分类
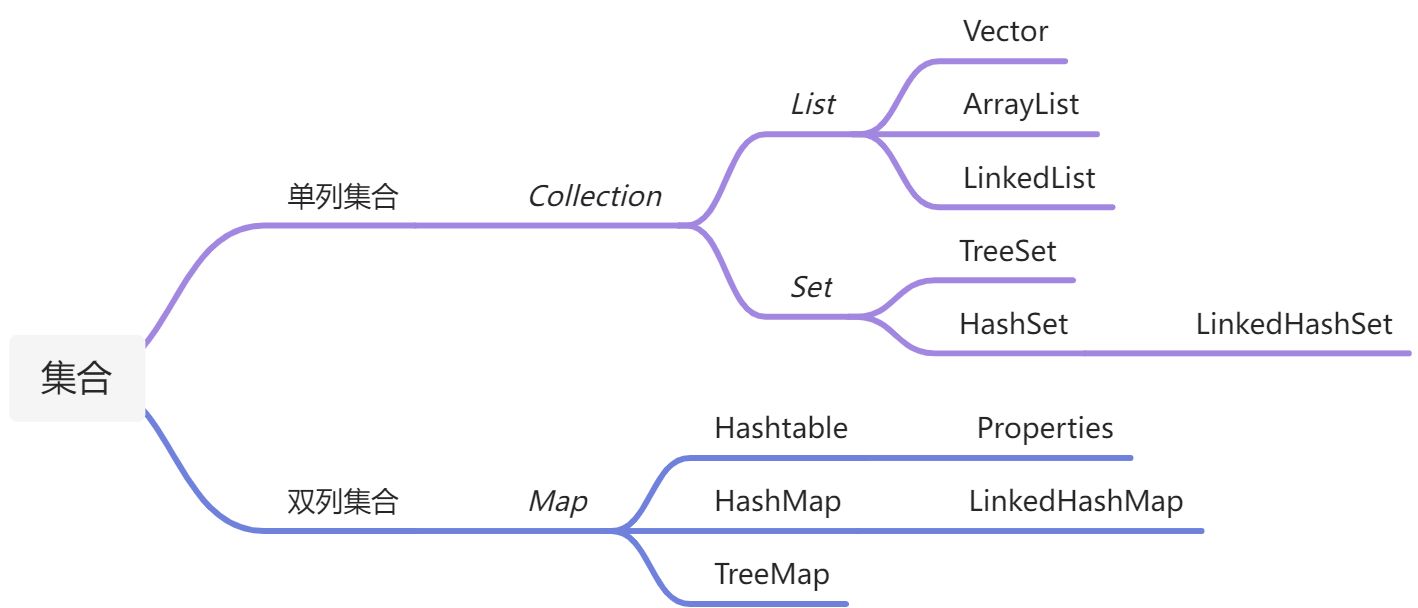
Collection(接口)
List(接口)
List中:
- 元素有序,即添加顺序和取出顺序一致
- 元素可重复,且可为null
- 每个元素都有对应的顺序索引
Vector
1. 实现方式:Object类型的数组
![44G13W@PI{6V3{9NZV7W}M.png2. 源码
(1)线程安全的,操作方法带synchronized
举例:![]`I(YMDW06G2CEKL$GSYJ@W.png](/uploads/projects/quantianbuhuoyue@abmz1b/e0f3791c4003980f0ed1e06eb9184cdf.png)
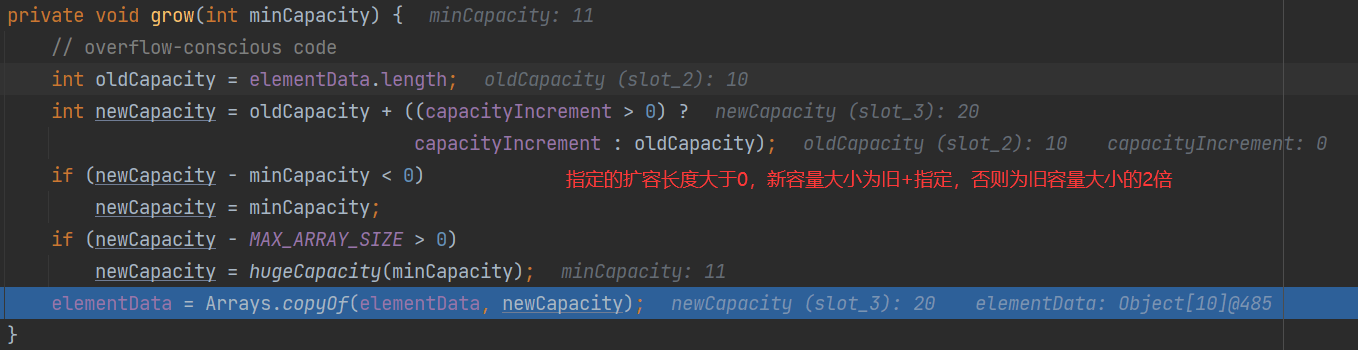
(2)扩容机制
如果是无参,默认10,满了按2倍扩容;如果指定大小,每次按2倍扩容
无参构造器
public static void main(String[] args) {Vector vector = new Vector();for (int i = 0; i < 10; i++) {vector.add(i);}vector.add(100);}
- 第2行:无参构造器创建Vector,给默认值10,再调用有参构造器
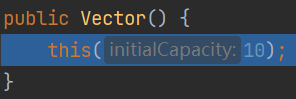

- 第4行:添加数据到集合


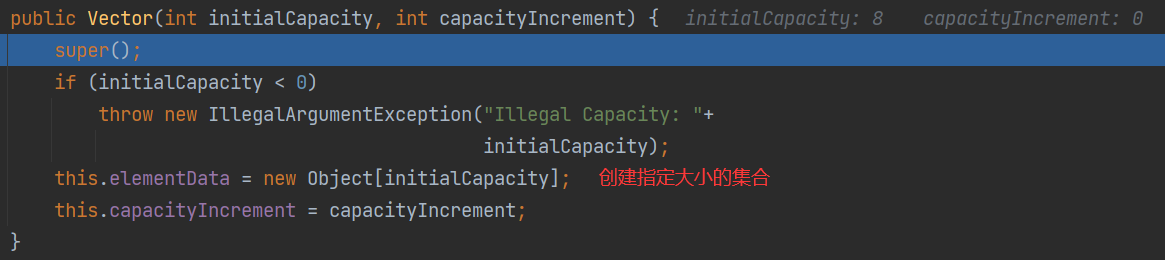
有参构造器
Vector vector = new Vector(8);
- 创建
![{38SPNS90]~L96(J8(6)D1G.png](/uploads/projects/quantianbuhuoyue@abmz1b/7e4a476934a60c025e08a1c82ffc62f0.png)
- 扩容
![MW@T0E41M{7]F01L}FNBS57.png](/uploads/projects/quantianbuhuoyue@abmz1b/af8e0687b1fe6d17d66de4159a6dc7f9.png)
ArrayList
1. 实现方式:数组
2. 源码
(1)底层维护一个Object类型的数组elementData
