典型问答
Q:对比Hashtable、HashMap、TreeMap 有什么不同?谈谈你对HashMap的掌握
A:HashTable、HashMap、TreeMap是常见的Map实现,是以键值对的形式存储和操作数据的容器类型。
Hashtable是Java类库(类似Vector、Stack的早期集合相关类型,扩展了Dictionary提供的一个哈希表实现,同步,不支持null键和值,由于同步导致性能开销,很少被推荐使用。(如果不需要线程安全的实现,建议使用 HashMap代替Hashtable。如果需要线程安全的高并发实现,则建议使用ConcurrentHashMap代替Hashtable。)
HashMap是应用更加广泛的哈希表实现,行为大致与HashTable一致,主要区别在于HashMap不是同步的,支持null键和值。是绝大部分利用键值对存取场景的首选,比如实现一个用户ID与用户对应的运行时存储结构。
TreeMap是基于红黑树的一种提供顺序访问的Map,具体顺序可以由制定的Comparator来决定,或者根据键的自然顺序来判断。
考点分析
- 理解Map相关类的整体结构,尤其是有序数据结构的一些要点
- 从源码分析HashMap的设计和实现要点,理解容量/负载因子等,为什么需要这些参数,如何影响Map的性能,实践中如何取舍
- 理解树化改造的相关原理和改进原因
知识拓展
- Map整体结构
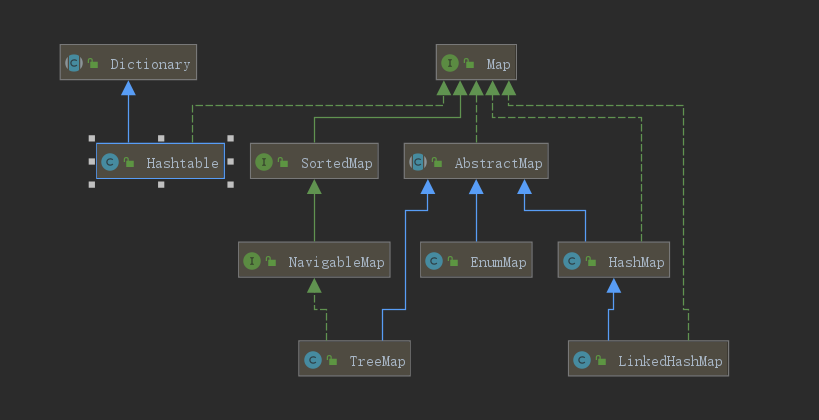
大部分使用Map的场景,通常是放入、访问或删除,对顺序没有特别要求。HashMap的性能表现依赖于哈希码的有效性,必须掌握hashCode和equals基本约定:
- equals相等,hashCode一定要相等
- 重写hashCode也要重写equals
- hashCode需要保持一致性,状态改变返回的哈希值任然要一致
equals的对称、反射、传递等特性
- LinkedHashMap 维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序。注意,通过特定构造函数,我们可以创建反映访问顺序的实例,所谓的 put、get、compute 等,都算作“访问”。这种行为适用于一些特定应用场景,例如,我们构建一个空间占用敏感的资源池,希望可以自动将最不常被访问的对象释放掉,这就可以利用 LinkedHashMap 提供的机制来实现,参考下面的示例:
- LinkedHashMap 维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序。注意,通过特定构造函数,我们可以创建反映访问顺序的实例,所谓的 put、get、compute 等,都算作“访问”。这种行为适用于一些特定应用场景,例如,我们构建一个空间占用敏感的资源池,希望可以自动将最不常被访问的对象释放掉,这就可以利用 LinkedHashMap 提供的机制来实现,参考下面的示例:
import java.util.LinkedHashMap;import java.util.Map;public class LinkedHashMapSample {public static void main(String[] args) {//LinkedHashMap<String, String> accessOrderedMap = new LinkedHashMap<String, String>(16, 0.75F, true){@Overrideprotected boolean removeEldestEntry(Map.Entry<String, String> eldest) { // 实现自定义删除策略,否则行为就和普遍 Map 没有区别return size() > 3;}};accessOrderedMap.put("Project1", "Valhalla");accessOrderedMap.put("Project2", "Panama");accessOrderedMap.put("Project3", "Loom");accessOrderedMap.forEach( (k,v) -> {System.out.println(k +":" + v);});// 模拟访问accessOrderedMap.get("Project2");accessOrderedMap.get("Project2");accessOrderedMap.get("Project3");System.out.println("Iterate