本文翻译自 https://habr.com/en/company/postgrespro/blog/442546/,已经得作者同意。
在第一篇文章中,我们已经提到访问方法必须提供关于它们自己的信息。现在,让我们来看看访问方法接口的结构。
属性
访问方法的所有属性都存储在 pg_am 系统表中( am 表示访问方法 access method)。我们可以从该表中获取当前支持的访问方法:
postgres=# select amname from pg_am;amname--------btreehashgistginspgistbrin(6 rows)
尽管顺序扫描也是一种访问方法,但由于历史原因,它不在此列。
译者注:在 PostgreSQL 12 中已经支持了表的访问方法,而不仅仅只有索引的访问方法。
在 PostgreSQL 9.5 以及更低的版本,每个属性都用 pg_am 表中的一个字段表示。从 9.6 开始,属性通过特定函数查询,且被划分为几层:
- 访问方法属性 ——
pg_indexam_has_property - 指定索引的属性——
pg_index_has_property - 索引中某个列的属性——
pg_index_column_has_property
为长远打算,将访问方法层和索引层分开:从现在起,基于一种访问方法的所有索引都将有相同的属性。
以下是访问方法的五个属性(以 btree 为例):
postgres=# select a.amname, p.name, pg_indexam_has_property(a.oid,p.name)from pg_am a,unnest(array['can_order','can_unique','can_multi_col','can_exclude','can_include']) p(name)where a.amname = 'btree'order by a.amname;amname | name | pg_indexam_has_property--------+---------------+-------------------------btree | can_order | tbtree | can_unique | tbtree | can_multi_col | tbtree | can_exclude | tbtree | can_include | t(5 rows)
- can_order.
访问方法允许我们在创建索引时指定值的排列顺序(目前只有 btree 支持)。
- can_unique.
支持唯一约束和主键(只应用于 btree)。
- can_multi_col.
可以在多列上创建索引。
- can_exclude.
支持排除约束 EXCLUDE。
- can_include.
创建索引时是否支持 INCLUDE 子句。
译者注:原文以 PostgreSQL 9.6 为例,仅有四个访问方法属性,本文以最新的 PostgreSQL 12 为例,新增了一个 can_include 属性,可以参考官方文档 https://www.postgresql.org/docs/current/functions-info.html。
以下属性与索引有关(让我们以一个现存的索引为例):
postgres=# select p.name, pg_index_has_property('t_a_idx'::regclass,p.name)from unnest(array['clusterable','index_scan','bitmap_scan','backward_scan']) p(name);name | pg_index_has_property---------------+-----------------------clusterable | tindex_scan | tbitmap_scan | tbackward_scan | t(4 rows)
- clusterable.
根据索引重新对数据行排序的可能性(即是否可以对该索引使用 CLUSTER 命令)
- index_scan
支持索引扫描。这个属性看起来有些奇怪,但并非所有的索引都能够逐个返回 TID,许多、、一些索引会一次性返回所有 TID,只支持 bitmap 扫描。
- bitmap_scan
支持 bitmap 扫描。
- backward_scan
结果可以按照创建索引时指定的相反的顺序返回。
最后,以下是列属性:
postgres=# select p.name,pg_index_column_has_property('t_a_idx'::regclass,1,p.name)from unnest(array['asc','desc','nulls_first','nulls_last','orderable','distance_orderable','returnable','search_array','search_nulls']) p(name);name | pg_index_column_has_property--------------------+------------------------------asc | tdesc | fnulls_first | fnulls_last | torderable | tdistance_orderable | freturnable | tsearch_array | tsearch_nulls | t(9 rows)
- asc, desc, nulls_first, nulls_last, orderable.
这些属性与列的排序相关(我们将在介绍 btree 索引的时候具体讨论)。
- distance_orderable.
列是否可以由 “distance” 运算符按顺序扫描,比如 ORDER BY col <-> constant 。
- returnable.
列的值是否可以由 Index-only Scan 返回。
- search_array.
列是否支持 col=ANY(array) 检索。
- search_nulls.
