目标爬取站点:https://www.dytt8.net/index.htm
目标:爬取站点【最新电影】分类内第一页的所有影片下载链接与电影海报链接
爬虫框架:
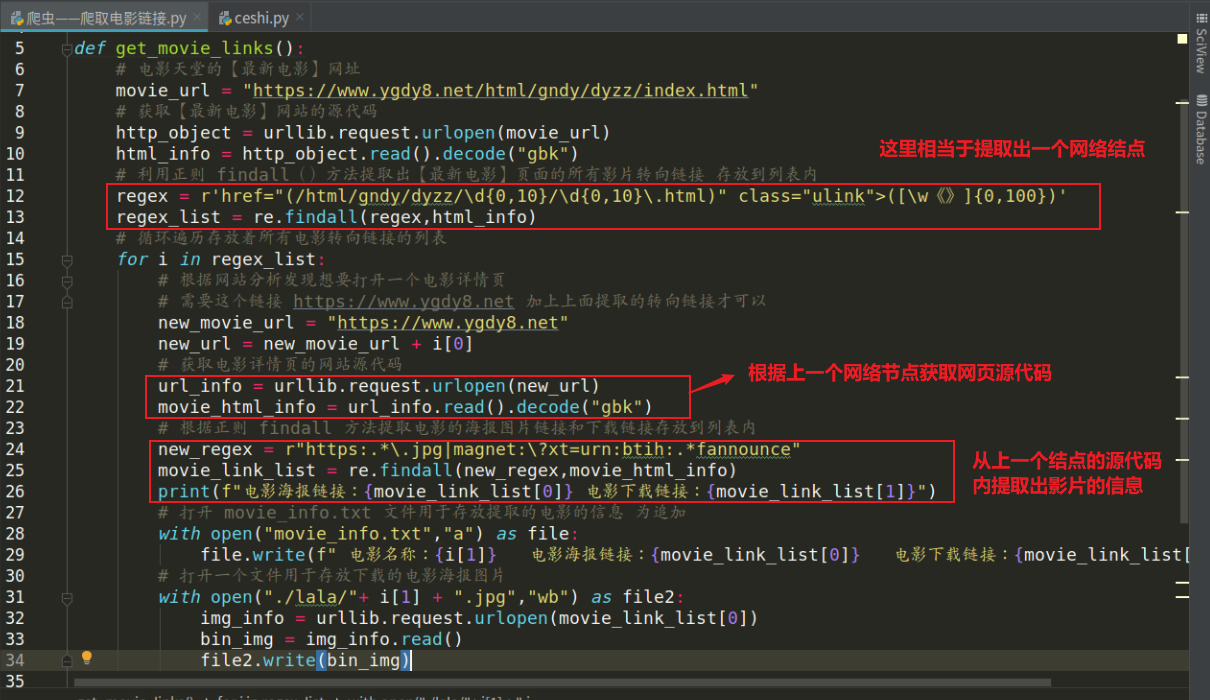
定义函数1:用来获取电影的转向链接以及利用转向链接获取电影的下载链接
1:利用urllib.request(url)方法获取最新电影页面的源代码
2:个利用re.findall()方法在源代码中匹配符合规则的影片转向链接(点击影片进入详情页的链接)【相当于一个网络结点】
3:利用for循环遍历整个存放电影转向链接的列表
3:再次利用urllib.request(new_url)获取电影详情页的源代码
4:再次利用re.findall()匹配出电影的下载链接
5:将下载链接保存至字典内!
定义主函数:运行函数1
主要代码截图:

若有收获,就点个赞吧
0 人点赞