/*** The array buffer into which the elements of the ArrayList are stored.* The capacity of the ArrayList is the length of this array buffer. Any* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA* will be expanded to DEFAULT_CAPACITY when the first element is added.*/transient Object[] elementData; // non-private to simplify nested class access/*** The size of the ArrayList (the number of elements it contains).** @serial*/private int size;
transient表示该属性不会被序列化
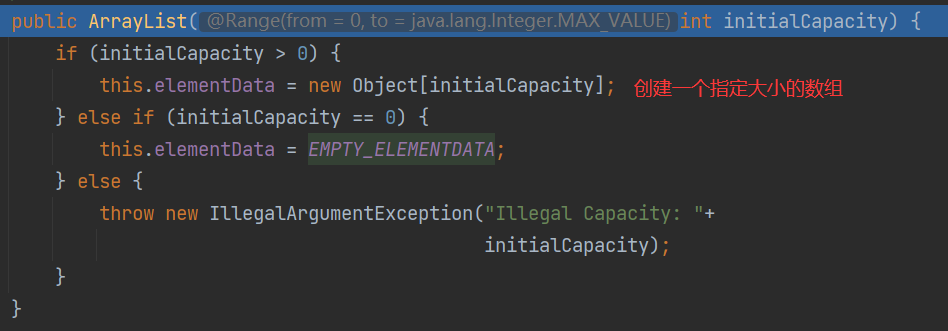
(2)构造器
![B7BUC%A39)JPZ6JL(A}6%B.png
(3)扩容机制
当创建ArrayList对象时,如果使用无参构造器,初始elementData容量为0,第1次添加,扩容为10,再次扩容,扩容为elementDate的1.5倍
如果使用的是指定大小的构造器(ArrayList(int)),初始elementDate容量为指定大小,如果需要扩容,则直接扩容elementData为1.5倍
无参构造器
public class ArrayListSource {public static void main(String[] args) {//使用无参构造器创建ArrayList对象ArrayList list = new ArrayList();//使用for给list集合添加 1-10数据for (int i = 1; i <= 10; i++) {list.add(i);}//使用for给list集合添加 11-15数据for (int i = 11; i <= 15; i++) {list.add(i);}}}
- 第4行:使用无参构造器创建ArrayList对象,创建了一个空的elementData
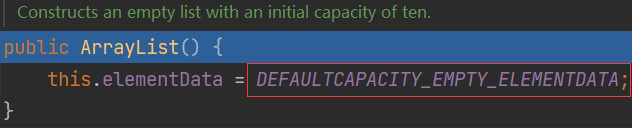 ![`AS)E(NJ}9TDVL])6{CYQ2.png
![`AS)E(NJ}9TDVL])6{CYQ2.png
- 第6行:i = 1时,即第一次添加元素,执行add方法
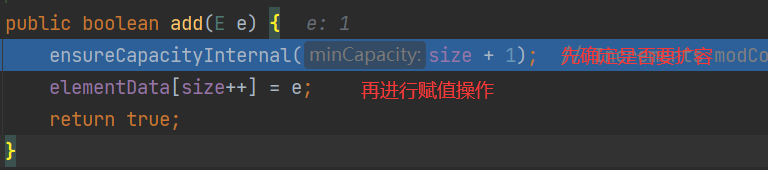
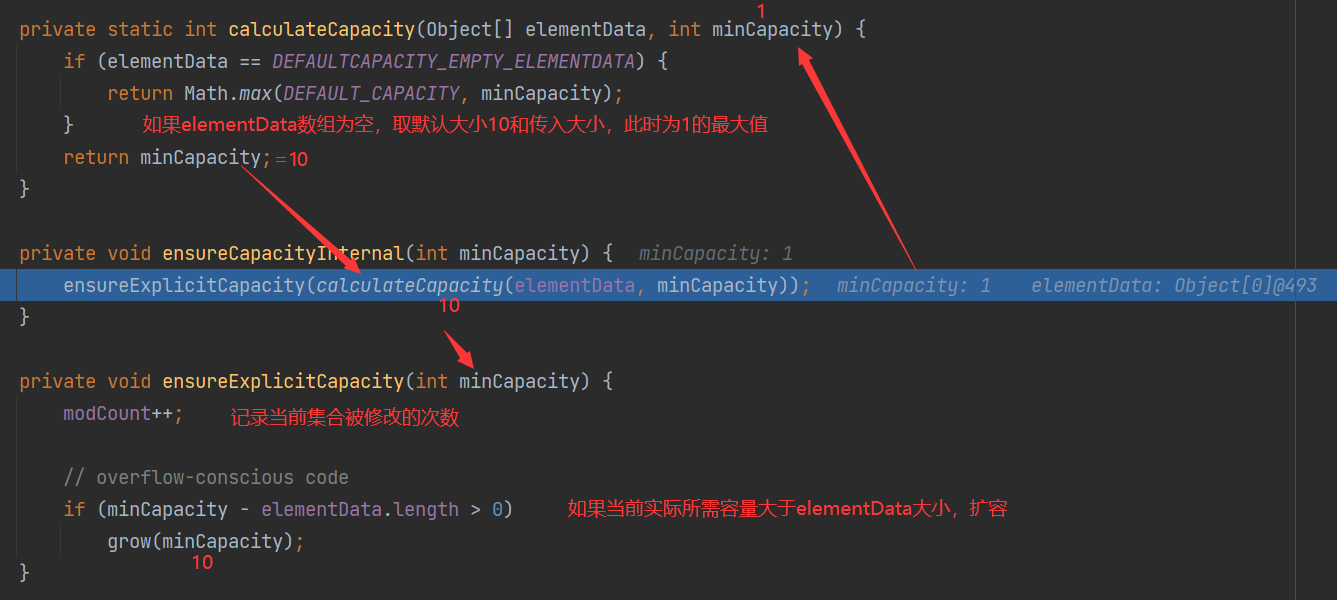
实际的扩容方法grow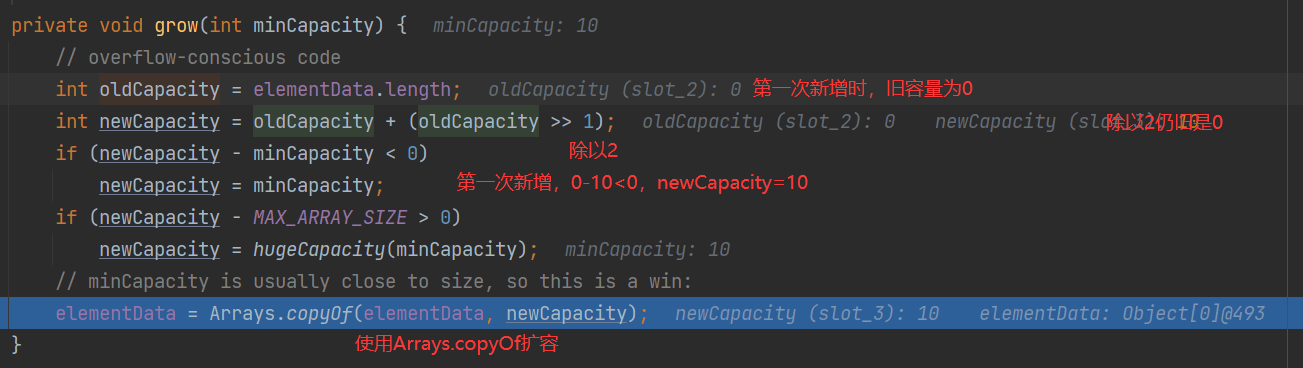
- 第6行:i=11,会进行第2次扩容,前面的流程都跟第1次一样,grow方法:
