基础知识
数据的分类
- 数值型数据
- 表示大小或多少的数据
- 例子:年龄、年购买量
- 数值型数据分析方法
- 最小值和最大值:查看这两个值的目的是为了能够确定一组数据的上界和下界。
- 平均值:平均值可以反映一组数据的综合水平。
- 中位数:中位数和平均数一样都是用来反映整体数据综合水平的指标。
分类型数据
饼图
- 主要用于展示不同类别在整体中所占比重
- 在饼图中,整个圆饼代表数据的总量,各扇形区域表示各分类数据的占比,所有面积加和等于100%,可以很好地帮助用户了解整体的构成情况
- 饼图通常是展现分类型数据频率分布的最佳选择
- 缺点:不适用于多分类数据
- 条形图
- 是一种用来描绘分类型数据频数或频率分布的可视化图表
- 条形图使用一个单位长度表示一定长度的数量,根据数量的大小画成长短不同的直条。相较于饼图,条形图的优势体现在数据间的差异更直观。因为肉眼对高度差异更敏感
- 缺点:数据占比的展示不如饼图直观
- 对于频率分布的数据可视化,我们一般会优先使用饼图。但如果数据分类过多,我们可以选择条形图
- 直方图
- 直方图可以用来描绘数值型数据频数分布或频率分布的图表
- 针对数值型数据,直方图往往会比条形图有更好的可视化效果
- 直方图和条形图之间,最明显的区别就是,直方图的 “柱” 之间,是没有空隙的,而条形图的 “柱” 之间会有空隙。直方图的 “柱” 之间之所以没有空隙,因为数值型数据是连续的,没有空隙恰好能体现出其连续性
折线图
当数据同时存在缺失值、重复值以及异常值的问题时,这份数据属于脏数据,需要进行数据清洗。
- 在实际的数据分析项目中,经常会遇见数据统计不完整的情况,我们一般将那些缺失的数据称为缺失值
- 重复值指的是表格中重复出现的数据。在多数情况中,重复值都是完全相同的数据
- 有时数据中有一个或多个异常大或异常小的数值,超出了这份数据实际的限定范围,这样的数值被称为异常值
- 清洗数据的步骤:
安装matplotlib库
pip3 install matplotlib
<a name="1NGnJ"></a># Series对象与DataFrame对象<a name="47zsu"></a>### Series对象```python# 一组数据 + 索引import pandas as pddata = pd.Series(['赵','钱','孙','李'])print(data)'''0 赵1 钱2 孙3 李dtype: object'''
DataFrame对象
# 一组数据 + 行索引 + 列索引
import pandas as pd
data = pd.DataFrame({'年龄':[22,23,21],'专业':['计算机','数学','物理']})
print(data)
'''
年龄 专业
0 22 计算机
1 23 数学
2 21 物理
'''
两者区别与联系
my_data = pd.read_csv( ‘./data.csv’, # 文件路径 encoding = ‘utf-8’ # 编码格式 ) print(my_data)
<a name="H5rQ8"></a>
# 查看数据
<a name="62QyC"></a>
### 显示头部数据
```python
# 查看头部数据(默认为前5行)
my_data.head()
# 查看前10行数据
my_data.head(10)
显示尾部数据
# 查看尾部数据(默认为后5行)
my_data.tail()
# 查看前10行数据
my_data.tail(10)
显示数据基本信息
# 整体数据总共有多少行、总共有多少列、每一列的列名、所有非空数据的数据量等
my_data.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 9994 entries, 0 to 9993
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 用户ID 9994 non-null object
1 性别 9994 non-null object
2 年龄 9994 non-null float64
3 行业 9994 non-null object
4 岗位 9994 non-null object
5 购买原因 9994 non-null object
6 年购买量 9994 non-null float64
dtypes: float64(2), object(5)
memory usage: 546.7+ KB
'''
查看某列数据
# 查看my_data数据中,'行业'这一列数据
my_data['行业']
查看某列数据的频数分布
# 查看'行业'这列数据的频数分布
my_data['行业'].value_counts()
'''
学生 3985
IT/通讯/互联网 2517
银行/证券/保险业 2002
其他 987
教育行业 311
新闻/出版行业 192
Name: 行业, dtype: int64
'''
数值型数据分析方法
求和
# 最小值
my_data['年购买量'].sum()
最小值和最大值
# 最小值
my_data['年龄'].min()
# 最大值
my_data['年龄'].max()
平均值和中位数
# 平均值
my_data['年龄'].mean()
# 中位数
my_data['年龄'].median()
分类型数据分析方法
数据的频率分布
# 频率分布公式: 频数/总数据数
# 频数
my_data['性别'].value_counts()
