基本功能
安装
- 源码编译安装
- brew/apt/yum安装
docker启动
默认有(0-15)16个库,默认使用的是0库
- select n; 切换到n库
-
性能测试
root@8b1beccfab8c:/etc# redis-benchmark -n 100000 -c 32 -t SET,GET,INCR,HSET,LPUSH,MSET -qroot@8b1beccfab8c:/etc# redis-benchmark -n 100000 -c 32
5种常用数据结构
string
在redis中是二进制安全的,意味着该类型可以接受任何格式的数据(int、str、byte[]、json字符串、jpg数据等)
- 字符串类型的value最多可容纳的数据长度是512M
- 字符串append操作
- 默认append是多次的,所以第一次append会预留内存,减少实时分配内存的消耗
- 如果需要少量的更改操作可以直接使用 set key newValue 替换旧值
- 整数共享
- 为了节省内存,redis会对整数共享起来,如果有多个key的值都是同一个整数,系统内部是共享的
- 如果能使用整数表示就尽量使用整数
- 如果限制了redis内存和LRU缓存淘汰策略,会关闭整数共享特性
- 整数精度问题
- 通常能保证16位的精度
- 超过的可能丢失精度 ```bash set get getset #获取旧值并设置新值 del exists append
incr decr incrby decrby
<a name="CfdTg"></a>### hash- 具有String key 和 String value的 Map容器- 适合于存储对象的信息```bashhsethgethmsethmgethgetallhdelhincrbyhexistshlenhkeyshvals
list
- 按插入顺序排序的字符串链表
- 如果键不存在则创建一个新的链表,如果所有元素均被移除则该键也被删除 ```bash lpush lpop
rpush rpop
lrange
<a name="KtxOD"></a>
### set
- 不重复的list
- 没有排序
```bash
sadd
srem
smembers
sismember
sdiff
sinter
sunion
sortedSet
- 字符串的集合
- 不允许重复
- 每一个成员都有一个分数score与之关联,通过分数为成员从小到大排序,分数可以重复 ```bash zadd key score member score2 member2 … zscore key member : 返回member的分数 zcard key: 返回成员数量 zrem key member1 … zrange key start end [withScores]: 获取集合中脚注为start-end的成员,withScores表明返回的成员包含其分数 zrevrange key start stop [withScores]: 按分数从大到小的顺序返回索引start到end之间的所有元素 zremrangebyrank key start stop: 按照排名范围删除元素
<a name="uz4wK"></a>
## 3种高级数据结构
<a name="wmHUC"></a>
### bitmaps
- 不是一个真实的数据结构
- 是string类型上的一组面向bit操作的集合的封装
- 因为string是二进制安全的blob,最大长度是512M,所以bitmaps能最大设置2^32个不同的bit
```bash
setbit
getbit
bitop
bitcount
bitpos
hyperloglogs
根据概率估计度量
pfadd pfcount pfmergegeo
存储经纬度信息并进行相关计算
geoadd geohash geopos geodist georadius georadiusbymember线程模型
作为一个redis服务,需要多个线程配合完成工作
通用数据缓存(string、int、list、map等)
- 实时热数据(最热500条等)
-
业务数据处理
非严格一致性要求的数据(评论、点击等)
- 业务数据去重(订单处理的幂等校验)
-
全局一致计数
全局流控计数
- 秒杀的库存计算
- 抢红包
-
高效统计计数
id去重,记录访问ip等
-
发布订阅与Stream
PUB/SUB模拟队列
redis Stream是5.0版本新增加的数据结构,主要用于MQ
分布式锁
分布式锁特点
释放锁-lua脚本(也保证redis的原子性,因为redis执行lua脚本时也单线程执行)
if redis.call(“get”, KEYS[1]) == ARGV[1] then return redis.call(“del”,KEYS[1]) else return 0 end
<a name="kkvsG"></a>
# Redis的Java客户端
<a name="EzlWY"></a>
## Jedis
- 官方客户端,类似于JDBC,对redis命令的封装
- 基于BIO,线程不安全,需要配置连接池管理连接
- 不推荐使用
<a name="CmphE"></a>
## Lettuce
- 主流推荐的驱动,基于NettyNIO,API线程安全,推荐使用
<a name="0yo4R"></a>
## Redission
- 基于NettyNIO,API线程安全
- 丰富的分布式功能特性(分布式版本、分布式基本数据类型、锁等)
<a name="lTuJA"></a>
# 与Spring整合
<a name="ZmRPO"></a>
## SpringDataRedis
- 核心是RedisTemplate(可配置基于Jedis、Lettuce、Redission)
