- 1.各个层命名约定
- 2.通用职责约定
- 3.原则与注意点【重点】
- 3.1 应用层的 xxxAppServiceImpl 是汇总用例的文件,里面的一个方法只能调用一个 CmdExe
- 3.2【推荐】应用层的 xxxCmdExe 是一个命令所有相关代码写的地方,它负责调用网关gateway获取数据,调用domain或实体的能力按照业务规则处理数据, 调用网关gateway持久化数据 【若是有特别复杂的业务逻辑,可以沉淀到domainService,然后domainService顺便调用gateway进行持久化】
- 3.3~~
~~领域层的domainService与实体里只能有业务规则的代码,不允许使用gateway操作数据, 操作数据应当由应用层做 【删除本条】【允许】 - 3.4 实体、值对象、聚合他们自己内部应该通过get与set自校验,多个实体的业务规则(这个业务规则的行为放到哪个实体都不自然)放到domainService
- 3.5: 先把App做厚,再把App做薄
- 3.6: CmdExe 只可以引用 domain 的能力(gateway 、实体、领域服务) , 不可以直接用mapper或RPC
- 3.7:假如一个同一个实体被多个限界上下文用的划分方式:分别在两个限界上下文中各定义一次
- 3.8 注意转换(converter)与 构建(build)之间的区别: 转换是值拷贝与字段映射, 构建是带有业务逻辑的设置值
- 3.9 区分领域对象与数据库实体字段的区别:哪些字段是数据库实体的,但是领域对象上不应该有的
- 4.推荐的最佳实践
- 参考:
1.各个层命名约定
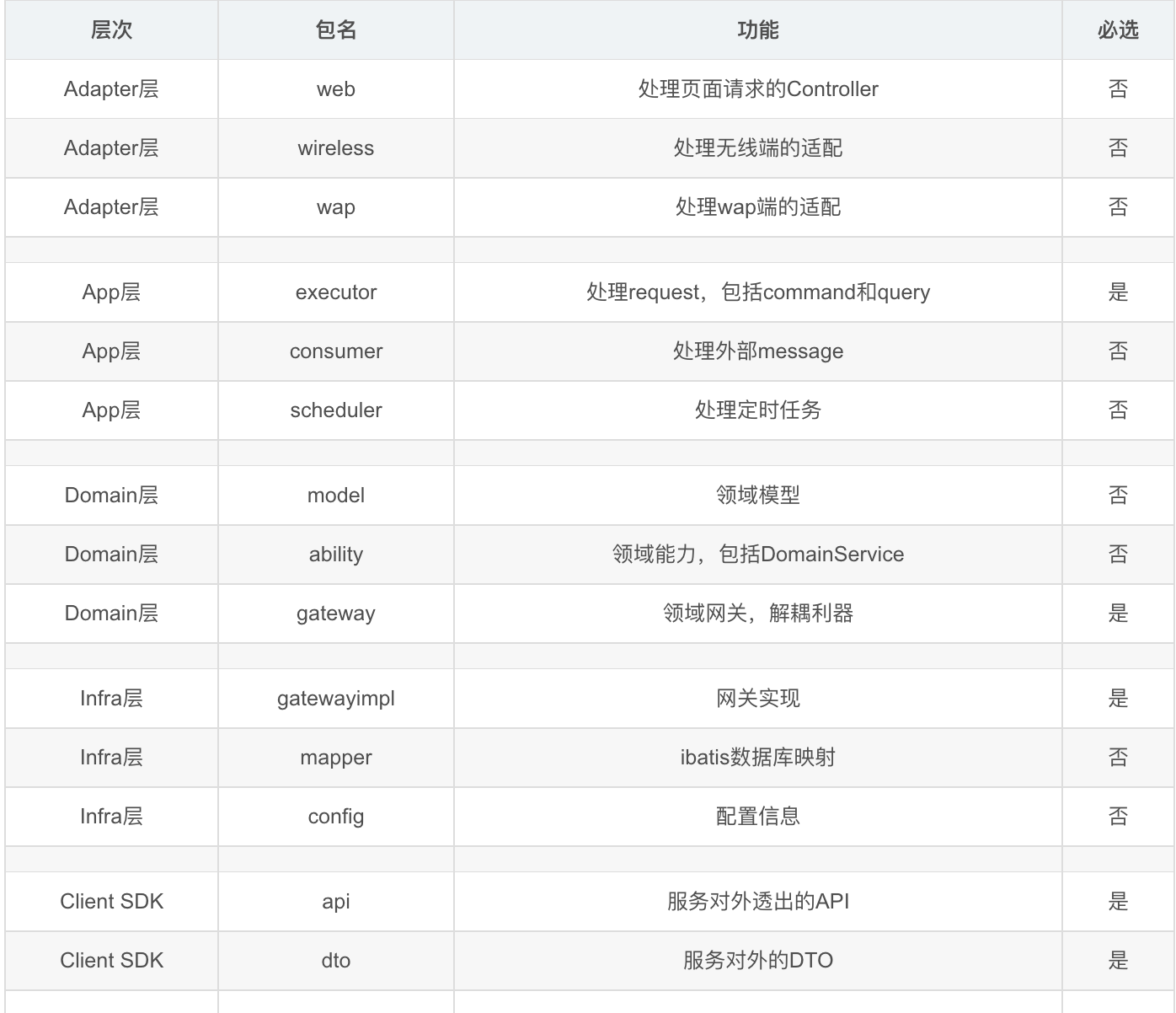
适配器层
web服务、定时任务、消费者分别为一个model :shebao-dispatch-ws、shebao-dispatch-task、shebao-dispatch-consumer , 拥有自己的启动类
文件命名
web服务:xxxController
定时任务:xxxJobHandler
消费者:xxxConsumer
**
入参与出参
定时任务和消费者的入参与返回都按照公司框架内要求即可
web服务:
入参:xxxDTO、xxxCmd
返回:xxxDTO、xxxVO
应用层(app和client)
文件命名
client-model中
api包 对外暴露的接口 xxxAppService
dto包 定义的外部参数,xxxAppServiceImpl汇总命令, 命令动作是 xxxCmd, 查询动作时 xxxQry
data包 普通数据传输对象 xxxDTO
event包 领域事件数据传输对象 xxxEvent
app-model中
consumer包 外部消息 xxxAppConsumer
scheduler包 定时任务 xxxAppobHandler
executor包 处理request xxxCmdExe
query 处理查询请求 xxxQryExe
入参与出参
