定义与参数
JavaScript中最关键的概念是:函数是第一类对象(first-class objects),或者说它们被称为一等公民(first-class citizens)。
函数与对象共存,函数也可以被视为其他任意类型JavaScript对象。函数和那些更普通的JavaScript数据类型一样,它能被变量引用,能以字面量形式声明,甚至能被作为函数参数进行传递。
函数是第一类对象
JavaScript中对象有以下几种常用功能:
- 对象可通过字面量来创建{}。
- 对象可以赋值给变量、数组项,或其他对象的属性。
- 对象可以作为参数传递给函数。
- 对象可以作为函数的返回值。
- 对象能够具有动态创建和分配的属性。
**
其实,不同于很多其他编程语言,在JavaScript中,我们几乎能够用函数来实现同样的事情。
JavaScript中函数拥有对象的所有能力,也因此函数可被作为任意其他类型对象来对待。但我们说函数是第一类对象时,就是说函数也能实现以下功能:
通过字面量创建。
function testFuction() {}
赋值给变量,数组项或其他对象的属性。
const testFunction = function() {};testArray.push(function(){});testObject.data = function(){};
作为函数的函数传递。
function call(testFuction){testFunction();}call(function(){});
作为函数的返回值。
function returnNewTestFunction(){return function(){};}
具有动态创建和分配的属性。
let testFuction = function(){};testFuction.data = "HelloWorld";
对象能做的任何一件事,函数也都能做。函数也是对象,唯一的特殊之处在于它是可以调用的(invokable),即函数会被调用以便执行某项动作。
回调函数
每当我们建立一个将在随后调用的函数时,无论是事件处理阶段通过浏览器还是通过其他代码,我们都是在建立一个回调(callback)。这个术语源自于这样一个事实,即在执行过程中,我们建立的函数会被其他函数在稍后的某个合适时间点“再回来调用”。
function addMessage(){const page = document.getElementById("page");page.inText += "Event:mousemove";}document.body.addEventListener("mousemove",addMessage);
JavaScript的重要特征之一是可以在表达式出现的任意位置创建函数,这种方式能使代码更紧凑和易于理解。当一个函数不会在代码的多处位置被调用时,该特征可以避免用非必须的名字污染全局命名空间。
document.body.addEventListener("mousemove",function(){const page = document.getElementById("page");page.inText += "Event:mousemove";});
使用比较器排序
假如我们有一组随机序列的数字数组:0、3、2、5、7、4、8、1,并且要将其重新排序。
通常来说,实现排序算法并不是编程任务中最微不足道的,我们需要为手中的工作选择最佳算法,实现它以适应当前的需要(使这些选项是按照特定顺序排序)。并且需要小心仔细不能引入故障。JavaScript有一个数组方法sort。利用该办法可以只定义一种比较算法,比较算法用于指示按什么顺序排序。
这就是回调函数所要介入的。不同于让排序算法来决定哪个值在前哪个值在后,我们将会提供一个函数来执行比较。我们会让排序算法能够获取这个比较函数作为回调,使算法在需要比较的时候,每次都能调用回调。该回调函数的期望返回值为:如果传入值的顺序需要被调换,返回正数;不需要调用,返回负数;两个值相等,返回0。
对于排序上述数组,我们对比较值做减法就能得到我们所需要的值:
let arr = [0,3,2,5,7,4,8,1];arr.sort(function(value1,value2){return value1 - value2;})
函数属性
我们可以给函数添加属性:
const wieldSword = function(){};wieldSword.swordType = "katana";
函数的这一特性可以做到:
- 在集合中存储函数是我们轻易管理相关联的函数。例如,某些特性情况下必须调用的回调函数;
- 记忆让函数能记住上一次计算得到的值,从而提高后续调用的性能。
存储函数
某些例子中(例如,我们需要管理某个时间发生后需要调用的函数集合),我们会存储元素唯一的函数集合。但我们向这样的集合添加函数时,会面临两个问题:哪个函数对于这个集合来说是一个新函数,从而需要被加入到该集合中?又是哪个函数已经在集合中,从而不需要再次加入集合中?