第2次及以后,都按1.5倍扩容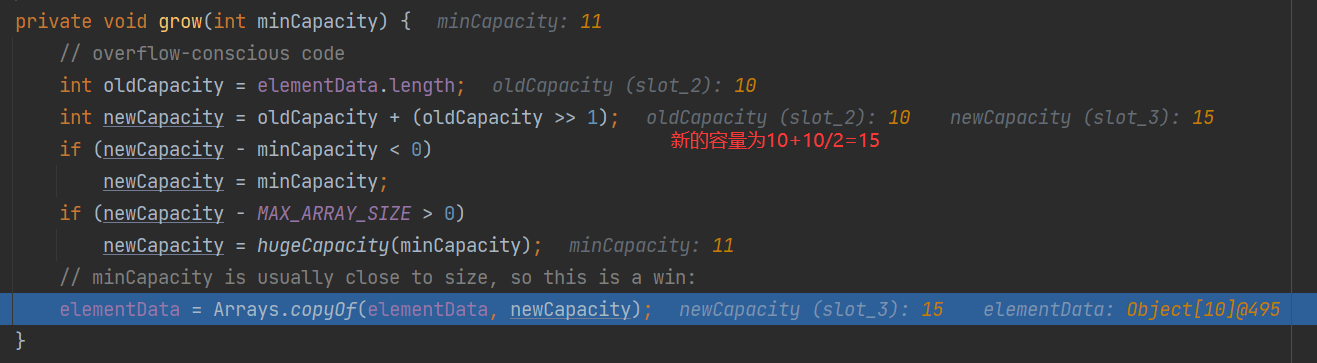
有参构造器
ArrayList list = new ArrayList(8);
- 第一次添加
- 之后扩容按1.5倍扩容
(4)线程不安全,执行效率高
如下面的add方法,没有进行线程安全的设置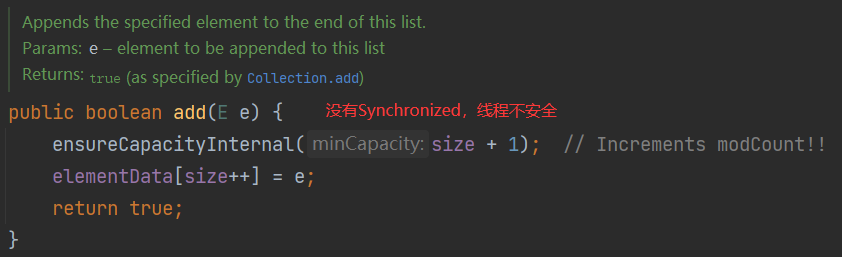
LinkedList
1. LinkedList底层实现了双向链表
2. 源码
(1)底层维护了一个双向链表
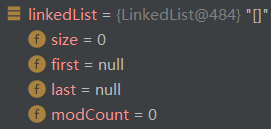
size是链表大小,first和last分别指向首节点和尾节点![D]DO9V$3LG%9C`TUQSX{HOX.png](/uploads/projects/quantianbuhuoyue@abmz1b/ec760fd176e02c96ec331064229976da.png)
(2)创建
创建了空的LinkedList,first和last都是nullLinkedList linkedList = new LinkedList();
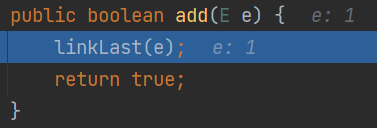
(3)添加,同理,删除节点等都是双向链表的操作
将新节点加到双向链表尾部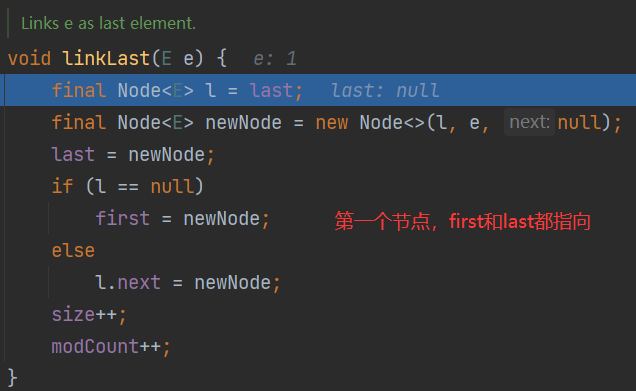
(4)线程不安全
Set(接口)
Set中:
- 元素无序
- 不允许有重复元素,最多有一个null
- 不能用索引
TreeSet
1. 底层是TreeMap
2. 特点:可以排序
(1)使用无参构造器,是无序的
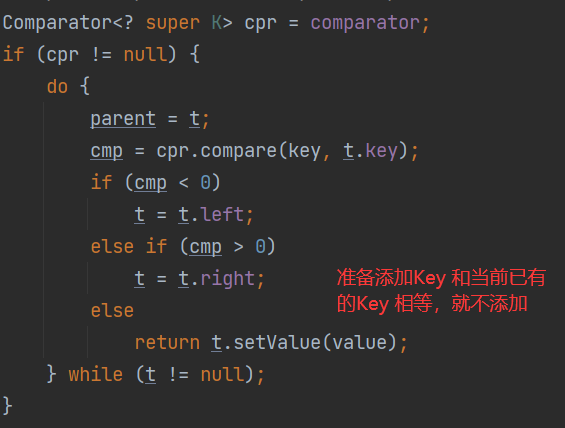
(2)使用传入比较器的构造器,进行指定规则排序
![%_06X~%8L(NFZUI08AAZAX.png
举例:按字符串大小比较TreeSet treeSet = new TreeSet(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {//下面 调用String的 compareTo方法进行字符串大小比较return ((String) o2).compareTo((String) o1);}});
![628K_])SHM)GG02KI](CO]Y.png](/uploads/projects/quantianbuhuoyue@abmz1b/7a345512bc7ef1283371744370cac21e.png)
HashSet
1. 底层实际上是HashMap
2. 源码
