笛卡尔积
在讲多表查询之前,先了解一下笛卡尔积。笛卡尔积就是集合 X 和集合 Y 的乘积。假设 A 表有 100 条数据,B 表有 100 条数据,本来分别查询两张表是挺快的,但是合并查询产生的结果是 100 * 100 = 10000 条记录。所以笛卡尔积的问题就是会导致数据查询效率降低。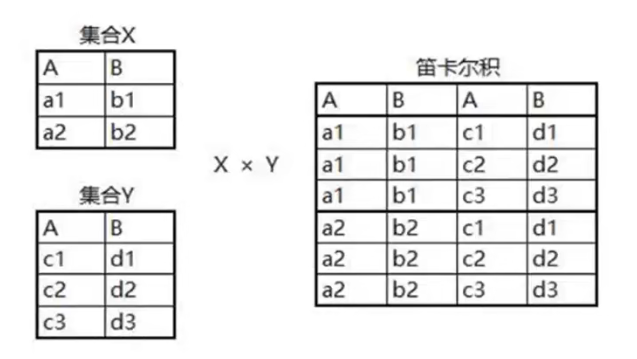
笛卡尔积产生的原因:
- 一个连接条件被遗漏时;
- 一个连接条件不正确时;
- 第一个表中的所有行被连接到第二个表的所有行时;
所以在查询中,尽量避免产生笛卡尔积的形成,在 where 子句中应当总是包含正确的连接条件。
多表查询的分类
多表查询的分类有:
- 交叉连接(cross join)
- 内连接(inner join)
- 外连接(outer join)
- 左连接(left outer join)
- 右连接(right outer join)
- 全连接(full outer join):Order 支持,mysql 不支持
- 联合查询(union)
left join、right join、inner join 和 full join 如下图所示。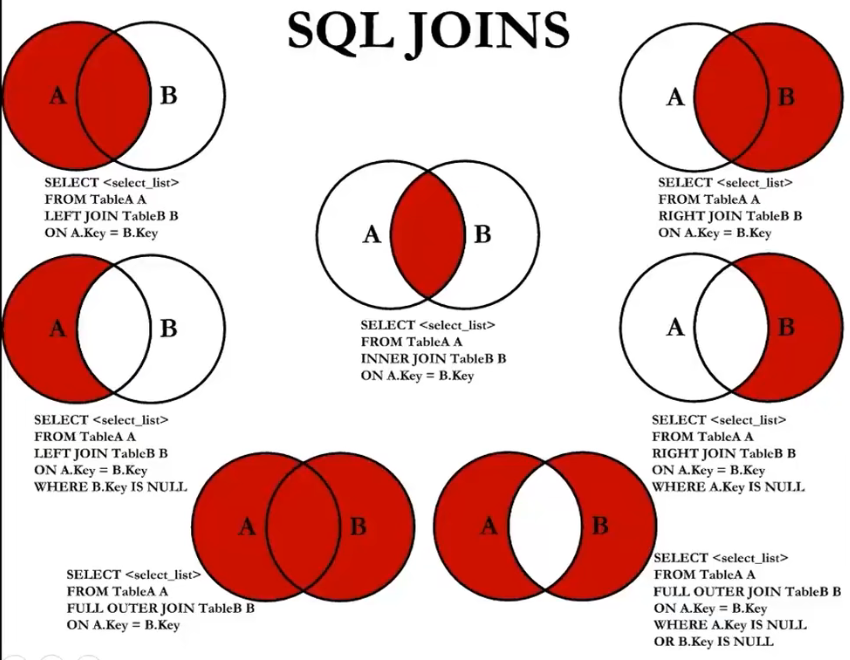
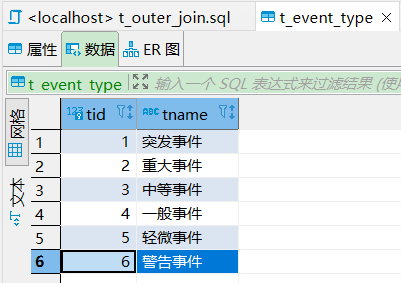
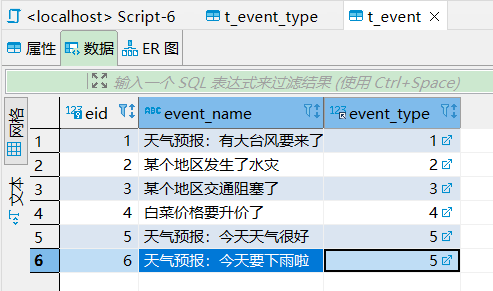
为了实践,先创建两个表并加入数据。
-- 创建表一: 事件类型create table if not exists t_event_type (tid int primary key auto_increment, -- 主键 自增tname varchar(10) -- 事件类型);-- 创建表二: 事件create table if not exists t_event (eid int primary key auto_increment, -- 