
这篇文章,旨在给一些好友分享,希望他们在这方面能够有些了解。也是自我的一次总结。我会通过不断的给自己提问来总结自己遇到的问题。希望对你有帮助。
在开始之前,我觉得有必要讲述一些InnoDB的一些基本概念。我们在面试的时候或多或少被提问过:InnoDB和MyISAM的区别。我们一般会说:MyISAM是表级锁,InnoDB是行级锁;MyISAM是以读为主,而InnoDB是以写为主。InnoDB支持事务,而MyISAM不支持。然后面试官会再问关于一些MySQL索引的问题和如何优化的问题。如我最初的回答其实就是基于在书上看到的一些实战内容,并未从内部原因去分析。当然也不知道。可是,一味的只从别人的嘴里或者实战的书籍获取这些表面的功夫,对我们来说仅仅只是学会用而已。所以我希望通过这篇文章能够让你对MySQL的InnoDB的内部原理也有所了解并且激发你们的兴趣去深入阅读。
文中很多地方的图都不一定是连贯的,因为没有系列性的做例子举证。倒是这些图也可以说明些什么,于是就用了。
文章覆盖目录:
- 表空间
- 数据行
- 页
- 区
- 段
表空间
- 系统表空间
- 独立表空间
说起表空间,即使我们似乎不太了解,但是却肯定有所接触。在我们刚开始安装MySQL的时候,就会提示我们指定MySQL的存储数据目录,当然如果不指定也会有默认的一个位置。
这就是我本地的MySQL存储数据目录。在data中会有我创建的很多的数据库,如phpcms。注意到ibdata1这个则是InnoDB的系统表空间,或称为共享表空间。
除了系统表空间外,每个数据表也有自己的独立表空间,以数据库test为例,它的独立表空间即test.ibd。
这里对test.frm和test.ibd做个介绍:
test.frm:数据库test的元数据,和数据引擎的类型无关。
test.ibd:数据库test的独立表空间,其中存储的主要是test数据表的数据。
这里需要注意的是:即使我们使用了独立表空间,但是有些数据依然会存在系统表空间内。
以上可以知道,表空间可以分为系统表空间和独立表空间,但是我们的InnoDB选择的是哪一个表空间呢?可以通过 show variables like 'innodb_file_per_table%';命令得到,如: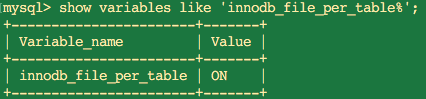
InnoDB默认启用了独立表空间,如果我们要选择系统表空间,已创建的数据表不会改变,只对新建的表起作用。
现在我们知道表空间是什么了。
行
- 行格式
- 行溢出
从大的方面我们已经知道表空间是什么了,所以接下来我要从表空间的数据行开始讲解,因为这样会更容易讲述和被理解。
我们存储的记录在InnoDB中的独立表空间中,是以二进制的形式存储的。想象一下那么多的数据存储在一个文件中,InnoDB是如何高效的查询并获取这些记录呢?
这里我要插入一个有意思的事情,那就是独立表空间的内容分析。 首先,看下test表结构: CREATE TABLE