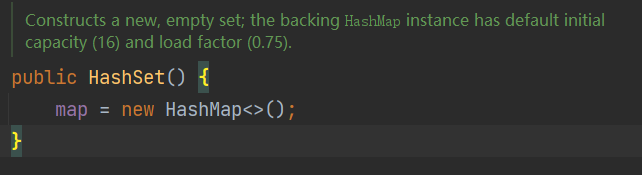
(1)创建
Set hashSet = new HashSet();
(2)HashSet的底层是HashMap,HashMap底层是数组+链表+红黑树
- 添加一个元素时,先得到hash值,再转成索引
- 找到存储数据表table,看这个索引位置有没有存放元素
- 如果没有存放元素,直接加入
- 如果有,调用equals比较,如果相同,放弃添加;如果不相同,添加到最后
一条链表的元素个数达到TREEIFY_THRESHOLD(默认8)且table大小>=MIN_TREEIFY_CAPACITY(默认64)会进行树化,否则对table扩容
hashSet.add("java");

PRESENT作为Map中所有的值,起占位的作用
![]B)HY~9RMWUTD[B5N7B%[I.png
执行put方法,key是传入的字符串”java”,value是PRESENT

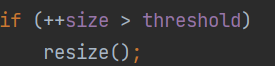
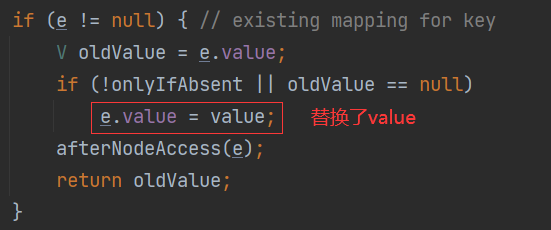
执行putVal方法,源码如下:final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// table是HashMap的一个属性,类型为Node[]// 如果当前的table为空或大小为0,第一次扩容if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length; // 扩到16// 根据传入的hash计算该key应该存放到table表的哪个索引位置,并把这个位置的对象赋给p// 如果这个位置为null,就创建一个Node把key存在这个位置if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;// 如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值一样// 并且满足以下两个条件之一就不能加入:// 1. 准备加入的key和当前位置结点(p)的key是同一个对象// 2. k不为null,不是同一个对象但是经过equals判断内容相同if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;// 再判断是否是一颗红黑树,如果是,就调用putTreeVal添加else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {// 如果table对应索引位置是一个链表,就使用for循环比较for (int binCount = 0; ; ++binCount) {// 如果比较到最后,都没有相同的,就将节点加到链表最后if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);// 添加到链表后,判断是否达到8个节点,到了8个就调用treeifyBin进行树化// 但再在treeifyBin方法中/*static final int MIN_TREEIFY_CAPACITY = 64;if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();*/// 表的大小不到64,暂时不进行树化,先扩容if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}// 比较过程中,如果有相同,不能加入,直接breakif (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 失败情况if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;// threshold,在resize里改变的,第一次是12// 大于临界值,就要扩容if (++size > threshold)resize();afterNodeInsertion(evict);// 空的,留着给HashMap子类return null;}
threshold:
LinkedHashSet
1. 底层是一个LinkedHashMap,维护了一个数组+双向链表
2. 源码
(1)LinkedHashMap维护了一个hash表和双向链表,LinkedHashMap有head和tail属性,每一个节点有before和after属性
![3AC~B$X]{Y0CVH2[[TTA2.png](https://cdn.nlark.com/yuque/0/2022/png/26273875/1649213127270-6addd615-94dd-4a94-b843-83cbe1d778e2.png#clientId=u62ef936c-a352-4&crop=0&crop=0&crop=1&crop=1&from=ui&id=u9f967181&name=3AC~B%24%60X%5D%7BY0CVH2%5B%5B%60TTA2.png&originHeight=186&originWidth=463&originalType=binary&ratio=1&rotation=0&showTitle=false&size=19886&status=done&style=none&taskId=ub6747df4-0a67-4377-b31c-0dac5444ddd&title=)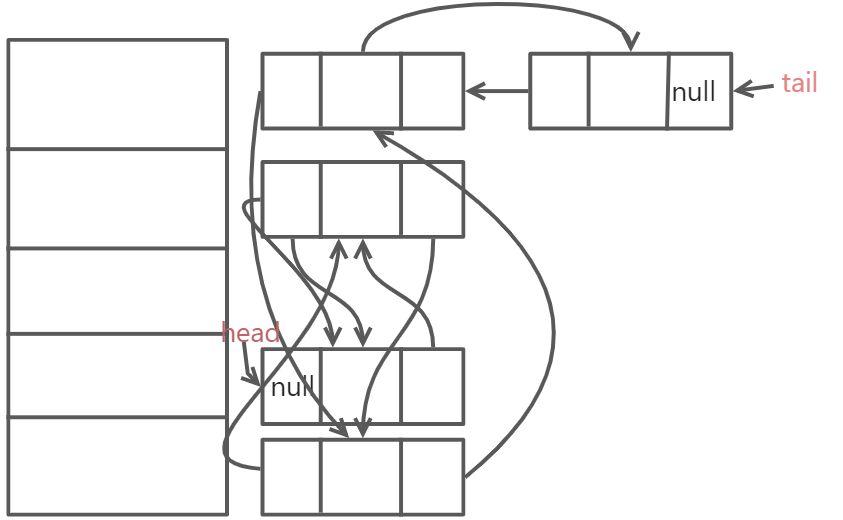
