我们考虑一个包含k个连续项的上下文窗口。 然后,我们跳过其中一个单词,尝试学习一个神经网络,该网络可以获得除跳过的所有术语外的所有术语,并预测跳过的术语。 因此,如果两个单词在大语料库中反复共享相似的上下文,那么这些术语的嵌入向量将具有相似的向量。
2.Continuous Bag of Words:我们在一个大的语料库中获取大量的句子,每当我们看到一个词,我们就会联想到周围的词。 然后,我们将上下文单词输入到神经网络,并预测该上下文中心的单词。 当我们有数千个这样的上下文单词和中心单词时,我们就有了一个神经网络数据集的实例。我们训练神经网络,最后编码的隐藏层输出表示一个特定的词嵌入。
当我们通过大量的句子进行训练时,类似上下文中的单词会得到相似的向量。
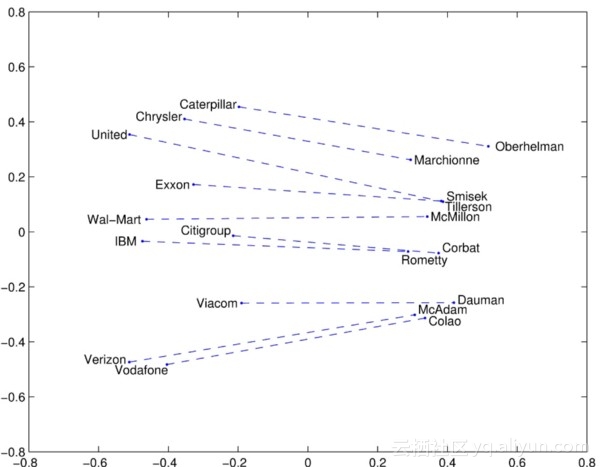
对Skip-Gram和CBOW的一个吐槽就是它们都是基于窗口的模型,这意味着语料库的共现统计不能被有效使用,导致次优的嵌入(suboptimal embeddings)。
GloVe模型旨在通过捕捉一个字与整个观测语料库的结构嵌入的含义来解决这个问题。为此,该模型训练单词的全局共现次数,并通过最小化最小二乘误差来充分利用统计量,从而产生具有有意义子结构的单词向量空间。这样的做法足以保留单词与向量距离的相似性。
除了这两种文本嵌入外,还有许多最近开发的高级模型,包括FastText,Poincare嵌入,sense2vec,Skip-Thought,Adaptive Skip-Gram,我强烈建议你学习一下。

若有收获,就点个赞吧
0 人点赞
