上节我们已经了一些概念:表空间、行、页、B+树、索引等概念。也提及了行的数据结构,页的数据结构,行在物理空间的存储格式等。通过B+树我们也分析了索引的一些特点。通过第一小节,我想至少对InnoDB引擎有了初步的了解,并且对从内理解 InnoDB有了一定的兴趣。这一节更深入的去从数据结构剖析和理解区和段的概念,从而知道我们的数据是如何一步步的写入到以InnoDB为引擎的MySQL数据中。
介绍之前,先介绍下面这张图。当我们已经对行和页有所了解之后,再来分析这张图可能就会比较容易理解。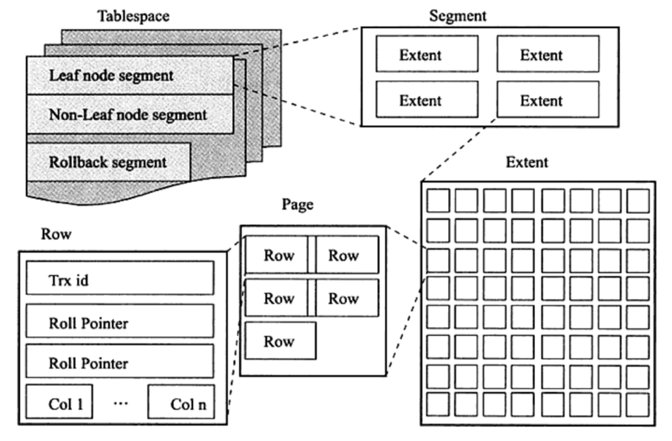
1、表空间:分为共享表空间和独立表空间,这里的图指的是独立表空间。
2、段:一个数据表分为多个索引,每个索引分为叶子节点段和非叶子结点段和其他(先不讲)。段是区分类的集合。
3、区:一个区由连续的64个页(16KB)组成,一个区大小1M。所以称“区是连续的一块物理空间”。多个区组成段。
4、页:页分为数据页和非数据页,也称为叶子页和非叶子页。一页大小16KB。
5、行:我们写入MySQL的记录称之为行。
这么看来似乎表空间的数据结构也已经明了,剩下的就是去了解各个结构之间的关系。
区(Extent)
讲解区概念之前,有必要回忆下页和行的概念。我们知道行是单向链表,通过next record字段将行连接起来。页是双向链表,通过File Header将页之间连起来。我们通过B+树就可以找到我们需要查找的所有数据,那么为什么还要引入区呢?没有区我们一样可以搜索结果。 这个问题也同样曾困扰着我,但是我却忽视了一个问题:页在物理空间的存储是随机IO,即使页与页之间是双链表,但是如果在随机IO中寻找页,将会浪费大量的时间。但是如果页与页之间是连续的话,那么将可以节省大量寻址的时间。这既是区引入的原因。
区的概念:由连续的64个16KB的Page组成的大小为1M的区。区是实际的1M物理空间,而段是概念上区的分类集合。当一个区用完之后,表空间会申请1M的连续物理空间分配给区。
段(Segment)
段的概念:一个索引分为两段,数据段和索引段,也称之为叶子段和非叶子段。段只是对区的分类,数据段存储的都是叶子节点,索引段存储的都是非叶子节点。
可是为什么要将数据段和索引段分开呢? 答案肯定是为了查找的效率。 试想如果将数据页和索引页都放在同一个区会发生什么情况:索引页和数据页掺杂在一起,如果数据量特别庞大,那么很有可能索引页之间夹杂着很多的数据页。虽然我们可以通过File Header找到下一个页,但是却也需要寻址,之前已经讨论过了,寻址的过程是浪费时间的。因此,为了节省寻址的时间,将数据页和索引页分开管理是有必要的。
那么接下来我们就一层一层的扒开表空间的各个数据结构之间的关系了。不过需要注意的是,所谓的这些表空间数据结构,其实只是对物理存储值结构的概述,并不是在物理空间有存储这些概述的字段。如数据行数据结构一样,实际存储的都是字段的值,通过分析二进制数据从而得到所有的字段对应的值。也可以理解为存储的值实际是所有字段值的集合。
碎片区(Fragment)
同样先问个问题:为什么要引入碎片区呢? 一个索引分为2段。按这么说,新建表的时候,即使只有一个主键,也会分配2M的物理空间作为这个表的独立表空间?这样的话,无疑是对物理空间巨大的浪费。为了解决这个问题,从而引入了“碎片区”。
碎片区:直属于表空间,叶子节点和非叶子节点开始都会存储在碎片区。
一个新表刚建立的时候只有96KB,刚开始插入的数据起始都会存入在这96KB。当然如果物理空间不够表空间是自扩展的。不过等到碎片区占用满了32个Fragment Array Entry,就开始申请1M物理空间分配给区。 说到这里,我想心中肯定疑惑重重,不要急,这些等我们一一道来。
从上图可见:数据量比较小的时候,myTest.ibd和myTest3.ibd都是96KB,而myTest2.idb是128KB。足以证明说新建表是96KB,并且表空间的物理空间是自增长的。
表空间组成
表空间由很多的区组成,犹如下图: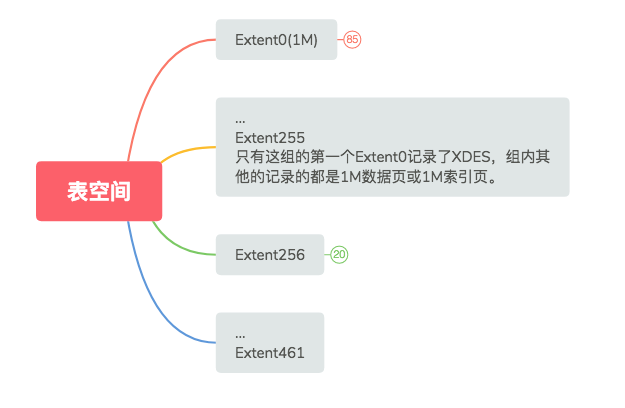
256个区分为一组,所以0-255是一组。256-461是一组。
我们知道一个区由64个Page组成,Page的类型也分为多种: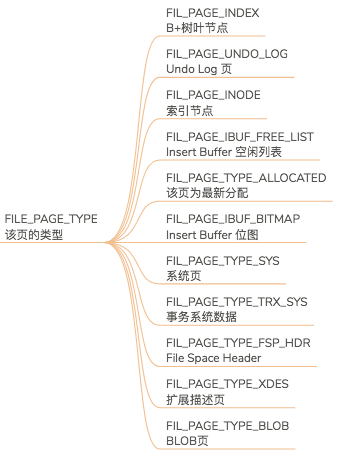
因此,一个区的组成可能由以上的多个类型的页组成。但是在InnoDB的区组成结构中,只有少数的几个区的类型是不同的,其他的区都是由64个叶子页或者非叶子页组成的区(即64个叶子阶段组成的区或64个非叶子节点组成的区)。这几个少数的区即是:Extent0和Extent256(为了更好的阐述,以下视为所有其他组的第一个区的代表),即每组的第一个区。可是Extent0的数据结构却又和Extent256的不同。之所以为什么这样呢,我们一一详述。
需要注意的是:我通过Xmind画了个头脑风暴的图,但是只标注了字段以及部分字段的含义,没有标注出字段所占用的大小。但是字段值所占用的大小在物理存储中其实是非常重要的,因为InnoDB就是通过每个结构所占用的一定大小从而可以通过物理偏移量相关联。下面的知识点很多都是来回串起来的,所以需要自己多去思考。由于知识点的错综复杂,因此讲解起来也比较费劲。因此有讲解不清晰的地方请留言。感谢!