列是否支持 IS NULL 和 IS NOT NULL 检索。
我们已经详细讨论了一些属性,某些属性特定于某些访问方法,我们将在讨论特定方法时介绍这些属性。
译者注:以上属性均可以在 https://www.postgresql.org/docs/current/functions-info.html 找到介绍。
运算符类和族(Operator classes and families)
除了访问方法的属性外,还需要知道访问方法接收哪些数据类型和运算符。为此,PostgreSQL 引入了运算符类(operator class)和运算符族(operator family)的概念。
运算符类包含索引操作特定数据类型的最小运算符集(可能还有辅助函数)。
运算符类包含在某个运算符族中。此外,一个公共运算符族可以包含多个有相同语义的运算符类。例如, integer_ops 族包括 bigint ,integer ,smallint 类型的 int8_ops , int4_ops 和 int2_ops 类,它们虽然类型大小不同,但含义相同:
postgres=# select opfname, opcname, opcintype::regtypefrom pg_opclass opc, pg_opfamily opfwhere opf.opfname = 'integer_ops'and opc.opcfamily = opf.oidand opf.opfmethod = (select oid from pg_am where amname = 'btree');opfname | opcname | opcintype-------------+----------+-----------integer_ops | int2_ops | smallintinteger_ops | int4_ops | integerinteger_ops | int8_ops | bigint(3 rows)
另一个例子: datatime_ops 族包括操作日期(包括有时间和没有时间的日期)的运算符类。
postgres=# select opfname, opcname, opcintype::regtypefrom pg_opclass opc, pg_opfamily opfwhere opf.opfname = 'datetime_ops'and opc.opcfamily = opf.oidand opf.opfmethod = (select oid from pg_am where amname = 'btree');opfname | opcname | opcintype--------------+-----------------+-----------------------------datetime_ops | date_ops | datedatetime_ops | timestamptz_ops | timestamp with time zonedatetime_ops | timestamp_ops | timestamp without time zone(3 rows)
运算符族还可以包含其他运算符以比较不同类型的值。按运算符族进行分组使计划器可以对包含不同数据类型的谓词使用索引。运算符族还可以包含一些辅助函数。
大多数情况下,我们不需要知道任何关于运算符族和类的信息。通常,我们创建一个索引会默认使用特定的运算符类。
但是,我们可以显式指定运算符类。以下是一个需要显式指定运算符类的例子:如果一个数据库的排序规则不是 C,则常规索引不支持 LIKE 操作:
