Hadoop伪分布式安装
一、准备
- Hadoop伪分布式安装前的准备:安装VMware、安装CentOS 7、配置CentOS7、为安装Hadoop做好环境准备
- Hadoop伪分布式安装:安装WinSCP、安装FinalShell、安装JDK、安装Hadoop
- Hadoop验证:在启动Hadoop之前先要格式化,启动后可以通过进程查看、浏览文件以及浏览器访问等方式验证Hadoop是否能正常运行
二、Hadoop伪分布式安装前的准备
Hadoop支持三种安装模式
- 本地模式:在系统中下载Hadoop,默认情况下,他会呗配置为一个独立的模式,用于运行Java程序,没有太多实用价值,不做详解;
- 伪分布式模式:在单台机器上的分布式模拟,这种模式对开发非常有用;
- 安全分布式模式:又叫集群安装,Hadoop安装在最少两台及玄机的集群中。
1. 安装VMware
2. 安装CentOS 7
3. 配置CentOS 7
- 设置IP```shell
查看本机IP
ifconfig配置成固定IP
```
修改主机名```shell
永久修改主机名为hadoop0
切换到root用户
su root hostnameclt set-hostname hadoop0 restart ```
配置hosts文件```shell vim /etc/hosts
在文件末尾添加一行
192.168.186.129 hadoop0 ```
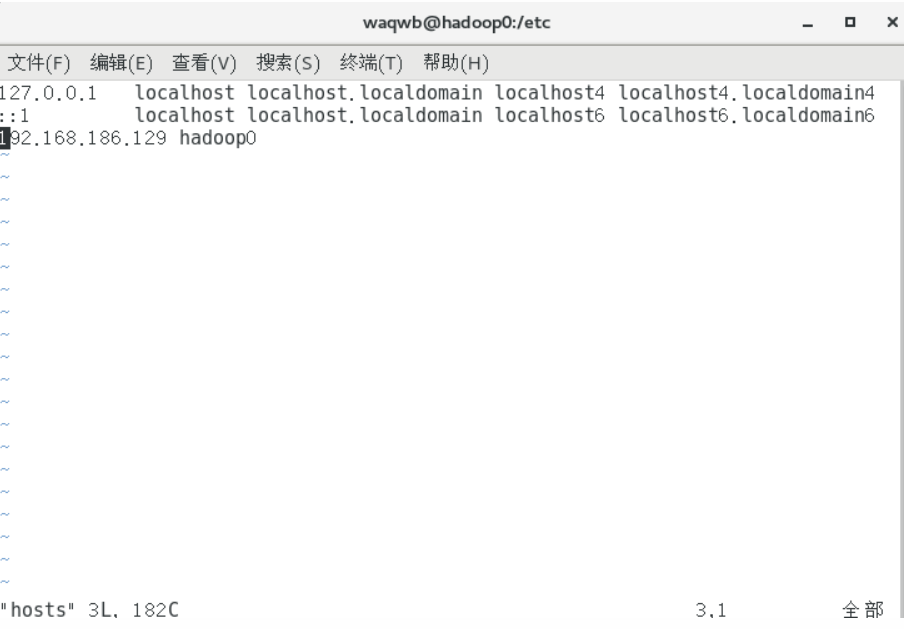
> 如果IP地址有改变,/etc/hosts中的IP必须爷手动同步更改
- 关闭防火墙```shell
开启防火墙
systemctl start firewalld.service重启防火墙
systemctl restart firewalld.service关闭防火墙
systemctl stop firewalld.service查看防火墙状态
systemctl status firewalld.service开机禁用防火墙
systemctl disable firewalld.service ```在生产环境中,服务器防火墙是不能关闭的,否则有重大安全风险 只能配置防火墙规则,打开特定端口
- 禁用selinux
修改/etc/selinux/config,永久关闭selunux安全策略shell vim /etc/selinux/config SELINUX=disabled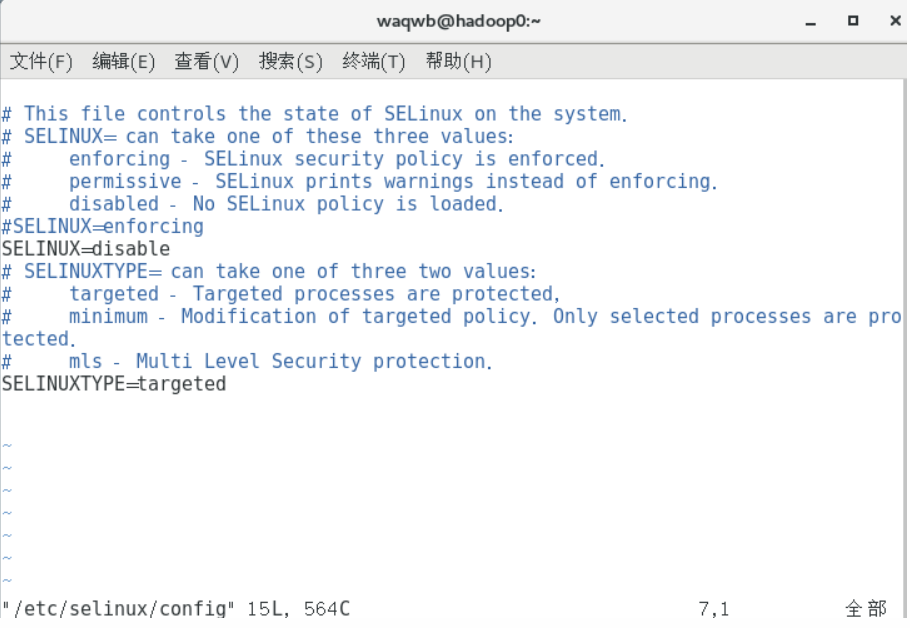
- 设置SSH免密码登陆(先ssh一下,验证登陆需要密码)