Extent0组成
Extent0结构图如下(蓝色的是系统表空间的字段,与独立表空间的无关):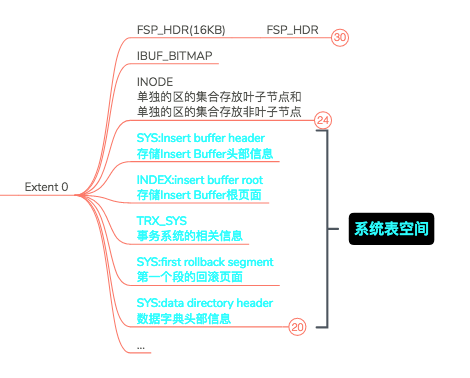
可见有3个字段:FSP_HDR、IBUF_BITMAP、INODE。IBUF_BITMAP暂且不说,我也还没看。
FSP_HDR
FSP_HDR的结构图如下: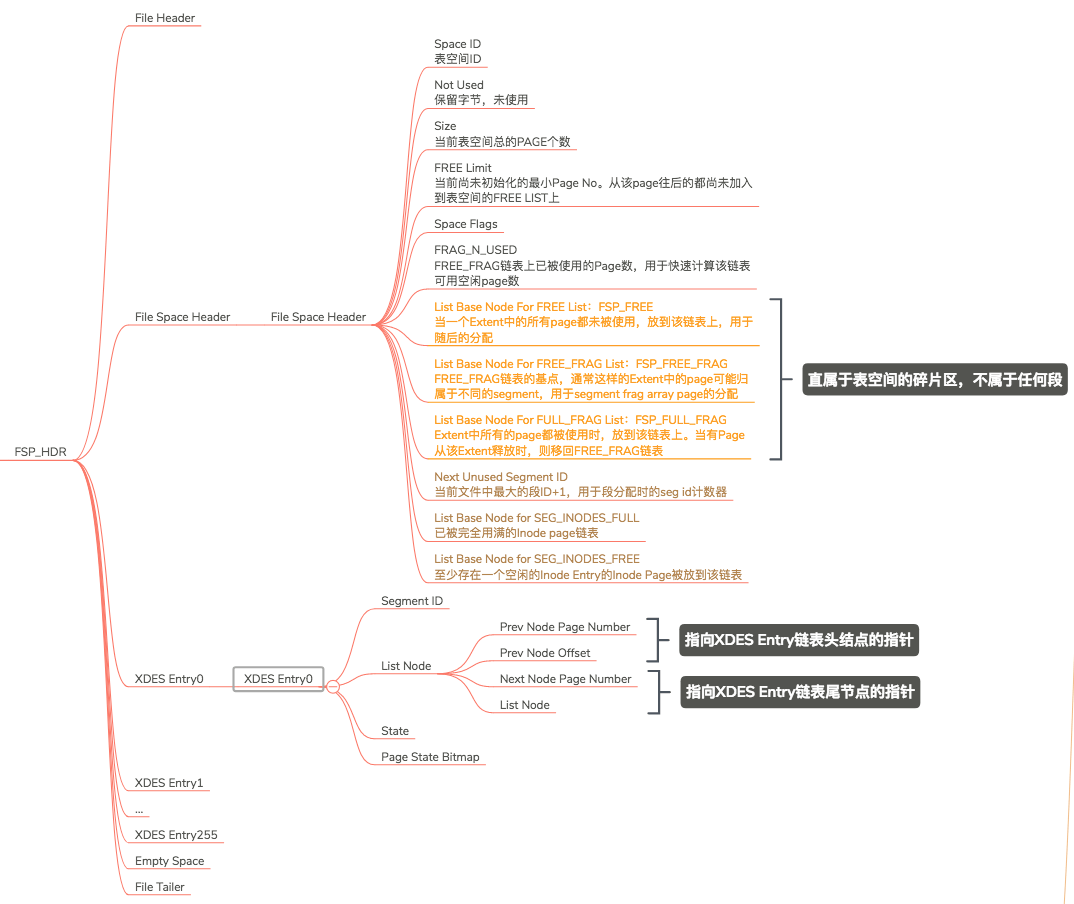
我们分析下Extent0的结构:File Header,File Space Header,XDES Entry0-XDES Entry255,Empty Space,File Tailer。
- File Header和File Tailer不用细说,所有的Page公用的。
- File Space Header是表空间头信息,这个需要详细的说。
- XDES Entry是对区的描述,XDES Entry0-XDES Entry255即对应256个区的描述,这也说明为什么256个区分为一组。
- Empty Space 空闲空间
File Space Header
为了缩短篇幅,这里只介绍我认为比较难以理解的字段,一些易于理解的字段就不单独介绍了。
- List Base Node For FREE List:FSP_FREE
- List Base Node For FREE_FRAG List:FSP_FREE_FRAG
- List Base Node For FULL_FRAG List:FSP_FULL_FRAG
- Next Unused Segment ID:当前最大段ID+1,用于分配时的segID计数器
- List Base Node for SEG_INODES_FULL:SEG_INODES_FULL
- List Base Node for SEG_INODES_FREE:SEG_INODES_FREE
FSP_FREE:当一个Extent中所有Page都未被使用,放到该链表上,用于随后的分配。
>FSP_FREE_FRAG:FREE_FRAG链表的基点,通常这样的Extent中的Page可能归属于不同的Segment,用于segment Frag array page的分配。
>FSP_FULL_FRAG:Extent中所有的Page都被使用时,放到该链表上。当有Page从该Extent释放时,则移回FREE_FRAG链表。
>SEG_INODES_FULL:已被完全用完的Inode Page链表
>SEG_INODES_FREE:至少存在一个空闲的INODE Entry的INODE Page被放在该链表
理解:
1、FSP_FREE:直属于表空间,现在还没用到这个区中的任何页面。
2、FSP_FREE_FRAG:直属于表空间,有剩余空间的碎片空间,表示碎片区中还有可用的页面。
3、FULL_FRAG:直属于表空间,没有剩余空间的碎片空间,表示碎片区中的所有页面都被使用,没有空闲页面。
4、SEG_INODES_FULL:这是个INODE PAGE链表的基节点,如果INODE满了就会链接在此。
5、SEG_INODES_FREE:这是个INODE PAGE链表的基节点,如果INODE还有INODE Entry没用,就链接在此处。
在网上盗了一张图,如下(地址:https://blog.csdn.net/bohu83/article/details/81086474):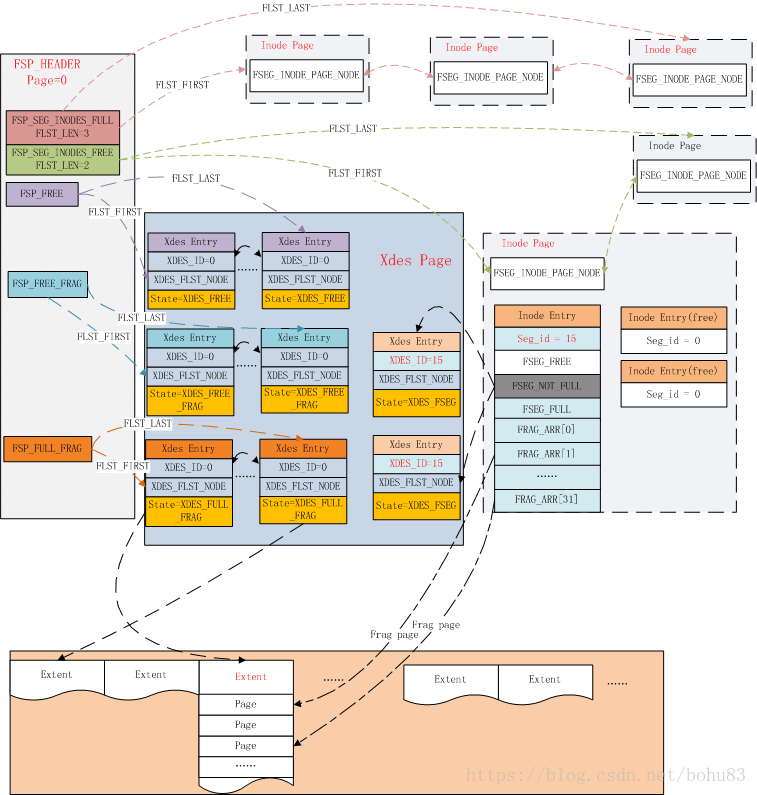
所以可以得知:FSP_FREE、FSP_FREE_FRAG、FSP_FULL_FRAG 3个字段指的都是XDES Entry的基点。FSP_FREE指向的区是还没有被划分类型的,FSP_FREE_FRAG指向的是碎片区,FSP_FULL_FRAG指向的是已经满了的碎片区。如果碎片区中的某个页面被释放,则从FSP_FULL_FRAG移除并且链接到FSP_FREE_FRAG。
XDES
XDES的数据结构和XDES Entry的数据结构如图: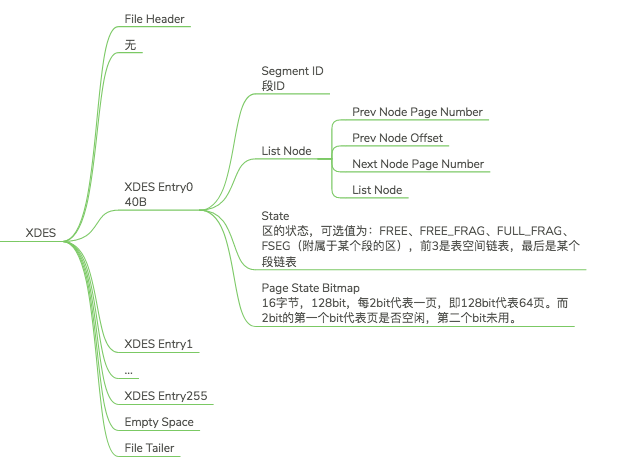
XDES Entry是对区的描述,我们知道一个256个区分为一组,每一个区都有一个对应的描述,用来描述区的类型和状态以及使用情况,所属段ID,和上一个段的上下指针。
我们在FSP_HDR的结构图中可见XDES Entry,但是并没有XDES结构。这其实就是Exten0和Extent256的一个区别。虽然FSP_HDR并没有XDES结构,但是在其中也是存在XDES Entry0-255的描述。比较有趣的是Page State Bitmap字段,它占用16字节,128bit。每2个bit代表的是1页,所以128bit就能代表64个页面。刚好一个区64个页面,所以一个区的所有页面是否用完是受到监控的。再次强调一下:一般来讲我们所谓的1个区64个页面指的是数据页,就是B+树的页面,除了Extent0(前三页)和Extent256(即每组的第一个区的前两页)。
