- 概念和原理
- 指标
- 工具
- 第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)
- 第二行开始是表格样式的数据
- 第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
- 第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
- 第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
- 最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
概念和原理
平均负载(Load average)
指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,可以理解为平均活跃进程数
注意平均负载和CPU 使用率并没有直接关系,直观上可以理解成单位时间内的活跃进程数,实际上是活跃进程数的指数衰减值(只是系统更快速的一种计算方式)。
tip平均负载的理想值=CPU 个数,当平均负载高于CPU个数的70% 时,需要引起关注。
CPU 使用率
单位时间内,CPU繁忙情况的统计
**
CPU 使用率相关指标: user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。 nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。 system(通常缩写为 sys),代表内核态 CPU 时间。 idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。 iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。 irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。 softirq(通常缩写为 si),代表处理软中断的 CPU 时间。 steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。 guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。 guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。

tip直接用proc/stat 中的数据计算出来的时开机以来的平均CPU使用率,参考意义不大。性能工具一般会取一段时间的值做差后,计算出这段时间内的平均CPU使用率。

CPU上下文切换
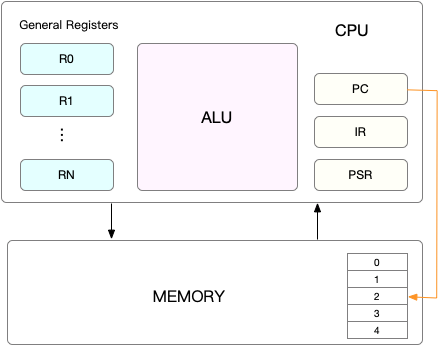
就是先把前一个任务的 CPU 上下文【也就是 CPU 寄存器/Register和程序计数(Program Counter,PC)】保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务
- 进程上下文切换:进程切换时(换句话说进程调度时)才需要切换上下文
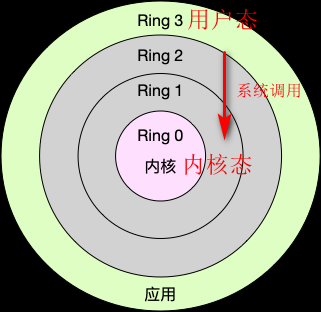
tip进程从用户态到内核态的转变通过系统调用完成。一次系统调用发生了两次上下文切换:为了执行内核态代码,CPU寄存器需要先将用户态指令位置保存,然后更新为内核态指令的新位置,最后跳转到内核态运行内核任务;系统调用结束后,CPU寄存器需要恢复用户态,切换回用户空间,继续执行进程。