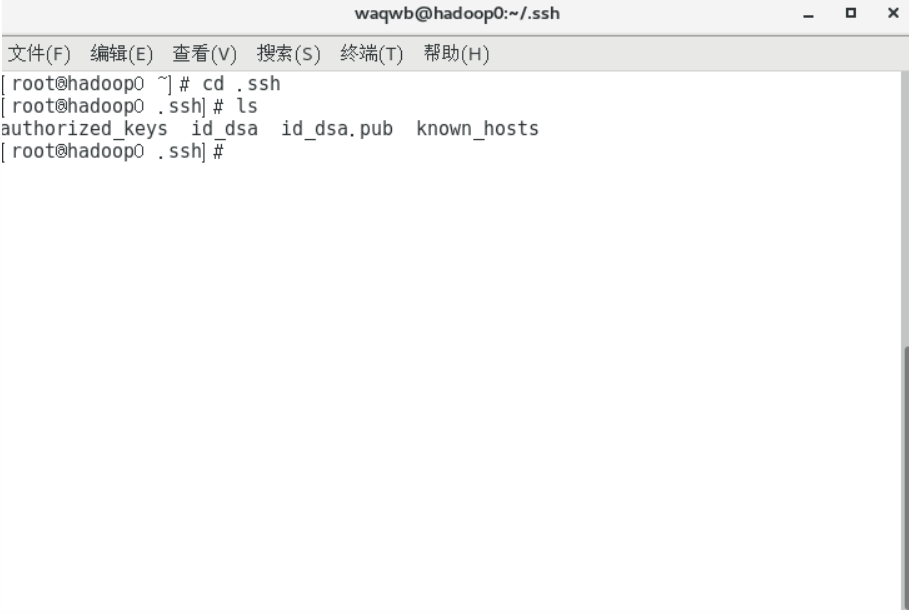
Hadoop各组件之间使用SSH登陆,为了免输密码,可以设计SSH免密码登陆```shell进入密钥存放目录
cd /root/.ssh删除旧密码
rm -rf *生成密码
ssh-keygen -t dsa一路回车
将生成的密钥文件id_dsa.pub复制到SSH指定的密钥文件authorized_keys中
cat id_dsa.pub >>authorized_keys测试SSH免密码登陆是否成功
ssh hadoop0输入yes继续,如果没有提示输入密码,则证明免密码登陆成功
```
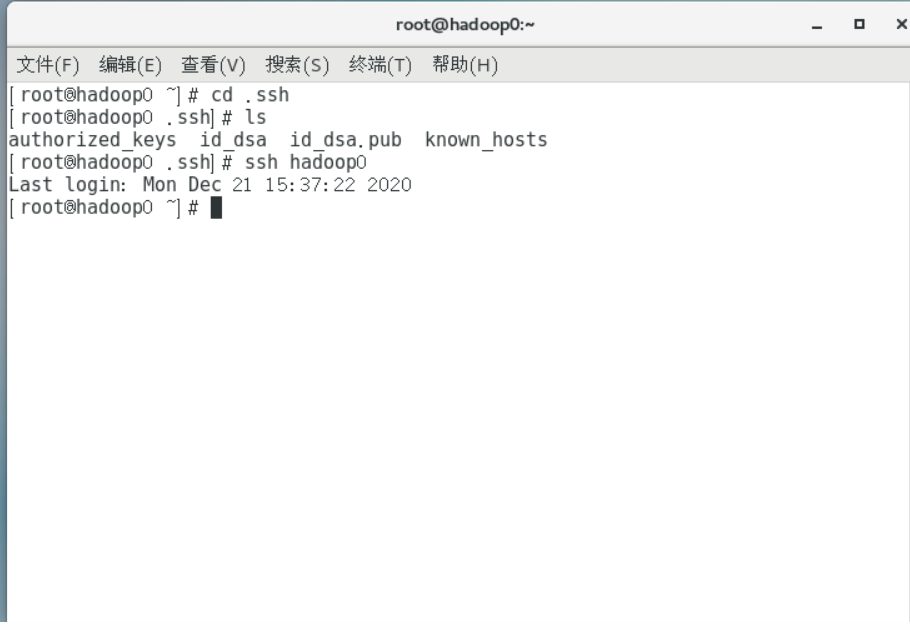
重启,使修改主机名等配置生效
4. 安装WinSCP
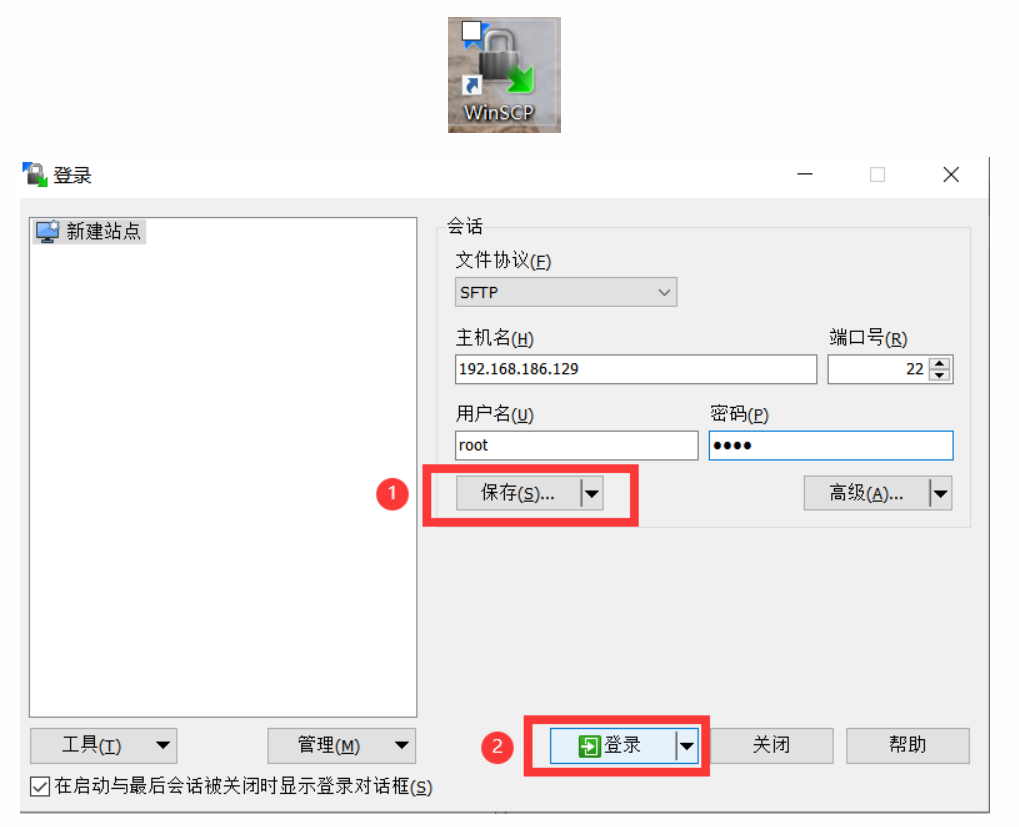

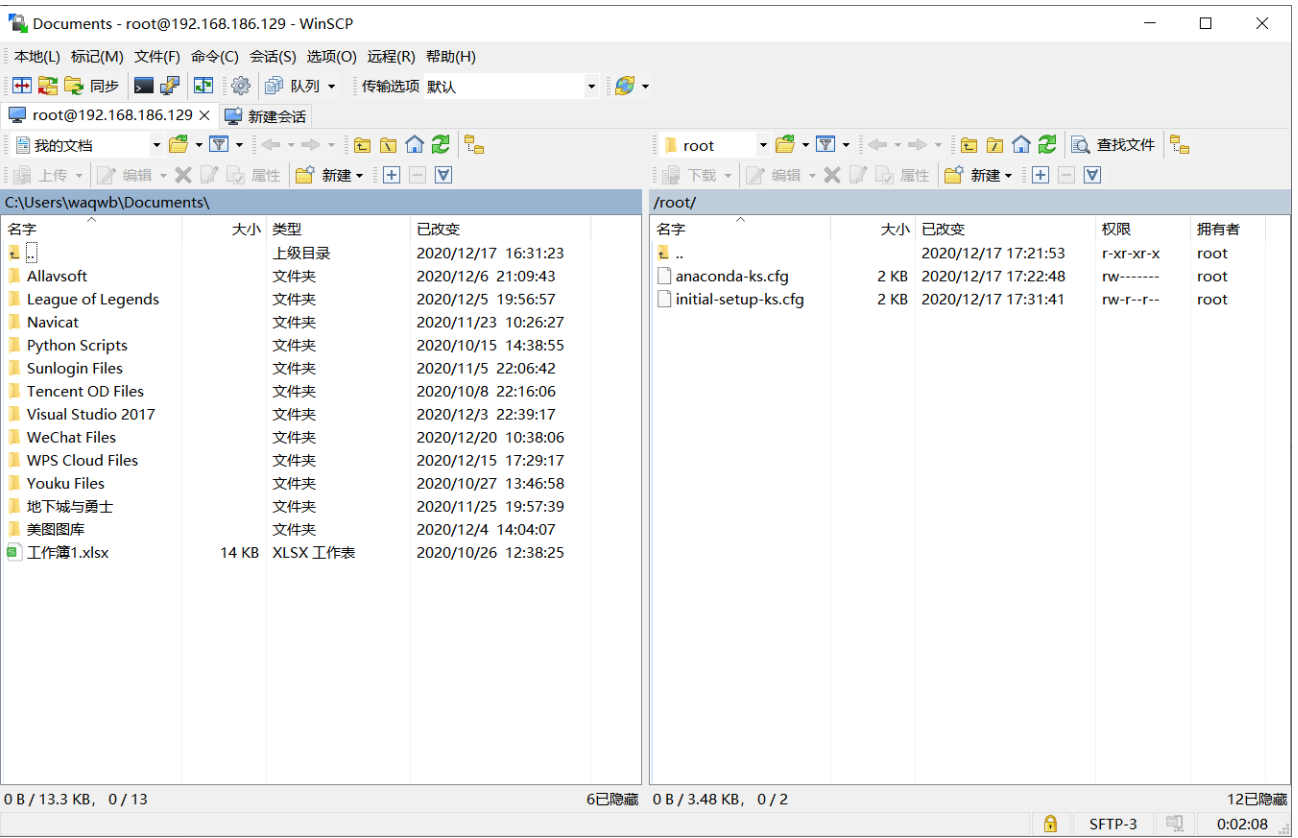
成功连接后,可以选中文件,右键-上传,上传至虚拟机
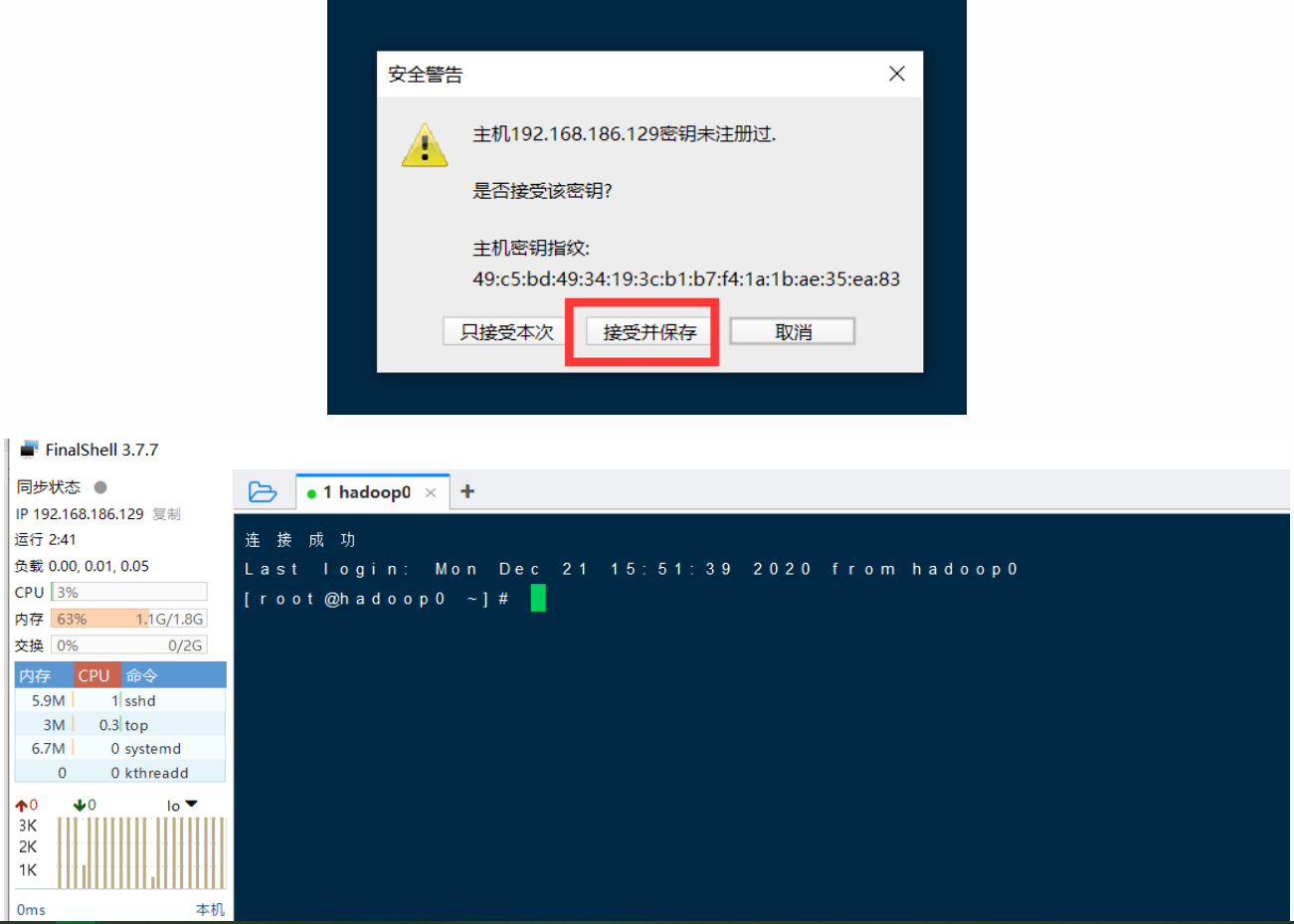
5. 安装FinalShell
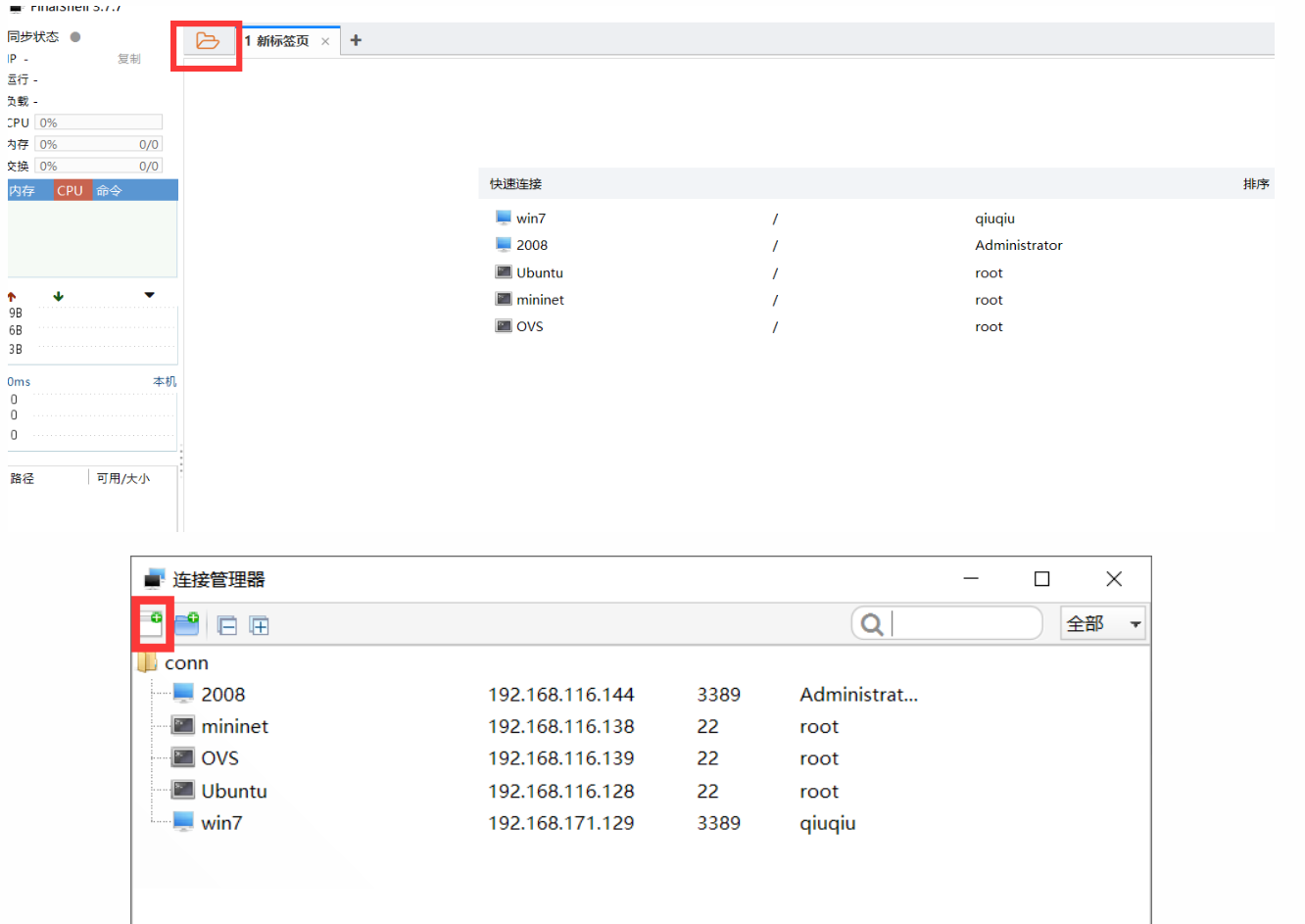
