目标:
1:知道(?P
2:掌握引用分组符号 “\num” 的作用
3:掌握(?P=组别名)引用起别名后分组所匹配的数据
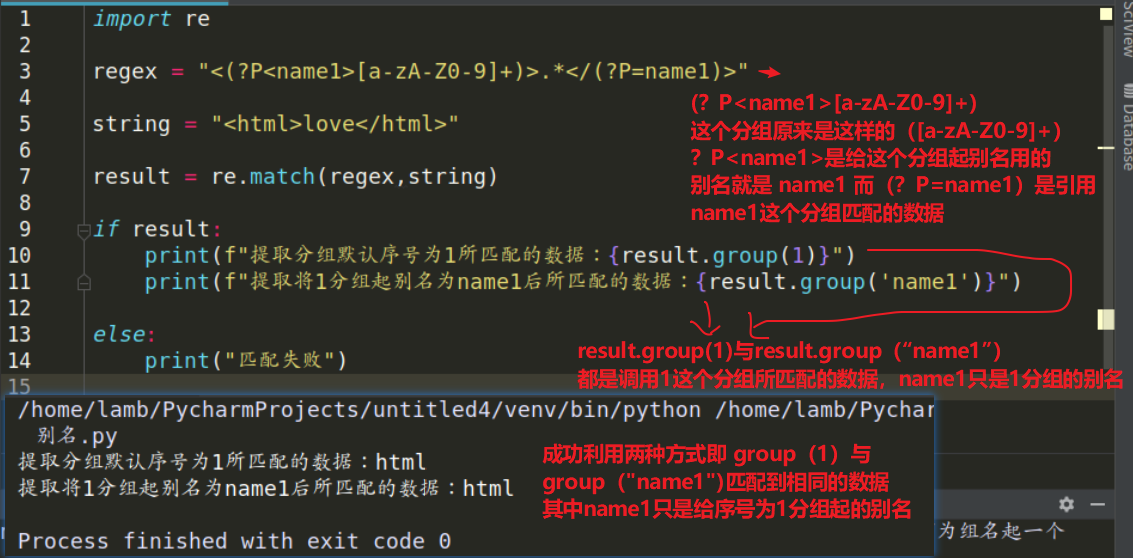
一:(?P
功能:为原来的分组起一个别名,方便在正则表达式后面引用这个分组匹配的数据
语法:(?P
示例:<([a-zA-Z0-9]+)> 其中([a-zA-Z0-9]+)是一个分组,这个分组默认序号(名字)是1,利用 ?P
注意事项:
1:起别名是在保留原有名字的前提下又起了另外一个名字,不是重命名
2:正则表达式中的P为大写的p
代码截图:
二:引用分组符号 “\num”
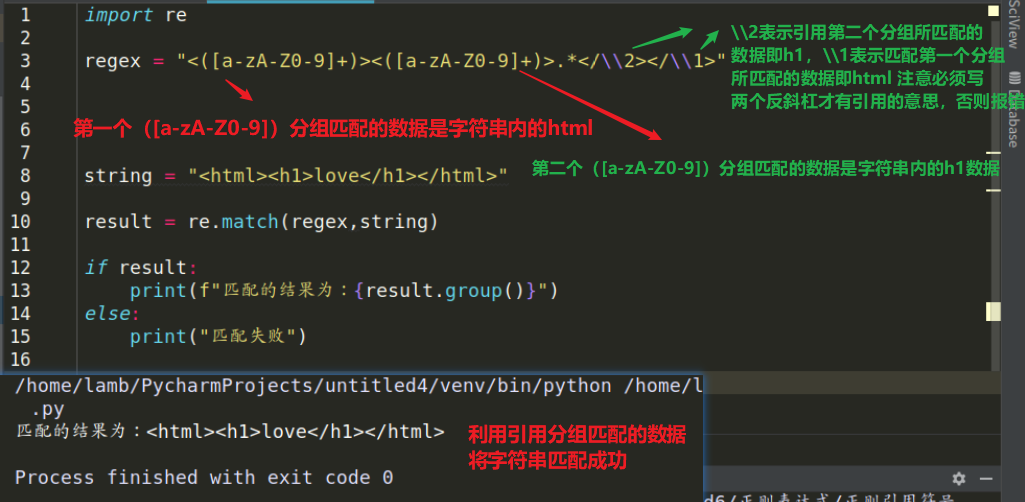
功能:引用序号为 num 那个分组所匹配的数据 ,即引用分组序号为num那个分组里面所匹配的字符串数据
语法:<([a-zA-Z0-9]+)>.*</\1>
简化 \1 就是引用第一个分组匹配的数据
\2 就是引用第二个分组匹配的数据
注意事项:
1:正则表达式内使用“\num”符号时,引用组号为num那个组所匹配的数据,组号为num的分组匹配了什么数据,那么 “\num”所引用的数据就是什么数据
2:在python 内写正则使用引用符号 \num 时,要加两个 \ 例如 \ \ 1才可以引用成功,因为在正则中\ 有着转义的功能,\1代表将1转义了,而不是引用第一个分组匹配的数据,因此我们要写两个 \ 才能成功引用,关于这可以用 r 完美解决此问题!!!
