Java 类名:com.alibaba.alink.pipeline.regression.FmRegressor
Python 类名:FmRegressor
功能介绍
FM即因子分解机(Factor Machine),它的特点是考虑了特征之间的相互作用,是一种非线性模型。该组件使用FM模型解决回归问题。
算法原理
FM模型是线性模型的升级,是在线性表达式后面加入了新的交叉项特征及对应的权值,FM模型的表达式如下所示:
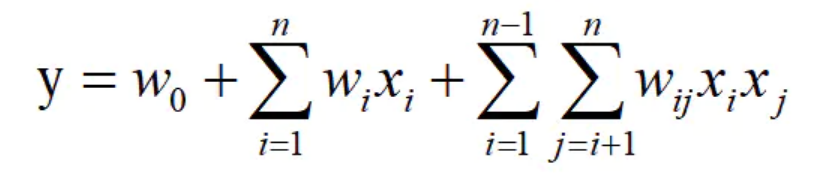
这里我们使用 Adagrad 优化算法求解该模型。算法原理细节可以参考文献[1]。
算法使用
FM算法是推荐领域被验证的效果较好的推荐方案之一,在电商、广告、视频、信息流、游戏的推荐领域有广泛应用。
文献
[1] S. Rendle, “Factorization Machines,” 2010 IEEE International Conference on Data Mining, 2010, pp. 995-1000, doi: 10.1109/ICDM.2010.127.
参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
|---|---|---|---|---|---|---|
| labelCol | 标签列名 | 输入表中的标签列名 | String | ✓ | ||
| predictionCol | 预测结果列名 | 预测结果列名 | String | ✓ | ||
| batchSize | 迭代数据batch size | 数据batch size | Integer | -1 | ||
| epsilon | 收敛阈值 | 迭代方法的终止判断阈值,默认值为 1.0e-6 | Double | [0.0, +inf) | 1.0E-6 | |
| featureCols | 特征列名数组 | 特征列名数组,默认全选 | String[] | null | ||
| initStdev | 初始化参数的标准差 | 初始化参数的标准差 | Double | 0.05 | ||
| lambda0 | 常数项正则化系数 | 常数项正则化系数 | Double | 0.0 | ||
| lambda1 | 线性项正则化系数 | 线性项正则化系数 | Double | 0.0 | ||
| lambda2 | 二次项正则化系数 | 二次项正则化系数 | Double | 0.0 | ||
| learnRate | 学习率 | 学习率 | Double | 0.01 | ||
| modelFilePath | 模型的文件路径 | 模型的文件路径 | String | null | ||
| numEpochs | epoch数 | epoch数 | Integer | 10 | ||
| numFactor | 因子数 | 因子数 | Integer | 10 | ||
| overwriteSink | 是否覆写已有数据 | 是否覆写已有数据 | Boolean | false | ||
| predictionDetailCol | 预测详细信息列名 | 预测详细信息列名 | String | |||
| reservedCols | 算法保留列名 | 算法保留列 | String[] | null | ||
| vectorCol | 向量列名 | 向量列对应的列名,默认值是null | String | null | ||
| weightCol | 权重列名 | 权重列对应的列名 | String | 所选列类型为 [BIGDECIMAL, BIGINTEGER, BYTE, DOUBLE, FLOAT, INTEGER, LONG, SHORT] | null | |
| withIntercept | 是否有常数项 | 是否有常数项,默认true | Boolean | true | ||
| withLinearItem | 是否含有线性项 | 是否含有线性项 | Boolean | true | ||
| numThreads | 组件多线程线程个数 | 组件多线程线程个数 | Integer | 1 | ||
| modelStreamFilePath | 模型流的文件路径 | 模型流的文件路径 | String | null | ||
| modelStreamScanInterval | 扫描模型路径的时间间隔 | 描模型路径的时间间隔,单位秒 | Integer | 10 | ||
| modelStreamStartTime | 模型流的起始时间 | 模型流的起始时间。默认从当前时刻开始读。使用yyyy-mm-dd hh:mm:ss.fffffffff格式,详见Timestamp.valueOf(String s) | String | null |
代码示例
Python 代码
from pyalink.alink import *import pandas as pduseLocalEnv(1)df = pd.DataFrame([["1:1.1 3:2.0", 1.0],["2:2.1 10:3.1", 1.0],["1:1.2 5:3.2", 0.0],["3:1.2 7:4.2", 0.0]])input = BatchOperator.fromDataframe(df, schemaStr='kv string, label double')test = StreamOperator.fromDataframe(df, schemaStr='kv string, label double')fm = FmRegressor()\.setVectorCol("kv")\.setLabelCol("label")\.setPredictionCol("pred")model = fm.fit(input)model.transform(test).print()StreamOperator.execute()
Java 代码
import org.apache.flink.types.Row;import com.alibaba.alink.operator.batch.BatchOperator;import com.alibaba.alink.operator.batch.source.MemSourceBatchOp;import com.alibaba.alink.operator.stream.StreamOperator;import com.alibaba.alink.operator.stream.source.MemSourceStreamOp;import com.alibaba.alink.pipeline.regression.FmRegressionModel;import com.alibaba.alink.pipeline.regression.FmRegressor;import org.junit.Test;import java.util.Arrays;import java.util.List;public class FmRegressorTest {@Testpublic void testFmRegressor() throws Exception {List <Row> df = Arrays.asList(Row.of("1:1.1 3:2.0", 1.0),Row.of("2:2.1 10:3.1", 1.0),Row.of("1:1.2 5:3.2", 0.0));BatchOperator <?> input = new MemSourceBatchOp(df, "kv string, label double");StreamOperator <?> test = new MemSourceStreamOp(df, "kv string, label double");FmRegressor fm = new FmRegressor().setVectorCol("kv").setLabelCol("label").setPredictionCol("pred");FmRegressionModel model = fm.fit(input);model.transform(test).print();StreamOperator.execute();}}
运行结果
| kv | label | pred | | —- | —- | —- |
| 1:1.1 3:2.0 | 1.0 | 0.473600 |
| 2:2.1 10:3.1 | 1.0 | 0.755115 |
| 1:1.2 5:3.2 | 0.0 | 0.005875 |
| 3:1.2 7:4.2 | 0.0 | 0.004641 |

若有收获,就点个赞吧
0 人点赞