INODE
INODE结构图如下: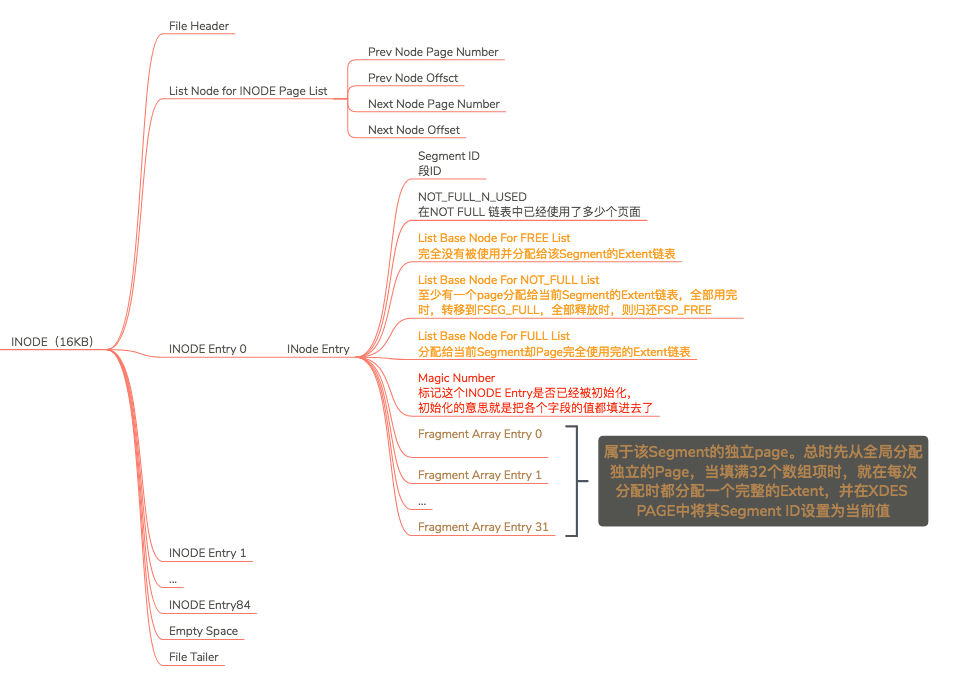
之前有说过,一个索引分为2段:数据段和索引段。就像区有区的描述XDES Entry一样,段也有段的描述INODE Entry。一般我们的索引建议最多建5个的比较好,所以差不多占用10个段的描述INODE Entry。而INODE又85个INODE Entry,所以对于独立表空间来说85个足矣。对于系统表空间来说,可能85个并不够用。那么List Node for INODE Page List字段就比较有用了,它类似于是段的双向链表指针。接下来我们将会重点关注INODE Entry。
INODE Entry
我们先一览段描述的重要字段:
- List Base Node For FREE List:FSEG_FREE
- Lise Base Node For NOT_FULL List:FSEG_NOT_FULL
- List Base Node For FULL List:FSEG_FULL
- Fragment Array Entry0-31
字段介绍:
FSEG_FREE:属于段,同一个段中,所有页面都是空闲的区对应的XDES Entry结构会被加入到这个链表。
FSEG_NOT_FULL:属于段,同一个段中,仍有空闲空间的区对应的XDES Entry结构会被加入到这个链表。
FSEG_FULL:属于段,同一个段中,已经没有空闲空间的区对应的XDES Entry结构会被加入到这个链表。
值得注意的是:这里的链表指的都是属于段的链表,和之前FSPHDR中直属于表空间的3个链表不同。并且段链表指的是本段,即一个索引分2段,每段分3个链表,因此就是6个链表了。
_Fragment Array Entry0-31:这里记录的是页号,占4个字节。当占满了32个页面之后,就开始申请1M的区使用。
到这里那么Extent0的数据结构基本已经讲完。可是对于这些字段是如何使用多少还会有些疑惑。那么接下来就是讲解下这些字段的用处。当然这也只是个人理解,有错请指正,不胜感激! 再次回顾下碎片区的概念:在一个碎片区中,**并不是所有的页都是为了存储同一个段的数据而存在的**,而是碎片区中的页可以用于不同的目的,比如有些页用于段A,有些页用于段B,有些页甚至哪个段都不属于。
插入数据文字分析
一开始建表的时候,独立表空间的大小才96KB。而Extent0的3个字段FSP_HDR、IBUF_BITMAP、INODE 三个页面就占用了16*3=48KB。所以还剩下48KB的物理空间用来存储数据页。
新建表假设只有一个主键id,那么肯定会初始化2个段描述INODE Entry分别描述索引段和数据段。因为一开始的时候不会申请完整的1M的区,所以使用的是碎片区。罗列下过程如下:
初始化过程:
- FSP_HDR:
- File Space Header:
- Space ID:1(假设是1,其实是有个表中表会记录自增的ID分配给表空间)
- FRAG_N_USED:0,表示FREE_FRAG链表上还没有Page被使用。
- FSP_FREE:假设碎片区最开始阶段就只有3个页面,即剩余的48KB。所以FSP_FREE指向的就是这个碎片区。
- FSP_FREE_FRAG:初始化阶段是个空链表。
- FSP_FULL_FRAG:初始化阶段是个空链表。
- SEG_INODES_FULL:空
- SEG_INODES_FREE:将INODE初始化的两个INODE Entry10和11链接在此处。
- XDES Entry0-255初始化,但是只有XDES Entry0有描述Extent0的相关信息。
- 省略
- File Space Header:
- IBUF_BITMAP:
- INODE:
- INODE Entry0:id的数据段
- Segment ID:段ID,假设是10,由File Space Header的Next Unused Segment ID分配
- NOT_FULL_N_USED:在FSEG_NOT_FULL中已经使用了0个页面
- FSEG_FREE:空的
- FSEG_NOT_FULL:空的
- FSEG_FULL:空的
- Magic Number:标记这个INODE Entry是否已经被初始化,初始化的意思即把各个字段的值都填进去了。初始化是为0.