# 总数据数
my_data['性别'].value_counts().sum()
# 频率分布
my_data['性别'].value_counts()/my_data['性别'].value_counts().sum()
'''
男 0.520412
女 0.479588
Name: 性别, dtype: float64
'''
数据清洗
缺失值
判断是否存在缺失值
在实际的数据分析项目中,我们一般使用 df.info() 方法查看数据的缺失情况。
# 查看mask_data的基本信息总结
mask_data.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 101942 entries, 0 to 101941
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 订单编号 101942 non-null object
1 日期 100956 non-null object
2 省 100956 non-null object
3 订单量 100960 non-null float64
4 单价 100958 non-null float64
5 销售额 100960 non-null float64
dtypes: float64(3), object(3)
memory usage: 4.7+ MB
'''
在数据基本信息总结中,我们可以看到数据的总量为101942。其中,日期,省,订单量,单价,销售额这些列的非空数据都比数据总量要小。
当非空数据与数据总量不一致时,说明这份数据有可能存在缺失值。
查找缺失值
# 查看mask_data的缺失值
mask_data.isna()
# 检测结果为布尔值:缺失数据会用True来表示,False则代表这里的数据正常
'''
订单编号 日期 省 订单量 单价 销售额
0 False False False False False False
1 False False False False False False
2 False False False False False False
3 False False False False False False
4 False False False False False False
... ... ... ... ... ... ...
101937 False True True True True True
101938 False True True False False False
101939 False True True False False False
101940 False True True False True False
101941 False True True False True False
'''
处理缺失值
这里可能是数据采集时出了一些问题,对于缺失值,最简单的方法就是将含有缺失值的行直接删除。
当然除了删除之外还有其它处理方法,比如给缺失值填充数据。
由于我们总体的数据量比较大,缺失值占总数据量的比重也比较低,将含有缺失值的行删除后并不会妨碍后续的分析。
# 删除所有缺失值
mask_data = mask_data.dropna()
# 查看数据基本信息总结
mask_data.info()
'''
<class 'pandas.core.frame.DataFrame'>
Int64Index: 100956 entries, 0 to 100955
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 订单编号 100956 non-null object
1 日期 100956 non-null object
2 省 100956 non-null object
3 订单量 100956 non-null float64
4 单价 100956 non-null float64
5 销售额 100956 non-null float64
dtypes: float64(3), object(3)
memory usage: 5.4+ MB
'''
重复值
查找重复值
# 查找mask_data中的重复行
mask_data.duplicated()
'''
0 False
1 False
2 False
3 True
4 True
...
100951 False
100952 False
100953 False
100954 False
100955 False
Length: 100956, dtype: bool
'''
# 查看mask_data中的重复数据
mask_data[mask_data.duplicated()]
'''
订单编号 日期 省 订单量 单价 销售额
3 535a-4eca-8fa0-9cc54c66e11d 2020-01-01 河南 0.0 30.0 0.0
4 535a-4eca-8fa0-9cc54c66e11d 2020-01-01 河南 0.0 30.0 0.0
412 2b31-4392-be6e-19af71e40261 2020-01-09 河南 1.0 30.0 30.0
441 d707-4d5c-ac10-59d3fd3dc0bb 2020-01-10 广东 1.0 30.0 30.0
845 49f6-4bd5-97a5-aeb075a1c8c3 2020-01-16 湖北 8.0 40.0 320.0
... ... ... ... ... ... ...