选择SSH登陆
填入IP,用户名和密码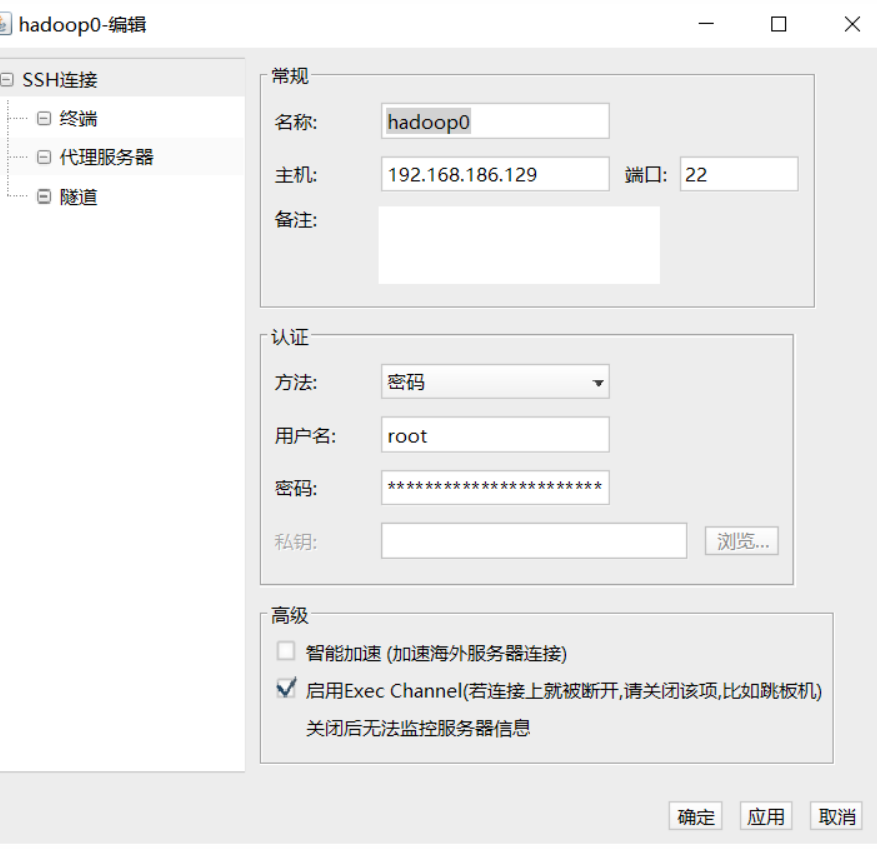
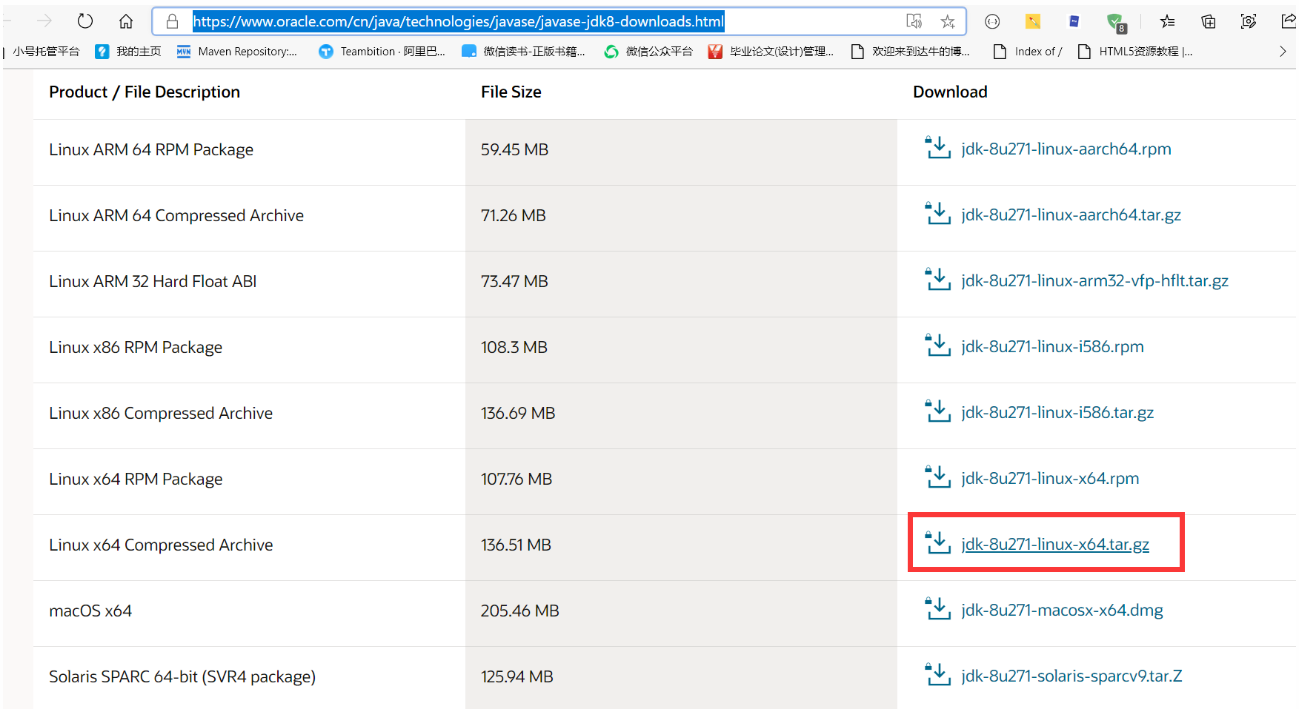
6. 下载JDK
链接:
https://www.oracle.com/cn/java/technologies/javase/javase-jdk8-downloads.html
使用WinSCP
用WinSCP传输到hadoop0的/usr/local目录下

使用FinalShell
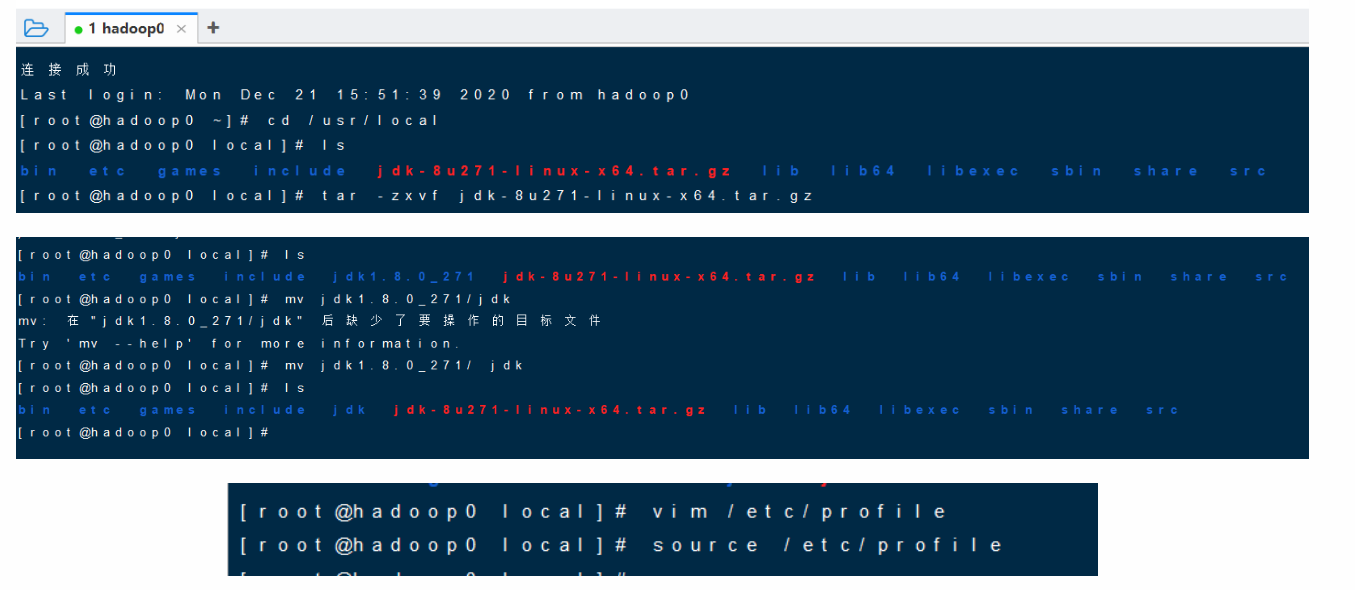
# 切换目录到/usr/localcd /usr/local# 解压jdk文件tar -zxvf jdk-8u271-linux-x64.tar.gz# 配置环境变量# 1.使用mv命令重命名解压后的文件夹jdk1.8.0_271为jdkmv jdk1.8.0_271/ jdk# 2.将jdk安装目录进行配置vim /etc/profile# 进入编辑iexport JAVA_HOME=/usr/local/jdkexport PATH=$PATH:$JAVA_HOME/bin# 退出编辑esc# 保存:wq# 使设置生效source /etc/profile# 验证java -version


7. 安装Hadoop
