参考文章
pytorch中如何处理RNN输入变长序列padding
TORCH.NN.UTILS.RNN.PACK_PADDED_SEQUENCE
TORCH.NN.UTILS.RNN.PAD_PACKED_SEQUENCE
pytorch对可变长度序列的处理
个人笔记
前言
使用RNN进行情感分析,主体流程如下图示: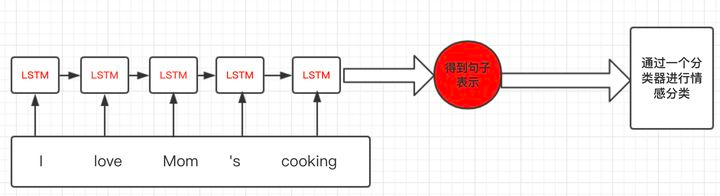
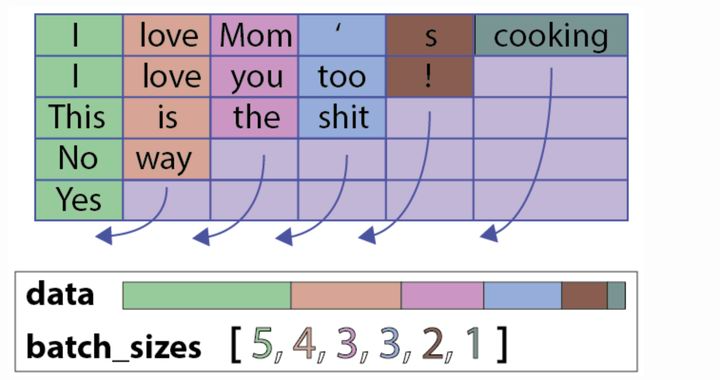
但是当我们进行batch个训练数据一起计算的时候,我们会遇到多个训练样例长度不同的情况,这样我们就会很自然的进行padding,将短句子padding为跟最长的句子一样,如下图: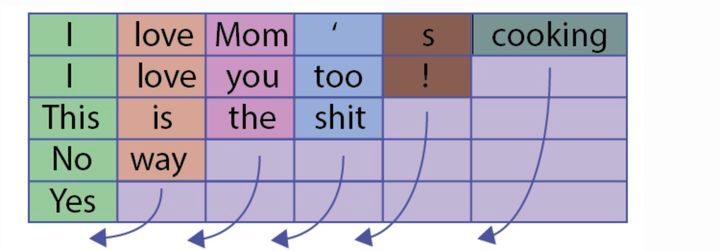
这会导致一个问题:比如上图最后一句,本来只有一个Yes单词,但是加了五个pad,这会导致LSTM对它的表示产生误差;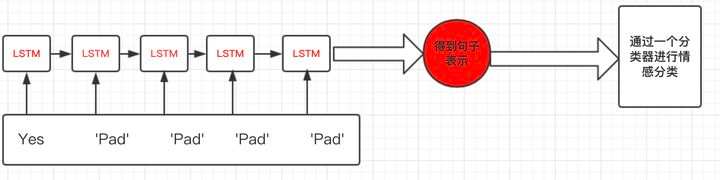
我们正确的做法如下图示: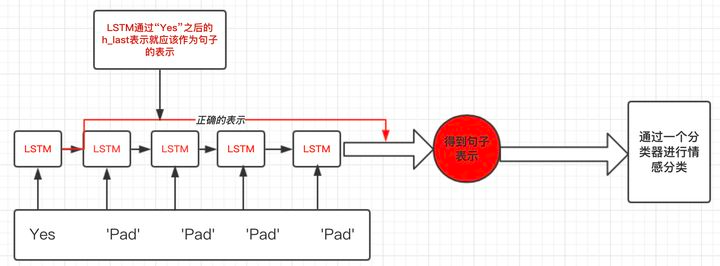
Pytorch处理机制
两个主要函数
torch.nn.utils.rnn.pack_padded_sequence()
torch.nn.utils.rnn.pack_padded_sequence(input, lengths, batch_first=False, enforce_sorted=True)


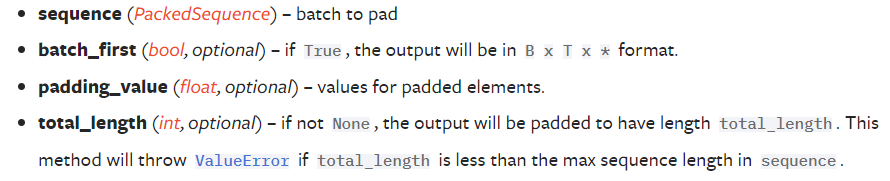
torch.nn.utils.rnn.pad_packed_sequence()
torch.nn.utils.rnn.pad_packed_sequence(sequence, batch_first=False, padding_value=0.0, total_length=None)

example
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequenceseq = torch.tensor([[1,2,0], [3,0,0], [4,5,6]])lens = [2, 1, 3]packed = pack_padded_sequence(seq, lens, batch_first=True, enforce_sorted=False)print(packed)'''PackedSequence(data=tensor([4, 1, 3, 5, 2, 6]), batch_sizes=tensor([3, 2, 1]),sorted_indices=tensor([2, 0, 1]), unsorted_indices=tensor([1, 2, 0]))'''seq_unpacked, lens_unpacked = pad_packed_sequence(packed, batch_first=True)print(seq_unpacked)'''tensor([[1, 2, 0],[3, 0, 0],[4, 5, 6]])'''print(lens_unpacked)'''tensor([2, 1, 3])'''
处理流程
- 首先对输入数据进行padding操作
然后通过pack_padded_sequence方法对填充数据进行pack压缩操作,可以得到PackedSequence对象:
embed_input_x_packed =pack_padded_sequence(embed_input_x, sentence_lens, batch_first=True)
放入LSTM中
encoder_outputs_packed, (h_last, c_last) = self.lstm(embed_input_x_packed)
返回的h_last和c_last就是剔除padding字符后的hidden state和cell state;但是返回的outputs是PackedSequence类型的,需要使用pad_packed_sequence方法进行还原:
encoder_outputs, _ = pad_packed_sequence(encoder_outputs_packed, batch_first=True)
得到的_代表各个句子的长度

若有收获,就点个赞吧
0 人点赞
