为什么做数据库拆分
- 单库单表承载的容量有限
- 索引树层级增加,IO性能下降
- 服务的无状态性可任意扩展导致压力都落到数据库,单一的数据库节点或简单的主从可用性不高
- 大库单库的不足
- 无法执行DDL,比如添加一列、增加索引、都会导致长时间的数据库无响应
- 无法备份,备份会锁表,量大了也无法执行
- 影响稳定性和性能,主从同步延迟变高,不可控
从读写分离到分库分表
软件架构扩展模型

数据库扩展模型

规范模型
管理模型
- 架构设计:TOGAF
- 项目管理:PMP
-
数仓模型
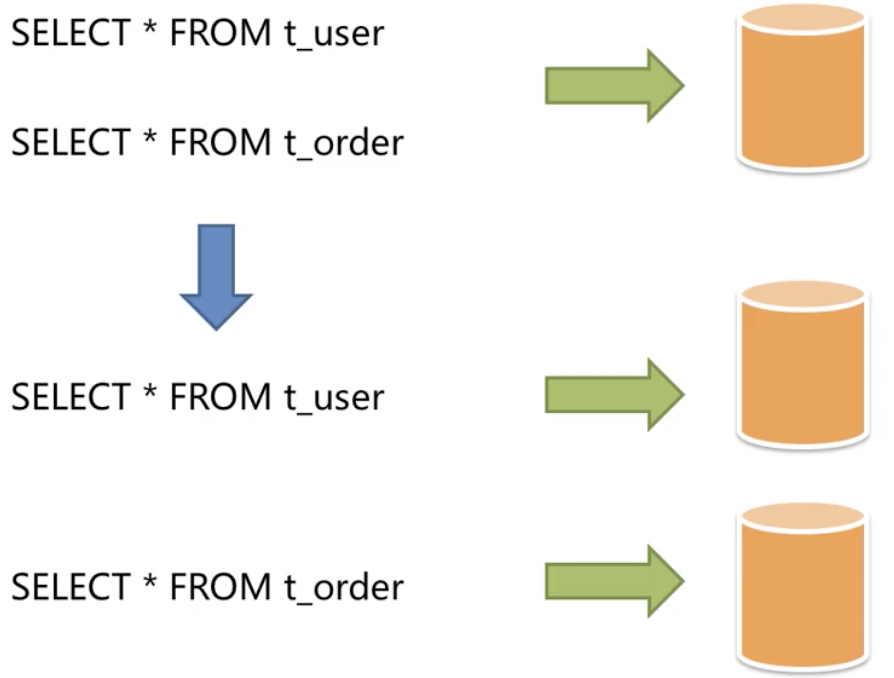
垂直拆分
淘宝拆分
优缺点
优点
- 单库单表变小,便于管理和维护
- 对性能和容量有提升
- 改造后,系统和数据复杂度降低
- 可作为微服务改造的基础
缺点
梳理清楚拆分范围和影响范围
- 检查评估和重构影响到的服务
- 准备新的数据库集群复制数据
- 修改系统配置并发布新版上线

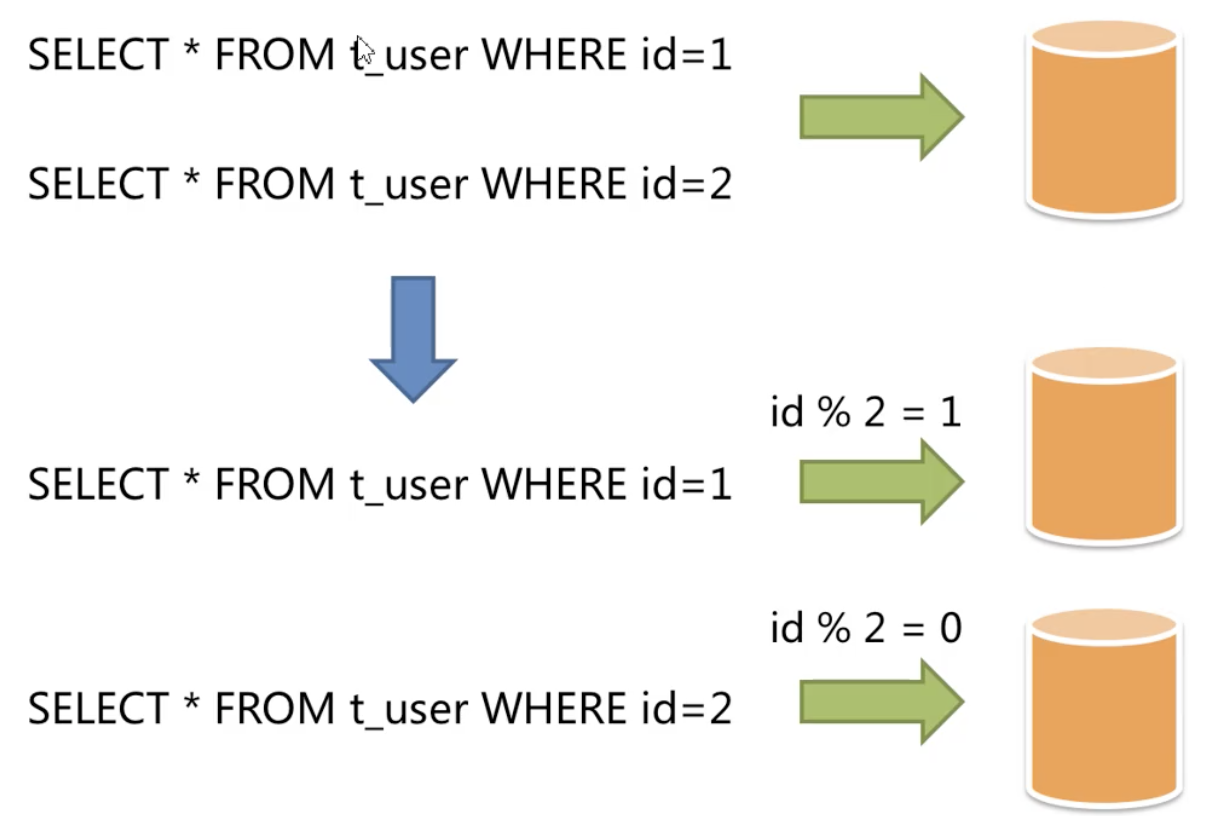
水平拆分
分类