下载链接:
https://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/
使用WinSCP
同理上传到/usr/local目录下
使用FinalShell
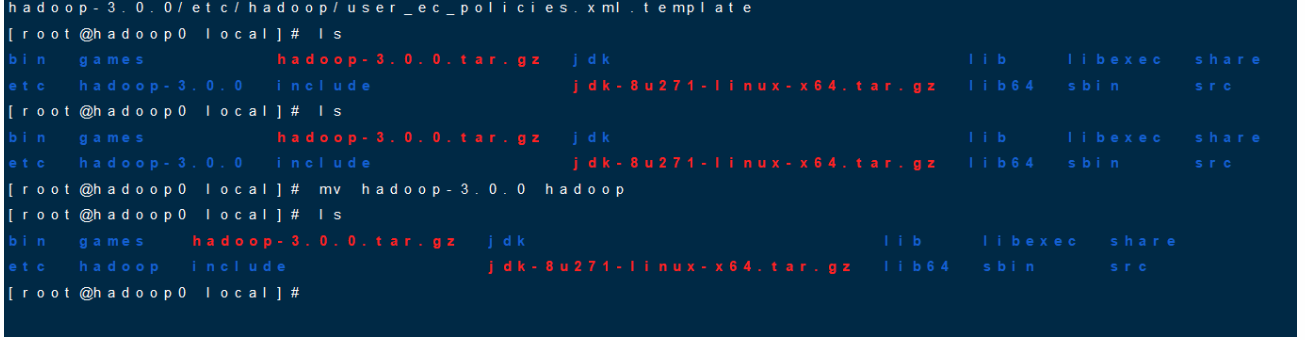
配置Hadoop
tar -zxvf hadoop-3.0.0.tar.gzlsmv hadoop-3.0.0 hadoop
配置环境变量
vim /etc/profileiexport JAVA_HOME=/usr/local/jdkexport HADOOP_HOME=/usr/local/hadoopexport PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexport HDFS_NAMENODE_USER=rootexport HDFS_DATANODE_USER=rootexport HDFS_SECONDARYNAMENODE_USER=rootexport YARN_RESOURCEMANAGER_USER=rootexport YARN_NODEMANAGER_USER=rootESC:wqsource /etc/profile