- 省略
- INODE Entry1:id的索引段
- Segment ID:段ID,假设是11,由File Space Header的Next Unused Segment ID分配
- 省略
- INODE Entry0:id的数据段
- FSP_HDR:
开始插入第一行记录
碎片区之所以成为碎片区,就是因为碎片区中的页可能是段A的页,也可能是段B的页,也可能都不属于。在上述初始化后,假设我要插入第一个数据行,那么又会发生哪些操作呢?
- 检查INODE Entry0的Magic Number的值,很明显刚开始是0.
- 如果是0,则说明碎片区还没有用完。继续用碎片区的空间。
- 如果是1,则说明当前的INODE Entry已经填满了,即碎片区的32个Fragment Array Entry被当前段使用完。可以开始申请1M的区了。
- 检查FSP_FREE_FRAG是否有可用区(即XDES Entry),发现没有。于是从FSP_FREE申请,并且将区的state标为FREE_FRAG。然后链入FSP_FREE_FRAG。
- 前面已经提到过碎片区的大小初始化是只有48KB,即2个Page。开始往第一个Page1中写入数据行,并且将该Page1的页号记录在INODE Entry0的第一个Fragment Array Entry0。由于当前只有一行数据,所以INODE Entry1不用写入。
- 检查INODE Entry0的Magic Number的值,很明显刚开始是0.
继续插入多条记录
虽然上述第一行数据插入过程已经讲解的很清楚了,但是还没有达到表空间自扩展和索引页生成的条件。所以这里假设继续插入数据,直到用完两页或者已经出现了索引页。一起分析下会出现哪些情况。
继续插入第二行数据,如第一行记录插入的过程,检查INODE Entry0的magic Number的值为0,说明碎片区还没满,因此继续用碎片区。
- FSP_FREE_FRAG的XDES Entry的Page State Bitmap记录了当前的第一页和第二页都还是有空闲的,所以继续在第一页插入记录。此时Fragment Array Entry0还是只记录了Page1.
重复第一步和第二步,直到开始出现索引页的产生。
我们回顾下索引页是怎么产生的:在讲解B+树的时候,我们是从自底向上的结构阐述了B+树的生成。而实际中B+树的生成是从上到下的过程。开始B+树的头节点即最开始的数据页,每页是16KB,可以插入的数据行也是固定的7992条。所以B+树分裂的条件有2:第一、数据页满了16KB了,无法再继续插入;第二、已经达到7992条记录了,也无法再继续插入。现在假设B+开始分裂,根节点会复制一页,然后将根节点指向复制页,然后在将新的记录写在新的页。可是这里存在一个疑问:根节点的页号会怎么变化呢?为了阐述这个问题,画图说明。