test(idint(11) NOT NULL AUTO_INCREMENT,namevarchar(12) NOT NULL DEFAULT ‘’, PRIMARY KEY (id), KEYidx_name(name) ) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;再而,看看表数据:
+----+--------------------------------------+| id | name |+----+--------------------------------------+| 1 | abcdefghigk || 2 | abcdefghigkl || 3 | 我爱中国。 || 4 | 我爱中国。我是中国人! || 5 | 我爱中国。我是中国人!! |+----+--------------------------------------+
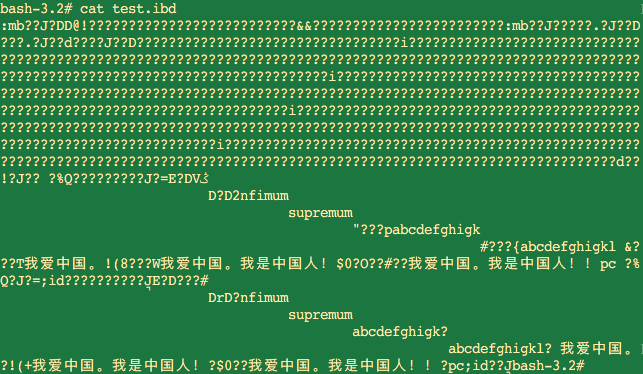
最后看看test.ibd,结果显示的是一段乱码:
之前有说过test.ibd是由二进制文件,可是怎么有中文和英文还可以显示呢? 注意到test表结构的字符编码是utf8,而shell的默认字符编码也是utf8,cat命令打开的文件即使是二进制文件,但是打开的编码格式是以utf8打开的,而行数据存储到ibd中也是以utf8存储的。这就不难理解了为什么有中文和英文显示了。 为了便于理解,我们使用命令将二进制文件输出成16进制文件,然后再看输出将如以下:
hexdump -e '16/1 "%02X " " | "' -e '16/1 "%_p" "\n"' test.ibd > test.txt详见:https://man.linuxde.net/hexdump当然这只是部分截图,更多的内容就不展示了。而且这里值得一提的是,InnoDB的行数据结构其实就是存储在这些二进制文件中,通过格式化的文件也可以推断出行数据,根据行数据的数据结构存储也可以找到行之间的关系。这里不一一展示,但是感兴趣可以通过分享的PDF自行了解。关于MySQL的字符编码感兴趣的同学也可以自行了解下。
上面已经交代了数据行的数据存储形式了,可是如果只知道数据形式,而却不知道如何分析数据那么也无用。因此接下来就是介绍行的数据结构。
行格式首先就分为了多种,5.0之后用的是Compact,5.0之前用的是Redundant。行格式的差异主要表现在期数据结构的不同。好比我们为了保存1这个字符,我们可以用字符串表示,也可以用数值表示,可以用二进制表示也可以用十进制表示。行格式也即如此,你可以用compact记录这一行的数据,也可以用redundant记录这行的数据。但是不管用哪种方式,目的都是一样。但是InnoDB最终的目的肯定是朝着更加节省空间和更加快速的数据结构前进。
Compact格式

通过以上的2张图片介绍,我们即可知道行的数据结构。通过这个数据结构的每个字段所占用的固定空间大小,我们就可以得到表示行数据的记录头信息。以下挪用书上的一个栗子作为介绍:

这个图旨在让大家对行数据的存储有个概念,并不要求说要学会如何推断出数据的内容。但是值得注意的是:
- 1KB=1024B,1B=1byte,1byte=8bit,在上图中的每2个数,即表示1B。
- 在列中的值包含有3个隐藏的列字段:rowID(6B),TransactionID(6B),Roll Pointer(7B)。
- 变长字段长度列表和NULL值列表是逆序的,思考下为什么要逆序呢?从以下的描述中可以得到答案。
- 记录头信息中的next_record是相对偏移量,占用记录头信息的2B,如第一行记录的头信息next_record是00 2c,用16进制表示即:0x002c。当前的位置是:0x0080,所以下一个next_record的位置是:0x0080+0x002c=0x00ac,找到00ac的位置即:2b所在的位置。从这个位置往前数5个字节,即是行记录的头信息。再往前数一个字节,即表示NULL值列表,如果为00即表示没有NULL值。数据表的字段是4个,除去一个char类型所以剩余3个字节,再往前数3个字节即各个字段的长度。这里注意到我们用到了条件“数据表的字段长度是4,并且其中varchar的是3个,char的是1个”,这种信息我们称为元数据,他存储在共享表空间中。并且通过
information_schema我们也能查到这些信息。 - 通过next_record我们就能将所有的行记录串起来,形成单向链表。
- 可是如果记录中有字段是NULL值怎么办?如上述的最后一行即有NULL值。根据上面的例子找到next_record的位置,然后NULL值列表是06,用二进制表示为:0110,显而易见表示中间的2个字段是NULL值,因此变长字段是2,则再往前找2个字节即:可变字符长度列表。
- 通过以上的分析,有没有得到答案:为什么变长字段长度列表和NULL值列表是逆序的?
似乎并不难,也的确InnoDB在表空间中就是如此存储的。当然其中头信息还是有很多可以值得推敲的字段。
Redundant格式
Redundant格式和Compact格式的不同点在于Compact记录的是变长字段长度列表,而Redundant记录的是字段长度偏移列表。还有就是细微的字段占用字节数不同。这里不做介绍,感兴趣可以自己看看PDF的案例。
行溢出
页的大小就16KB,而且一页至少要有2个记录(除了最小记录和最大记录),硬性规定最多是16KB/2-200=7992行记录。
字段长度小于255用1字节表示,大于255用2字节表示长度。2字节即2^16=65536-1,但是除去一些额外占用的字节,其实VARCHAR最大长度只能是65532字节。不同的编码占用的字节不同:latin1占用1字节,utf8占用3字节。所以不同编码可能占用的最大长度是不同的。
保存长文本内容的情况比比皆是,类似text,medium text,long text,blob 等。所以在处理长文本内容的时候,InnoDB是如何处理的呢?
行溢出即是处理这种长文本引入的概念。
Compact格式和Redundant格式在统称为Antelope文件格式,新的文件格式称为Barracuda。Barracuda文件格式下拥有两种新的行记录格式Compressed和Dynamic两种。Barracuda文件格式和Antelope文件格式的不同之处就在于行溢出的处理方式。
