事务与锁
事务
基础
- 事务强一致的可靠性模型ACID
- Atomicity原子性,一次事务中的操作要么全部成功,要么全部失败
- Consistency一致性,跨表、跨行、跨事务,数据库时钟保持一致状态
- Isolation隔离性,可见性,保护事务不会互相干扰,包含4个隔离级别
- Durability持久性,事务提交成功后,不会丢数据(如电源故障、系统崩溃等)
InnoDB
-
2个范围
可设置全局默认的隔离级别
-
4个级别
读未提交
- READ UNCOMMITTED
- 可以直接读到其他未提交的数据
- 可能产生脏读(DirtyRead,使用未被确认的数据)、幻读、不可重复读
- 很少使用
- 读已提交
- READ COMMITTED(RC)
- 读到的是其他事务已经提交的
- 可能同一个事务中读取到的数据不一致
- 每次查询都会设置和读取自己的新快照
- 仅支持基于行的bin-log
- 不可重复读(不加锁的情况下,其他事务UPDATE或DELETE会对查询结果有影响)
- 幻读(加锁后,不锁定间隙,其他事务可以INSERT,相同查询语句不同时间点执行RS不同,避免幻读需要锁定间隙)
- 可能产生幻读、不可重复读
- 可重复读
- REPEATABLE READ(RR)
- 反复读,每次读到的都一样