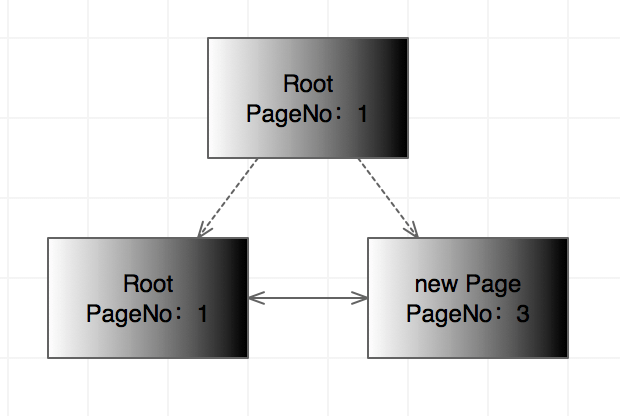 上图描述了Root Page复制之后,并且最终可能产生的关系。这里需要注意的是还没有修改根节点复制页的页号相关信息。大家有没有注意到一个问题:在表空间的所有数据结构中的类似指针功能,存的都是页号和相对偏移量,以及Fragment Array Entry中存的也是页号。既然这么多地方存的都是页号,所以我猜测页号肯定是不能经常变动的,否则可能存在大量地方需要变动页号信息。在最开始只有根节点的情况下,根节点的页号已经存在了Fragment Array Entry,所以这里的页号应该不会发生变化。最终得出的结论可能是:根节点的物理位置不发生变化,但是页号发生变化,根节点的复制页号不发生变化,但是新增了一个物理空间对应的页号,新增的数据页也是新增了物理空间和页号的映射(可能不是映射,大概就是这个意思)。得到的图如下:
上图描述了Root Page复制之后,并且最终可能产生的关系。这里需要注意的是还没有修改根节点复制页的页号相关信息。大家有没有注意到一个问题:在表空间的所有数据结构中的类似指针功能,存的都是页号和相对偏移量,以及Fragment Array Entry中存的也是页号。既然这么多地方存的都是页号,所以我猜测页号肯定是不能经常变动的,否则可能存在大量地方需要变动页号信息。在最开始只有根节点的情况下,根节点的页号已经存在了Fragment Array Entry,所以这里的页号应该不会发生变化。最终得出的结论可能是:根节点的物理位置不发生变化,但是页号发生变化,根节点的复制页号不发生变化,但是新增了一个物理空间对应的页号,新增的数据页也是新增了物理空间和页号的映射(可能不是映射,大概就是这个意思)。得到的图如下:
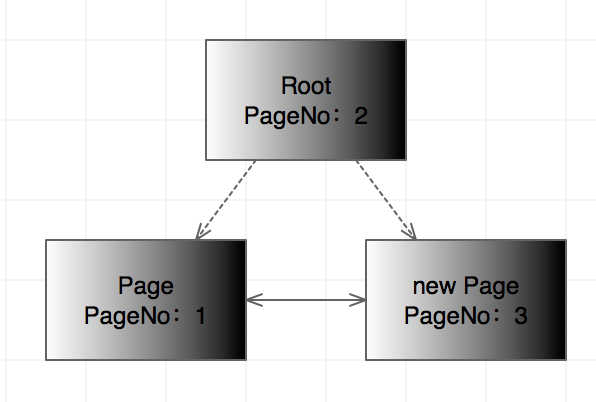 于是索引页出现了。在【MySql技术内部-InnoDB存储引擎.pdf】上记得有特别详细的阐述页分裂的情况。刚好可以验证下猜测。
于是索引页出现了。在【MySql技术内部-InnoDB存储引擎.pdf】上记得有特别详细的阐述页分裂的情况。刚好可以验证下猜测。索引页产生之后,可见这会已经产生了3个页面。最初的页面有48KB共3个页面,刚好都被占用。当占满了3个Page的时候,表空间需要申请更多的空间。索引页的出现,使INODE Entry11的Fragment Array Entry开始记录了第一个索引页的页号2。此时的INODE Entry10已经记录了第二个页号3。
(总结:碎片区和段的区别就已经体现了:碎片区中存了ID索引段的页,也存了ID数据段的页;而ID索引段指向的区将存储的全是索引页,ID数据段指向的区将存储的全是数据页。)
【存在一个疑问:表空间的碎片区是记录在哪里呢?】
这里也可以做个试验:往一张新建表中持续插入数据,然后观察并且分析发生的变化。