- 线程上下文切换
tip进程与线程的区别:线程是调度的基本单位,而进程则是资源拥有的基本单位
线程上下文切换场景:
- 第一种, 前后两个线程属于不同进程。因为资源不共享,所以切换过程就跟进程上下文切换一样。- 第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
- 中断上下文切换
为了快速响应硬件设备的事件,中断会打断进程的正常调度和执行。对于同一个CPU来说,中断处理比进程有更高的优先级
CPU上下文切换的场景(时机)
- 其一,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
- 其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
- 其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
- 其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
- 最后一个,发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
上下文切换的场景
- 自愿上下文切换:指进程无法获取所需的资源,比如内存、I/O等系统资源不足时,会发生自愿上下文切换
- 非自愿上下文切换:指系统分配的时间片已到,被系统强制调度,进而发生非资源上下文切换。比如大量进程争抢CPU的场景就容易发生非自愿山下问切换
进程组
会话
共享同一个控制终端的一个或多个进程组
指标
工具
stress: Linux 系统压力测试工具,这里用作异常进程模拟平均负载升高的场景。
mpstat: 多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
vmstat:系统内存和CPU性能分析工具。
#r(running or runnable):就绪队列长度,也就是正在运行和等待CPU运行的进程数#b(blocked):处于不可中断睡眠状态的进程数#cs(context switch):每秒上下文切换次数#in(interrupt):每秒中断次数[root@space ~]# vmstat -wprocs -----------------------memory---------------------- ---swap-- -----io---- -system-- --------cpu--------r b swpd free buff cache si so bi bo in cs us sy id wa st5 0 0 93556 155360 1207764 0 0 1 4 0 1 0 0 99 0 00 0 0 93540 155360 1207764 0 0 0 0 2069 2539 1 1 98 0 0
pidstat: 进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
#-w 显示进程上下文切换信息#cswch(voluntary context switches):#nvcswch(non voluntary context switches):[root@space ~]# pidstat -wLinux 3.10.0-693.2.2.el7.x86_64 (space) 09/16/2019 _x86_64_ (1 CPU)10:53:40 AM UID PID cswch/s nvcswch/s Command10:53:40 AM 0 1 0.04 0.00 systemd10:53:40 AM 0 2 0.00 0.00 kthreadd10:53:40 AM 0 3 0.38 0.00 ksoftirqd/010:53:40 AM 0 5 0.00 0.00 kworker/0:0H10:53:40 AM 0 7 0.00 0.00 migration/010:53:40 AM 0 8 0.00 0.00 rcu_bh10:53:40 AM 0 9 18.81 0.00 rcu_sched
sysbench:多线程基准测试工具,一般用来评估不同系统参数下的数据库负载情况。这里哟过来模拟多线程场景。
[root@space ~]# sysbench --threads=10 --max-time=300 threads runWARNING: --max-time is deprecated, use --time insteadsysbench 1.0.17 (using system LuaJIT 2.0.4)Running the test with following options:Number of threads: 10Initializing random number generator from current timeInitializing worker threads...Threads started!
/proc/interrupts :中断使用情况
#-d 表示高亮显示变化区域[root@space ~]#watch -d cat /proc/interruptsCPU00: 68 IO-APIC-edge timer1: 1812 IO-APIC-edge i80424: 58 IO-APIC-edge serial6: 3 IO-APIC-edge floppy8: 0 IO-APIC-edge rtc09: 0 IO-APIC-fasteoi acpi11: 33 IO-APIC-fasteoi uhci_hcd:usb1, virtio312: 6352 IO-APIC-edge i804214: 0 IO-APIC-edge ata_piix15: 0 IO-APIC-edge ata_piix24: 0 PCI-MSI-edge virtio2-config25: 15929891 PCI-MSI-edge virtio2-req.026: 4 PCI-MSI-edge virtio0-config27: 24876634 PCI-MSI-edge virtio0-input.028: 1 PCI-MSI-edge virtio0-output.029: 0 PCI-MSI-edge virtio1-config30: 32 PCI-MSI-edge virtio1-virtqueuesNMI: 0 Non-maskable interruptsLOC: 556427488 Local timer interruptsSPU: 0 Spurious interruptsPMI: 0 Performance monitoring interruptsIWI: 278410636 IRQ work interruptsRTR: 0 APIC ICR read retriesRES: 0 Rescheduling interruptsCAL: 0 Function call interruptsTLB: 0 TLB shootdownsTRM: 0 Thermal event interruptsTHR: 0 Threshold APIC interruptsDFR: 0 Deferred Error APIC interruptsMCE: 0 Machine check exceptionsMCP: 147353 Machine check pollsERR: 0MIS: 0PIN: 0 Posted-interrupt notification eventPIW: 0 Posted-interrupt wakeup event
/proc/stat:各种内核统计信息
#只保留CPU的统计数据$ cat /proc/stat | grep ^cpucpu 280580 7407 286084 172900810 83602 0 583 0 0 0cpu0 144745 4181 176701 86423902 52076 0 301 0 0 0cpu1 135834 3226 109383 86476907 31525 0 282 0 0 0
top:系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况
Tiptop 并没有细分进程的用户态 CPU 和内核态 CPU,想查看每个进程的详细情况可使用 pidstat
#几个有用的交互式命令Interactive Commands - procps-ng version 3.3.100,1,2,3,I Toggle: '0' zeros; '1/2/3' cpus or numa node views; 'I' Irix modef,F,X Fields: 'f'/'F' add/remove/order/sort; 'X' increase fixed-widthR,H,V,J . Toggle: 'R' Sort; 'H' Threads; 'V' Forest view; 'J' Num justifyk,r Manipulate tasks: 'k' kill; 'r' renice
perf:perf 是 Linux 2.6.31 以后内置的性能分析工具。以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
- perf top
- perf record
- perf report
:::info
perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要用 perf report 解析展示。
:::
```shell
第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)
第二行开始是表格样式的数据
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
perf top Samples: 833 of event ‘cpu-clock’, Event count (approx.): 97742399 Overhead Shared Object Symbol 7.28% perf [.] 0x00000000001f78a4 4.72% [kernel] [k] vsnprintf 4.32% [kernel] [k] module_get_kallsym 3.65% [kernel] [k] _raw_spin_unlock_irqrestore …
**ab**(apache bench):一个常用的 HTTP 服务性能测试工具,这里用来模拟 Ngnix 的客户端```shell# 并发 10 个请求测试 Nginx 性能,总共测试 10000 个请求ab -c 10 -n 10000 http://10.240.0.5:10000/...Complete requests: 10000Failed requests: 0Total transferred: 1720000 bytesHTML transferred: 90000 bytesRequests per second: 2237.04 [#/sec] (mean)Time per request: 4.470 [ms] (mean)Time per request: 0.447 [ms] (mean, across all concurrent requests)Transfer rate: 375.75 [Kbytes/sec] received...
execsnoop:一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
$ execsnoopPCOMM PID PPID RET ARGSsh 30394 30393 0stress 30396 30394 0 /usr/local/bin/stress -t 1 -d 1sh 30398 30393 0stress 30399 30398 0 /usr/local/bin/stress -t 1 -d 1sh 30402 30400 0stress 30403 30402 0 /usr/local/bin/stress -t 1 -d 1sh 30405 30393 0stress 30407 30405 0 /usr/local/bin/stress -t 1 -d 1...
:::success top,ps 这种展示系统概要和进程快照类工具很难发现短时应用,需要借助记录事件的工具配合诊断,如execsnoop,perf top :::
分析和优化思路

若有收获,就点个赞吧
0 人点赞