- MySQL默认的隔离级别
- 使用事务第一次读取时创建的快照
- 可能出现幻读,需要加锁
可串行化
撤销日志保证事务的原子性
- 记录事务回滚时所需要的操作(INSERT对应DELETE的undoLog,UPDATE也会记录相反的undoLog)
- 用处
- 事务回滚
- 一致性读
- 崩溃恢复
保存位置
重做日志保证事务的持久性,防止事务提交后数据未刷新到磁盘就掉电或崩溃
- 记录事务对数据页做了哪些修改
- 提升性能
- WAL(WriteAheadLogging)
- 先写日志,再写磁盘
- 日志文件
- ib_logfile0
- ib_logfile1
- 日志缓冲
- innodb_log_buffer_size
强刷
多版本并发控制
- 使InnoDB支持一致性读:RC和RR
- 查询不再阻塞,无需等待被其他事务持有的锁,增加并发性能
- 每行数据都存在一个版本号,每次更新时都更新该版本
- 实现机制

锁
表级锁
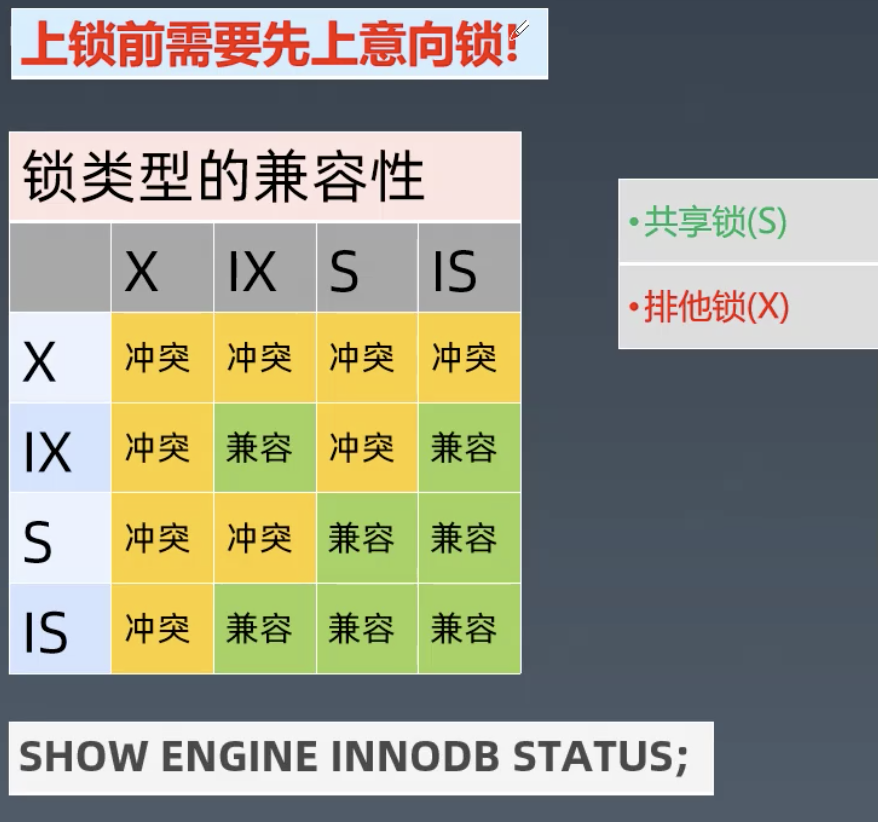
- 意向锁:表明事务稍后要进行哪种类型的锁定
- 意向共享锁(IS IntentionShared):打算在某些行上设置共享锁
- 意向排他锁(IX IntentionExclusive):打算对某些行设置排他锁