xxxAppService 和 xxxCmdExe
入参: xxxCmd 【client中定义】
出参数: xxxDTO 【client中定义】
xxxQryExe
入参: xxxQry 【client中定义】
出参数: xxxDTO 【client中定义】
领域层
文件命名
domain-model中
domainservice包 放领域服务定义 xxxService
domainservice.impl 放领域服务实现 xxxServiceImpl
gateway包 定义网关接口 xxxGateway
model包 实体、值对象、聚合相关 【贴紧业务 好理解的命名】
aggregates包 聚合 (实体)
valueobjects 值对象
入参与出参
xxxService领域服务
入参:聚合、实体、值对象【domain.model包中定义】
返回:聚合、实体、值对象【domain.model包中定义】
xxxGateway 网关接口
入参:聚合、实体、值对象【domain.model包中定义】
返回:聚合、实体、值对象 【domain.model包中定义】
聚合、实体、值对象分门别类放到对应包即可,不带后缀,直接起一个贴切的名字
分别放到对应的包即可: aggregates、entity、valueobjects
基础设施层
文件命名
infrastructure-model中
gatewayimpl包: 网关的实现 xxxGatewayImpl
database包 数据库相关 xxxmapper.java 和 xxxmapper.xml
do包 用到的数据库实体对象 xxxDO , 与表结构一一对应
rpc包 远程调用相关 , xxxRPC
dto和vo包 用到的dto与vo
config包: 配置相关的
utils包: 工具类相关
入参与出参
xxxGatewayImpl
入参:聚合、实体、值对象【domain.model包中定义】
返回:聚合、实体、值对象 【domain.model包中定义】
mapper
入参:xxxDO
出参:xxxDO
xxxRPC
入参:xxxDTO
出参:xxxVO
2.通用职责约定
2.1 校验
应用层必须做一次基本校验
- 必传参数
- 参数的基本属性校验,如:邮箱账号
领域层中:
- 实体内自己做校验,自己实体内数据正确【通过get、set,在领域对象内包含自检逻辑确保入参合法】
- 领域服务的能力去做业务规则上的校验 【跨多个实体的情况】
2.2 异常处理
一般原则
基础设施层和领域层 只抛异常,不处理异常
所有异常都在应用层统一处理
提供两种异常类型:BizException、SysException
| 异常名称 | 用法 | 备注 |
|---|---|---|
| BizException | 业务异常,我们不需要知道也不需要处理 | Biz为“商户的缩写” 与 business 含义基本一致 |
| SysException | 系统异常,我们需要知道需要处理 |