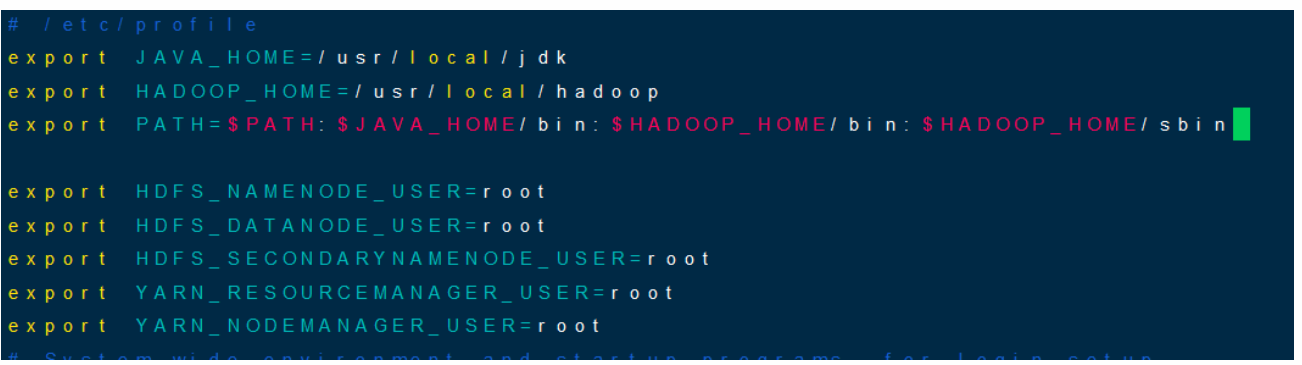
$HADOOP_HOME/bin和¥HADOOP_HOME/sbin都必须加入到PATH中 Hadoop的早期版本不需要将Hadoop各进程的用户设为root
配置hadoop-env.sh
切换目录至/usr/local/hadoop/ect/hadoop
cd /usr/local/hadoop/ect/hadoop
修改hadoop-env.sh
vim hadoop-env.sh# 将第37行解除注释,并更改JAVA_HOME=/usr/local/jdk

vim core-site.xml# 在<configuration>标签间加入如下内容
# 配置HDFS的访问URL和端口<property><name>fs.defaultFS</name><value>hdfs://hadoop0:9000/</value><description>NameNode URI</description></property></configuration>
配置hdfs-site.xml
切换到/usr/local/hadoop/etc/hadoop目录下