Antelope文件格式处理行溢出的方式是在页内放入768个字节和指向其他页的地址。而Barracuda文件格式处理行溢出的方式是仅在数据页内存20字节的地址,指向blob page页面。
页
- 业数据结构
- 槽点
- 页分裂
- 行分裂
- B+树
也称之为“块”。页的大小一般是16KB。以下会贴出关于页相关的一些截图,我们先简单的过一下,然后有点印象。在后面的讲解中在通过不断的刺激从而熟悉。
页的数据结构
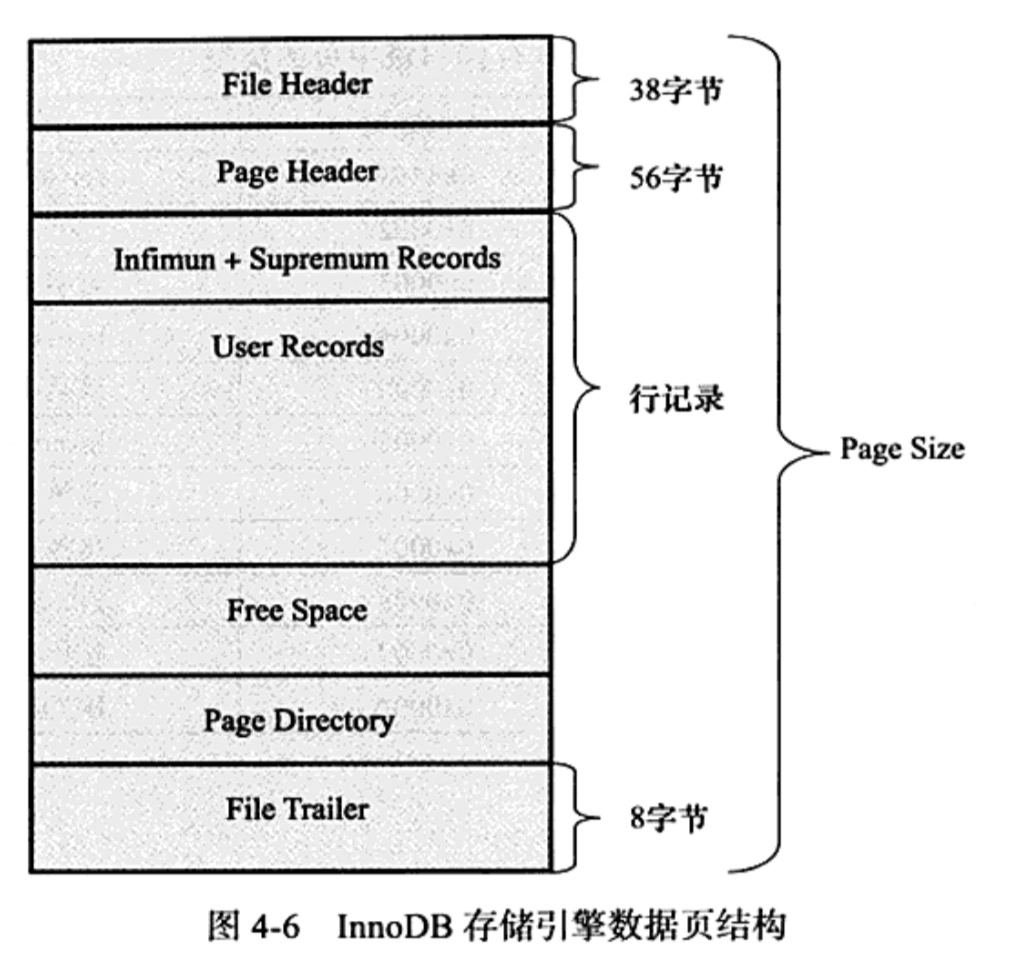
File Header说明
页与页之间即是通过File Header实现页与页之间的双向链表。
页类型枚举
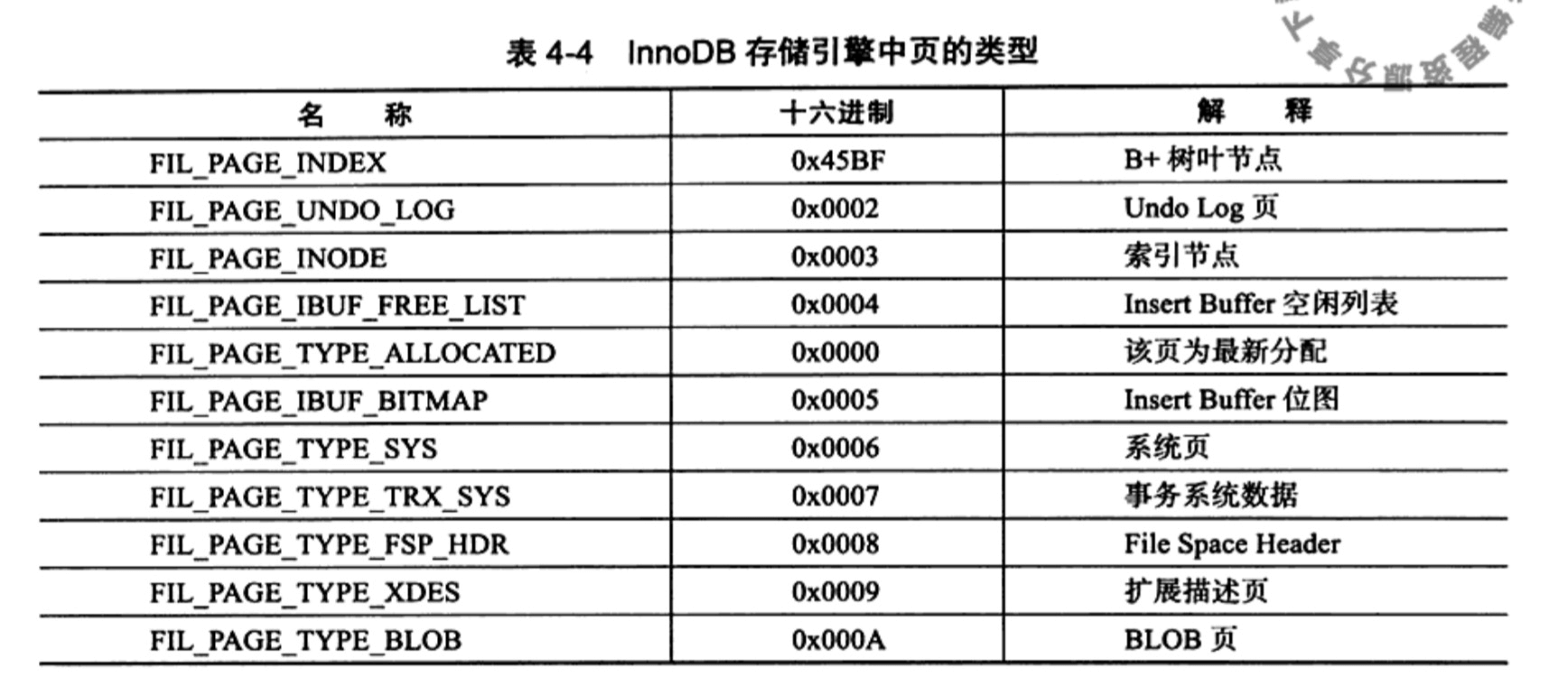
Page Header组成部分

以上都贴出来了页相关的一些数据结构和相关的字段说明,我们不必要现在将它拿下,只是知道就好。等通过慢慢的讲解后,再回过头来看看页的数据结构,你会更加清晰。
开始
我们的行记录实则存在页的User Record字段。新建表即使我们没有插入任何记录,一开始在表中也会有2行记录,即最小行和最大行:Infimum和Supermum。行与行之间的关系如下: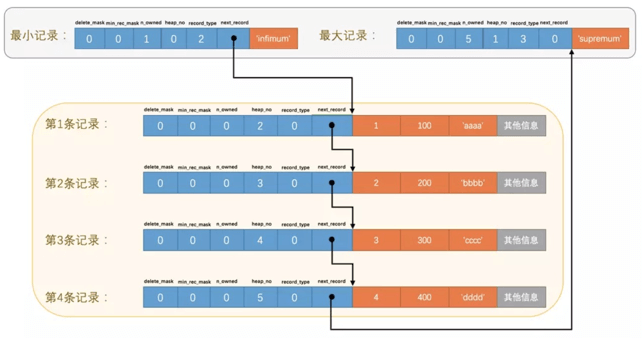
我们可见,最小记录永远是第一条记录,并且连接着下一条记录,直到最大记录。通过这个单向链表我们即可完成全表扫描。可是有没有更高效的方式呢?当然有,比如引入槽点。
槽点(Page Directory)
槽点的意思有点像是行目录,类似书本页码的目录。我们通过页码目录即可快速找到某篇文章对应的页码。同理我们通过槽点即可快速定位行所在的位置。槽点的结构图如下: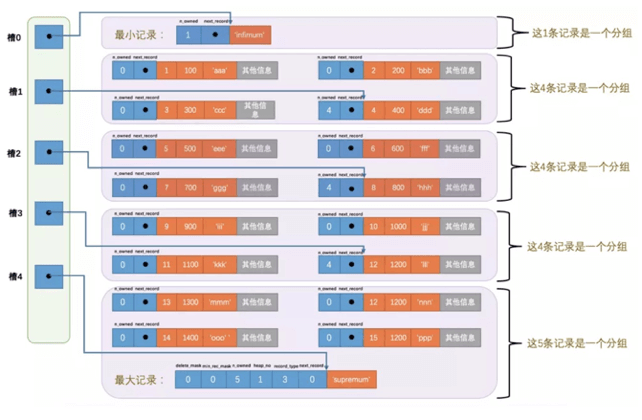
槽点记录的是行分组内最大记录数的相对位置。注意:不是相对偏移量,是相对位置。
假设我们搜索id=3的记录,通过槽点我们即可通过二分法快速定位到id=3所在的范围,然后在范围内遍历。
那么,槽点是记录在哪里呢?没错,就是页目录含义的字段:Page Directory。那么,页在表空间中是如何存储的呢?见下图(PDF上的部分截图):
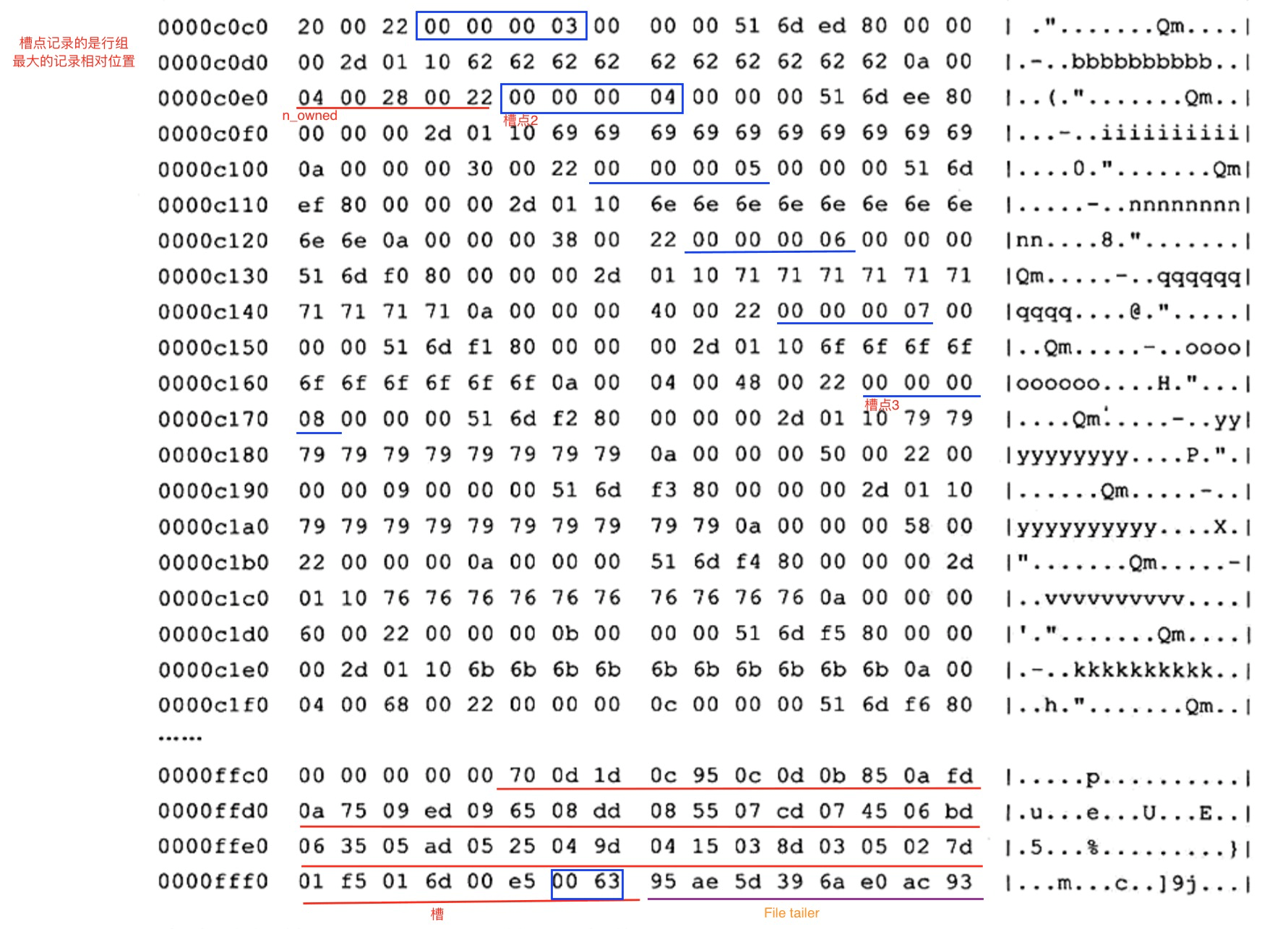
见图中的页目录:Page Directory,在File Tailer之前。所以在页尾往前数8个字节即是Page Directory。页目录存储的槽点列表也是逆序的,显而易见。0x0063即最小记录,0x00e5即第一个行分组的最大记录相对位置,以此类推。找到每个槽点之后,即可找到rowID。通过二分法查找即可快速定位,然后在遍历即可。
举例说明:我想找id=5的记录。通过槽点分析后我们可以找到id=5在槽点2和槽点3之间,即4和8之间。于是从4开始遍历,即可找到id=5的记录。
这里有必要介绍下行分组是什么?