100157 1ee1-41a6-8c0a-7c24f988689f 2020-06-25 湖北 8.0 30.0 240.0
100312 c72a-401d-8f11-39becb49d442 2020-06-26 湖北 9.0 30.0 270.0
100321 73f3-4d40-af4e-426548a7c539 2020-06-26 广东 3.0 30.0 90.0
100330 1265-4d27-a5c6-d3d6f44cd594 2020-06-26 广东 3.0 30.0 90.0
100772 a56d-4415-ad6e-020cdb154c35 2020-06-29 其他 0.0 30.0 0.0
'''
处理重复值
这种重复数据并不具备分析的意义,而且会影响数据分析的结果,因此我们需要直接删除。
# 直接删除所有重复值
mask_data = mask_data.drop_duplicates()
# 查看mask_data中的重复数据
mask_data[mask_data.duplicated()]
'''
订单编号 日期 省 订单量 单价 销售额
'''
异常值
检查异常值
describe() 方法可以用来查看 pandas 库中的 Series 对象或者 DataFrame 对象数值型数据的描述性统计信息。
# 查看mask_data的描述性统计信息
mask_data.describe()
'''
订单量 单价 销售额
count 1.005080e+05 1.005080e+05 1.005080e+05
mean 9.551786e+05 9.552499e+05 9.592048e+05
std 3.089086e+07 3.089085e+07 3.089073e+07
min 0.000000e+00 3.000000e+01 0.000000e+00
25% 9.000000e+00 5.000000e+01 5.500000e+02
50% 2.000000e+01 5.000000e+01 1.700000e+03
75% 4.700000e+01 1.500000e+02 4.000000e+03
max 1.000000e+09 1.000000e+09 1.000000e+09
'''

处理异常值
布尔索引
# 查看订单量小于等于100的数据
mask_data[mask_data['订单量'] <= 100]
'''
订单编号 日期 省 订单量 单价 销售额
0 87af-48e5-8bed-c5dcf9ecc172 2020-01-01 广东 0.0 30.0 0.0
1 535a-4eca-8fa0-9cc54c66e11d 2020-01-01 河南 0.0 30.0 0.0
2 a56d-4415-ad6e-020cdb154c35 2020-01-01 湖北 1.0 30.0 30.0
5 953f-4b46-a8a2-0eb0e39818a8 2020-01-01 其他 0.0 30.0 0.0
6 953f-4b46-a8a2-0eb0e39818a8 2020-01-01 湖北 1.0 30.0 30.0
... ... ... ... ... ... ...
100951 8cad-41ee-85b7-c59b85f0ebe6 2020-06-30 湖北 10.0 30.0 300.0
100952 4ea4-480a-a070-295408955363 2020-06-30 湖北 6.0 30.0 180.0
100953 70f3-4461-9b5f-7f53a55c51b6 2020-06-30 湖北 10.0 30.0 300.0
100954 9cc8-4542-8fed-3145e1942504 2020-06-30 湖北 10.0 30.0 300.0
100955 f202-45df-96e2-ca4e4c389624 2020-06-30 湖北 5.0 30.0 150.0
'''
使用布尔索引过滤掉异常值
# 清除订单量超过100的数据
mask_data = mask_data[mask_data['订单量'] <= 100]
写入文件
# 保存清洗干净的数据
mask_data.to_csv(
'./工作/mask_data_clean.csv', # 导出路径
index = False # 写入行索引
)
处理日期数据
转化日期数据
# 转化日期数据,并设置对应的日期格式
date_data = pd.to_datetime(
mask_data_clean['日期'], # 是要转化的数据
format = '%Y-%m-%d' # 传入的日期数据的格式
)
print(date_data)
'''
0 2020-01-01
1 2020-01-01
2 2020-01-01
3 2020-01-01
4 2020-01-01
...
99480 2020-06-30
99481 2020-06-30
99482 2020-06-30
99483 2020-06-30
99484 2020-06-30
Name: 日期, Length: 99485, dtype: datetime64[ns]
'''
print(mask_data_clean['日期'])
'''
0 2020-01-01
1 2020-01-01
2 2020-01-01
3 2020-01-01
4 2020-01-01
...
99480 2020-06-30
99481 2020-06-30
99482 2020-06-30
99483 2020-06-30
99484 2020-06-30
Name: 日期, Length: 99485, dtype: object
'''
转化前的日期这一列的数据类型是 object ,而转化后的日期这一列的数据类型是 datetime
提取日期信息
# 提取日期数据中的年份信息
year_data = date_data.dt.year
# 提取日期数据中的月份信息
month_data = date_data.dt.month
# 提取日期数据中的日期信息
day_data = date_data.dt.day
print(year_data)
'''
0 2020
1 2020
2 2020
3 2020
4 2020
...
99480 2020
99481 2020
99482 2020
99483 2020
99484 2020
'''
print(month_data)
'''
0 1
1 1
2 1
3 1
4 1
..
99480 6
99481 6
99482 6
99483 6
99484 6
Name: 日期, Length: 99485, dtype: int64
'''
print(day_data)
'''
0 1
1 1
2 1
3 1
4 1
..