vim hdfs-site.xml
# 在<configuration>标签后加入如下内容
# 配置访问NameNode和DataNode的元数据存储路径以及NameNode和SecondNameNode的访问端口
<property>
<name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop0:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name><value>hadoop0:50090</value>
</property>

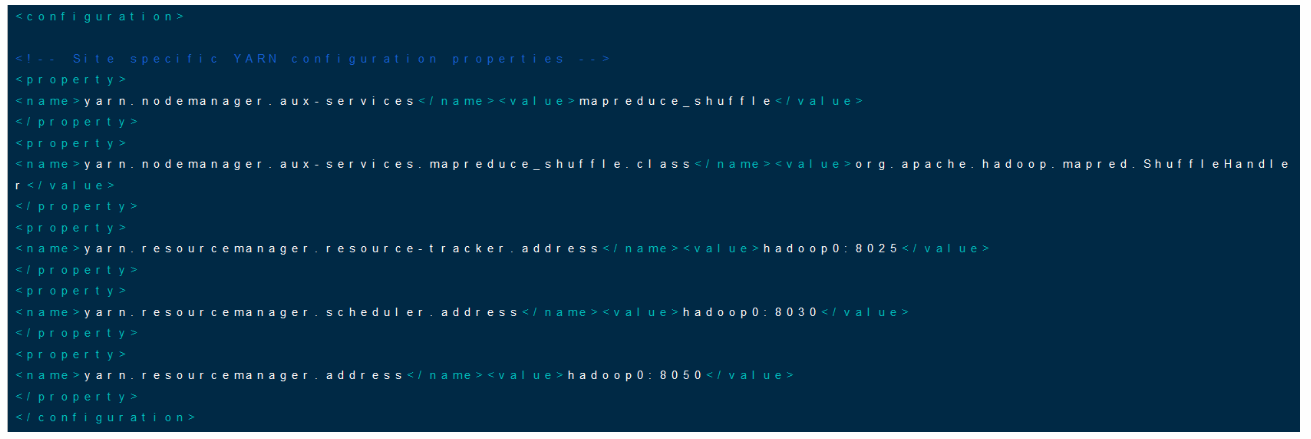
配置yarn-site.xml
vim yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop0:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop0:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop0:8050</value>
</property>
如果在使用Hadoop中出错或者启动不了,可能需要重新格式化