为了更好的分析结果,我在github上下载了一个分析idb的工具,地址:https://github.com/tianyk/py_innodb_page_info。并且执行了:python py_innodb_page_info.py myTest.ibd得到结果如下:
说明了什么呢?这个独立表空间中一个有6页,分别是:6*16=96KB,所以验证了新建表共有6页。
- FSP_HDR:File Space Header(16KB)
- IBUF_BITMAP:Insert Buffer Bitmap(16KB)
- INODE:File Segment inode(16KB)
- B-tree Node:这是根节点(16KB)
- Freshly Allocated Page:可用页(32KB)
以上可见,目前还有2页是空闲,只占用了一个数据页:根节点。
python py_innodb_page_info.py -v myTest.ibd得到结果如下:
现在我要不断的往myTest数据表中插入数据,直到占满根节点。现在截图如下:
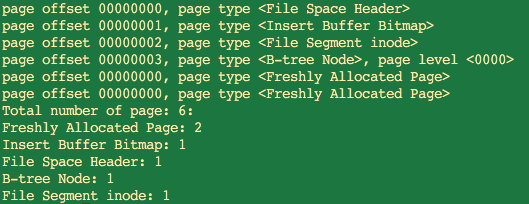
首先看B-tree Node为3,说明目前的B+树共占用3页,其中1个根节点,2个叶子节点(看page level,0000是叶子节点,0001是非叶子节点)。和第三步的猜想也一致。
再继续看发现: page offset 00000003, page type
, page level <0001> page offset 00000004, page type , page level <0000> page offset 00000005, page type , page level <0000> 从page offset 00000003, page type
, page level <0000> 变化成 page offset 00000003, page type > 继续验证表空间的自扩展:方法还是继续往myTest写入数据,直到第三个页面也写满了。此时的截图如:>, page level <0001>,根节点的物理空间是没有变的(从offset可以看出),但是页号看不出来(除非分析idb二进制文件内容)。而且有句话叫做:根节点是万年不动窝。其实我想意思也就是说根节点的位置永远都在offset 00000003这个位置。 >
通过以上我们可以基本证明:> 模拟表空间数据的插入猜想基本是没问题的。
- 我们再继续写入数据,直到数据段INODE Entry10的Fragment Array Entry占满了32页(很明显数据页写的比索引页要快,因此肯定是数据段的Fragment Array Entry先满)。数据段满了之后,就开始申请完整的区Extent1作为数据的存储,在XDES Entry1中开始写入描述Extent1的相关信息。并且XDES Entry10的List Node指向新申请的Extent1。这里是轻描淡写的说完了如何申请1M的区的条件过程,但是更细致的说应该是这样:
- Fragment Array Entry的32个页面写满了,那么开始需要申请完整的区了。在申请之前,先查看NOT_FULL_N_USED查看FSEG_NOT_FULL链表中已经使用了多少了页面。目前是0,因此说明FSEG_NOT_FULL链表中没有可用的区。
- 查看FSEG_FREE链表是否有可分配的区,发现并没有。于是FSEG_FREE从FSP_FREE申请一个可用的区使用并且链入FSEG_FREE。然后FSEG_NOT_FULL从FSEG_FREE中申请区,在开始写入数据。如果FSEG_NOT_FULL写满了,则从FSEG_NOT_FULL移除链入到FSEG_FULL链表。如果FSEG_FULL有页被删除,那么从FSEG_FULL移除并且链入FSEG_NOT_FULL。
到这里,我想接下来的就不要在讲了。可是讲了通篇,发现确实不好理解,原因在于我也是边写边去求证。可是为了让大家还是能够有个清晰的认识,我觉得还是有必要画个图表示。
插入数据图文分析
1、新建表的时候,假设只有主键ID,是这样的: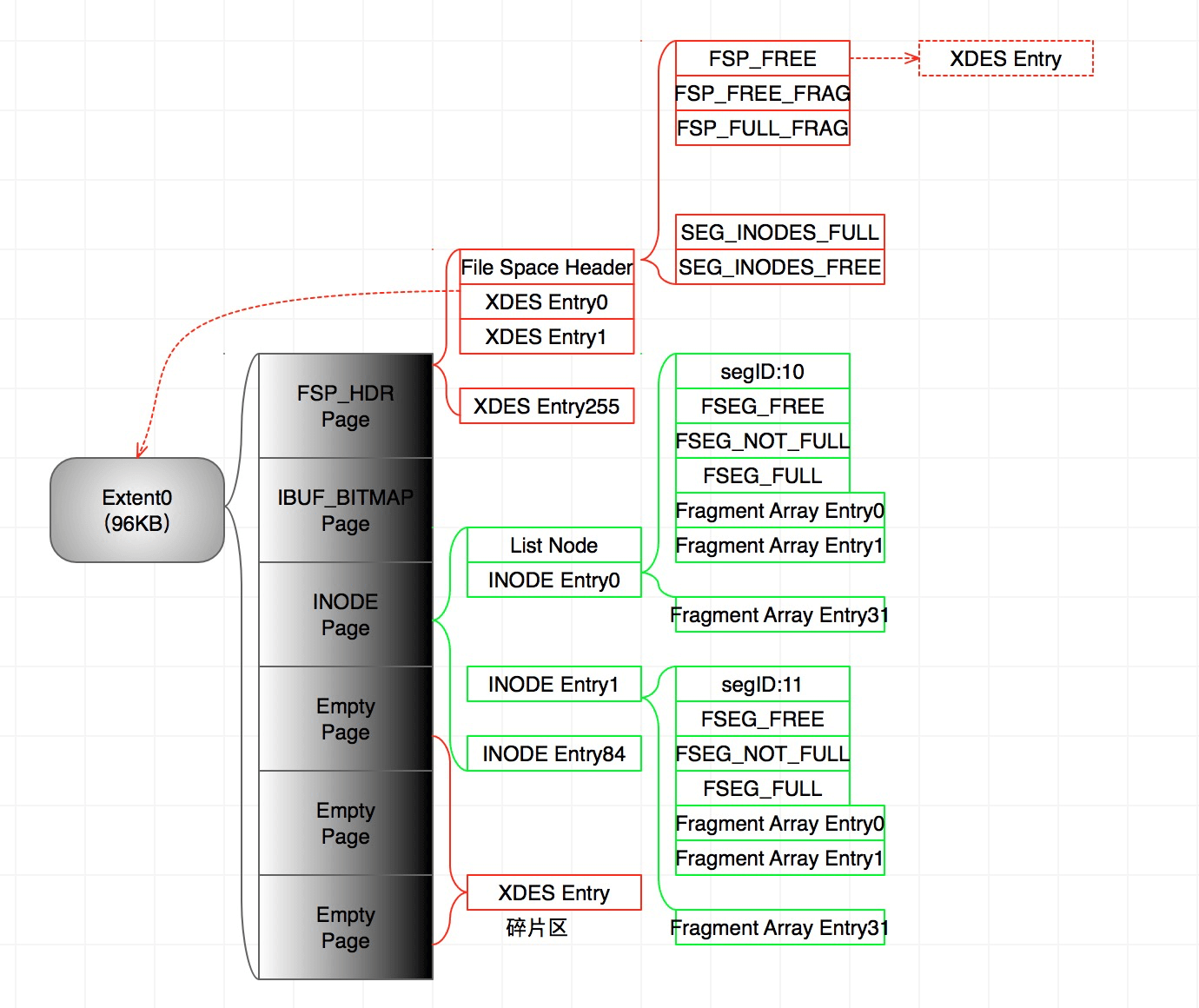
- INODE Entry0是主键ID的数据段,INODE Entry1是主键ID的索引段。
- FSP_FREE开始指向的是描述碎片区的XDES Entry。
- 在图中标志的碎片区是3个空闲的页面组成的XDES Entry。这个不一定是对的。因为我也不能确定。
2、然后开始往数据表中插入第一条数据: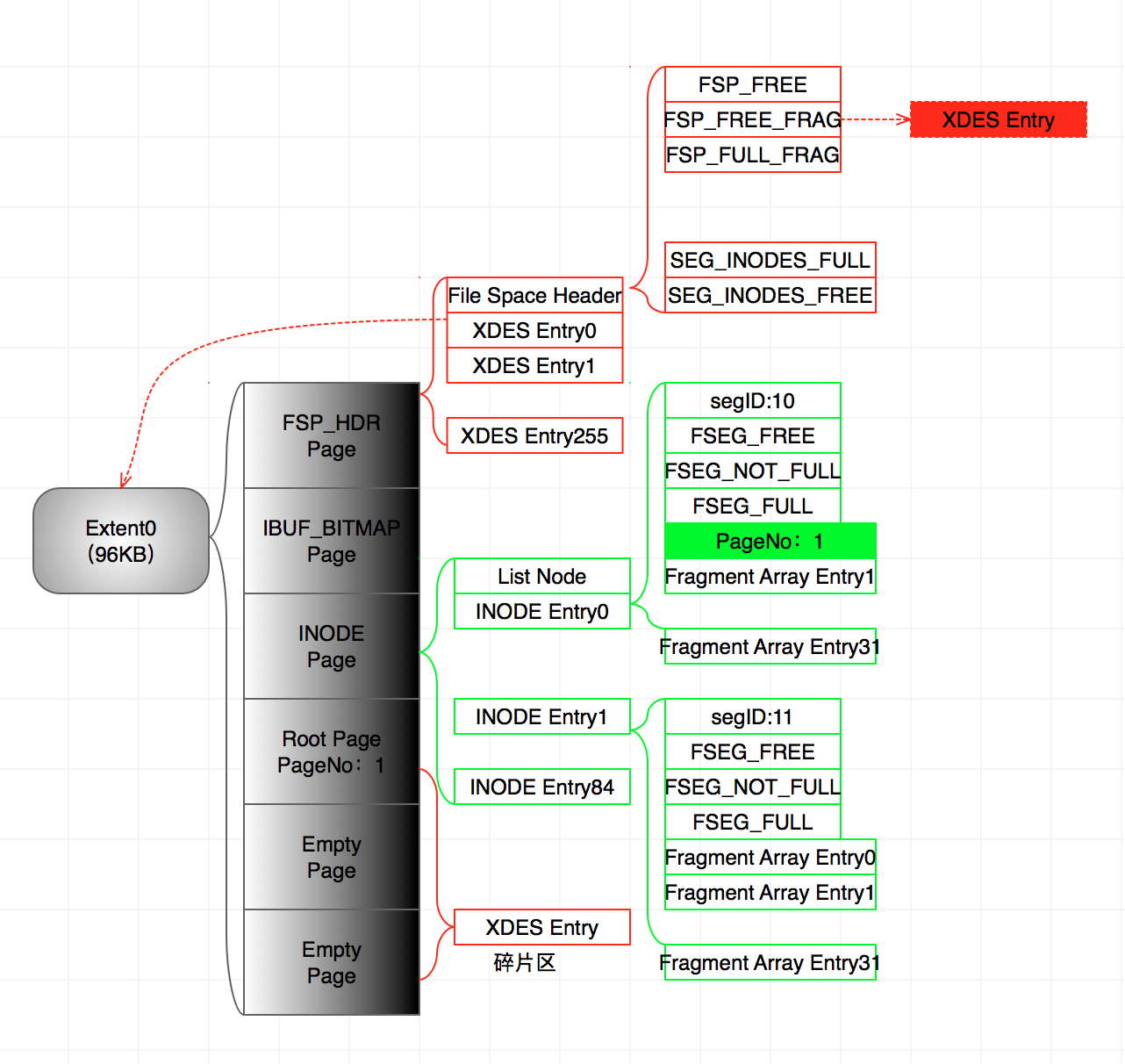
- 第一个空页被用来作为数据页&根节点,并且将页号存储在数据段的Fragment Array Entry0。
3、继续往数据表中插入数据,直到第一个索引页出现: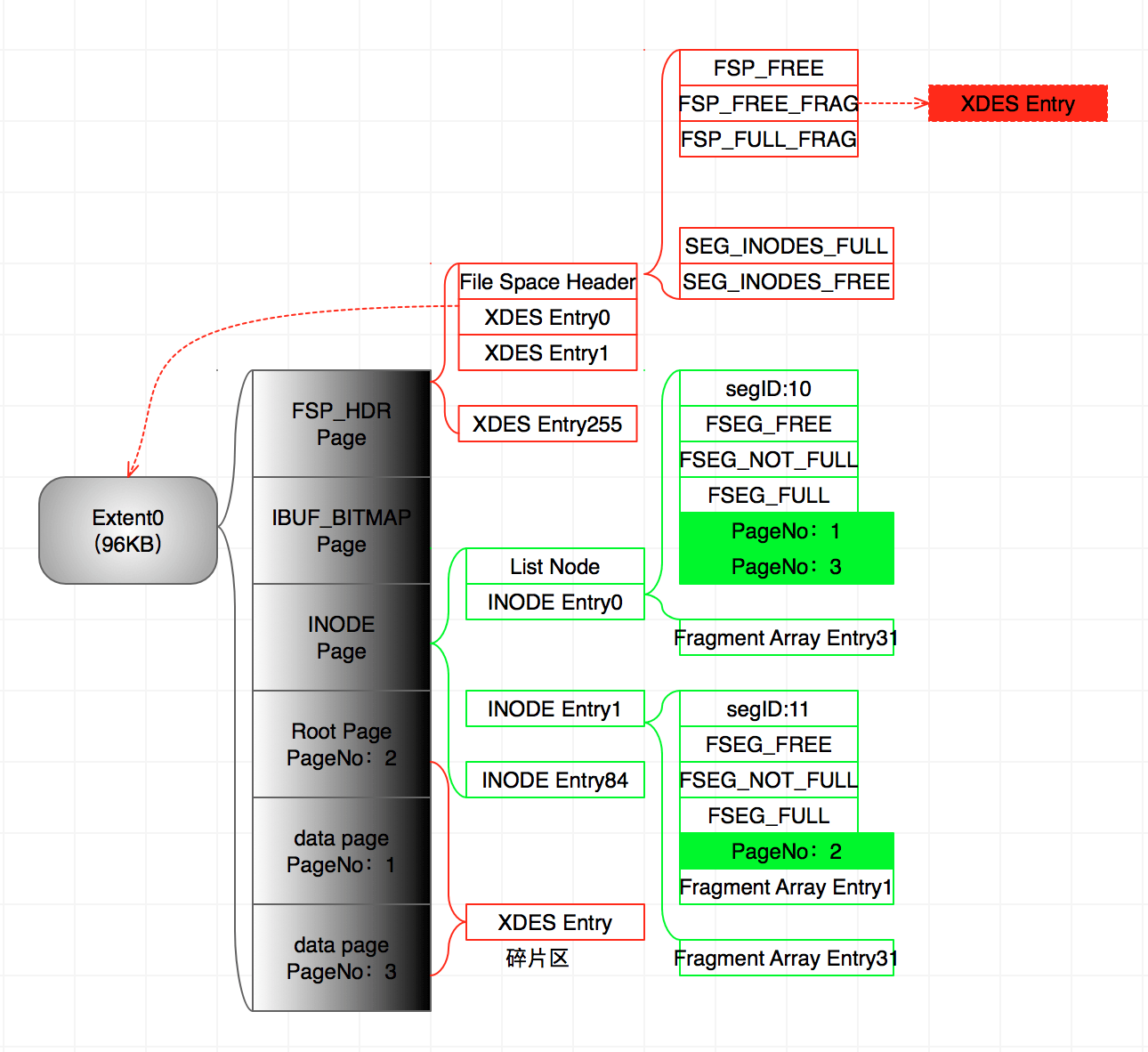
- 索引页的页号PageNo:2插入到索引段的Fragment Array Entry0
- 新数据页的页号PageNo:3插入到数据段的Fragment Array Entry1
- 注意:此时的数据页PageNo:1已经写满16KB。
4、继续插入记录,直到PageNo:3也写满16KB,此时表空间需要申请新的空间,按2页32KB申请。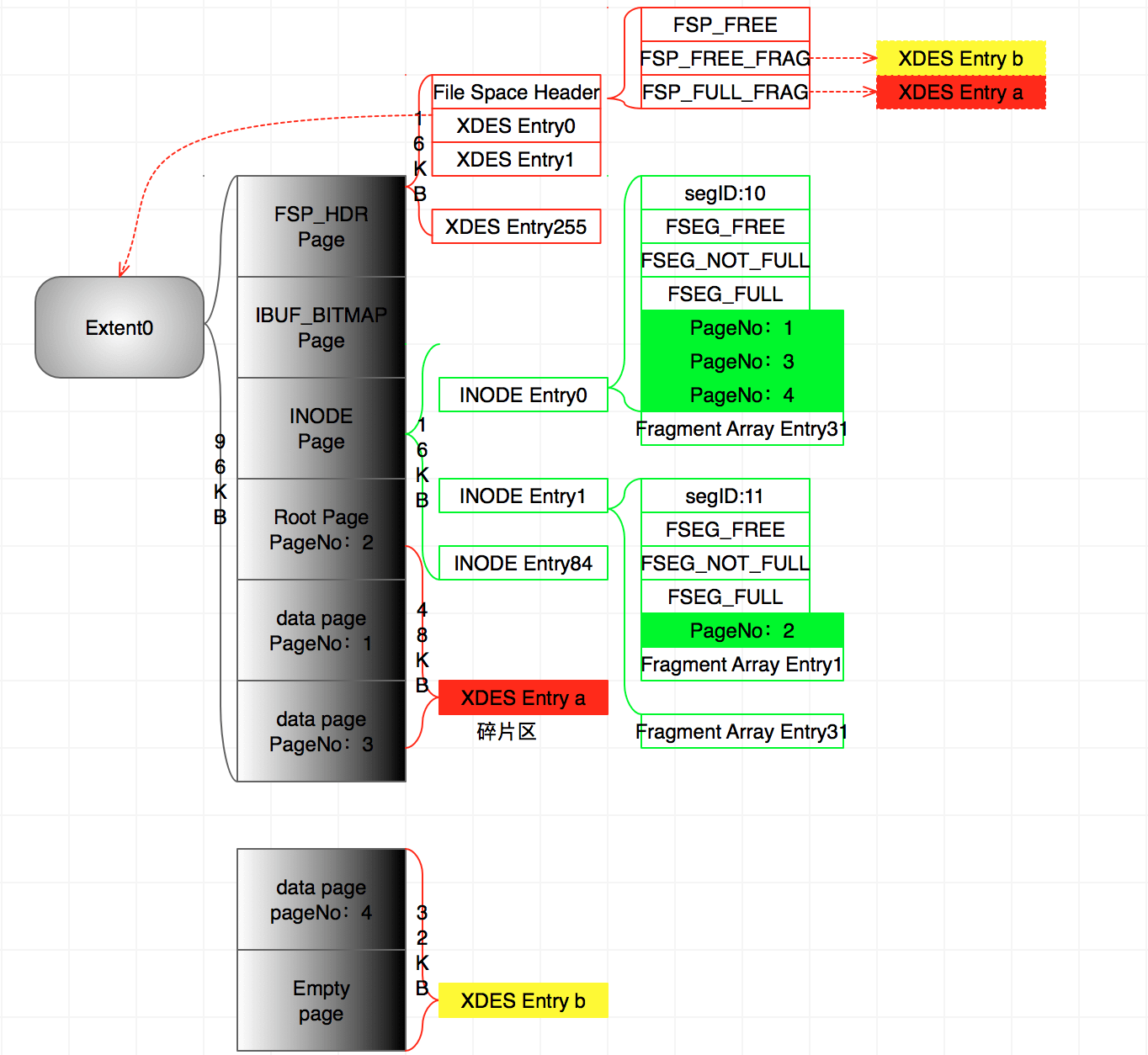
- 为了区分新申请的空间顾命名原来的碎片区为XDES Entry a和新碎片区为XDES Entry b。值得注意的是XDES Entry b和XDES Entry a不是连续的物理空间,表空间会在磁盘中选择一块32KB的空间作为新的碎片区。
- 申请的碎片区首先链接在FSP_FREE,然后FSP_FREE_FRAG从FSP_FREE申请资源,再而链接在FSP_FREE_FRAG。