主键 自增event_name varchar(20), -- 事件名称event_type int,constraint fk_event_tid foreign key(event_type) references t_event_type(tid) -- 外键映射到事件类型表);
交叉连接
交叉连接查询,是将两张表的数据与另外一张表彼此交叉,交叉连接产生的结果是笛卡尔积,虽然保证连接查询的整体完整性,但没有实际应用。
原理:
- 从第一张表依次取出每一条记录;
- 取出每一条记录后,与另外一张表的全部记录挨个匹配;
- 没有任何匹配条件,所有结果都会进行保留;
- 记录数 = 表一记录数 * 表二记录数(笛卡尔积);字段数 = 表一字段数 + 表二字段数
语法:表1 cross join 表2
select * from t_event te cross join t_event_type tet;
可以看到,查询结果是 36 条数据 = 6 * 6。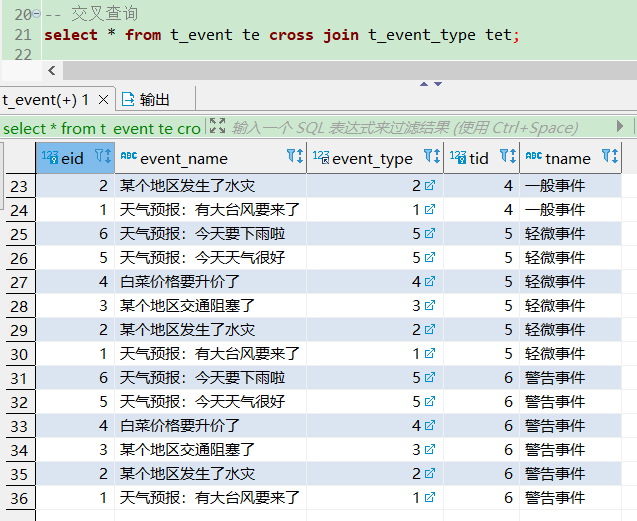
内连接【重点】
内连接,是从一张表中取出所有的记录去另外一张表中匹配,利用匹配条件进行匹配,成功了则保留,失败就放弃。
原理:
- 从第一张表中取出一条记录,然后去另外一张表中匹配;
- 利用匹配条件进行匹配;
- 匹配成功,保留,继续向下匹配;
- 匹配失败,向下继续,如果全表匹配失败,结束;
语法:表1 [inner] join 表2 on 匹配条件。
内连接通常是在对数据有精确要求的地方使用,必须保证两张表中都能进行数据匹配。
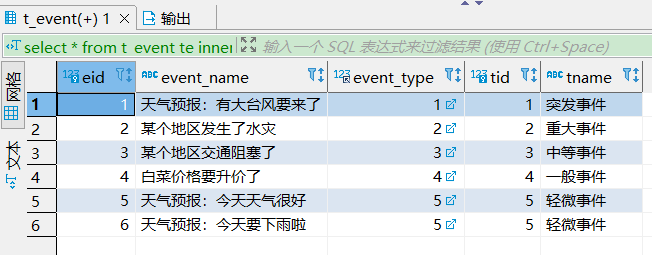
select * from t_event te inner join t_event_type tet on te.event_type = tet.tid;
-- 查询部分字段
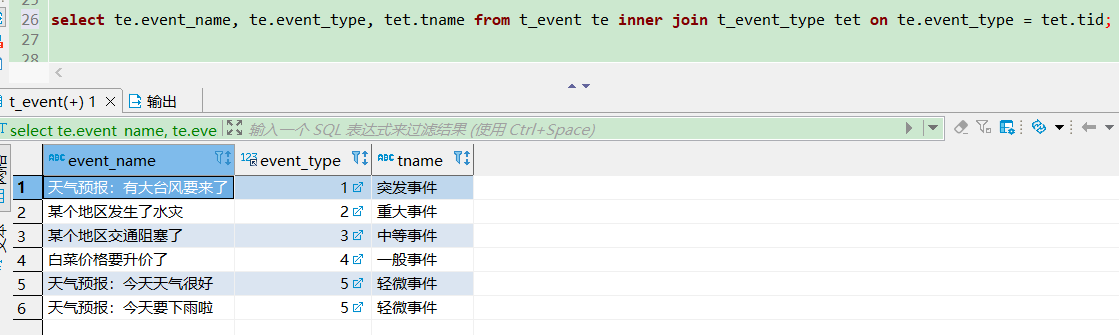