postgres=# show lc_collate;lc_collate-------------en_US.UTF-8(1 row)postgres=# explain (costs off) select * from t where b like 'A%';QUERY PLAN-----------------------------Seq Scan on tFilter: (b ~~ 'A%'::text)(2 rows)
我们可以在创建索引时指定 text_pattern_ops 运算符类来克服这个限制(注意计划中的条件是如何变化的):
postgres=# create index on t(b text_pattern_ops);postgres=# explain (costs off) select * from t where b like 'A%';QUERY PLAN----------------------------------------------------------------Bitmap Heap Scan on tFilter: (b ~~ 'A%'::text)-> Bitmap Index Scan on t_b_idx1Index Cond: ((b ~>=~ 'A'::text) AND (b ~<~ 'B'::text))(4 rows)
系统目录(System catalog)
本文的最后,系统目录中与运算符类和运算符族直接相关的表的简化图如下:
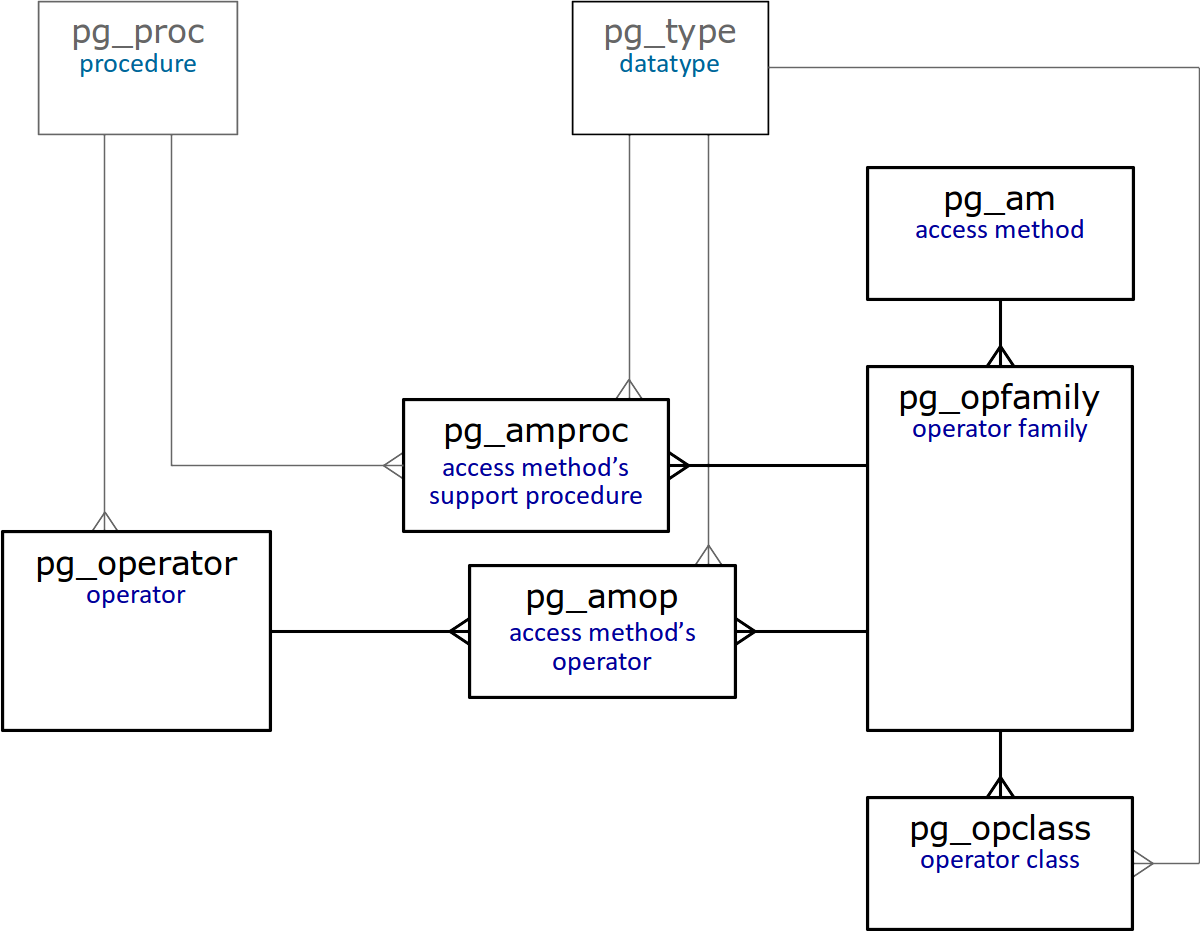
以上表的详细介绍可以参考官方文档。
系统目录使我们能够在不翻阅任何文档的情况下找到很多问题的答案。例如,某个访问方法可以操作那些数据类型?
postgres=# select opcname, opcintype::regtypefrom pg_opclasswhere opcmethod = (select oid from pg_am where amname = 'btree')order by opcintype::regtype::text;opcname | opcintype---------------------+-----------------------------abstime_ops | abstimearray_ops | anyarrayenum_ops | anyenum...
某个运算符族包含哪些运算符(因此,包含该运算符的条件可以使用索引访问)?
postgres=# select amop.amopopr::regoperatorfrom pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amopwhere opc.opcname = 'array_ops'and opf.oid = opc.opcfamilyand am.oid = opf.opfmethodand amop.amopfamily = opc.opcfamilyand am.amname = 'btree'and amop.amoplefttype = opc.opcintype;amopopr-----------------------<(anyarray,anyarray)<=(anyarray,anyarray)=(anyarray,anyarray)>=(anyarray,anyarray)>(anyarray,anyarray)(5 rows)

若有收获,就点个赞吧
0 人点赞
