声明字符串
- 声明字符串:
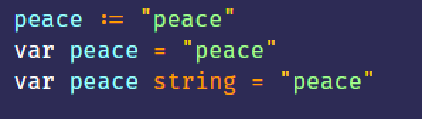
- 字符串的零值

字符串字面值/原始字符串字面值
- 字符串字面值可以包含转义字符,例如 \n
- 但如果你确实想得到 \n 而不是换行的话,可以使用 ` 来代替 “,这叫做原始字符串字面值。


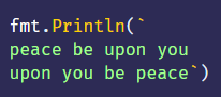
- 字符串字面值:string literal
- 原始字符串字面值:raw string literal
字符,code points,runes,bytes
- Unicode 联盟为超过 100 万个字符分配了相应的数值,这个数叫做 code point。
- 例如:65 代表 A,128515 代表

- 例如:65 代表 A,128515 代表
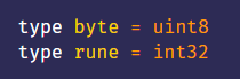
- 为了表示这样的 unicode code point,Go 语言提供了 rune 这个类型,它是 int32 的一个类型别名。
- 而 byte 是 uint8 类型的别名,目的是用于二进制数据。
- byte 倒是可以表示由 ASCII 定义的英语字符,它是 Unicode 的一个子集(共128个字符)
类型别名
- 类型别名就是同一个类型的另一个名字。
- 所以,rune 和 int32 可以互换使用。
- 也可以自定义类型别名,语法如下:
打印
- 如果想打印字符而不是数值,使用 %c 格式化动词
- 任何整数类型都可以使用 %c 打印,但是 rune 意味着该数值表示了一个字符
字符
- 字符字面值使用 ‘’ 括起来。例如:’A’
- 如果没指定字符类型的话,那么 Go 会推断它的类型为 rune
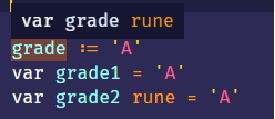
- 这里的 grade 仍然包含一个数值,本例中就是 65,它是 A 的 code point。
- 字符字面值也可以用 byte 类型:

string
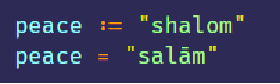
- 可以给某个变量赋予不同的 string 值,但是 string 本身是不可变的
测试
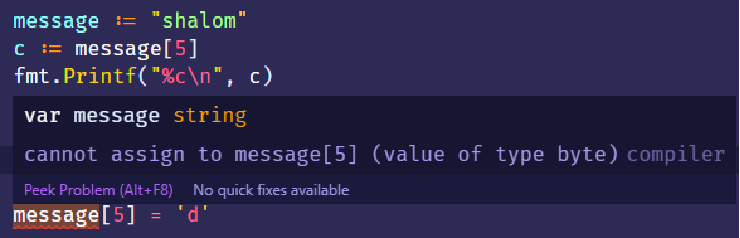
- 写个程序,打印出 shalom 的每个字符,每个字符独占一行。
package mainimport ("fmt")func main() {message := "shalom"for i := 0; i <= 5; i++ {fmt.Printf("%c\n", message[i])}}
Caesar cipher 凯撒加密法
- 对于加密信息,一种简单有效的办法就是把每个字母都移动固定长度的位置。
- 例如:a -> d,b -> e
package mainimport "fmt"func main() {c := 'a'c = c + 3fmt.Printf("%c", c)c = 'x'c = c + 3if c > 'z' {c = c - 26}fmt.Printf("%c", c)}
ROT13
- ROT13(旋转13)是凯撒密码在 20 世纪的变体。
- 它会把字母替换成+13后的对应的字母。
package mainimport "fmt"func main() {message := "uv vagreangvbany fcnpr fgngvba"for i := 0; i < len(message); i++ {c := message[i]if c >= 'a' && c <= 'z' {c = c + 13if c > 'z' {c = c - 26}}fmt.Printf("%c", c)}}
Go 的内置函数
- len 是 Go 语言的一个内置函数。
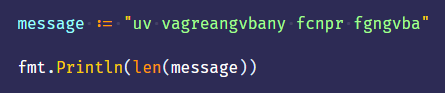
- 本例中 len 返回 message 所占的 byte 数。
- Go 有很多内置函数,它们不需要 import
UTF-8
- Go 中的字符串是用 UTF-8 编码的,UTF-8 是 Unicode Code Point 的几种编码之一。
- UTF-8 是一种有效率的可变长度的编码,每个 code point 可以是 8 位、16 位或 32 位的。
- 通过使用可变长度编码,UTF-8 使得从 ASCII 的转换变得简单明了,因为 ASCII 字符与其 UTF-8 编码的对应字符是相同的。
- UTF-8 是万维网的主要字符编码。它是由 Ken Thompson 于 1992 年发明的,他是 Go 语言的设计者之一。
package mainimport ("fmt""unicode/utf8")func main() {question := "¿Cómo estás?"fmt.Println(len(question), "bytes")fmt.Println(utf8.RuneCountInString(question), "runes")c, size := utf8.DecodeRuneInString(question)fmt.Printf("First rune: %c %v bytes\n", c, size)}
- 本例中,len函数计算的是question这个字符串的每个字节(8位),没有考虑多字节的情况(16、32位)。
- 如何支持西班牙语、俄语、汉语等?
- 把字符解码成 rune 类型,然后再进行操作。
- 使用 utf-8 包,它提供可以按 rune 计算字符串长度的方法RuneCountInString。
- DecodeRuneInString 函数会返回第一个字符,以及字符所占的字节数。
- 所以 Go 里的函数可以返回多个值。
range
- 使用 range 关键字,可以遍历各种集合。


作业题
- L fdph, L vdz, L frqtxhuhg,每个字母向前移动 3个位置,能得到什么字符串?
package mainimport "fmt"func main() {message := "L fdph, L vdz, L frqtxhuhg."for i := 0; i < len(message); i++ {c := message[i]if c >= 'a' && c <= 'z' {c -= 3if c < 'a' {c += 26}} else if c >= 'A' && c <= 'Z' {c -= 3if c < 'A' {c += 26}}fmt.Printf("%c", c)}fmt.Println()}
- 把西班牙语 “Hola Estación Espacial Internacional” 用 ROT13 进行加密
- 使用 range 关键字
- 带重音符号的字母要保留
package mainimport "fmt"func main() {message := "Hola Estación Espacial Internacional"for _, c := range message {if c >= 'a' && c <= 'z' {c = c + 13if c > 'z' {c = c - 26}} else if c >= 'A' && c <= 'Z' {c = c + 13if c > 'Z' {c = c - 26}}fmt.Printf("%c", c)}fmt.Println()}

若有收获,就点个赞吧
0 人点赞