示例:正则表达式 为 <([a-zA-Z0-9]+)>.*</\1> 字符串为 woaini 根据正则表达式匹配的规则成功将字符串内的所有字符进行匹配! ([a-zA-Z0-9]+)这个分组匹配的数据为 html ,那么 </\1> 所匹配的数据就是 如果字符串是 那么分组 ([a-zA-Z0-9]+) 匹配的数据为 title,那么 </\1> 所匹配的数据就是
图示:
如果不理解本节课内容请看网站的内容:https://www.cnblogs.com/work115/p/5614199.html
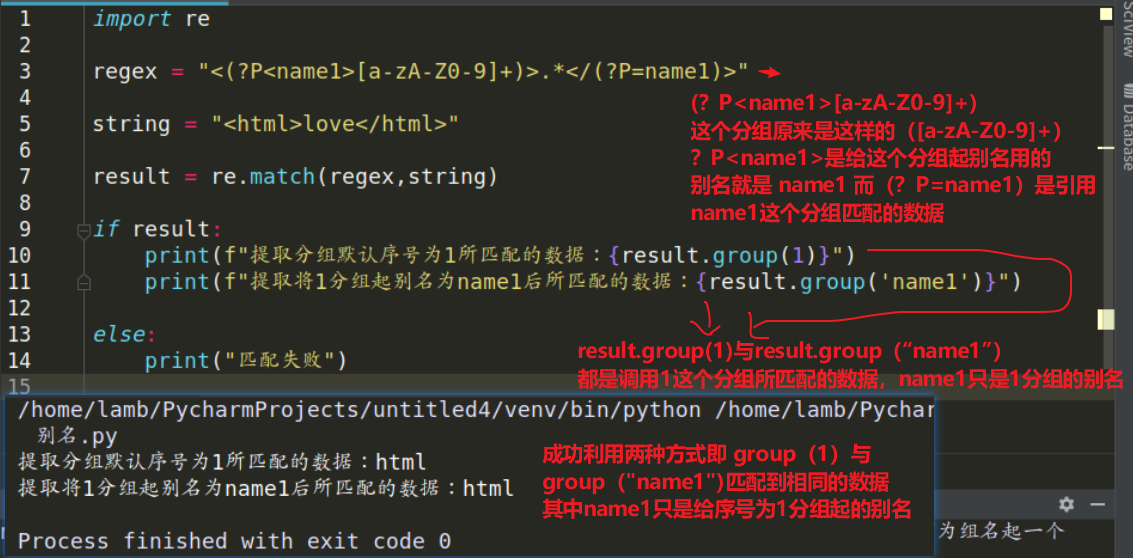
三:(?P=组别名)引用别名分组的数据
注意事项:
1:引用别名分组匹配的数据不要忘记加()
2:起别名语法的P是大写的P

若有收获,就点个赞吧
0 人点赞