over should be not affected:");accessOrderedMap.forEach( (k,v) -> {System.out.println(k +":" + v);});// 触发删除accessOrderedMap.put("Project4", "Mission Control");System.out.println("Oldest entry should be removed:");accessOrderedMap.forEach( (k,v) -> {// 遍历顺序不变System.out.println(k +":" + v);});}}
- TreeMap,它的整体顺序是由键的顺序关系决定的,通过 Comparator 或 Comparable(自然顺序)来决定。我在上一讲留给你的思考题提到了,构建一个具有优先级的调度系统的问题,其本质就是个典型的优先队列场景,Java 标准库提供了基于二叉堆实现的 PriorityQueue,它们都是依赖于同一种排序机制,当然也包括 TreeMap 的马甲 TreeSet。
- HashMap源码分析
未完待补充
一课一练
解决哈希冲突有哪些典型的方法?
精选留言
Hashtable、HashMap、TreeMap三者均实现了Map,存储的内容是基于key-value的键值对映射,一个映射不能有重复的键,一个键最多只能映射一个值
- 元素特性
HashTable中的KV都不能为null;
HashMap中的KV可以为null,只能有一个key为null的键值对,但是允许多个值为null的键值对
TReeMap中当为实现Comparator接口时,key不可以为null;当实现Comparator接口时,若未对null情况进行判断,则key不可以为null,反之亦然。- 顺序特性
HashTable、HashMap具有无序性。
TReeMap利用红黑树(树中的每个节点的值,都大于或等于左子树中的所有节点值,并且小于 或等于它右子树中所有节点的值),实现了sortedMap接口,能够对保存的记录根据键进行排序,默认为升序排序方式(深度优先搜索),可自定义实现Comparator接口实现排序方式。- 初始化与扩容方式
初始化:
HashTable在不指定容量的情况下默认容量为11,且不要求底层数组的容量一定要为2的整数次幂;
HashMap默认容量为16,且要求容量一定为2的整数次幂;
扩容:
Hashtable将容量变为原来的2倍加1;
HashMap将容量变为原来2倍。- 线程安全
HashTable是线程安全的,其方法函数都是同步的(采用Synchronized修饰),不会出现两个线程同时对数据进行操作的情况,但正因为如此,在多线程环境下效率表现非常低下。因为当一个线程访问HashTable同步方法时,其他线程也访问同步方法就会进行阻塞状态。比如当一个线程在添加数据时,另外一个线程即使执行获取其他数据的操作也会被阻塞,降低程序的运行效率,在新版本中已被废弃,不推荐使用。
HashMap不支持线程的同步,即任一时刻多个线程同时写HashMap可能会导致数据不一致。如需同步(1)可以用Collections的synchronizedMap方法;(2)使用ConcurrentHashMap类,相较于HashTable锁住的是对象整体, ConcurrentHashMap基于lock实现锁分段技术。首先将Map存放的数据分成一段一段的存储方式,然后给每一段数据分配一把锁,当一个线程占用锁访问其中一个段的数据时,其他段的数据也能被其他线程访问。ConcurrentHashMap不仅保证了多线程运行环境下的数据访问安全性,而且性能上有长足的提升。- 一句话HashMap
HashMap是基于哈希思想,实现对数据的读写。当我们将键值对传递给put()方法时,调用对象的hashCode()方法来计算hashcode,然后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞,对象会存储在链表的下一个节点中。HashMap在每个链表节点中存储键值对对象。当两个不同的键对象的hashcode相同时,会存储在同一个bucket位置的链表中,可通过键对象的equals方法找到键值对。如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),链表就会被改造为树形结构。

若有收获,就点个赞吧
0 人点赞