异常的响应码统一放到ReturnCode枚举中, 且按照分类分别放到 :ReturnCode10Enum、ReturnCode11Enum等
/*
返回码分类枚举都在此报下定义
异常类型: 错误码是int类型以1开头
10.其他
11.参数校验问题
12.业务逻辑问题
13.二、三方系统异常
14.数据问题
15.底层组件依赖异常
/
代码见下图
2.3 表结构设计
要注意区分领域里的实体与数据库实体DO
应该转变思想为 领域驱动 ,而不是表驱动
领域实体与数据库实体通过gateway来解耦
2.4 公共代码: 枚举、常量类、bean工厂、工具类等存放约定
枚举、bean工厂、常量类放到 领域层中
- 根据所属不同的聚合进行分包 , 如: businesspeople下有自己的 枚举、bean工厂、常量 , contract下也有自己的 枚举、bean工厂、常量
- 如果有多个领域用到的 如 是否删除的枚举 ,此种可以单独在domain建立enums统一放置
工具类放到 基础实施层
- 属于工具类的枚举、常量等与工具放同一个地方
业务的归领域层、 基础工具的归基础设施层
如果所有层都要用,则放到 xxx-components 中
2.5 全局能力:切面日志、异常处理存放约定
处理哪层的就放到哪层
比如:
接口切面日志就放到用户接口层
应用层切面日志放到用户接口层
全局的异常处理同样也是
2.6 如果需要事务,则将事务控制加在应用层
对于数据库事务: 建议是手动加事务注解 ,避免全局的事务切面(防止事务过大)
如果涉及到多个外部系统,采取最终一致性来保障数据一致性
3.原则与注意点【重点】
3.1 应用层的 xxxAppServiceImpl 是汇总用例的文件,里面的一个方法只能调用一个 CmdExe
这样做将不同用例的调用代码按照命令合理拆分到各个CmdExe中,可以避免service的膨胀,避免出现上帝类
正例:
反例:
3.2【推荐】应用层的 xxxCmdExe 是一个命令所有相关代码写的地方,它负责调用网关gateway获取数据,调用domain或实体的能力按照业务规则处理数据, 调用网关gateway持久化数据 【若是有特别复杂的业务逻辑,可以沉淀到domainService,然后domainService顺便调用gateway进行持久化】
应用层的职责是负责 组合网关与领域的业务规则 ,是一个流程具体的控制者 , 数据操作找网关,业务规则找领域服务
这样分离了业务规则和流程控制(查和插入通过网关)【分离关注点】
正例:
反例:
3.3~~ ~~领域层的domainService与实体里只能有业务规则的代码,不允许使用gateway操作数据, 操作数据应当由应用层做 【删除本条】【允许】
领域层是居于最核心的层,他不依赖任何层,只有最纯粹的业务规则,这些规则被其他层所依赖
正例:
反例:
3.4 实体、值对象、聚合他们自己内部应该通过get与set自校验,多个实体的业务规则(这个业务规则的行为放到哪个实体都不自然)放到domainService
一般来说, 实体、值对象、聚合都有自己的属性和行为(规则), 但是某个规则涉及多个实体放哪个都不合适,就可以把它们统一放到domainService