99480 30
99481 30
99482 30
99483 30
99484 30
Name: 日期, Length: 99485, dtype: int64
'''
添加新列
# 将月份数据添加到原数据中
mask_data_clean['月份'] = month_data
print(mask_data_clean)
'''
订单编号 日期 省 订单量 单价 销售额 月份
0 a56d-4415-ad6e-020cdb154c35 2020-01-01 湖北 1.0 30.0 30.0 1
1 953f-4b46-a8a2-0eb0e39818a8 2020-01-01 湖北 1.0 30.0 30.0 1
2 87af-48e5-8bed-c5dcf9ecc172 2020-01-01 湖北 1.0 30.0 30.0 1
3 535a-4eca-8fa0-9cc54c66e11d 2020-01-01 湖南 1.0 30.0 30.0 1
4 d707-4d5c-ac10-59d3fd3dc0bb 2020-01-01 广东 1.0 30.0 30.0 1
... ... ... ... ... ... ... ...
99480 8cad-41ee-85b7-c59b85f0ebe6 2020-06-30 湖北 10.0 30.0 300.0 6
99481 4ea4-480a-a070-295408955363 2020-06-30 湖北 6.0 30.0 180.0 6
99482 70f3-4461-9b5f-7f53a55c51b6 2020-06-30 湖北 10.0 30.0 300.0 6
99483 9cc8-4542-8fed-3145e1942504 2020-06-30 湖北 10.0 30.0 300.0 6
99484 f202-45df-96e2-ca4e4c389624 2020-06-30 湖北 5.0 30.0 150.0 6
'''
分组聚合
- 分组操作
- 根据某项规则将数据分入不同的组
df.groupby(key)
- 聚合操作
‘’’ 月份 1 550370.0 2 29256800.0 3 343641650.0 4 27313800.0 5 6327520.0 6 666660.0 Name: 销售额, dtype: float64 ‘’’
<a name="l6QBY"></a>
# 数据可视化
<a name="pQ9pm"></a>
### Pandas库
<a name="1qRgu"></a>
#### 饼图
```python
import pandas as pd
from matplotlib import pyplot as plt
# matplotlib库默认不支持中文字体的可视化,需要设置图像中文字体
plt.rcParams['font.family'] = ['Source Han Sans CN']
my_data = pd.read_csv('./data.csv', encoding = 'utf-8')
# 计算总体数据'行业'一列频率分布,并将结果赋值到profession变量
profession = my_data['行业'].value_counts()/my_data['行业'].value_counts().sum()
# 生成总体数据'行业'一列频率分布饼图
payWay.plot(
kind='pie', # 设置图表的类型:pie -> 饼图 bar -> 条形图 hist -> 直方图 line -> 折线图
autopct='%.2f%%', # 设置图表中数据显示格式:%.2f%% -> 保留两位小数
figsize=(7, 7), # 调整可视化图表的大小,单位为英寸
title='行业频率分布图', # 设置图表的标题名
label='' # 设置图像的标签,如果不想在图像上出现列标题,可以直接传入一个空字符串
)
# 显示统计图
plt.show()

条形图
# 提取my_data中的'岗位'数据
position = my_data['岗位'].value_counts()/my_data['岗位'].value_counts().sum()
# 绘制'岗位'一列的频率分布饼图
position.plot(kind = 'bar', figsize = (13, 6), title = '岗位频率分布图')
plt.show()

直方图
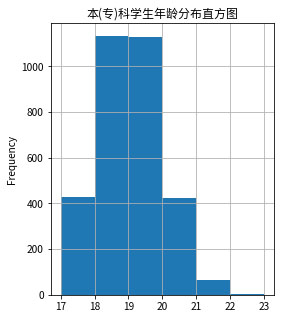
# 读取'本(专)科'学生中'年龄'这一列的数据
age = college_student['年龄']
# 绘制'年龄'这列的频率分布直方图
age.plot(
kind = 'hist',
bins = [17, 18, 19, 20, 21, 22, 23], # 设置分组
figsize = (4, 5),