从以上我们知道槽点记录的是行分组内最大记录数的相对位置,因此我们可以认为多个行可以分为一组。见截图:
槽很好的解释了行的n_owned字段,这个字段说明的就是这个行分组共拥有多少条记录。见槽点2往前数5个字节。
这里值得注意的是:最小记录Infimum的n_owned值总为1,最大记录Supermum的n_owned的取值范围为[1,8],其他用户记录n_owned的取值范围为[4,8]。这是为什么呢?
这里不得不提的就是关于行分裂概念了:最开始的时候表空间中只有最小记录和最大记录,最小记录永远是独占一组,而最大记录会随着记录的增加渐渐的增多,最多到8行。当在插入记录的时候,就可能导致行分裂了,这时最大分组就会分成2组,每组4个。然后在将新的记录放到最大分组或中间组(视情况而定)。由此就可得出以上每个分组的范围限定了。
页分裂
页与页之间通过File Header实现双向链表,如图: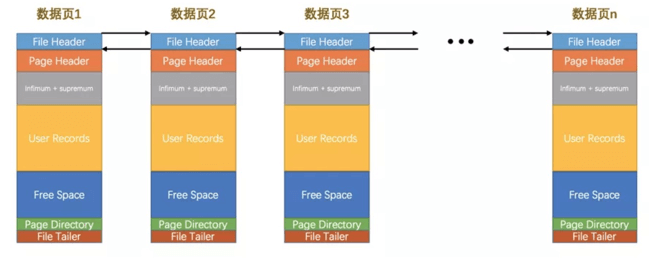
用户记录存在User Record,假设某页的数据已经满16KB了,这时继续插入数据。那么可能就会出现页分裂。页分裂是需要尽可能避免的,因为产生页分裂可能需要耗费大量的时间处理。这既是为什么我们一般都会创建一个自增主键的原因。行分裂同理也是需要尽量避免的。
B+树
想象一下,如果我们的数据量特别大,那么数据页肯定特别多。这种情况下,如果我们需要查找某一个记录,该如何处理呢?
类似于数据行和页之间的处理:将页的页号(PageNo)提取,在将该页最小记录(即数据行标记为min_rec_mark的记录的最小主键值ID)提取,所以我们可以得到如下图: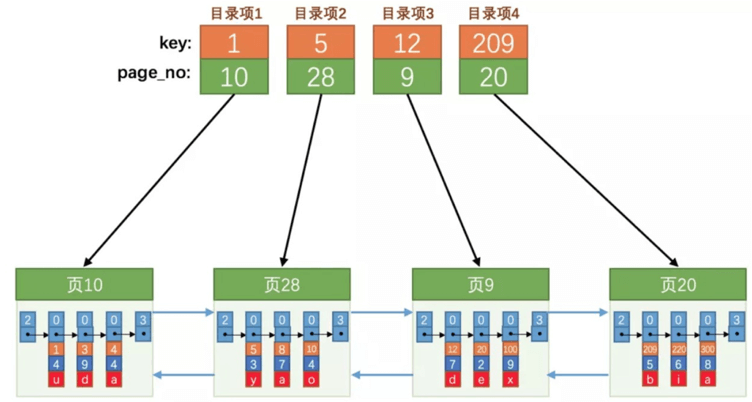
以页10为例:橙色部分的1、3、4是主键,指针指的是next_record,20003指的是record_type。将4个数据页聚在一起然后形成新的非数据页,我们称之为“非叶子结点”。数据页我们一般称之为“叶子节点”。
如此,将很多个叶子节点都按这种形式即可得到B+树,如下图:
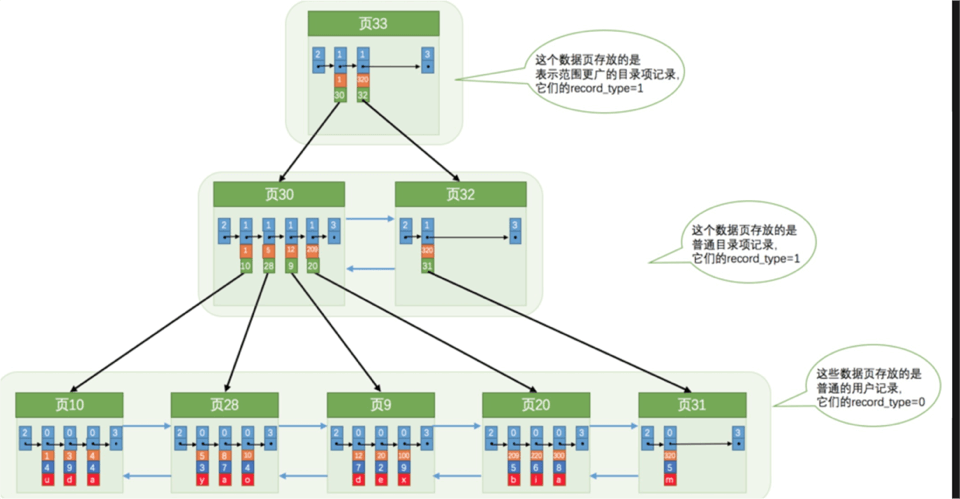
这里有几点值得注意:
- 页与页之间的双向链接实则是通过
File Header的**FIL_PAGE_PREV**和**FILE_PAGE_NEXT**实现。这两个字段实则指的是上一个页号和下一个页号。甚至你会发现,InnoDB数据结构之间几乎都是如此实现的。可是直接记录页号就能找到对应页码存储的内容了吗?