# 停止Hadoop cd /usr/local/hadoop stop-all.sh # 删除data和logs文件夹 rm -rf data/ logs/ # 格式化 hadoop namenode -format
8. 启动Hadoop
cd /usr/local/hadoop/sbin
start-all.sh

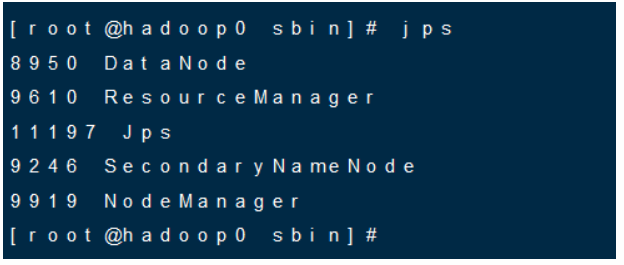
9. 查看Hadoop相关进程
jps
10. 浏览文件
hadoop fs -ls /

11. 浏览器访问
打开CentOS,使用内置浏览器打开:http://hadoop0:50070
或者打开:http://192.168.186.129:50070

NameNode端口:50070
DataNode端口:9864
SecondaryNameNode端口:50090
ResouceManager端口:8088
12.错误:
- 如果出现Name or Service not Known,那么请检查hosts文件中主机名是否配置正确
- 如果格式化失败,那么在改完错误之后,先检查Hadoop安装路径下是否出现tmp目录,如果出现,那么需要先将这个tmp目录删除之后再重新格式化

若有收获,就点个赞吧
0 人点赞