select te.event_name, te.event_type, tet.tname from t_event te inner join t_event_type tet on te.event_type = tet.tid;
一个难点的示例,如果员工和领导都是一张表,要显示员工名和领导名关系时,就要转换一下思路。后续会江西说,这里先提前了解。
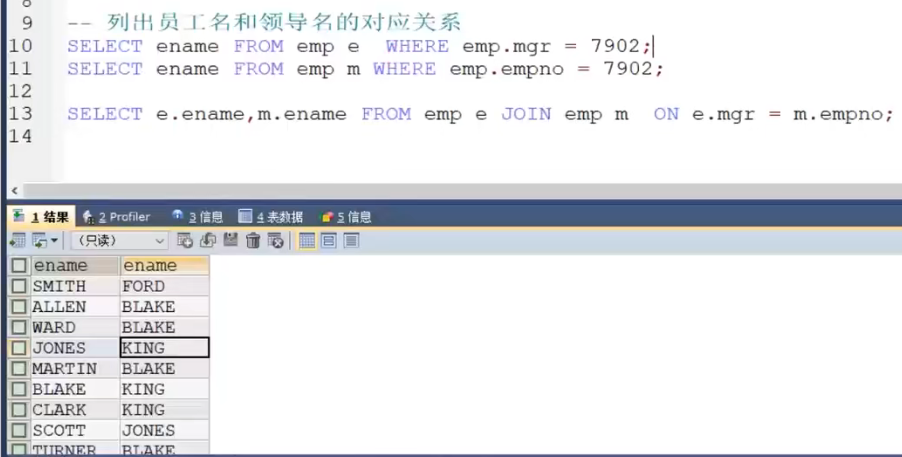

外连接【重点】
外连接,是按照某一张表作为主表(表中所有记录在最后都会保留),根据条件去连接另外一张表,从而得到目标数据。
外连接分为左外连接(左表是主表)、右外连接(右表是主表)。
【外连接的原理】
- 确定连接主表:left join 左边的表为主表,right join 右边的表为主表;
- 拿主表的每一条记录,去匹配另外一张表(从表)的每一条记录;
- 如果满足匹配条件,保留,不满足即放弃;
- 如果主表记录在从表中一条都没有匹配成功,那么也要保留该记录,从表对应的字段值为 null;
【特点】
外连接中主表数据记录一定会保存。连接之后不会出现记录数少于主表(内连接可能),左连接和右连接可以互相转换,但是数据对应的位置(表顺序)会改变。
【应用】
非常常用的一种获取数据的方式。作为数据获取对应的主表以及其他数据(关联)。
左外连接
左连接对应的主表数据在左边。
语法:主表 left join 从表 on 连接条件;
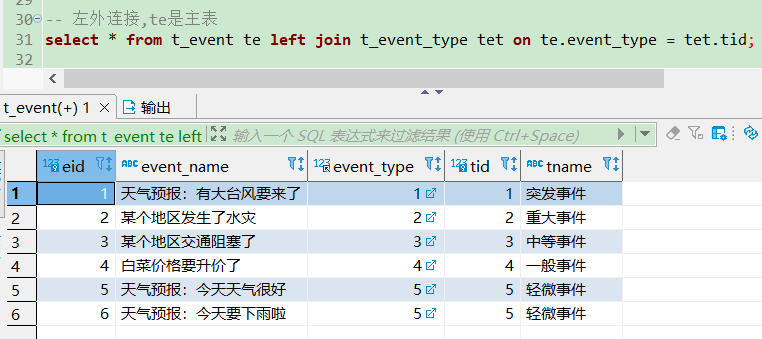
-- 左外连接,te是主表
select * from t_event te left join t_event_type tet on te.event_type = tet.tid;
右外连接
右连接对应的主表数据在右边。
语法:从表 right join 主表 on 连接条件;
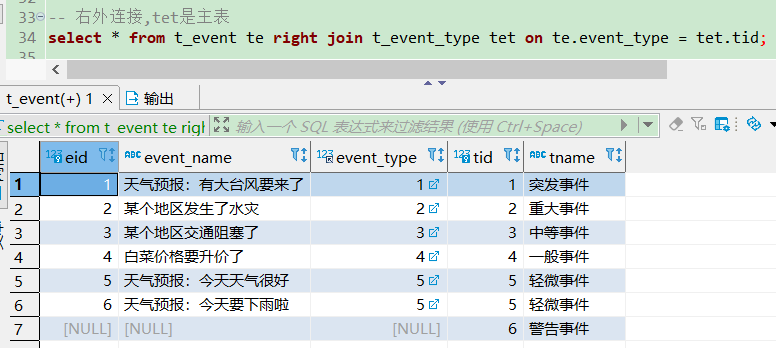
-- 右外连接,tet是主表