- 使用方式类似于MongoDBTemplate,JDBCTemplate或JPA
- 封装了基本的Redis操作
<a name="VWDsQ"></a>
## SpringBoot集成
- 引入spring-boot-starter-data-redis
- 配置spring redis
<a name="eRkts"></a>
## SpringCache集成
- 默认使用全局CacheManager自动集成
- 使用ConcurrentHashMap或ehcache时,不需要考虑序列化问题
- redis默认使用java的对象序列化,对象需要实现Serializable,也可自定义配置,修改为其他序列化方式
<a name="4jmX3"></a>
# Redis高级功能
<a name="TNLmr"></a>
## Lua
- redis内置了lua的JIT引擎,可以直接执行lua脚本
- 也可以预编译lua脚本,运行时直接执行其签名即可
```bash
# eval script numkeys key [key ...] arg [arg ...]
eval "return 'hello world'" 0
eval "redis.call('set',KEYS[1],ARGV[1])" 1 lua-key lua-value
# SCRIPT LOAD 代码片段 返回其SHA1 shastring
# evalsha sha1 numkeys key [key ...] arg [arg ...]
数据备份和恢复
RDB
save
bgsave
# 默认保存数据到数据目录的dump.rdb文件
# 服务启动时也会默认加载此文件来初始化数据
# 查看数据目录可执行如下命令
config get dir
AOF
appendfilename "append.aof"
# appendfsync always
# appendfsync everysec
# appendfsync no
事务
# 事务命令
## 开启事务
multi
## 执行事务
exec
## 撤销事务
discard
# 乐观锁
watch 实现乐观锁,watch一个key,发生变化则事务失败
管道pipline
- 因为redis操作大多是小命令且频繁的,CS交互的消耗可能远大于命令真正执行的消耗
所以需要合并操作批量处理,且不阻塞前序命令的技术
(echo -en "PING\r\nSET pkey redis\r\nGET pkey\r\nINCR visitor\r\nINCR visitor\r\nINCR visitor\r\n";sleep 1) | nc localhost 6379实践经验
CPU
不要阻塞
- 谨慎使用范围操作
- SLOWLOG GET 10 # 默认只保留最后的128条
-
内存
推荐最大内存10G-20G
- 配置hash-max-ziplist-value 64
- 配置zset-max-ziplist-value 64