- 分库
- 分表
- 分库分表
优缺点
- 优点
- 解决容量问题
- 比垂直拆分对系统影响小
- 部分提升性能和稳定性
缺点
直接对数据进行分片,有分库、分表两种方式,都是降低单节点容量,不改变数据本身结构,也就不会对业务系统做特别大的改动,甚至可以基于一些中间件做到透明
常用模式
一般情况下,如果数据库本身的读写压力比较大,磁盘IO是瓶颈,则优先考虑分库,并行提升IO性能
- 相反情况下,考虑分表,降低单表的数据量,从而减少单表操作的时间
- 有些中间件只支持分库,不支持分表,DBA也建议分库,不建议分表
原因
热数据:查询比较频繁的,需要放到数据库和内存
- 温数据:放到数据库,提供正常的查询操作
- 冷数据:归档到磁盘,用户需要提交工单或邮件来查询,导出后发回
-
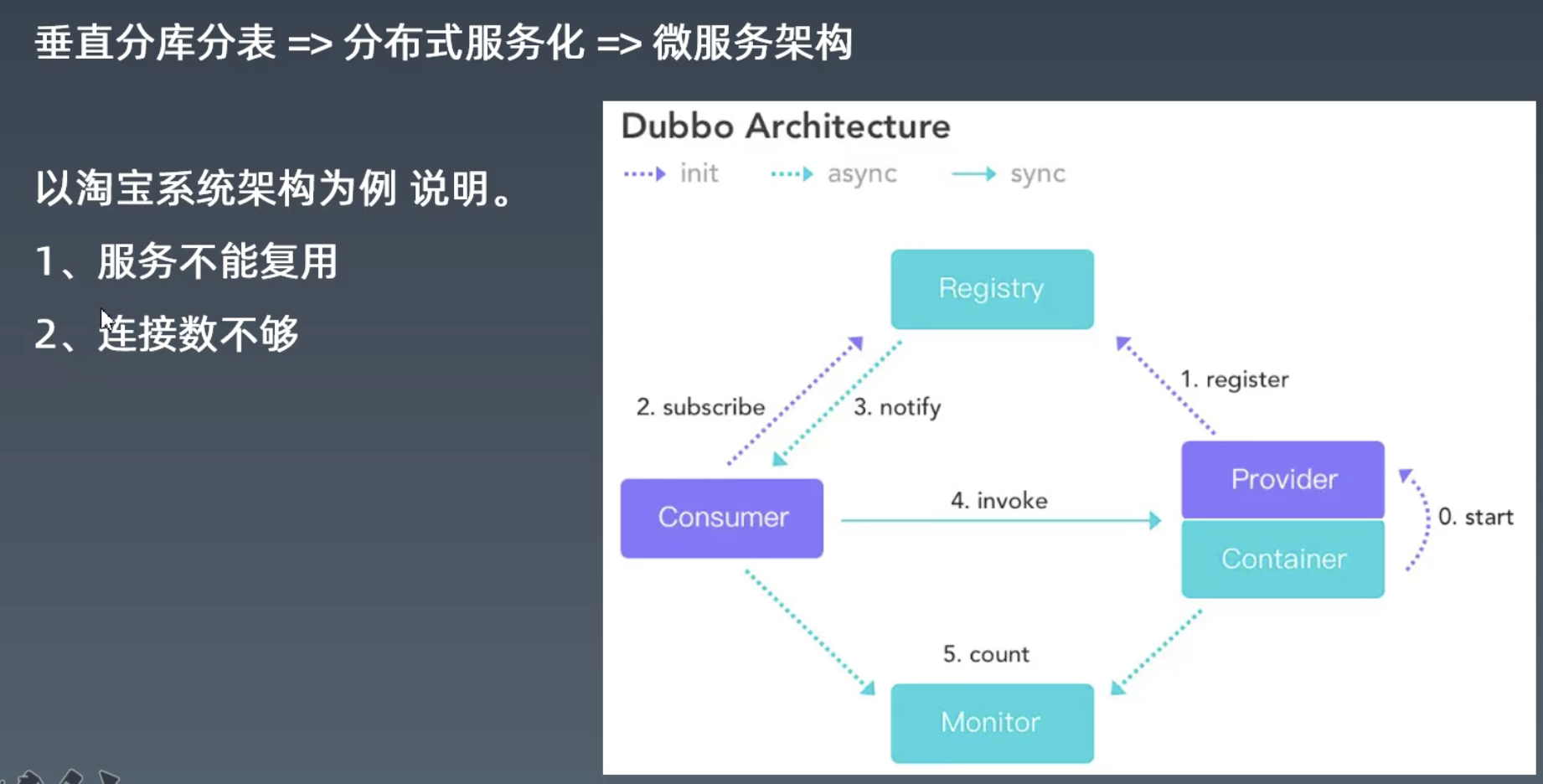
Java框架
TDDL
-
中间件
ApacheShardingSphere-Proxy
- MyCat
优势
OceanBase
-
数据网格
-
如何做数据迁移
最重要也最容易出故障的一环
设计新系统容易,但是我们处理的都是老系统和历史诗句
- 平滑的迁移旧数据到新的数据库和系统
-
方式1:全量
全量数据导出和导入
- 业务系统停机
- 数据库迁移,导入新库时可以先把索引、约束等去除,只导入数据,然后再加索引和约束,提高效率
- 校验一致性(库、表、记录行)
- 然后业务系统升级,接入新数据库
- 直接复制的话,可以dump后全量导入
- 如果是异构数据,需要用程序来处理
- 优点:简单
-
方式2:全量+增量
依赖于数据本身的时间戳
- 先同步数据到最近的某个时间戳
- 然后在发布升级时停机维护
- 再同步最后一段事件(通常是一天)的变化数据
- 最后升级业务系统,接入新数据库
-
方式3:binlog+全量+增量(推荐)
通过主库或从库的binlog来解析和重新构造数据,利用主从复制实现扩展迁移
- 一般需要中间件工具的支持
- 可以实现多线程,断点续传,全量历史和增量数据同步
继而可以做到
支持数据全量和增量同步
- 支持断点续传和多线程数据同步
- 支持数据库异构复制和动态扩容
- 具有UI界面,可视化配置

若有收获,就点个赞吧
0 人点赞