注意:如果业务规则较为简单,仅仅实体的规则就够用了, domainService可以不写 ,
正例:
反例:
3.5: 先把App做厚,再把App做薄
| 我们先可以把业务逻辑都写到App里面,在写的过程中,我们会发现有一些业务逻辑,不仅仅是过程式的代码,它也是领域知识(Domain knowledge),应该被更加清晰、更加内聚的表达出来,那么我们就可以把这段代码沉淀为领域能力。 |
|---|
重构的过程里我们可能会发现,很大一部分逻辑都在应用层的各个CmdExe里, domain层的逻辑少的可怜,没关系,先这样写,没问题,别怀疑,如果你不了解该放到哪里,就按照以前的思路,把CmdExe当成以前的service即可 ,大家在CR 的时候一块看
:哪些是领域的规则,哪些是底层的技术实现细节,分门别类的移动过去 , 渐渐的你就会发现代码越来越清晰了
例子:
3.6: CmdExe 只可以引用 domain 的能力(gateway 、实体、领域服务) , 不可以直接用mapper或RPC
原因1:
COLA作者张建飞建议将Domain设计为开放的,可以应用层可以直接用mapper、rpc,但这样会导致退化, 我们在实践的时候要避免
| 我更愿意把Domain层设计成开放的,这种开放性不仅体现在CQRS的时候,App可以绕过Domain层直达Infrastructure;也体现在当你的团队实在hold不住DDD的时候,可以选择退化到老的三层架构。 虽然可以退化,但不应该成为你轻易放弃Domain层的理由。据我观察,很多同学不喜欢DDD,其根本原因还不在于对象之间的转换成本(实际上,这个转换成本也没那么大),而在于他不清楚Domain的职责,不知道哪些东西应该放到Domain里面。一种典型的错误做法是把所有的业务逻辑都放到了Domain层,包括我们上面说的CRUD统统放到了领域层,这样的DDD当然没人喜欢。 |
|---|
原因2:直接调用mapper、rpc等,势必要求应用层了解具体的细节逻辑,当依赖变更会影响到应用层 , 而通过gateway调用则相当于建立了防腐层,只需要改动gateway即可 【防腐层】
原因3: 层次严格的调用,依赖比较好管理
3.7:假如一个同一个实体被多个限界上下文用的划分方式:分别在两个限界上下文中各定义一次
原因:虽然是同一个东西,但在不同限界上下文下可能含义也是稍稍有所不同,为了避免 限界上下文1下 的实体里有本上下文中用不到的, 我们彻底给分开 【业务含义清晰】
3.8 注意转换(converter)与 构建(build)之间的区别: 转换是值拷贝与字段映射, 构建是带有业务逻辑的设置值
3.9 区分领域对象与数据库实体字段的区别:哪些字段是数据库实体的,但是领域对象上不应该有的
我们的表结构设计规范要求必须有: create_time , create_id, update_time,update_id,is_delete 字段
但是到了领域对象中,我们还需要这些吗?