title = '本(专)科学生年龄分布直方图',
grid = True # 设置网格
)
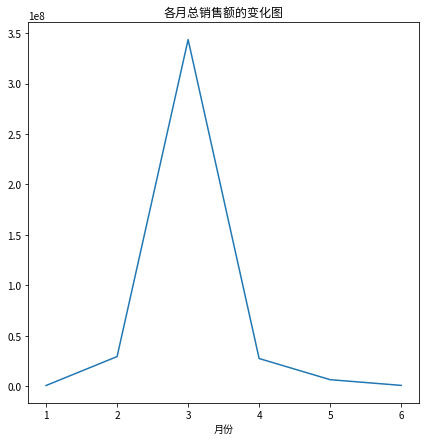
折线图
# 绘制各月总销售额的折线图
sales_price.plot(
kind = 'line',
figsize = (7, 7),
title = '各月总销售额趋势图'
)
matplotlib库
画图流程
- 生成画布
- 设置x轴和y轴的值
- 绘图
- 调整图形的样式
- 调整x轴和y轴的样式
- 设置图形的标题
- 设置图例(可选)
- 保存图形
折线图
```python引入matplotlib
from matplotlib import pyplot as plt
生成画布,并设置画布的大小
plt.figure(figsize = (6, 6))
设置x轴和y轴的值
x = sales_price.index y = sales_price.values
绘制折线图
plt.plot( x, # x轴数据 y, # y轴数据 linewidth = 3, # 线条的宽度 color = ‘grey’, # 线条颜色(更多颜色参数参考附录) marker = ‘o’, # 图形标记(更多marker参考附录) markerfacecolor = ‘dodgerblue’, # 标记的颜色 markersize = 8 # 标记的大小 )
调整x轴和y轴刻度值的字体大小
plt.xticks(size = 12) plt.yticks(size = 12)
添加x轴和y轴的标签
plt.xlabel(‘月份’, fontdict = {‘size’: 15}) plt.ylabel(‘各月总订单量’, fontdict = {‘size’: 15})
设置图形的标题
plt.title(‘各月总订单量变化折线图’, fontsize = 15)
保存图形
plt.savefig(‘./各月订单量变化折线图.png’)

<a name="LEPG0"></a>
#### 柱状图
```python
# 引入matplotlib
from matplotlib import pyplot as plt
# 生成画布,并设置画布的大小
plt.figure(figsize = (6, 6))
# 设置x轴和y轴的值
x = order_number.index
y = order_number.values
# 绘制柱状图(包含调整图形的样式)
plt.bar(
x,
height = y, # 第二个参数是height,不是y
color = 'dodgerblue',
width = 0.5 # 柱子宽度,值为(0,1],默认为0.8,当值为1时,柱子之间的间隙就位0
)
# 调整x轴和y轴刻度值字体的大小
plt.xticks(size = 12)
plt.yticks(size = 12)
# 设置x轴和y轴的标签
plt.xlabel('月份', fontdict = {'size': 15})
plt.ylabel('各月总订单量', fontdict = {'size': 15})
# 设置图形的标题
plt.title('各月总订单量分布柱状图', fontdict = {'size': 15})
# 保存图形
plt.savefig('./工作/各月总订单量分布柱状图.png')

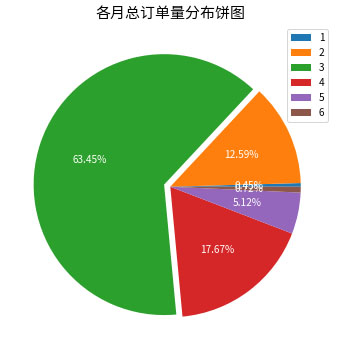
饼图
# 引入matplotlib
from matplotlib import pyplot as plt
# 生成画布,并设置画布的大小
plt.figure(figsize = (6, 6))
# 设置扇形面积的大小
x = order_number.values
# 设置textprops参数值
textprops = {
'fontsize': 10, # 字体大小
'color': 'white' # 字体颜色
}
# 设置explode参数值
explode = [0,0,0.05,0,0,0] # 每个扇形距离圆心的距离,起始位置为3点钟方向,逆时针方向排序
# 绘制饼图(包括调整图形样式)
plt.pie(
x,
autopct = '%.2f%%', # 显示的百分比中保留小数点后两位
textprops = textprops, # 设置显示的百分比的字体大小和颜色
explode = explode # 爆炸效果
)
# 设置图形的标题
plt.title('各月总订单量分布饼图', fontsize = 15)
# 设置图例
plt.legend(labels = order_number.index)
# 保存图形
plt.savefig('./工作/各月总订单量分布饼图.png')
附录
matplotlib颜色参考:



matplotlib marker参考:


若有收获,就点个赞吧
0 人点赞
