连表查询分析第一讲
create table `nba_odds_companys` (`id` int(11) not null auto_increment,`companyId` int(11) not null DEFAULT 0,`companyName` varchar(32) not null DEFAULT '',`if_used` tinyint(1) not NULL DEFAULT 0 comment '是否启用',`order` tinyint(2) not null DEFAULT 0 comment '排序',`sfUsed` tinyint(1) not null DEFAULT 0 comment'胜负是否抓取',`rfsfUsed` tinyint(1) not null DEFAULT 0 comment'让分胜负是否抓取',`dxUsed` tinyint(1) not null DEFAULT 0 comment'大小是否抓取',`create_time` datetime not null DEFAULT '0000-00-00 00:00:00',PRIMARY key(`id`),UNIQUE key `unq_companyId`(`companyId`),key `idx_order`(`order`))engine=innodb DEFAULT charset=utf8 auto_increment=1;create table `nba_sf_odds` (`id` int(11) not null auto_increment,`matchId` int(11) not null DEFAULT 0 comment'小炮NBA比赛ID',`sourceId` int(11) not null DEFAULT 0 comment'数据源比赛ID',`sourceName` varchar(32) not null DEFAULT '' comment'数据源描述:如盈球',`oddsId` int(11) not NULL DEFAULT 0 comment '赔率ID',`hostWinOdds` VARCHAR(6) not null DEFAULT '' comment'主队胜赔率',`awayWinOdds` VARCHAR(6) not null DEFAULT '' comment'客队胜赔率',`create_time` datetime not null DEFAULT '0000-00-00 00:00:00',`companyId` int(11) not null DEFAULT 0,`companyName` varchar(32) not null DEFAULT '',`loseRation` VARCHAR(10) not null DEFAULT '' comment '返还率',`winRate` VARCHAR(10) not null DEFAULT '' comment '主胜率',`loseRate` VARCHAR(10) not null DEFAULT '' comment '客胜率',`winKelly` VARCHAR(10) not null DEFAULT '' comment '主凯利指数',`loseKelly` VARCHAR(10) not null DEFAULT '' comment '客凯利指数',PRIMARY key(`id`),UNIQUE key `unq_matchId_companyId_sourceName`(`matchId`,`companyId`,`sourceName`),key `idx_oddsId`(`oddsId`))engine=innodb DEFAULT charset=utf8 auto_increment=1;
nba_odds_companys 这是nba的赔率公司,nba_sf_odds这是nba的胜负赔率。但是从胜负赔率中获取某个比赛的所有赔率还必须以赔率公司的顺序排序。对于原来我一贯的做法可能就是将大的查询拆分然后在业务层面处理逻辑。这也是优化的手段常用方法之一,但是每种方法都要在对的场景使用。
拆分查询
1、从胜负赔率中获取某个比赛的所有赔率(初盘)SELECT * FROMnba_sf_oddsWHEREmatchId=?;
2、从赔率公司获取所有关于胜负开盘的公司并且排好序SELECT * FROMnba_odds_companysWHEREsfUsed=1 ORDER BYorderASC;
3、遍历已经排好序的所有赔率公司,然后在将胜负赔率就号入座。
这里已知:胜负赔率公司有71家,所以开的初盘也有71个。最小代价就是先处理胜负赔率:将胜负赔率的结果格式化成 companyId=>array(“记录”), 然后遍历赔率公司的时候直接从companyId获取记录数据,然后将结果集返回。一共是71+71次的循环遍历。
内连接查询
select a.* from `nba_sf_odds` as a INNER JOIN `nba_odds_companys` as b where `a`.companyId=`b`.companyId AND `a`.`matchId`='261927' order by `b`.order ASC;
我们分析下这个SQL:
1、查询优化器会自动选择查询代价最小的查询方式:假设是以a表的matchId为索引查询,即nba_sf_odds作为驱动表(当然你也可以假设以b为驱动表,但是这里查询条件只有一个matchId,所以肯定是a为驱动表)。我们也看到了matchId是建立了唯一索引的UNIQUE keyunq_matchId_companyId_sourceName``,因此可以得到如下结果:
SELECT * FROM `nba_sf_odds` WHERE `matchId`='261927'; --可以得到71条记录SELECT * FROM `nba_odds_companys` WHERE `companyId`=?; --以驱动表的companyId为值查询
通过两个表的关联我们可以将两个表的记录关联在一起,但是最后是以被驱动表的字段排序,所以将联合的结果集暂存在临时表然后在进行文件排序。当然,这么说是因为我执行了explain语句。结果如下:
从a.Extra的结果即可得知用来临时表和文件排序。
倘若我不进行排序,那么结果将大不同,返回的速度也将更快,如:
explain select a.* from `nba_sf_odds` as a INNER JOIN `nba_odds_companys` as b where `a`.companyId=`b`.companyId AND `a`.`matchId`='261927';
得到结果如下:
那么查分查询和内连接查询到底谁更快呢?内连接虽然是查询了两个表,但是都是在引擎层完成的,而且数量也是71+71条,内连接的两次查询都用到了查询,所以在速度上肯定也更快。只是文件排序可能会稍微耗时。但是从可读性来讲,我更喜欢第二种。当然为了更大的优化,其实可以将a.*改成具体需要的输出字段。
实际开发后续
如上连表查询没有任何问题,但是在接口返回中需要返回当前赔率的最新开盘,于是我还必须去变盘表里面找寻最新的变盘。变盘表如:
create table `nba_sf_change`(`id` int(11) not null auto_increment,`matchId` int(11) not null DEFAULT 0 comment'小炮NBA比赛ID',`sourceId` int(11) not null DEFAULT 0 comment'数据源比赛ID',`sourceName` varchar(32) not null DEFAULT '' comment'数据源描述:如盈球',`oddsId` int(11) not NULL DEFAULT 0 comment '赔率ID',`hostWinOdds` VARCHAR(6) not null DEFAULT '' comment'主队胜赔率',`awayWinOdds` VARCHAR(6) not null DEFAULT '' comment'客队胜赔率',`create_time` datetime not null DEFAULT '0000-00-00 00:00:00',`changeTime` VARCHAR(20) not null default 0 comment '时间戳',`timestr` varchar(10) not null DEFAULT '' comment '距离比赛开始时间',`md5` varchar(64) not null Default '' comment 'md5(oddsId,homeWinOdds,awayWinOdds,changeTime)',`loseRation` VARCHAR(10) not null DEFAULT '' comment '返还率',`winRate` VARCHAR(10) not null DEFAULT '' comment '主胜率',`loseRate` VARCHAR(10) not null DEFAULT '' comment '客胜率',`winKelly` VARCHAR(10) not null DEFAULT '' comment '主凯利指数',`loseKelly` VARCHAR(10) not null DEFAULT '' comment '客凯利指数',PRIMARY key(`id`),unique Key `unq_md5`(`md5`),key `idx_matchId_sourceName`(`matchId`,`sourceName`),key `idx_oddsId_changeTime`(`oddsId`, `changeTime`))engine=innodb DEFAULT charset=utf8 auto_increment=1;
为了能够快速获取最新变盘,于是建了idx_oddsId_changeTime索引。但是从上面连表分析可知要循环71次,所以如果在循环中去获取最新变盘也要71次查询。我先看看每个查询的时间: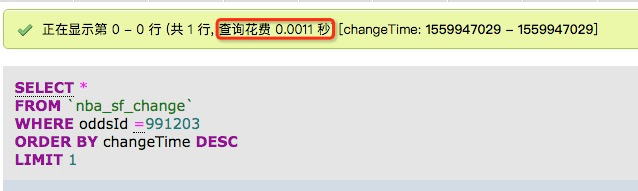
可见似乎并不需要多久,如果是71*0.0011也几乎可以忽略。但是实际情况并不是这样,因为每次查询还有连接数据库走的网络开销,于是最终一个请求的响应时间是5s多!真慢!时间都花哪里去了呢?通过xhprof工具查看可知数据库花了4.4s。简直不能接受!!(看到的141次调用是系统的一些其他调用一共加起来有141次。)
那么优化的方案肯定是减少查询最新变盘的次数了!
第一种方案:以空间换时间
在数据库的初盘表中,增加最新盘的字段。然后每次在刷新最新盘到变盘表中的时候,也同步刷新到初盘表中。这是一个非常好用的办法!
第二种方案:优化处理逻辑
原本查询最新的变盘SQL是:SELECT * FROMnba_sf_changewhere oddsId=991203 order bychangeTimeDESC LIMIT 1,可是怎么批量查询呢?
1、(SQL1) UNION (SQL2) 可行!,将71个SQL都union起来了,8-)
2、GROUP BY oddsId,不行!
3、oddsId in( a,b,c,d ) 但是也是无法从变盘中刷选。!
现在接口的请求时间从5.3s变成了1.48s,算是提高了3倍多。可是还是觉得很慢,为什么呢?查看xhprof可知:

两次连接和四次查询。其实这里已经很优化了!所以我只能靠打缓存了!

若有收获,就点个赞吧
0 人点赞