4.推荐的最佳实践
4.1 重视统一语言,建立项目的核心词汇对照表
中文是我们日常交流和文档中经常要体现的,所以需要统一,这样我们在交流的时候才能高效,没有歧义;英文和英文缩写主要体现在我们的设计和代码上,也就是说我们的“统一语言”不仅仅是停留在交流和文档中,还要和代码保持一致,这样才能做到知行合一,提升代码的可读性和系统的可理解性。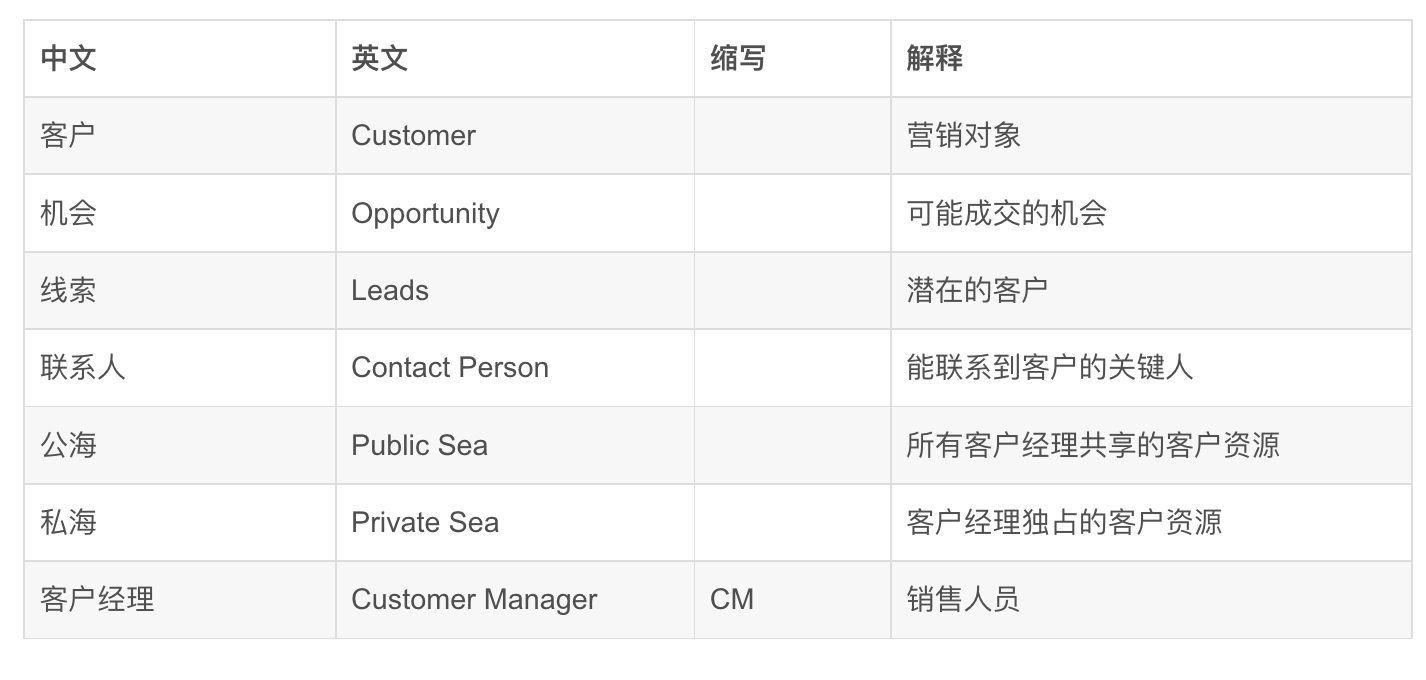
注意的是,词汇表中英文对中文的翻译不一定非常“准确”,不过没关系,语言就是一个符号,共识即正确,只要大家容易理解达成一致即可
4.2 推荐的编码良好习惯
- 【日志规范】能用debug就不要用info,能用warn就不要用error。滥用的error与狼来了无疑;
- 【方法参数要少】参数越少,越容易理解,也便于测试,各个参数的组合就如笛卡尔积;
- 【空行规范】方法、逻辑分段,要加空行,提高代码可读性。车轮毂与车轴之间有空隙,车才能跑;书法绘画有留白;
- 【防止破窗】首先我们要有一套规范,并尽量遵守规范,不要做“打破第一扇窗”的人;其次,发现“破窗”要及时修复,不要让问题进一步恶化;
- 【三次原则】第一次用到某功能时,写一个特定的解决方法;第二次又用到时,复制上一次的代码;第三次出现时,就要着手写通用解决方案了;
- 【最小惊奇原则】写代码不是写侦探小说,要的是简单易懂,而不是时不时搞点烧脑的骚操作;
- 【请求读写分离】增删改,会改变对象的状态,只需返回成功失败即可;查询是不会改变对象状态的,对系统没副作用。
4.3 优雅的异常使用写法【推荐 ,非强制】
4.3.1 使用异常工厂方法获取异常
提供了异常工厂 ExceptionFactory ,里面封装了异常对象
用法如下:
| // 不使用异常工厂 if(xxx){ throw new BixException(code, msg); } //使用异常工厂 if(xxx){ throw ExceptionFactory.BixException(code, msg); } |
|---|
4.3.2 使用断言来进行优雅校验
提供了断言类 Assert
用法如下:
| //定义listA //不使用断言 if(CollectionUtils.isEmpty(listA)){ throw ExceptionFactory.BixException(code, msg); } //使用断言 Assert.notEmpty(listA,code,msg); //断言内部对if进行了一次封装 public static void notEmpty(Collection<?> collection, Integer errorCode, String errMessage) { if (collection == null || collection.isEmpty()) { throw new BizException(errorCode, errMessage); } } |