-- 类型6在te表中没有出现,所以前面部分是null,后面警告事件
select * from t_event te right join t_event_type tet on te.event_type = tet.tid;
联合查询
联合查询是可合并多个相似的选择查询的结果集。等同于将一个表追加到另一个表,从而实现将两个表的查询组合在一起,使用是 UNION 或 UNION ALL。
将同一张表中不同的结果(需要对应多条查询语句来实现),合并到一起展示数据。
在数据量大的情况下,会对标进行分表操作,需要对每张表进行部分数据统计,使用联合查询来将数据存放到一起显示。
语法:
select 语句
union [union 选项]
select 语句
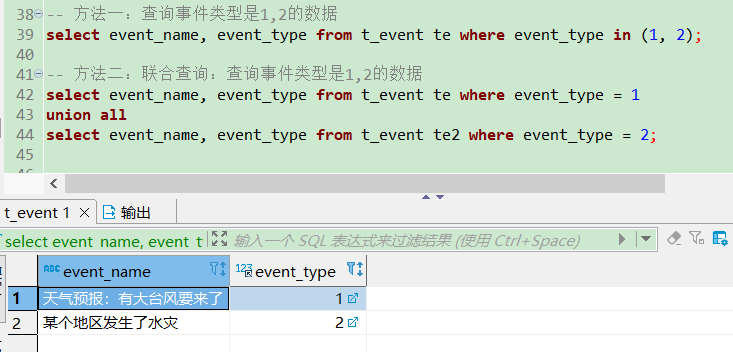
-- 方法一:查询事件类型是1,2的数据
select event_name, event_type from t_event te where event_type in (1, 2);
-- 方法二:联合查询:查询事件类型是1,2的数据
select event_name, event_type from t_event te where event_type = 1
union all
select event_name, event_type from t_event te2 where event_type = 2;
子查询分类
子查询允许把一个查询嵌套在另一个查询当中。
【特点】
- 子查询可以包含普通 select 可以包括的任何子句,如:distinct、group by、order by、limit、join 和 union 等。
- 对应的外部查询必须是以下语句之一:select、insert、update、delete、set 或 do。
- 子查询的位置:select 中、from 后、 where 中, 而在 group by 和 order by 中无实用意义。
【子查询执行顺序】
