目标:
1:掌握第三方库 urllib.requset 的方法及功能
2:掌握第三方库 re 的方法及功能
一:urllib.request库
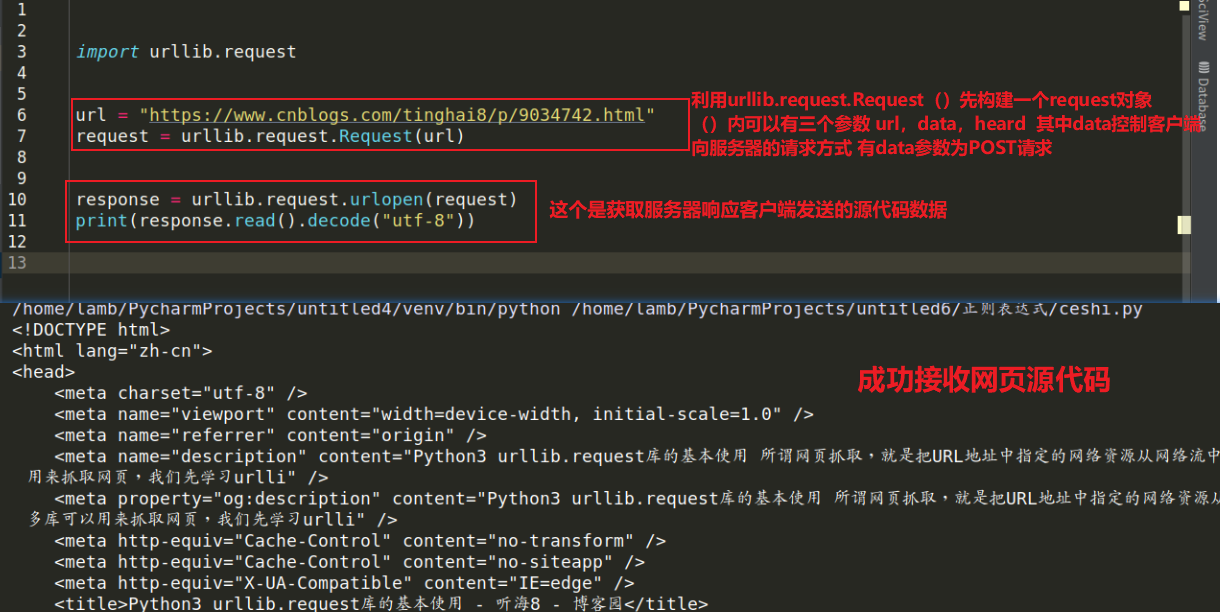
urlopen方法:response = urllib.request.urlopen(url)
功能: 配合 response 的read()方法获取url服务器向客户端(pycharm)发送的源代码
注意事项:
1:其中 response 不是接收的 url 服务器源代码,而是一个http类,需要利用read()方法获取网页源代码
2:response.read( )方法读取到的是网站源代码的二进制形式,需要用 decode(“字符集”)进行解码
Request方法:
1:利用Request方法先构建一个request对象,即 request = urllib.request.Request(url,data,headers)
2:将request对象传递到urlopen()方法内,即 respones = urllib.request.urlopen(requset)
功能:与urlopen的方法类似,获取网页源代码用,但是Request()可更改请求方式,请求方式默认为GET
注意事项:
1:request = urllib.request.Request(url,data,headers)请求方式为GET,data(默认为空)请求方式如果是POST,需要加上data参数,headers是一个字典,包含了需要发送的HTTP报头的键值对
2:根据注意事项1可以看出来 利用Request()先构建request对象在进行 urlopen(request)处理的这种方法可以更改客户端对服务端的请求方式!
二:re库
方法:result = re . match(pattern,string,flags)
功能: 在一个字符串内匹配指定的子字符串
**
参数详解:
pattern:正则模式 即正则表达式
string:待匹配的子字符串
falgs:匹配模式
注意事项:
1:待匹配字符串第一个字符不符合正则表达式直接返回None
2:match()方法只匹配第一个符合规则的子字符串
3:result = re.match(pattern,string,flags)返回的result 是一个类不是匹配的数据需要利用 result.group()方法才能获取匹配的数据
方法:result = re . search(pattern,string,flags)
功能: 在一个字符串内匹配指定的子字符串
参数详解:
pattern:正则模式 即正则表达式
string:待匹配的子字符串
falgs:匹配模式
注意事项:
1:待匹配字符串第一个字符不符合规则会继续向后查找,这是与match方法的不同
2:search()方法也只是查找第一个符合规则的子字符串
3:result = re.match(pattern,string,flags)返回的result 是一个类不是匹配的数据需要利用 result.group()方法才能获取匹配的数据
方法:result_list = re . findall(pattern,string,flags)
功能: 在字符串内查找所有**符合规则的子字符串并且返回一个列表,可直接打印
参数详解:
pattern:正则模式 即正则表达式
string:待匹配的子字符串
falgs:匹配模式
注意事项:
1:findall()方法是爬虫的常用方法
2:使用findall方法时,正则表达式内含有分组,则只匹配符合分组的那部分字符串保存至列表内,如果正则中有两个分组,则将符合这两个分组的字符串先保存至元组内在保存到列表中
参考文档:https://www.cnblogs.com/tinghai8/p/9034742.html

若有收获,就点个赞吧
0 人点赞