(2)添加
HashSet的子类,因此操作与添加和扩容等操作与HashSet一样,只是变成了双向链表
添加一个元素时,先求hash值,得到索引,确定在table中的位置,然后再把元素加入双向链表。如果已经存在,不添加
第一次添加时,直接将数组table 扩容到16,存放的结点类型是LinkedHashMap$Entry
![`JKSWKH(2YWD~HBFQL@S0O.png
![S~VQJ]G$I{U[S0A5_CP~_W.png](https://cdn.nlark.com/yuque/0/2022/png/26273875/1649214615570-4d3d8e3d-7479-48f4-89e3-f96148837290.png#clientId=u62ef936c-a352-4&crop=0&crop=0&crop=1&crop=1&from=ui&id=u94f7dc4d&name=S~VQJ%5DG%24I%7BU%5BS0A5_CP~_W.png&originHeight=167&originWidth=969&originalType=binary&ratio=1&rotation=0&showTitle=false&size=26589&status=done&style=none&taskId=u926d6ee0-c01c-44fb-b580-4db25805cac&title=)
添加时还是HashMap的add
![$Q_M0C}KH8TU82}4EPR7T5.png
Map(接口)
- 保存具有映射关系的数据key-value
key不允许重复,value可以重复。有相同key时,替换value
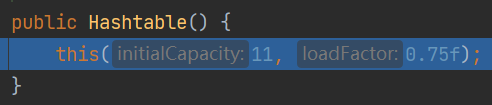
Hashtable
1. 底层数组 Hashtable$Entry[]
![4L]JS521MN~DD]U~)0FOS_J.png](/uploads/projects/quantianbuhuoyue@abmz1b/3bf6962fb93a4a6668a93753b64e22e2.png)
![%I2`8JOKO_]$L3)0MD5FIYC.png](/uploads/projects/quantianbuhuoyue@abmz1b/8f4a39cacec6a1ce065470f999153a2a.png)
由put方法, Hashtable对象的key、value值均不可为null。2. 源码
(1)线程安全的
(2)再次插入key相同的,value会覆盖