执行顺序:先执行子查询,子查询的返回结果作为主查询的条件,再执行主查询;
执行次数:子查询只执行一遍;
执行结果:若子查询的返回结果为多个值,mysql 会去掉重复值之后,再将结果返回给主查询。
子查询分类有:
- 标量子查询:返回单一值的标量,最简单的形式;
- 列子查询:返回的结果集是 N行一列;
- 行子查询:返回的结果集是 一行N列;
- 表子查询:返回的结果集是 N行N列;
可以使用的操作符:= > < >= <= <> ANY IN SOME ALL EXISTS
为了测试新增了两个表 emp(员工表)和dept(部门表)。
-- 创建部门表
create table if not exists dept(
deptno int(10) primary key, -- 部门编号
deptname varchar(20) -- 部门名称
);
-- 创建员工信息表
create table if not exists emp(
empno int(10) primary key, -- 员工编号
ename varchar(20), -- 姓名
job varchar(20), -- 职位
mgr int(10), -- 领导编号
hiredate date, -- 入职日期
sal int(100), -- 工资
deptno int(10), -- 部门id,外键
constraint fk_emp_deptno foreign key(deptno) references dept(deptno) -- 外键
);

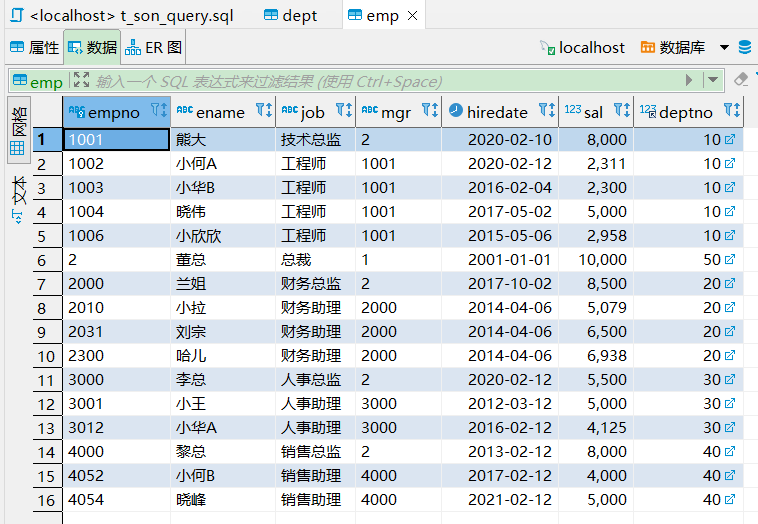
标量子查询
返回单一值的标量,最简单的形式。
-- 查询工资最高的员工信息
-- 子查询中只查询出单一的标量,再通过该标量查询出整条记录数据
select * from emp where sal = (select max(sal) from emp);
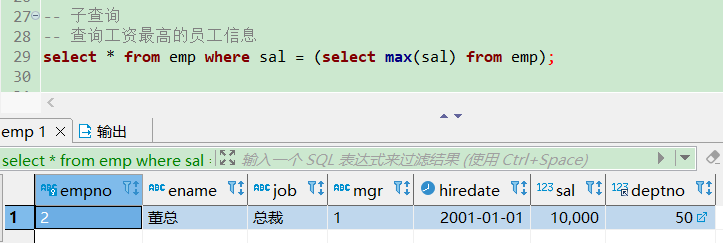