|---|
源代码参见 cola 源码中的组件模块
4.3.3 使用 CatchAndLog 注解打印方法和类的执行信息(包括异常)
使用切面包了所有加 CatchAndLog 注解的类和方法, 将它们执行前入参执行后返回值都打印出来
源代码参见 cola 源码中的组件模块
4.4 删除“规范: 消费者和定时任务不能直接连库,必须要通过接口操作数据”
我们之前有一条规范: 消费者和定时任务不能直接连库,必须要通过接口操作数据
目的是: 收住逻辑的入口避免一个逻辑到处改, 迁移的时候也方便
但是改为COLA架构后, 我们的核心业务规则都在领域层,且定义了抽象的网关接口 , 由基础设施层来实现,应用层编排时依赖的都是:纯业务规则或抽象网关定义
此时:业务逻辑集中,底层设施变动时只需要改网关的实现,不会对上层的代码产生影响
“消费者和定时任务不能直接连库,必须要通过接口操作数据” 带来的好处基本就意义不大了, 反而因为只能走接口还得写额外的接口调用麻烦了很多
4.5 领域层的实体和领域服务是核心的业务逻辑聚集地,不应该依赖外部资源 (不通过gateway调用外部资源)【推荐,非强制】
领域层只有核心的业务逻辑 ,尽量不依赖第三方资源 , 这时的单元测试就很好写
所以我们可以要求核心业务逻辑必须编写单元测试
实行起来复杂度就大大降低

参考:
跨越DDD从理论到工程落地的鸿沟:https://blog.csdn.net/significantfrank/article/details/123267395
cola架构的发展过程各个链接整理【推荐阅读:可以看到COLA架构的演变历史,理解为什么要这么分层这么约定】
复杂度应对之道 - COLA应用架构 :https://blog.csdn.net/significantfrank/article/details/85785565
应用架构COLA 2.0:https://blog.csdn.net/significantfrank/article/details/100074716
应用架构COLA3.0 :让事情回归简单:https://blog.csdn.net/significantfrank/article/details/106976804
应用架构COLA 3.1:分类思维: https://blog.csdn.net/significantfrank/article/details/109529311
COLA 4.0:应用架构的最佳实践:https://blog.csdn.net/significantfrank/article/details/110934799
张建飞著. 代码精进之路:从码农到工匠[M].北京:人民邮电出版社,2020.1 【本书第三部分-12章作者详细讲了COLA架构的实践,值的一读】

若有收获,就点个赞吧
0 人点赞