官方内存优化链接 👉 https://redis.io/topics/memory-optimization
业务
尽量相互独立,不混用
- 规范环境和key的管理
- 做好容量规划和监控(使用量、连接数、命中率、读写比)
尽量只使用默认的 0 库,因为很多功能都不支持后面的15个库的配置,如redis cluster
集群与高可用
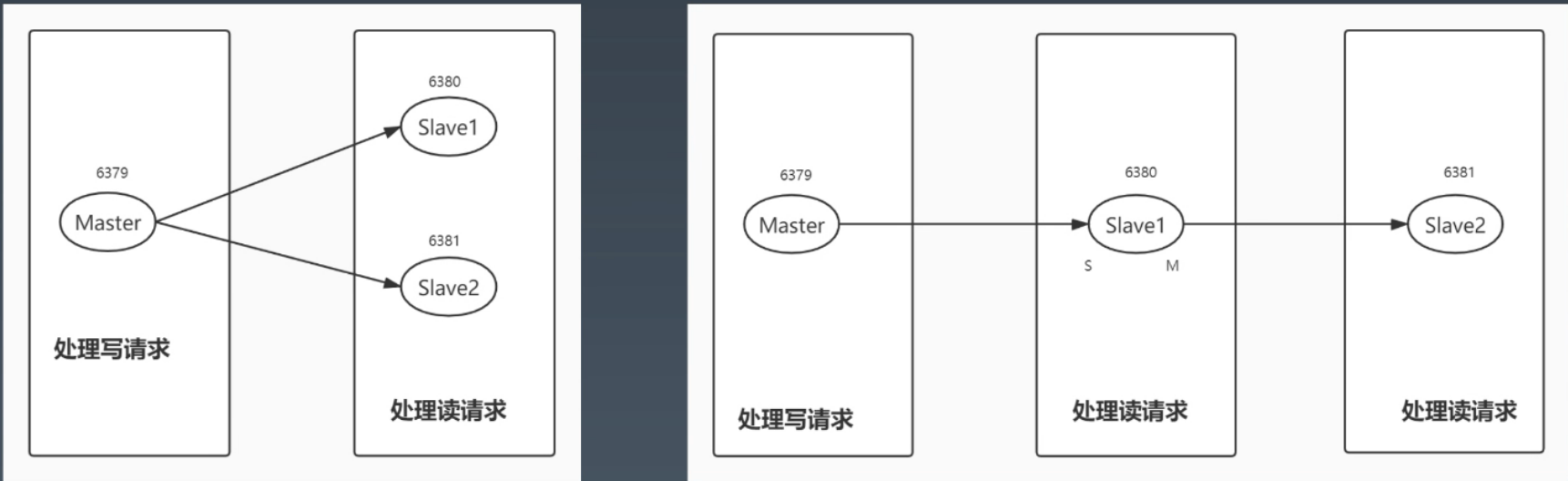
主从复制:从单节点到多节点
从节点执行 SLAVEOF IP PORT 可以把自己变为从库,但推荐写在配置文件中,这样服务重启时可以自动配置
- 这时的从节点会异步复制,并且是只读状态
- 两种拓扑
- SLAVEOF NO ONE 断开主从关系
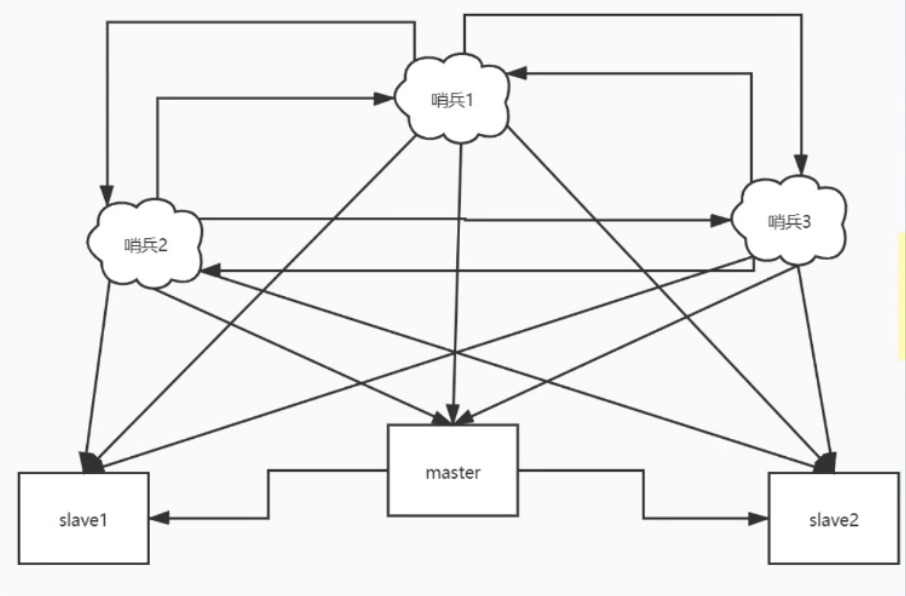
Sentinel:走向高可用
- sentinel 基于raft协议监控主从节点状态并自动切换
- 两种启动方式
- redis-sentinel sentinel.conf #其实redis-sentinel命令就是redis-server的软连接
- redis-server sentinel.conf —sentinel
- 不需要配置从节点,不需要配置其他sentinel信息,会自动读取
Sentinel服务一般配置多个,只要有符合配置的(默认半数以上)的节点能提供服务就能保证集群可用
# sentinel.conf # 最后的2是最少需要多少个节点的确认才能认为节点下线 sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 60000 sentinel failover-timeout mymaster 180000 sentinel parallel-syncs mymaster 1RedisCluster:走向分片
主从复制从容量角度来说还是单机
- 分片设计原理
- RedisCluster通过一致性hash算法,将数据分散到多个服务器节点
- 先设计16384个hash槽,分配到多个节点
- 当需要在集群中读取一个key时,redis客户端先对key使用crc16算法计算一个数值,然后对16384取模,这样每个key都对应一个编号在0-16383之间的hash槽
- 然后在此槽对应的节点上进行操作
- 配置
- cluster-enabled yes
注意
基于NettyNIO
- API线程安全
- 大量丰富的分布式功能特性
- JUC线程安全集合
- 工具分布式版本
- 分布式基本数据类型和锁
代码场景
Redis演化出来Redisson,Redisson演化出来Hazelcast
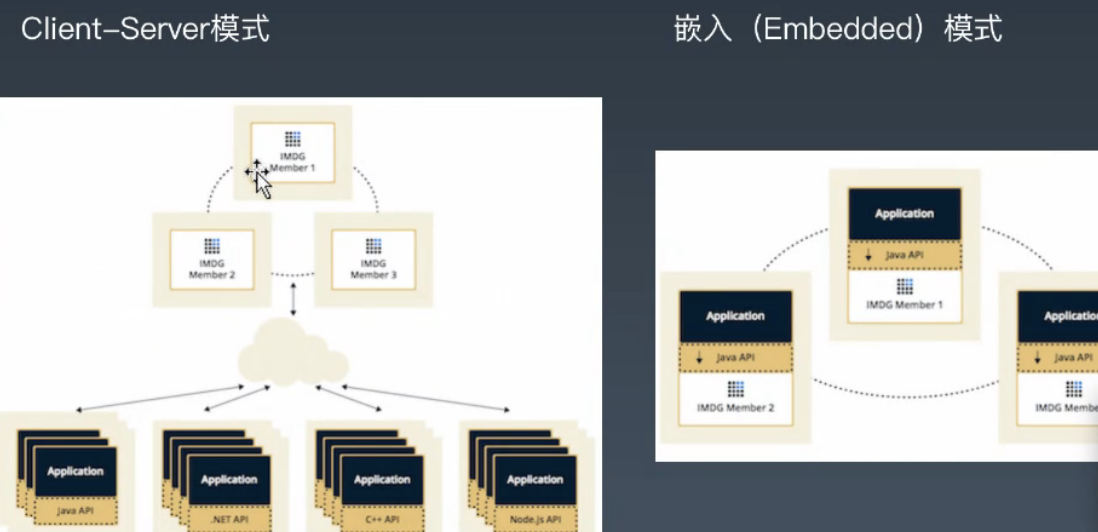
- Hazelcast IMDG(InMemoryDataGrid)是一个标准的内存网格系统
基本特征
Client-Server模式
- Embedded模式
数据分区

若有收获,就点个赞吧
0 人点赞