列子查询
返回的结果集是 N 行一列。
-- 列子查询
-- 查询每个部门最低工资的员工
select ename from emp where sal in (select min(sal) from emp group by deptno);
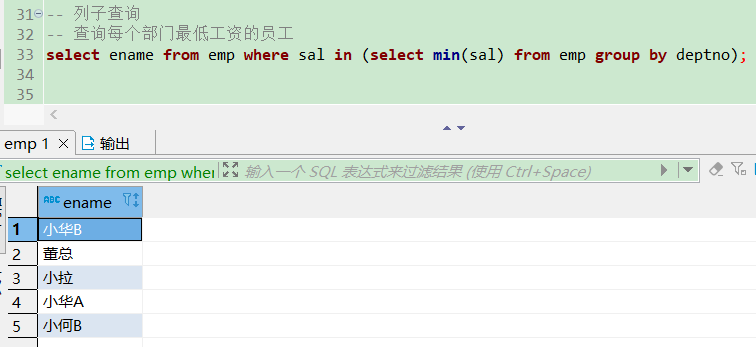
行子查询
返回的结果集是 一行 N 列。
-- 行子查询
-- 查询部门10,姓名是小华B的员工信息
select * from emp where (deptno, ename) = (select deptno, ename from emp where ename = '小华B' and deptno = 10);
表子查询
返回的结果集是 N 行N 列。
-- 表子查询
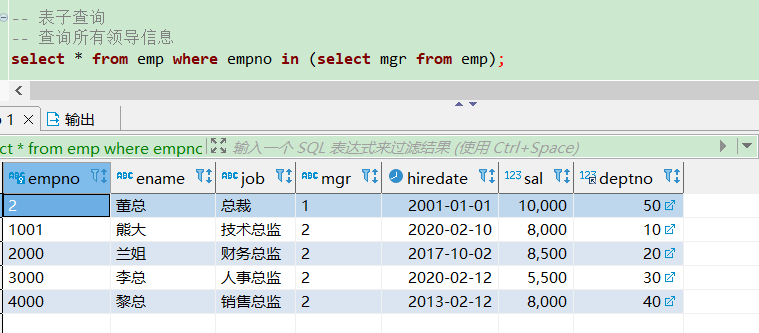
-- 查询所有领导信息
select * from emp where empno in (select mgr from emp);
但是上面这几种分类方式比较难做好分类的查询,所以有了一种新的方式去做分类:关联子查询和非关联子查询。
关联子查询和非关联子查询
非关联子查询
外部查询和内部子查询语句之间没有关联,仅仅靠值来关联,这种查询叫非关联子查询。
如下示例。
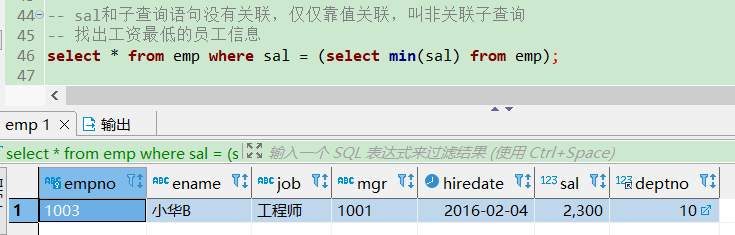
-- 内部查询和子查询语句没有关联,仅仅靠值sal关联,叫非关联子查询
-- 找出工资最低的员工信息
select * from emp where sal = (select min(sal) from emp);
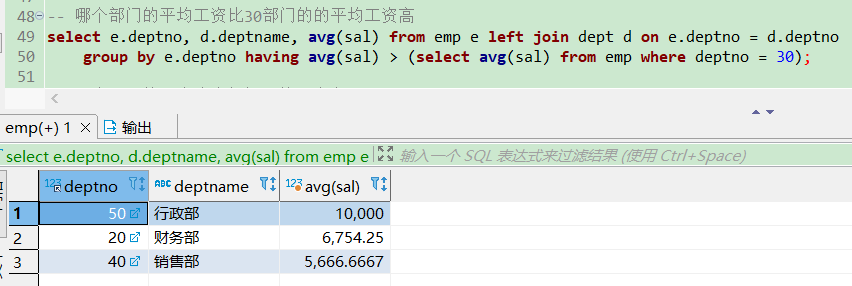
-- 哪个部门的平均工资比30部门的的平均工资高
select e.deptno, d.deptname, avg(sal) from emp e left join dept d on e.deptno = d.deptno