- 新插入的记录则写在PageNo:4,并且将页号记录在Fragment Array Entry2。
- 由于XDES Entry a已经写满了所以链接在FSP_FULL_FRAG。
5、还在继续插入数据,直到数据段的Fragment Array Entry写满32页。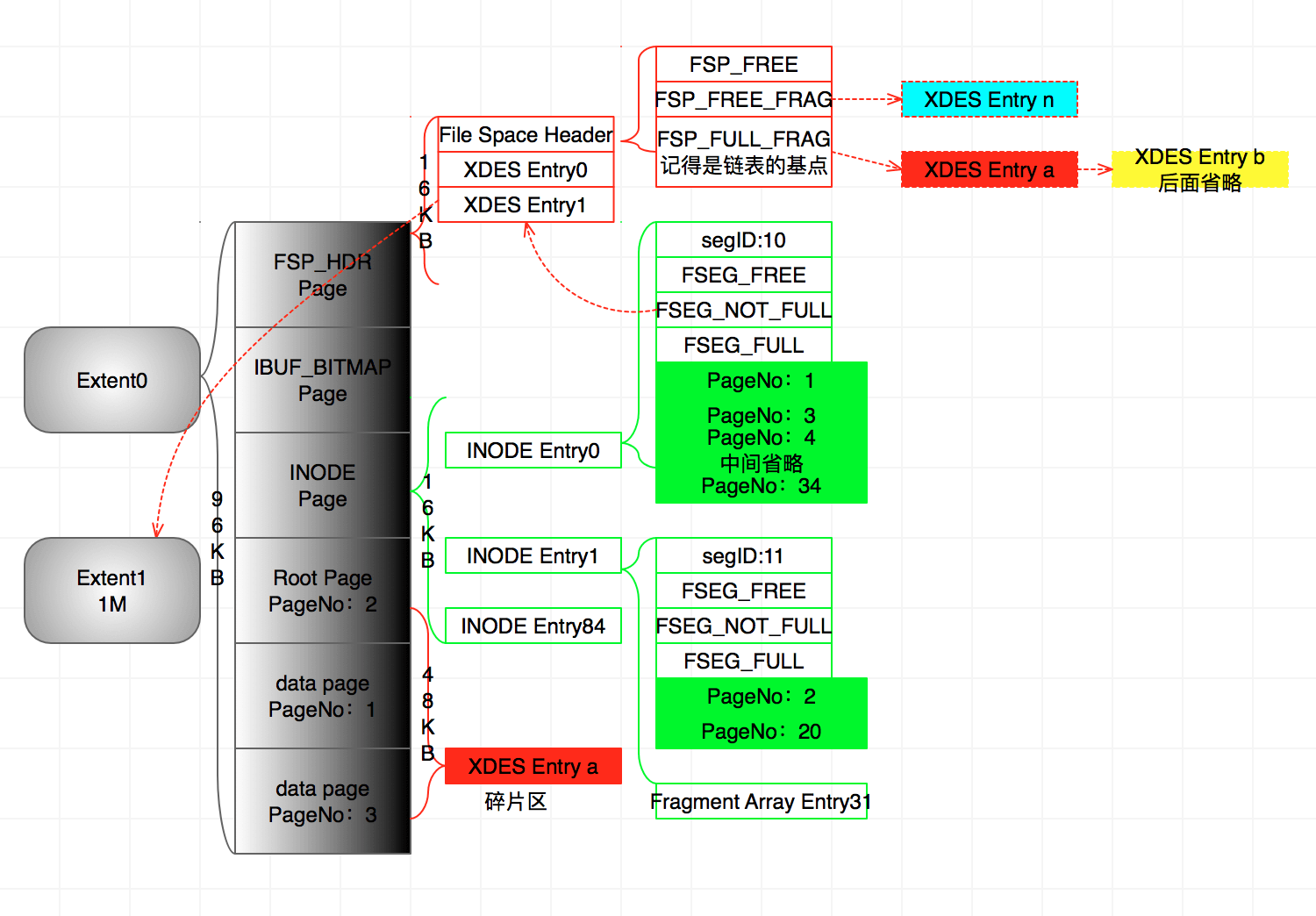
- 这里首先假设在继续插入记录的时候,还生成了一页索引页PageNo20,很容易想象。并且记录在了索引页。
- 由于碎片区会被一直消耗物理空间,所以表空间会一直去申请新的碎片区。至于是否每次都会以32KB申请需要实验。所以不难想象可能会生成碎片区XDES Entry c、d、e等。被用完的碎片区则会链接在FSP_FULL_FRAG链表(图中省略了)。最后新申请的可用碎片区XDES Entry n则被链接在FSP_FREE_FRAG。
- 由于INODE Entry0已经用满了32个Fragment Array Entry,所以可以申请完整的区使用。于是FSEG_FREE向FSP_FREE申请空间,FSP_FREE再申请1M的区Exten1然后分配给FSEG_FREE,并且由XDES Entry1描述Extent1。
- 继而FSEG_FREE将区XDES Entry1链接在FSEG_NOT_FULL链表。新插入的记录则写在了Extent1的Page。值得注意的是:Extent1的Page记录的全都是数据页,因为INODE Entry0是数据段。一个索引分为两段:数据段和索引段,数据段则是数据页区的集合。
至此,我想我已经把新数据插入涉及到的表数据结构的变化已经交代的明明白白,清清楚楚。
从图文分析的过程中,让我对碎片区的概念有了更深的了解。似乎感觉很对的样子。当然也都是个人猜测,有知道实际情况的希望不吝赐教。 继续验证碎片区的自扩展,往myTest数据表中继续插入数据,直到占满了XDES Entry b:
比之前的128KB多了16KB,在分析下myTest.ibd,得到:
可见碎片区的扩展并不是固定的啊!
Extent256组成
Extent256并不仅仅代表的是256,而是每组区的第一个区的前2页。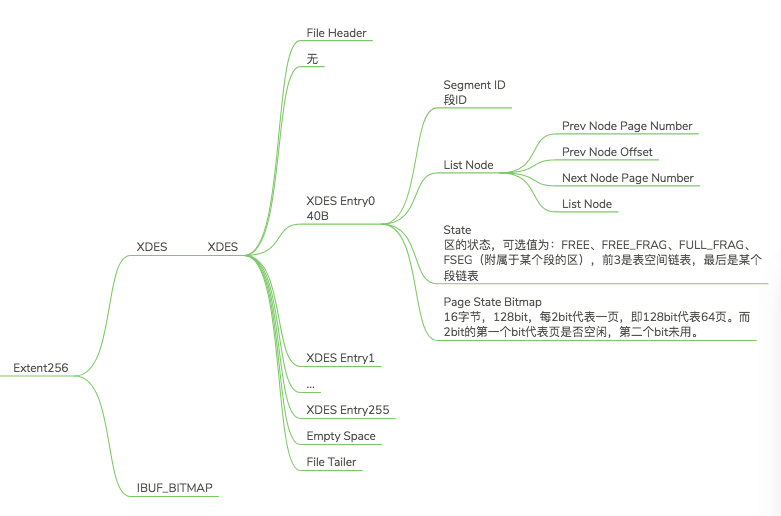
Extent0的前三页分别是:FSP_HDR、IBUF_BITMAP,INODE。
Extent256千2页分别是:XDES、IBUF_BITMAP。
Extent0可谓是比较特殊的了,因为在新建表的时候只有Extent0。所以在Extent0中记录了很多的数据。但是XDES也不难理解,由于在Extent0中该记录的指针啊什么的链表啊都已经记录了,所以接下来的Extent只用记录区组的描述即可。
到此,已经讲述完毕!
最后
最后还是得感谢我的领导斯哲大神的分享,让我在这个知识点上可以花更少的时间去学习和总结!
附件

若有收获,就点个赞吧
0 人点赞

{kind=link}