- Insert意向锁:Insert操作设置的间隙锁
- 其他
- 自增锁(AutoIn)
- LOCK TABLES
- DDL
- Mysqldump
- 上锁前需要先上意向锁
行级锁(InnoDB)
- 记录锁Record
- 始终锁定索引记录,注意隐藏的聚簇索引
- 间隙锁Gap , update/delete时尽量不要用范围,避免间隙锁
- 临键锁NextKey
- 记录锁和间隙锁的组合
- 可锁定表中不存在的记录
谓词锁Predicat
阻塞与互相等待
- 增删改、锁定读
- 死锁检测与自动回滚
- 锁粒度与程序设计
- 解决死锁
显示指定表tableName的字段名 show columns from tableName;
关闭事务的自动提交 set autocommit=0;
for update加锁 select * from tableName where id =10 for update;
查看引擎状态 show engine innodb status\G;
回滚 rollback;
DB与SQL优化
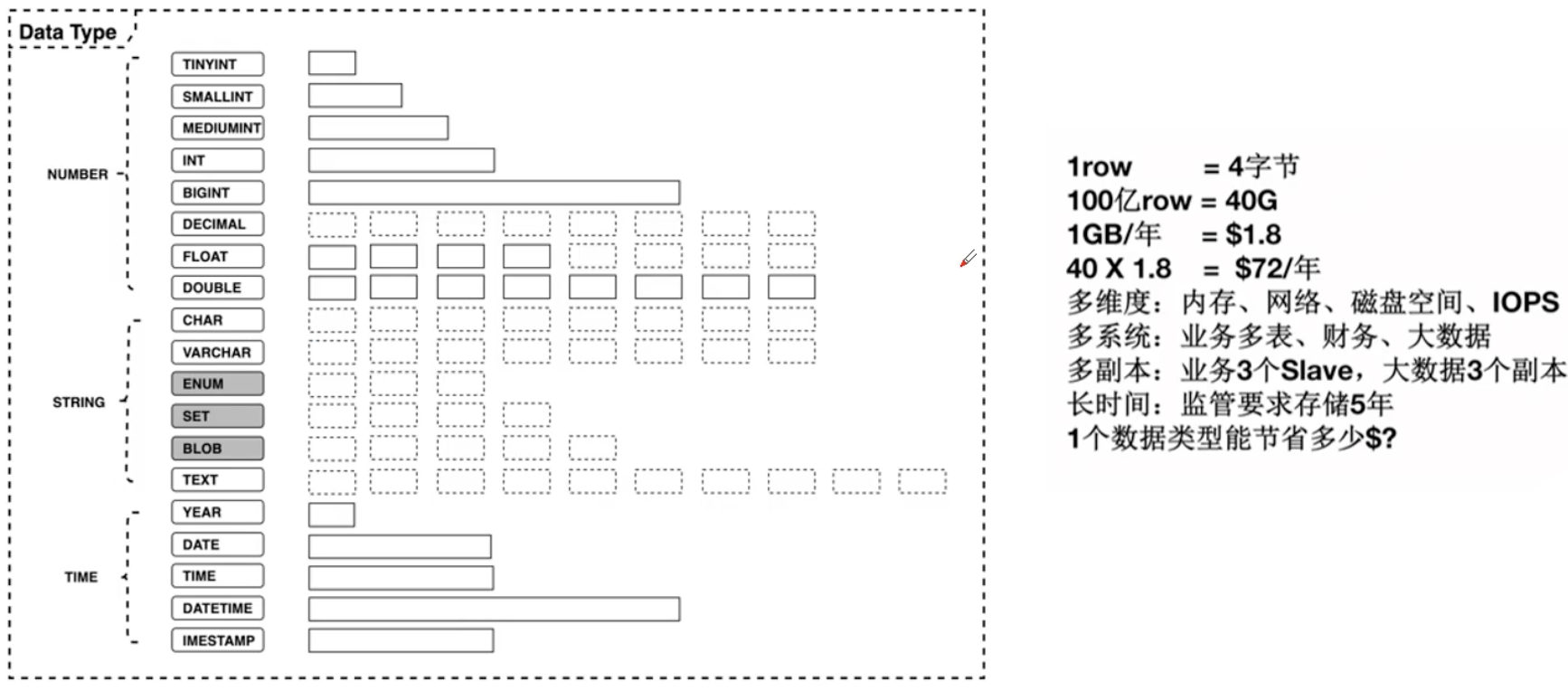
数据类型选择
存储引擎选择

DBA规范
常见坑