猜测:在InnoDB的内存中,维护着类似页码和物理空间的映射关系。通过这个映射关系可以快速定位到页的物理空间位置。 - 头结点的位置是永远不会变化的,因此在InnoDB中肯定记录了这个位置的实际位置。
现在知道B+树长什么样子了,那么如果在让你去搜索id=4的记录时,又是怎么查找的呢?
- 从根节点开始槽点二分法查找,在页30。
- 在页30通过槽点二分法继续查找,在页10。
- 在页10通过槽点二分法继续查找,找到所在组范围在遍历查找。
通过以上对行、页以及B+树的简单分析,我想我们对InnoDB的数据的查询肯定有些猜想。那么在我们在查询的时候,InnoDB具体都做了些什么呢?
索引
说到数据库的索引,我们是再熟悉不过了。从开始学习MySQL就一直听到的词,面试也经常被问到的热区。可是为什么面试官这么喜欢问呢?
在MySQL开始真正查找你写的SQL之前,MySQL会先去分析你写的SQL,然后构建查询的SQL,最终才去执行SQL。在构建分析的过程中,MySQL会评估最小代价,到底使用哪种策略才是最简单呢?这就是为什么有些时候明明我对某个字段加了索引,但是MySQL却不用的原因。很可能就是全表扫描的代价更小。这些都是查询优化器的工作。
查询优化器:在查询优化器开始工作之前,都会对需要查询的条件进行一些随机采集,然后得到一些数据。这些数据就是为后面的分析做准备。如果倾向于越多的数据回表查询那么可能就用全表扫描,反之用索引。
单表查询的快慢排序:
| const | ref/ref_or_null | range | index | index merge | all |
|---|---|---|---|---|---|
>const:主键查询,或者不含Null的唯一键查询。const即等值匹配查询。在表中只有唯一对应。
- select * from t where
id=1; - select * from t where
uniqueKey=2;
>ref:二级索引的等值查询,但是表中可能存在多条记录对应。
- select * from t where
key1=1; - select * from t where uniqueKey=2 or uniqueKey is null;
>ref_or_null:查询的结果中包含有null值
- select * from t where key1=1 or key1 is null;
>range:在能用到索引的情况下范围查找。
- select * from t where key1 in(1,2,3);
>index:查找的字段在二级索引中即可满足,无需回表,却又无法使用索引。
- 如select key_part2 from table where key_part2=’’;
>index merge:索引合并查询,即多个索引等值查询(主键除外)。如:
- select * from table where key1=’a’ and key2=’b’;
- select * from table where key_part1=’a’ and key_part2=’b’ and key_part3=’c’;
- select * from table where key1=’a’ and
id>100;
>all:全表扫描,直接在聚簇索引上面对叶子节点进行全表扫面。
回表的代价
一个索引即占一个B+树,增删改对索引都会有所影响。所以理论上讲不是越多个索引就越好,一般控制在5个。
聚簇索引:索引即数据,数据及索引。对主键查询即是在聚簇索引的B+树上进行搜索。因为聚簇索引上的叶子节点包含所有的字段,所以在聚簇索引上搜索即可得到所有的字段。
二级索引:在唯一索引或者其他二级索引进行搜索,除非是index搜索或者覆盖索引搜索,否则都需要回表。回表即回到聚簇索引查找叶子节点获取查询的字段值。
回表代价是查询优化器在进行搜索时的考量之一。这也就是说为什么我们在搜索的时候尽可能少的去搜索需要的字段,这样回表的代价也会更少。
连表
- 内连接
- 外连接
- 左连接
- 右连接
- 外连接中WHERE和ON的区别
连表查询是我比较避讳的事情,因为不好的连表查询可能给数据库带来一场灾难。在实际开发中,我也尽可能少的(几乎没怎么用)去用连表查询。然而,这是一个错误的概念。好的连表查询可以比分两步查询更快,关键就是索引。连表查询对于我们来说是有点难度的,因为不爱用。趁这次克服它。
连表查询第一反应想到的就是笛卡尔积,如
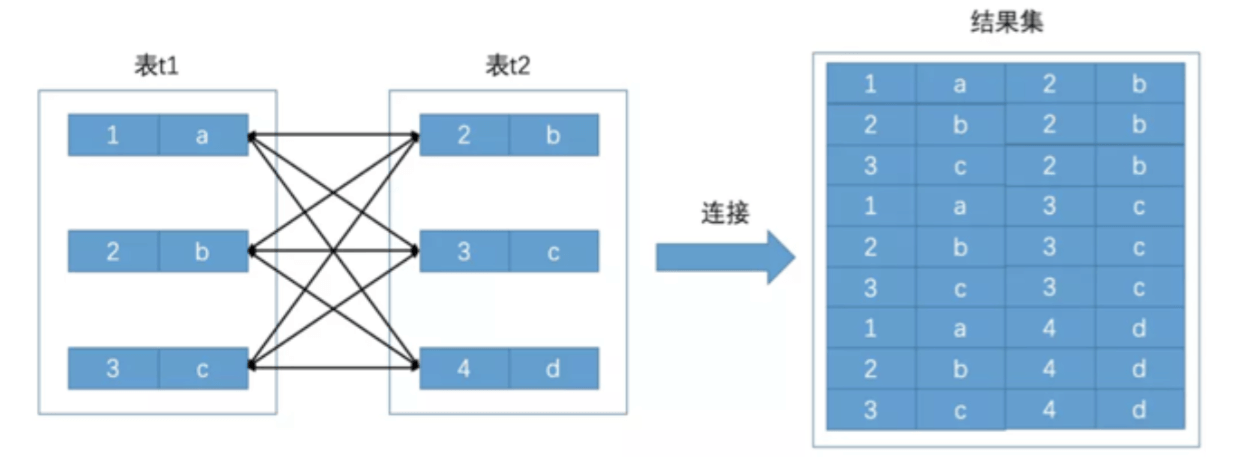
这种情况我们应该尽量去避免,因为线上的数据量如果很大,笛卡尔积可能直接导致宕机。
连表查询还分为:内连接、外连接。
外连接分为:左外连接和右外连接。
内连接
内连接的概述见图,其中两个圈的交集即是内连接的结果: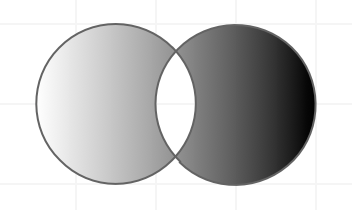
SQL如:
- SELECT * FROM t1,t2 WHERE t1.id=t2.id;
- SELECT * FROM t1 inner join t2 WHERE t1.id=t2.id;
- SELECT * FROM t2 inner join t1 WHERE t2.id=t1.id;
这样我们就可以得到结果:
2 b 2 b
3 c 3 c
注:内连接查询只要都能用到索引,速度是很快的哦~
查询分析器在处理内连接查询的时候,会通过分析最小代价从而确定哪个表可以作为驱动表或被驱动表。我们一起去分析一下吧! explain上面的三句SQL分析得到的结果是一致的,如:
而且很明显在myTest中全表扫描只有4条记录,而在myTest2中全表扫描有1000条记录。不言而喻就能发现代价小的是以myTest为驱动表。倘若有更复杂的查询如: SELECT FROM myTest,myTest2 WHERE (myTest.name=a OR myTest2.name=’b’) AND (myTest.id=myTest2.id OR myTest2.id=3) AND (myTest2.name=’r’ AND myTest2.name=’g’); 乍一看觉得很复杂,可是查询分析器是如何处理的呢? 1、首先假设myTest为驱动表作为分析: (myTest.name=a OR myTest2.name=’b’) 简化成 (true OR true) => true 。 (myTest.id=myTest2.id OR myTest2.id=3) 简化成 (myTest.id=myTest2.id OR true) => true (myTest2.name=’r’ AND myTest2.name=’g’) 简化成 (true AND true) => true; 即最终是:**SELECT FROM myTest,myTest2 WHERE true; —true and true and true 2、再假设以myTest2为驱动表: (myTest.name=a OR myTest2.name=’b’) 简化成 (true OR true) => true 。 (myTest.id=myTest2.id OR myTest2.id=3) (myTest2.name=’r’ AND myTest2.name=’g’) 简化成 (true AND true) => true; 即最终是:SELECT FROM myTest,myTest2 WHERE (myTest.id=myTest2.id OR myTest2.id=3);
* 这纯粹是为了举例子而举例子,大概了解分析的过程就好了!
外连接
SELECT FROM t1 left|right [outer] join t2 *ON** 连接条件 [WHERE 普通过滤条件];
外连接分为左连接和右连接。左连接是以左数据表为驱动表,右表为被驱动表。右连接刚好相反。图形如:
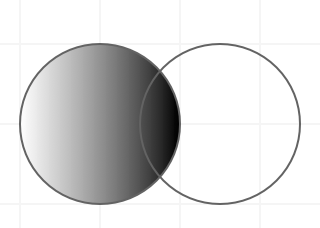 左连接
左连接 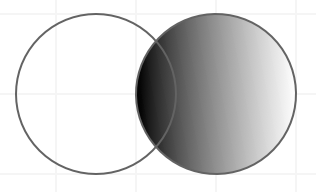 右连接
右连接
左连接SQL如:
SELECT * FROM t1 left join t2 WHERE t1.id=t2.id; ~~【报错】~~- SELECT * FROM t1 left join t2 ON t1.id=t2.id [where 1=1]; 【正确】
得到结果:
1 a null null
2 b 2 b
3 c 3 c
WHERE和ON到底有什么区别呢? ON 是专为外连接驱动表中的记录在被驱动表找不到匹配记录时应不应该把该记录加到结果集这个场景下提出的。什么意思呢?ON是连表条件,WHERE是普通过滤条件。猜想:先通过WHERE过滤数据后在通过ON过滤。 ON在内连接中和WHERE是等价的。
我在本地库创建了多个数据表myTest、myTest2、myTest3,表结构一致id(主键),name。其中myTest和myTest3只有4条记录,myTest2有1000条记录。数据分别如下: CREATE TABLE
myTest(idint(11) NOT NULL AUTO_INCREMENT,namevarchar(20) NOT NULL DEFAULT ‘’, PRIMARY KEY (id) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;myTest:1 a、2 b、3 c、4 d myTest2:id 1-1000,name:t myTest3:1 a、2 b、3 c、4 d
1、explain format=json select from myTest left join myTest2 ON myTest.id=myTest2.id;
可见,左连接查询myTest和myTest2时分了2次查询,先在myTest中全表扫描,然后得到结果1,2,3,4。再通过得到的结果在myTest2中做*eq_ref(相当于const)查询。eq_ref是只有连表查询中才有。
改造下: explain select * from myTest left join myTest2 ON myTest.id=myTest2.id WHERE myTest.id=4;
可见myTest和myTest2都是单表查询,后在处理查询的结果。(之前以为都是以eq_ref的情况出现,但并非是)
2、explain select * from myTest left join myTest3 ON myTest.id=myTest3.id;
可见,左连接查询myTest和myTest3时分了2次查询,先在myTest中全表扫描,然后得到1,2,3,4。再在myTest3中全表扫描。即使myTest3中有建立索引,但是并没用。并且在extra中可见还用了join buffer。
通过以上的分析,可以得知:外连接查询必然有一个会有全表扫描。另外一个则是视情况而定了。但无论如何,比内连接查询肯定是要慢的。
从此以后我不在惧怕内连接和外连接了[假的,还是很怕!]。你呢?
