一、binlog 写入流程
1、写入流程
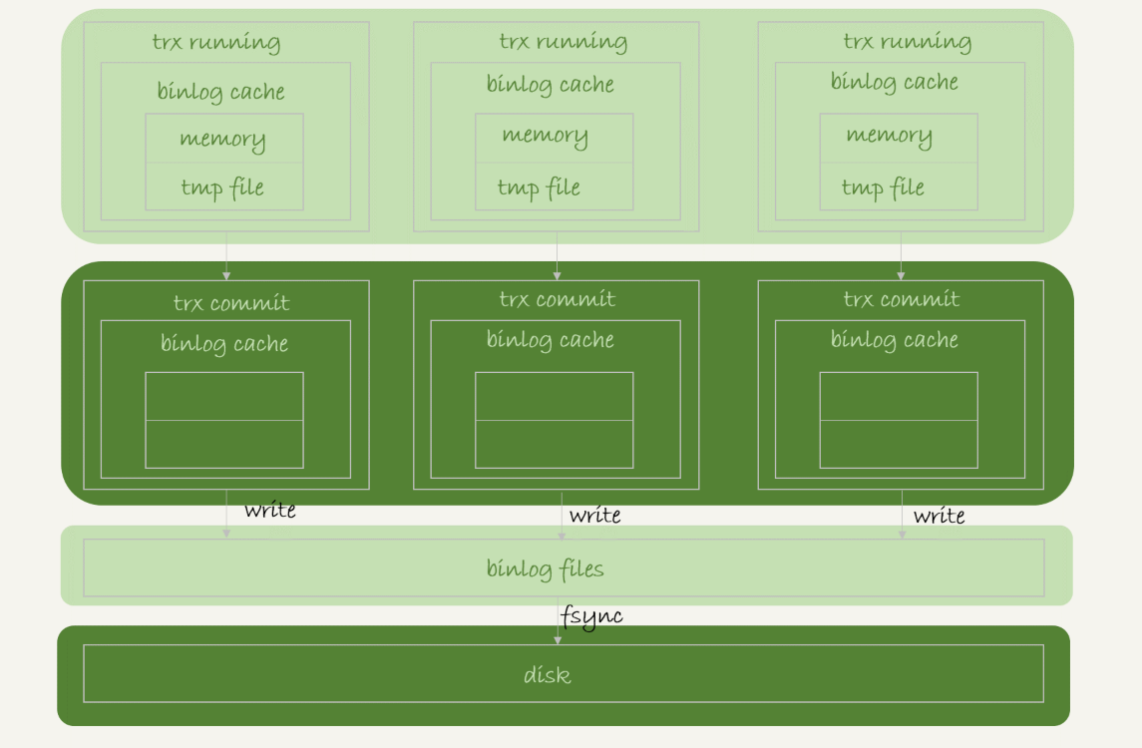
(1)每个线程有自己 binlog cache,但是共用同一份 binlog 文件。
2、TRX-Commit 刷盘策略
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
- sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
- sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
- sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
二、redo log 写入流程
1、触发时机
(1) master-thread
- 每隔 1 秒 ,write->fsync
- checkpoint:redo log buffer >= innodb_log_buffer_size/2,write
(2) group commit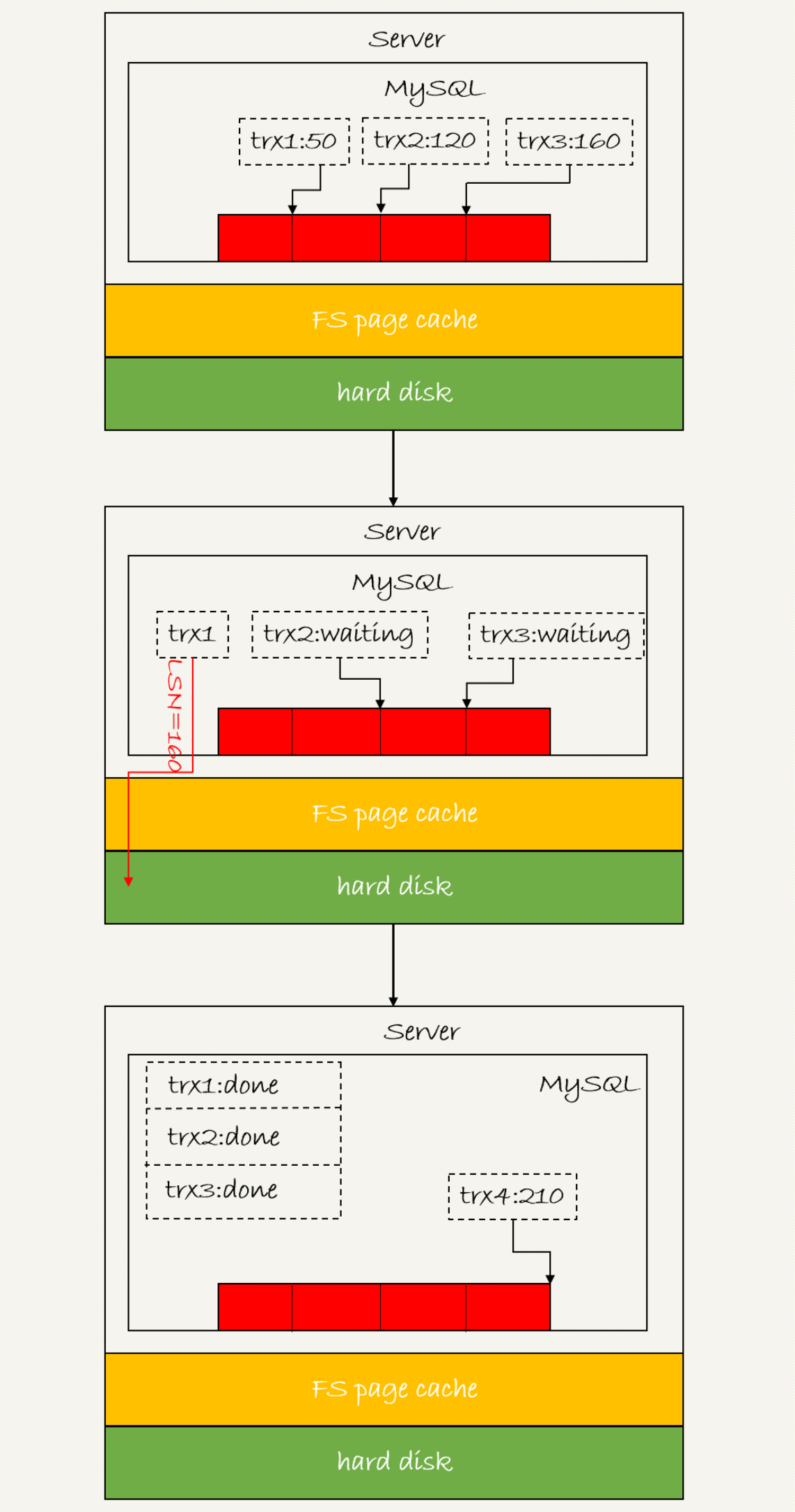
2、TRX-Commit 刷盘策略
innodb_flush_log_at_trx_commit 参数,它有三种可能取值:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;
- 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。
三、两阶段提交

(1) 二阶段提交思想:两阶段提交就是为了给所有人一个机会,当每个人都说“我 ok”的时候,再一起提交。
如果 redo log 提交完成了,事务就不能回滚(如果这还允许回滚,就可能覆盖掉别的事务的更新)。而如果 redo log 直接提交,然后 binlog 写入的时候失败,InnoDB 又回滚不了,数据和 binlog 日志又不一致了。
(2) 优化思想:拖时间。
- binlog_group_commit_sync_delay 参数,表示延迟多少微秒后才调用 fsync;
- binlog_group_commit_sync_no_delay_count 参数,表示累积多少次以后才调用
fsync。
(3) innodb_flush_log_at_trx_commit 设置成 1
- redo log 在 prepare 阶段就要持久化一次,因为有一个崩溃恢复逻辑是要依赖于 prepare 的 redo log,再加上 binlog 来恢复的。
- 每秒一次后台轮询刷盘,再加上崩溃恢复这个逻辑,InnoDB 就认为 redo log 在 commit 的时候就不需要 fsync 了,只会 write 到文件系统的 page cache 中就够了。

若有收获,就点个赞吧
0 人点赞