(3)初始化大小为11,临界值threshold=11*0.75=8
(4)扩容
按旧容量*2+1扩
addEntry方法:![BJ3FCU5ZI]TGIJ(_CD1}G4R.png](/uploads/projects/quantianbuhuoyue@abmz1b/56c2b5cbe58aa63c6ddf18d86bc208eb.png) ![@$FC4306_KCQ7WDB`05R20.png
![@$FC4306_KCQ7WDB`05R20.png
Properties
继承Hashtable,用于从xx.properties文件中加载数据到Properties类对象,进行读取和修改
HashMap
1. 底层是数组+链表+红黑树
2. 源码
(1) 一对k-v存放在一个HashMap$Node中,HashMap的putVal中:
![{6]P5K0_E7X(CY@ZBJZNFL.png

![XC82$10%CT]_WV_M17{LS94.png](/uploads/projects/quantianbuhuoyue@abmz1b/32dd92c834601179b0129f4b80cc75a9.png)
为了方便遍历,还会创建EntrySet集合 ,该集合存放的元素的类型 Entry, 而一个Entry对象就有k,v EntrySet
entrySet 中, 定义的类型是 Map.Entry ,但是实际上存放的是HashMap$Node:
static class Node
Map.Entry有方法K getKey(); V getValue();(2)再次添加相同的key,value会覆盖
(3)扩容
与HashSet部分的源码相同
- HashMap底层维护了Node类型的数组table,默认为null
- 创建对象时,加载因子初始化为0.75
- 添加k-v时,通过k的哈希值得到在table的索引,判断该索引处是否有元素,如果没有元素直接添加,如果有元素,继续判断该元素的k和准备加入的k是否相等,相等,直接替换v,不相等,判断是树结构还是链表结构,做出相应处理。添加时容量不够,扩容
- 第一次添加,table扩容至16,临界值为12
- 之后再扩容,table扩容至2倍32,临界值24
- 如果一条链表的元素个数超过EREEIFY_THRESHOLD(默认8),且table>=MIN_TREEIFY_CAPACITY(默认64),树化(红黑树)
(4)线程不安全的
LinkedHashMap
见LinkedHashSet部分TreeMap
见TreeSet部分

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}