根据键的分区类型
- 范围分区:如0-500是一个曲,501-1000是一个区
散列分区:把键hash了再分区,好处是均衡,坏处是无法范围查找,Cassandra、MongoDB、Voldemort 如是做
分区与次级索引
分区的痛点是次级索引不能简单地像单表一样作用于一个表中的所有数据,有两种主要策略创建分区下的次级索引:
基于文档的分区次级索引

如图,对color的次级索引在每个分区都全部构建,并且其范围仅仅包括当前分区,不同分区完全独立。这种方法在使用次级索引时需要并行查询所有分区,所以尾部延迟会放大,但是胜在稳定且鲁棒性强,ES,MongoDB、Cassandra都使用此方式基于关键词的分区次级索引
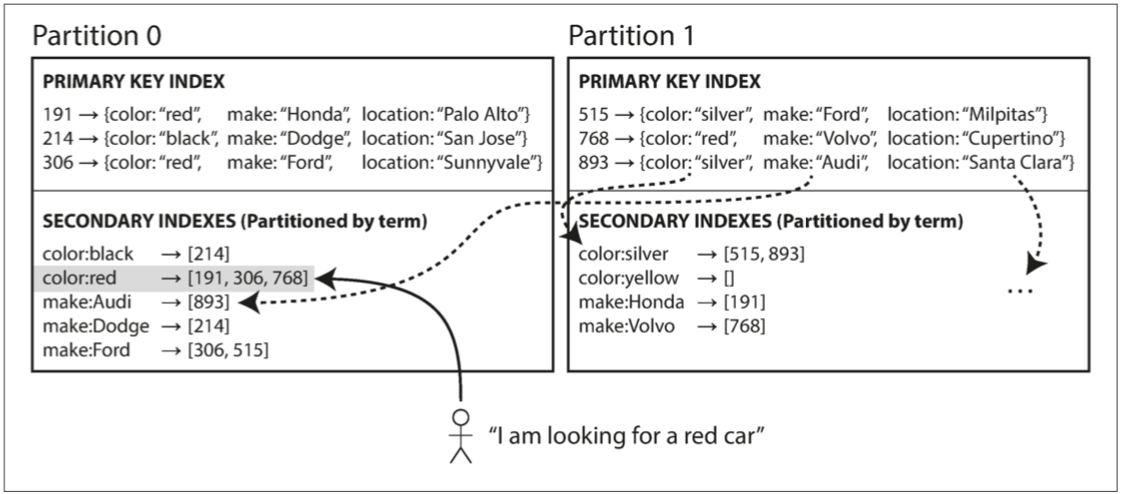
如图,对次级索引也进行分区哈希或字典序,但一个次级索引就包含全部分区信息,此种索引对范围扫描支持较好,C端只需对索引所在分区请求即可读取索引。
但是,这种索引的更新慢且复杂,高写入状态是也有可能产生热点分区,所以使用者并不多分区再平衡(rebalancing)
随数据与机器变化需要将数据从节点移动的操作称为分区再平衡,此操作要满足:
再平衡后,负载不应更不公平
- 再平衡发生时,数据库应能继续接受读写请求
- 节点之间只移动必要的数据
再平衡策略
坏策略:hash mod N
坏就坏在需要移动非必需数据固定数量分区
创建比节点更多的分区,并为每个节点分配多个分区。此后如果一个节点被添加到集群中,新节点可以从当前每个节点中窃取一些分区,直至分区分配公平,删除时,余下的节点窃取释放的分区。
此方法的关键在于选取合适数量的分区,因为相当多DB不提供分区分割与合并的功能。ES、riak、Couchbase 和 Voldemort 中使用了这种再平衡的方法。动态分区
对于使用键范围分区的数据库,固定边界固定数量的分区可能使得分区没有数据,这会提升调度成本。
因此按键的范围进行分区的数据库(HBase、RethinkDB)将动态创建分区。当分区增长到超过配置大小时会“基本公平地”被分割,与之相反,如果大量数据被删除并且分区缩小到某个阈值以下,则可以将其与相邻分区合并。此过程与 B 树顶层发生的过程类似。
HBase和MongoDB允许在空数据库上配置初始分区,此为预分割,显然它应当以知道键的分布情况为前提。
显然动态分区不仅适用于数据的范围分区,而且也适用于散列分区。从版本 2.4 开始,MongoDB 同时支持范围和散列分区,并且都支持动态分割分区。
按节点比例分割
此方法下,每个节点具有固定数量的分区,每个分区大小与数据集大小成比例增长。当增加节点时,分区将被分割并再次变小。Cassandra和Ketama如是做。
新节点加入集群时,它岁计算则一个节点对应固定数量的分区对半分,占有其一半,将剩下的一半留在原地。这会产生不公平分割,但是分区数量增加时(Cassandra默认1:256),这个不公平会被基本抹平,同时Cassandra引入了另一种再平衡算法避免不公平分割。
此种分区方法更适合散列分区,并且与“一致性哈希”较完美地契合。
请求路由
可用的大概可分两种:
- 有backbone,如zookeeper或者其他configserver作为服务发现组件
- 用gossip协议传播节点状态,增加复杂度但不依赖zookeeper

若有收获,就点个赞吧
0 人点赞