group by e.deptno having avg(sal) > (select avg(sal) from emp where deptno = 30);
关联子查询
内部子查询的执行需要依赖于外部查询。
关联子查询的执行顺序:先执行主查询,拿到一条记录,再到子查询作为条件执行。
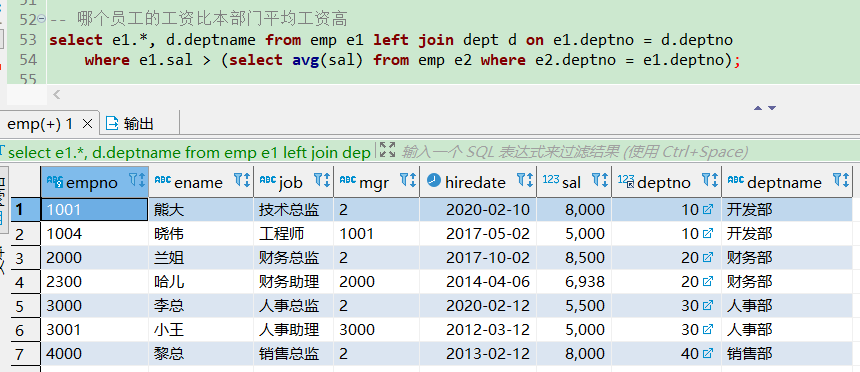
-- 哪个员工的工资比本部门平均工资高
select e1.*, d.deptname from emp e1 left join dept d on e1.deptno = d.deptno
where e1.sal > (select avg(sal) from emp e2 where e2.deptno = e1.deptno);
EXISTS(存在)运算符
原理:EXISTS 采用的是循环(loop)方式,判断 outer 表中是否存在记录,只要在 inner 表中找到一条匹配的记录即可。
执行步骤:
1)外部查询得到一条记录(查询先从 outer 表中读取数据)并将其传入到内部查询的表;
2)对 inner 表中的记录一次扫描,若根据条件存在一条记录与外表中的记录匹配,立即停止扫描,返回 true,将外表中记录放入结果集中,若扫描全部记录,没有任何一条记录符合匹配条件,返回 false,外表中的该记录被过滤掉,不能出现在结果集中。
3)重复执行步骤 1、2,直到把 outer 表中的所有记录判断一遍。
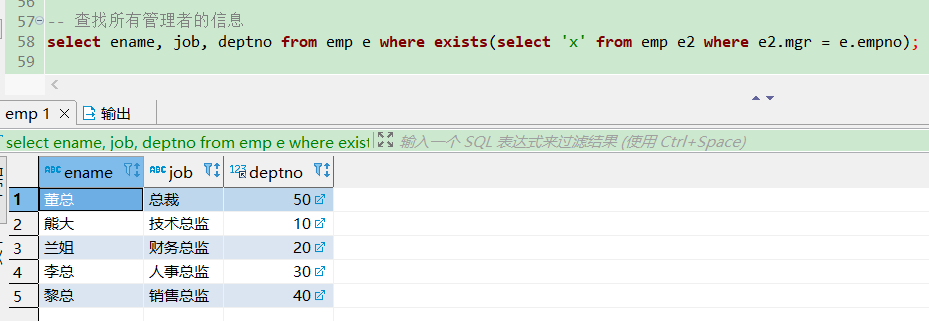
-- 查找所有管理者的信息
-- 首先在外部查询获取一条记录,判断该记录是否满足子查询的条件(e1.mgr=e.empno)
-- 满足那么这条记录就留下,否则就过滤掉,遍历下一条记录
select ename, job, deptno from emp e where exists(select 'x' from emp e2 where e2.mgr = e.empno);