连表原理
连表的原理分为三种:
- 嵌套循环连接(Nested-Loop Join)
- 使用索引加快连接的速度
- 基于块的嵌套循环连接(Block Nested-Loop Join)
嵌套循环连接
先查询驱动表得到结果集,然后遍历结果集并且可能结合一些查询的条件进行搜索。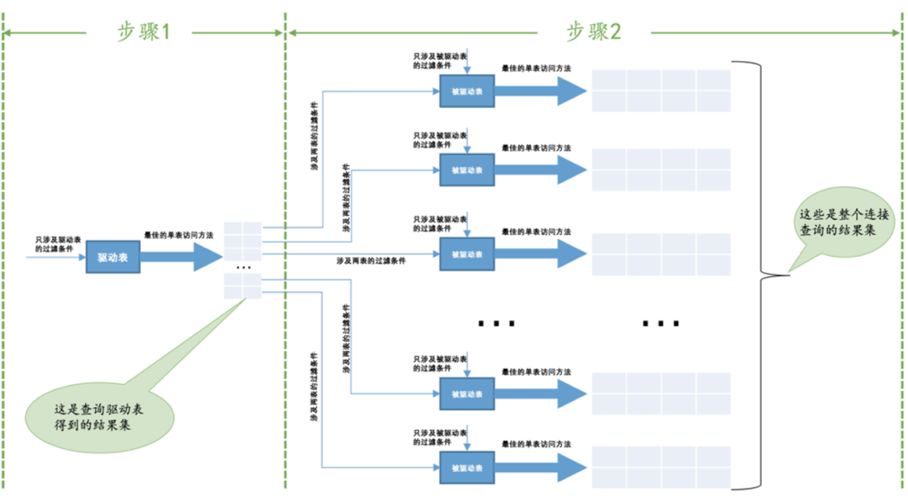
使用索引加快连接的速度
连接查询使用索引的例子其实在前面已经遇到过了,如:
- SELECT * FROM t1,t2 WHERE t1.id=t2.id; —这里是用了聚簇索引
create table t1 (`id` int(11) auto_increment,`name` varchar(20) not null default '',`age` int(3) not null default 0,primary key(`id`))engine=innodb default charset=utf8 auto_increment=1;create table t2 (`id` int(11) auto_increment,`name` varchar(20) not null default '',`age` int(3) not null default 0,primary key(`id`))engine=innodb default charset=utf8 auto_increment=1;insert into t1 values(1,'zs',15),(2,'zy',26),(3,'zz',20);insert into t2 values(1,'zs',30),(2,'zy',18),(3,'zz',19);s
查询SQL:SELECT * FROM t1,t2 WHERE t1.name like ‘z%’ AND t2.age<20 AND t2.name=t1.name;
此时没有任何索引,所以查询使用了Block Nested-Loop Join。
加上索引:
- alter table t1 add unique key(
name); - alter table t2 add unique key(
name);
添加索引后,我们再继续分析查询分析器如何分析SQL:
1、假设以t1为驱动表:
SELECT FROM t1,t2 WHERE t1.name like ‘z%’ AND true AND true;
[通过索引或者全表扫描]得到的结果是:zs,zy,zz
[全表扫描]在继续查找t2:select FROM t2 WHERE t2.age<20 AND t2.name='zs'; 依次类推查询3次。
2、假设以t2为驱动表:
SELECT FROM t1,t2 WHERE true AND t2.age<20 AND true;
[全表扫描]得到:zy,zz
[通过唯一索引]再继续查找t1:SELECT FROM t2 WHERE name=’zy’; 依次类推查询2次。
最后通过explain分析得到是第二种情况:
块的嵌套循环连接
在上述的例子中,已经出现了Block Nested-Loop Join,那么何为块的嵌套循环连接呢?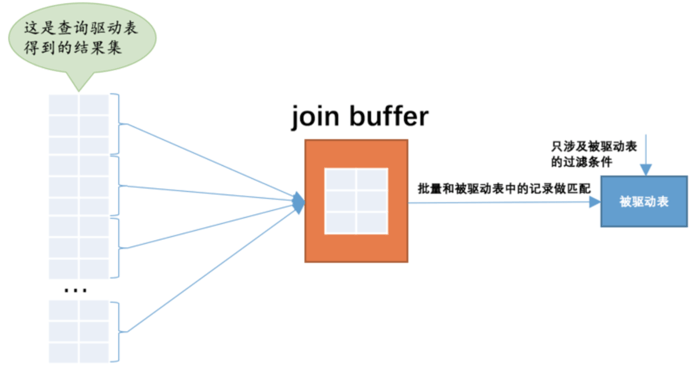
分析SQL(name没有唯一键之前):
SELECT * FROM t1,t2 WHERE t1.name like ‘z%’ AND t2.age<20 AND t2.name=t1.name;
1、先通过t1全表扫描,得到结果:zs,zy,zz
2、将zs,zy,zz加入到内存 join buffer中
3、然后将整个结果集到t2去查询。
猜想:到底这个查询的过程是什么样的呢?
- 类似SQL:SELECT * FROM t2 WHERE t2.age<20 AND t2.name in(‘zs’,’zy’,’zz’);
总结
- 尽可能的避免:回表查询。
- 尽可能的:覆盖索引查询,只查询需要的字段。
- 连表查询尽可能:用内连接查询,能够用到索引,只查询需要的字段。
- 索引最多建立5个,主键有序递增。
- 熟练能够使用索引的方法,避免一些错误的使用导致索引失效。
最后,感谢斯哲大佬的分享,让我们受益匪浅!!!
附件

若有收获,就点个赞吧
0 人点赞

{kind=link}