一、并发控制
1、并发的演进思路
普通锁-> 读写锁 -> MVCC

二、锁的分类
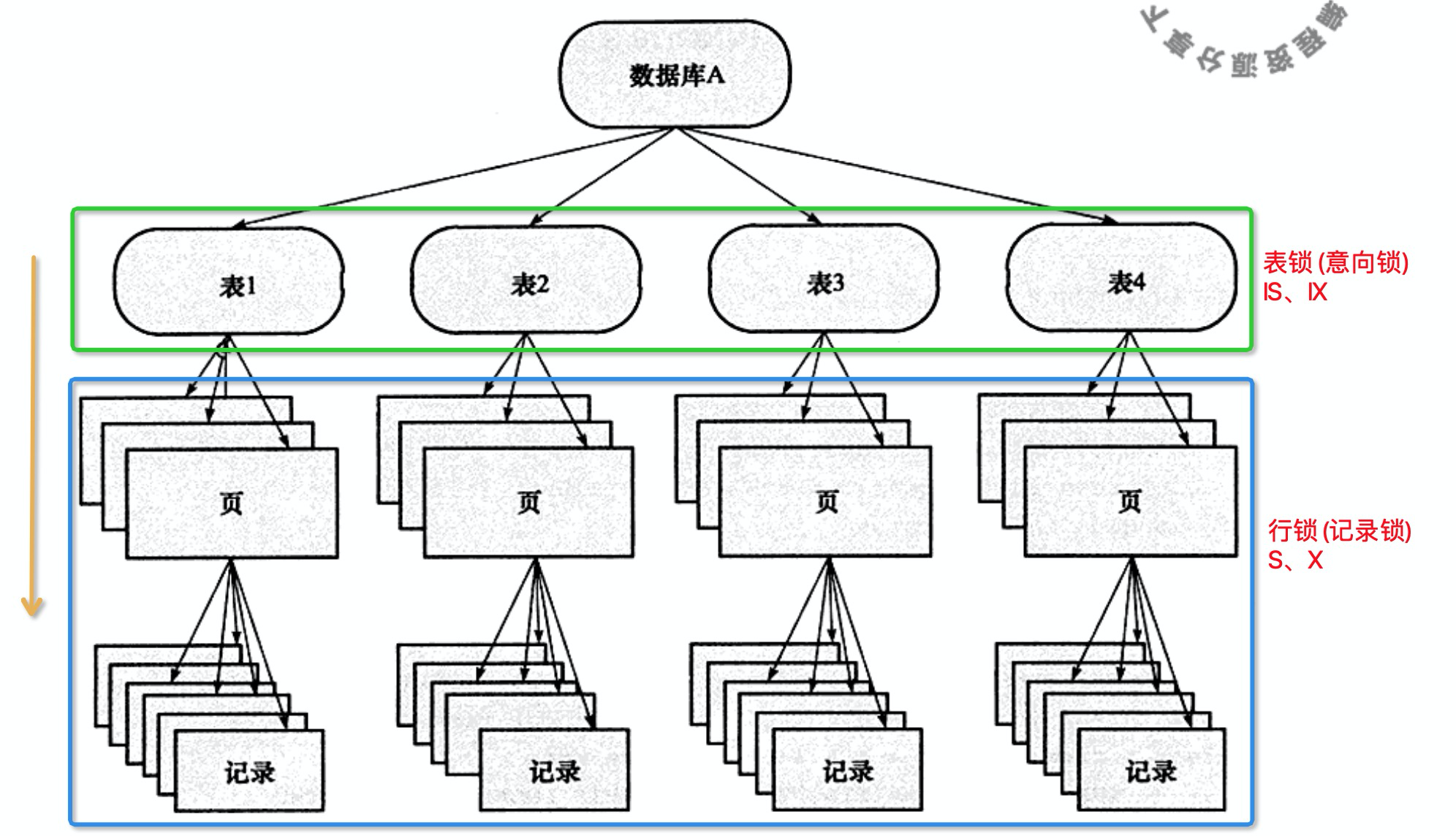

三、锁的算法
1、行锁算法
(1) Record Lock
单行记录上的锁,通过主键进行锁定。
(2) Gap Lock
范围锁
(3) Next-Key Lock
Record Lock + Gap-Lock,用于避免幻读。
2、锁的升级、降级
降级
当查询索引为单列唯一索引,Gap-Lock会自动降级为Record-Lock
升级
innodb不存在锁升级。innodb行锁的实现为通过bitmap管理页锁来进行的,无论锁住页中的一行记录还是多行开销是一样的,因此无需进行锁升级
四、加锁方式
1、表锁
(1) 自动上锁
在添加行锁时,innodb会自动添加表级别的意向锁。
(2) 手动上锁
上锁:lock tables …read / write
需要注意,lock tables语法除了会限制别的线程的读写之外,也限定了本线程接下来的操作对象。
解锁:unlock tables主动释放锁;也可以在客户端断开的时候自动释放。
2、行锁
(1) 自动上锁
insert、update、delete:InnoDB 会自动给涉及的数据加排他锁(X)。
select:一致性读,无锁
(2) 手动上锁
共享锁(S):select … lock in share mode
排他锁(X):select … for update
五、死锁
1、常见解决方式
(1) 超时
优点:实现简单
缺点:FIFO回滚方式,无法基于最小成本选择回滚事务。
(2) 死锁检测
通过检测wait-for-graph,选择回滚undo量最小的事务进行回滚。
优点:
缺点:
六、MVCC
1、思想
读写分离
如上图:
1. 最开始数据的版本是V0;
2. T1时刻发起了一个写任务,这是把数据clone了一份,进行修改,版本变为V1,但任务还未完成;
3. T2时刻并发了一个读任务,依然可以读V0版本的数据;
4. T3时刻又并发了一个读任务,依然不会阻塞;
2、实现方式
undo log
七、事务隔离级别
1、Read Uncommitted
2、Read Committed
(1) 普通select:snapshot read。
(2) 上锁select、update、deleted,会出现不可重复度:使用Record Lock。
3、Repeatable Read
(1) 普通select:snapshot read。
(2) 上锁select、update、deleted:使用Record Lock(单列唯一索引)、或Next-Key Lock。
4、Serializable
select语句,默认会加共享锁(S):select … lock in share mode。

若有收获,就点个赞吧
0 人点赞
