逻辑日志
MySQL的binlog使用逻辑日志,与物理日志区分开来:关系数据库的逻辑日志通常是以行的粒度来描述对数据库表的写入记录的序列:
对仅能由自己写的库,对自己的内容仅从主库读(主库压力大),其他内容在从库读
- 否则,可以设定一些标准,如对1min内的写入的读读主库,否则读从库
- 客户端记录写入时间戳,读从库时确保读更新时间戳新于最近写入时间戳的从库,或者等待没到指定时间戳的从库知道其满足要求
- 对多设备、多数据中心的情况应当有额外设计
单调读
先读一个快从库后读一个慢从库可能产生时光倒流,单调读保证一个用户顺序多次读取,不会看到时间回退,即若读到新数据,不会再读到旧数据。
解决方法:”时光倒流”问题是由于对一个数据读不同从库产生的,可以通过用户IDhash到固定的从库去读。一致前缀读
如果一系列写入按指定顺序发生,读取者应当也按照这个顺序读取(这个问题是读同一个库,但是是不同分区/分片,与上一个问题读不同库有区别)。
解决方法:确保有因果关系的写入发生在同一分区多数据中心多主下的写入冲突处理
一个数据中心构成一个主从架构,能够使得地理上贴近用户,但是有多主要处理独立的主库的写入冲突。1. 冲突避免
对单个用户(或单个用户的一定地理范围)对其指定一个数据中心进行读写,这能解决大部分情况下的问题。
当地理位置大幅改变或数据中心失效而需要变更绑定新数据中心时,冲突就无法避免,此时需要其他机制。
2. 确保状态一致/收敛
确保每个值在所有写入复制后收敛到一个结果,实现方法:
- 给每一个写入一个唯一ID(UUID、K+V的哈希、长随机数、时间戳等),挑选ID最高者写入,这种技术被称为 最后写入胜利(LWW, last write wins)。其较简单,但容易造成数据丢失;
- 为每一个副本(即数据中心)分配一个UID,编号更高者写入优先级更高,但这种方法也意味着写入丢失;
- 将值合并并按字母顺序排列(个人感觉有点扯但是最简单);
用一种可保留所有信息的显式数据结构来记录冲突,并编写解决冲突的应用程序代码(也许通过提示用户的方式)。
3. 自定义冲突解决逻辑
自定义冲突解决逻辑需要取决于应用程序,因此大多数多主复制工具允许通过应用程序编写代码解决冲突,有2个执行环节:
写时执行(Bucardo):只要系统检测到复制更改log时的冲突,就运行冲突解决程序。
- 读时执行(CouchDB):检测到冲突时存储冲突的所有值,读取时将多个冲突值全部返回使得应用程序处理冲突或由用户决策,解决后再写会所有DB。
已经有一些有趣的研究来自动解决由于数据修改引起的冲突。有几项研究值得一提:
- 无冲突复制数据类型(Conflict-free replicated datatypes,CRDT)【32,38】是可以由多个用户同时编辑的集合、映射、有序列表、计数器等一系列数据结构,它们以合理的方式自动解决冲突。一些 CRDT 已经在 Riak 2.0 中实现【39,40】。
- 可合并的持久数据结构(Mergeable persistent data structures)【41】显式跟踪历史记录,类似于 Git 版本控制系统,并使用三向合并功能(而 CRDT 使用双向合并)。
- 操作转换(operational transformation)[42] 是 Etherpad 【30】和 Google Docs 【31】等协同编辑应用背后的冲突解决算法。它是专为有序列表的并发编辑而设计的,例如构成文本文档的字符列表。
这些算法在数据库中的实现还很年轻,但很可能将来它们会被集成到更多的复制数据系统中。自动冲突解决方案可以使应用程序处理多主数据同步更为简单。
因果冲突
多主复制下会产生若干因果冲突,如一个update要依赖另一个主节点insert进的行,这两个操作出现在两个主节点时,第三个节点就可能产生因果错乱: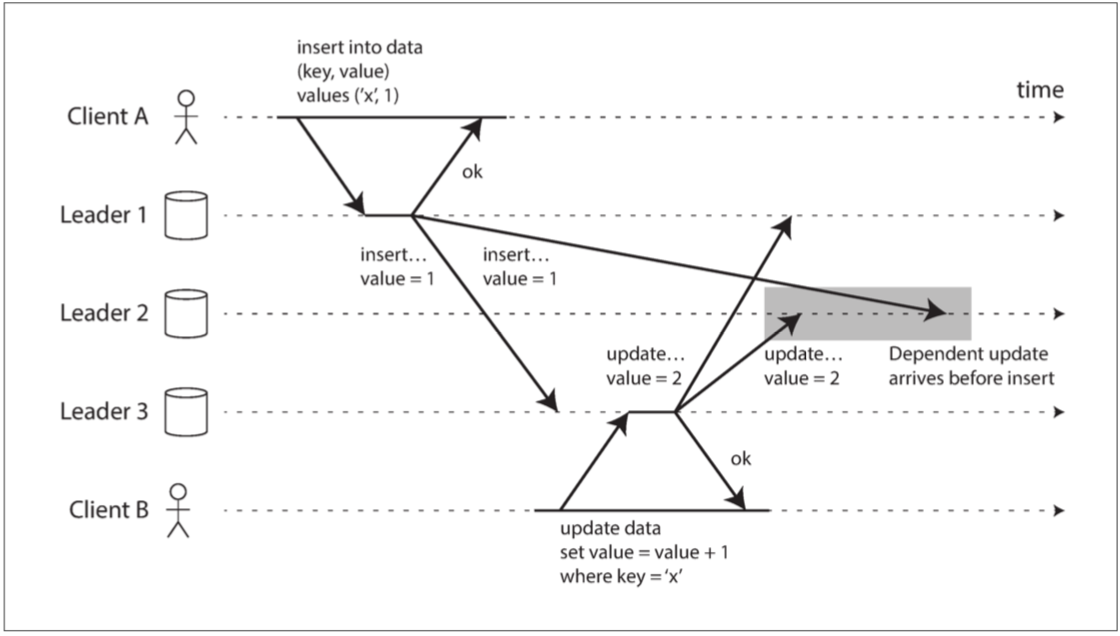
要正确排序这些事件,可以使用一种称为 版本向量(version vectors) 的技术。
无主复制
模式:每次写入都尝试写入所有副本,读取时尝试读取一定量的副本,并根据结果的版本号确定读取结果。
副本赶上错过的写入的方法:
- 读修复,即读时写会最新值,开销小但要应用读时才起作用,长时间不读的值就可能会丢失
反熵过程,相当于持续检查副本,并从新版本节点拉取变更到老版本节点
读写法定人数(Quorum)
基本的Quorum公式:如果对指定的region有n个副本,要求写入时必须至少w个节点确认才算成功,读取时必须至少查询r个节点,则应有:

这一限定被称为严格的Quorum,与之后的宽松对应。
常见的dynamo风格:通用:n为奇数,w=r=(n+1)/2
- 读多写少:w=n,r=1
另外:
- w<n时,n-w代表写入时可容忍不可用的节点数
r
宽松的法定人数(sloppy quorum)与提示移交
在一个大型的集群中(节点数量明显多于 n 个),SQ规定写和读仍然需要 w 和 r 个成功的响应,但这些响应可能来自不在指定的 n 个 “主” 节点中的其它节点;一旦网络中断得到解决,一个节点代表另一个节点临时接受的任何写入都将被发送到适当的 “主” 节点。这就是所谓的 提示移交(hinted handoff)
如此,只要任何时刻有在写时有w个,读时有r个节点可用,就可以执行读写操作。然而,这意味着即使当 w + r > nw+r>n 时,也不能确保读取到某个键的最新值,因为最新的值可能已经临时写入了 n 之外的某些节点。检测与处理并发写入
简单的LWW(只接受最后写)会丢失写的值,典型的场景是两个人共同向购物车增减东西,所以需要用版本号(在多副本时时版本号向量)捕获并发关系:


处理方法(单副本时,多副本以此类推):服务器为每个键维护一个版本号,每次对该键写入时递增版本号,并将新版本号与写入的值一起存储(即每个值对应一个版本号)
- 客户端读取键时,服务器需返回所有未覆盖的值及其最新版本号(这意味着服务端可能返回多个值,对应了多个版本号)。客户端在写入之前必须先读取以获得上述信息。
- 客户端写入键时,必须指定之前读取的版本号,且要将之前读取的所有值合并在一起作为单个值写入(当然到了DB,可能又因为有并发变成了多个值)。进一步,可以在写入之后返回所有处理后的当前值,这样可以避免下次写之前的读。
- 当服务器接收到具有特定版本号的写入时,它将用写入值覆盖<=给出版本号的值,并用更高的版本号标识它们,因为这些值与正在进行的其他写入也是并发的。(例子中的多值情况比较极端,实际上可以分析出,只要一个client连写两次,两个值就都会被覆盖掉,进而只剩1个值)
- 当要删除值时,不能简单地将key+版本号对应的值中的元素删去,这样在合并写入时,删去的值可能又会出现,正确的做法是设置墓碑,即一种删除标记,看到它客户端、服务端就会忽略对应值。

若有收获,就点个赞吧
0 人点赞