- MySQL数据类型隐式转换可能引发错误、不走索引等问题,应避免数据类型的隐式转换
- 运行时间长了后查询变慢,需要看慢查询日志、看监控指标
如果慢查询中涉及要加索引就需要Alter table NAME add index INDEXNAME(column_list);
索引
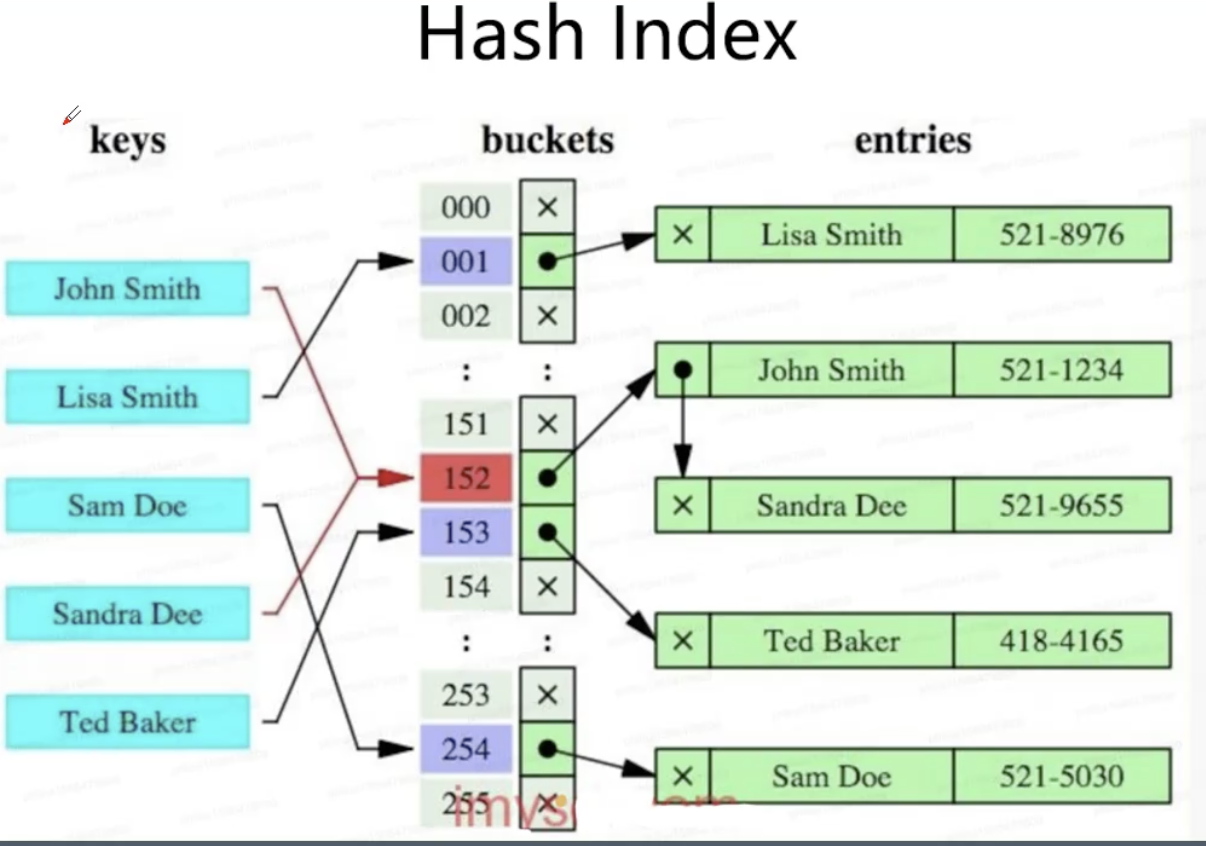
Hash索引
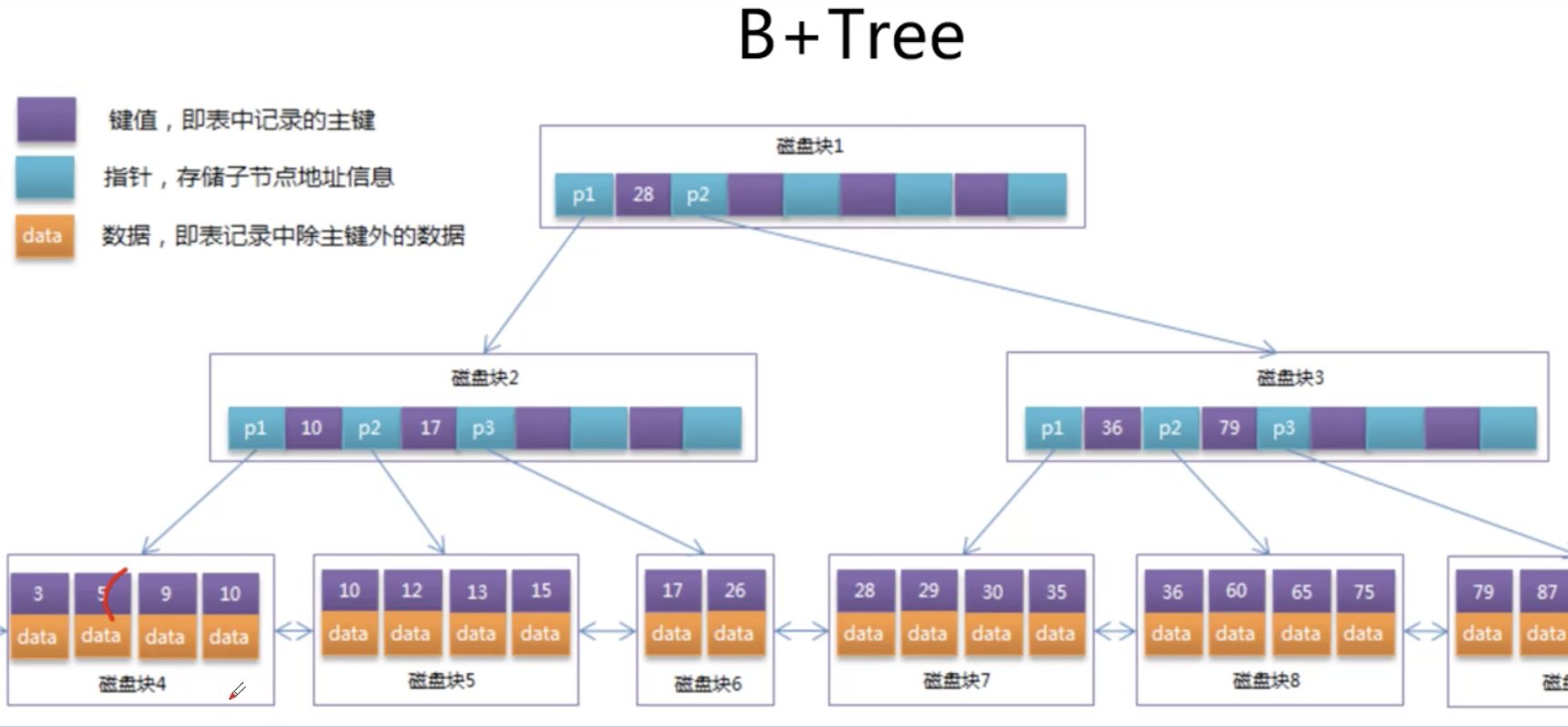
B-Tree索引
B-Tree所有节点都带数据
- B+Tree只有叶子节点带数据

B+Tree索引
- B+Tree只有叶子节点带数据
- 主键不宜太大,太大一个页上可放的数量变少,层级可能就高了
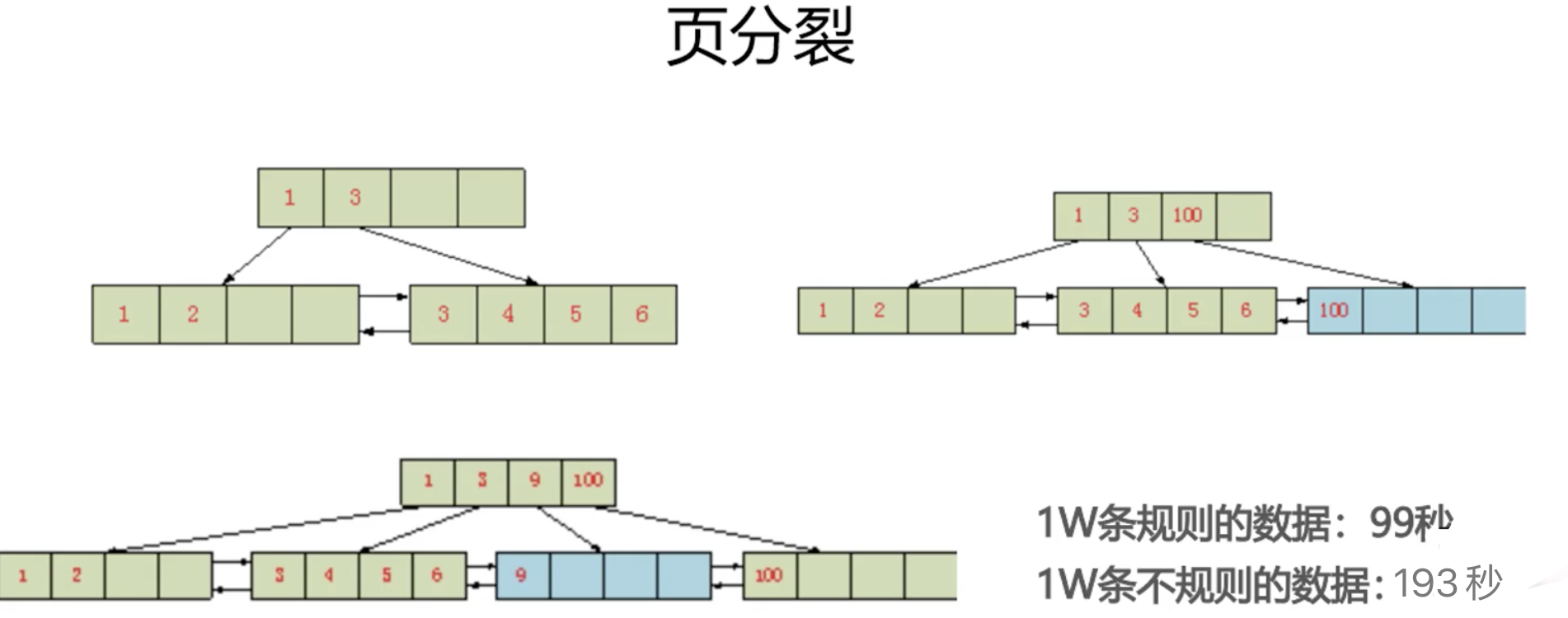
页分裂
- 需要主键是单调自增的,尽量避免向之前的页里增加数据
- 之前页里增加数据需要开辟新空间、移动老数据,性能开销比直接向后添加大
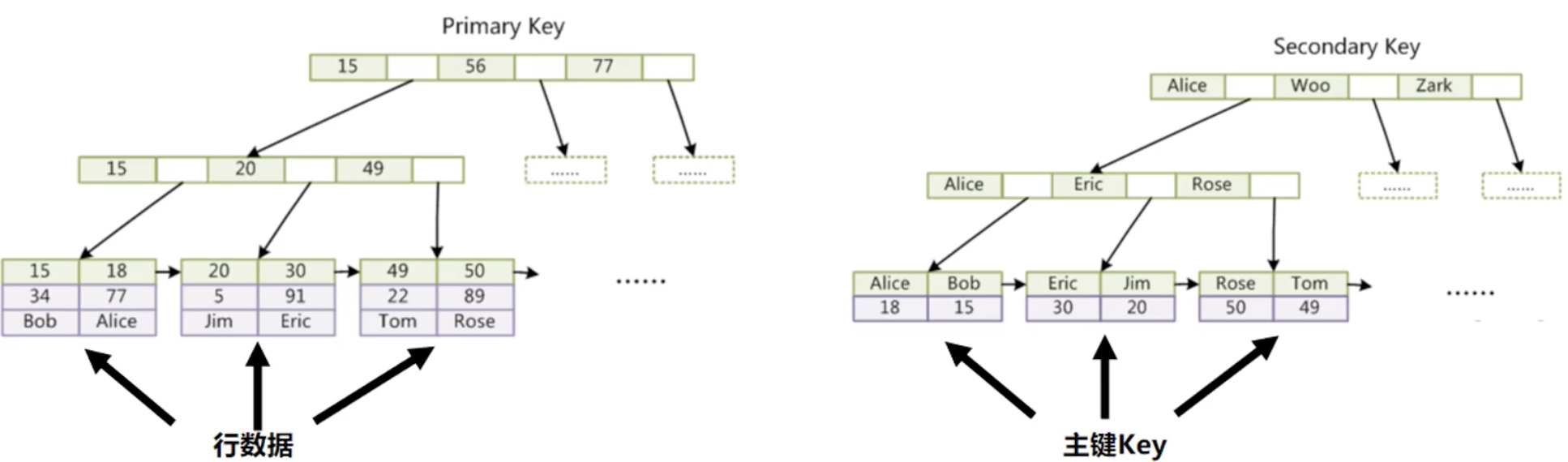
聚集索引和二级索引
- 主键的索引是聚集索引(PrimaryKey),叶子节点上有数据
- 非主键索引都是二级索引(SecondaryKey),叶子节点上只有主键,如果需要其他数据还需要回表查询
字段选择性