NOT EXISTS(不存在)运算符
-- NOT EXISTS
-- 查询哪个部门没有员工
select * from dept d where not exists (select * from emp e where e.deptno = d.deptno);
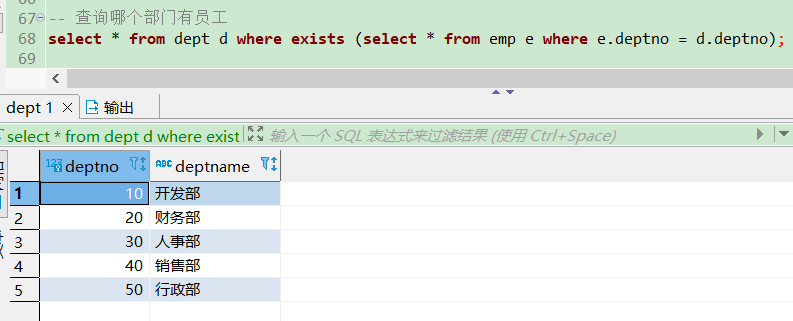
-- 查询哪个部门有员工
select * from dept d where exists (select * from emp e where e.deptno = d.deptno);
为了测试,这里多加一个测试部,deptno 为 60。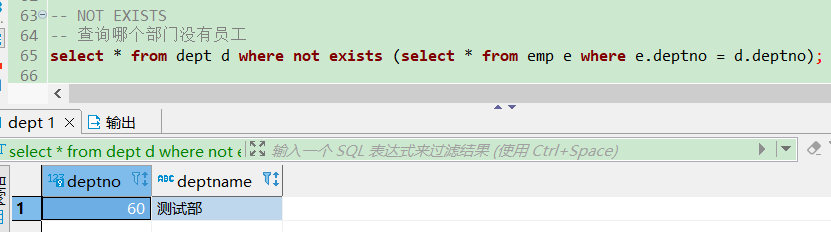
【总结】IN 和 EXISTS 比较
- EXISTS 是用循环的方式,由于外表的记录数决定循环次数,故对于 EXISTS 影响最大,所以外表的记录数要少才适合;
- IN 先执行子查询,子查询的返回结果去重之后,再执行主查询,所以子查询的返回结果越少,越适合使用该方式;
分页查询
当数据量太多,在显示到页面时就需要使用分页查询。
limit 子句可以被用于指定 select 语句返回的记录数。需要注意以下几点:
- 第一个参数指定第一个返回记录行的偏移量,注意初始记录行的偏移量是 0(不是 1);
- 第二个参数指定返回记录行的最大数目;
- 如果只给定一个参数:它表示返回最大的记录行数目
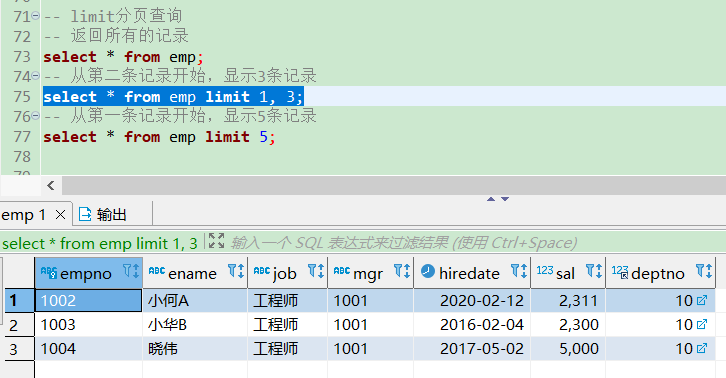
-- limit分页查询
-- 返回所有的记录
select * from emp;
-- 从第二条记录开始,显示3条记录
select * from emp limit 1, 3;
-- 从第一条记录开始,显示5条记录
select * from emp limit 5;
to be continue…

若有收获,就点个赞吧
0 人点赞