- 最左原则
- 某个字段值的重复程度,称为字段的选择性
-
冗余索引
只给关键的字段加索引
如果所有的组合都加索引也会让系统变慢,更新数据时需要更新所有的索引,反而变慢
主键索引要求
尽量单调自增
-
修改表结构
危害
- 锁表
- 索引重建
- 抢占资源
- 主从延时
解决方案
大批量写入的优化
- 用PrepareStatement中的addBatch,推荐,这个比下面的values减少了SQL的解析
- 用values(),(),…多值写入,这个如果值很多,对中间件的SQL解析是个挑战
- 如果没有应用程序处理,推荐使用loadData直接导入数据文件
- 大批量写入时可以先把索引和约束都去掉,数据加入完毕后再添加索引和约束(Mysqldump时也是这样处理)
- 数据更新
- 注意数据的更新范围,范围尽量小,尽量精确到主键
- 注意GapLock的问题
- 模糊查询
- 索引只支持前缀匹配,即keyword%
- 如果前面也有%则无法使用索引
- 如果需要全文检索、模糊搜索推荐使用ES等技术实现,mysql这边只做关键的结构数据的查询支持
- 如果是热点数据,读写比很高的,直接存储在Redis
- 连接查询
- 注意驱动表的选择,要选择小表做驱动表
- 避免笛卡尔积
- 索引失效
- NULL、not、not in、函数convert等都会造成索引失效
- 减少使用or,可以用union以及前面的like
- 大数据量的情况下,放弃所有条件组合都走索引的幻想,直接使用全文检索的ES等
- 必要时可以使用force index来强制查询走某个索引,避免数据库引擎选择了其他索引
查询SQL到底怎么设计
自增auto_increment
- sequence(全库级别的)
- 模拟seq
- mysql建立一个表,里面存放数据段
- 客户端获取时select for update加锁,拿到后在应用程序中自增,增到约定的步长后再去获取
- UUID
- 算法变慢
- 长度略长
- 不递增
- 但无中心点
- 时间戳+随机数
snowflake
避免使用分页插件 mysqlPlus
- select count(*) 带来的性能问题,自己实现时要重新count
- 大数据量级别的分页问题,limit 1000000,20 引擎跳100000也会带来性能问题,自己实现可能会使用反序
- 分页
- count
- pageSize
- pageNum
需求上出发
select for update 悲观锁
- update XXX where value=oldValue 也可以采用乐观锁

若有收获,就点个赞吧
0 人点赞