一般来说,管理回调函数集合时,我们不希望存在重复函数,否则一个事件会导致同一个回调函数被多次调用。
一种显著有效的简单方法是把所有函数存入一个数组,通过循环该数组来检查重复函数,但是这种方法性能较差。
因此我们可以使用函数的属性,用适当的复杂度来实现它。
let store = {nextId:1, // 跟踪下一个要被复制的函数cache:{}, // 使用一个对象作为缓存,我们可以在其中存储函数add:function(fn){/* 仅当函数唯一时,将该函数加入缓存 */if(!fn.id){fn.id = this.nextId++;this.cache[fn.id] = fn;return true;}}}
我们创建了一个对象赋值给变量store,这个变量存储的是唯一的函数集合。这个对象有两个数据属性:其一是下一个可用的id,另外一个缓存着已经保存的函数。函数通过add()方法添加到缓存中。
在add函数内,我们首先检查该函数是否存在id属性。如果当前的函数已经有id属性,我们则假设该函数已经被处理过了,从而忽略该函数,否则为该函数分配一个id属性,同时增加nextId,并将该函数作为一个属性增加到cache上,id作为属性名。紧接着该函数返回值为true,从而可得知调用了add()后,函数式什么时候被添加到存储中。
自记忆函数
记忆化(memoization)是一种构建函数的处理过程,能够记住上次计算结果:当函数计算得到结果时就将该结果按照参数存储起来。
采用这种方式时,如果另一个调用也使用相同的参数,我们这可以直接返回上次存储的结果而不是再计算一遍。像这样避免即重复又复杂的计算可以显著地提高性能。对于动画里的计算、搜索不经常变化的数据或任何耗时的数学计算来说,记忆化这种方法是十分有用的。
// 该例子使用了一个简单算法来计算素数function isPrime(value){if(!isPrime.answers){isPrime.answers = {}; // 创建缓存}if(isPrime.answers[value] !== undefined){return isPrime.answers[value]; // 检查缓存的值}let prime = value !== 0 && value !== 1;for(let i = 2;i < value;i++){if(value % i === 0){prime = false;break;}}return isPrime.answers[value] = prime;}
这个方法具有两个优点:
- 由于函数调用时会寻找之前调用所得到的值,所以用户最终会乐于看到所获得的性能收益。
- 它几乎是无缝地发生在后台,最终用户和页面作者都不需要执行任何特殊请求,也不需要任何额外初始化,就能顺利进行工作。
**
当然也存在一些缺陷:
- 任何类型的缓存都必然会为性能牺牲内存。
- 纯粹主义者会认为缓存逻辑不应该和业务逻辑混合,函数或方法只需要把一件事做好。
对于这类问题很难做负载测试或估计算法复杂度,因为结果依赖于函数之前的输入。
函数定义
JavaScript函数通常由函数字面量(function literal)来创建函数值,就像数字字面量创建一个数字值一样。JavaScript提供了几种定义函数的方式,可以分为4类:
函数声明(function declarations)和函数表达式(function expressisons)——最常用,在定义函数上却有微妙不同的两种方式。人们通常不会独立去看待它们,但正如你看到的,意识到两者的不同能帮我们理解函数何时能够被调用。 ```javascript function myFun(){return 1};
const myFun = function(){return 1};
- **箭头函数(通常被叫做lambda函数)**——ES6新增的JavaScript标准,能让我们以尽量简洁的语法定义函数。```javascriptmyArg => myArg*2;
函数构造函数——一种不常使用的函数定义方式,能让我们以字符串形式动态构造一个函数,这样得到的函数是动态生成的,这个例子动态创建了一个函数,其参数为a和b,返回值为两个数的和。
new Function('a','b','return a + b');生成器函数——ES6新增功能,能让我们创建不同于普通函数的函数,在应用程序执行过程中,这种函数能够退出再重新进入,在这些再进入之间保留函数内变量的值,我们可以定义生成器版本的函数声明、函数表达式、函数构造函数。
function* myGen(){yield 1;}函数声明和函数表达式
JavaScript中定义函数中最常见的方式是函数声明和函数表达式。
函数声明
JavaScript定义函数最基本方式是函数声明。每个函数声明以强制性的function开头,其后紧接着强制性的函数名,以及括号和括号内一列以逗号分隔可选参数名。函数体是一列可以为空的表达式,这些表达式必须包含在花括号内。
除了这种形式以外,每个函数声明还必须包含一个条件:作为一个单独的JavaScript语句,函数声明必须独立(但也能够包含在其他函数和代码块中)。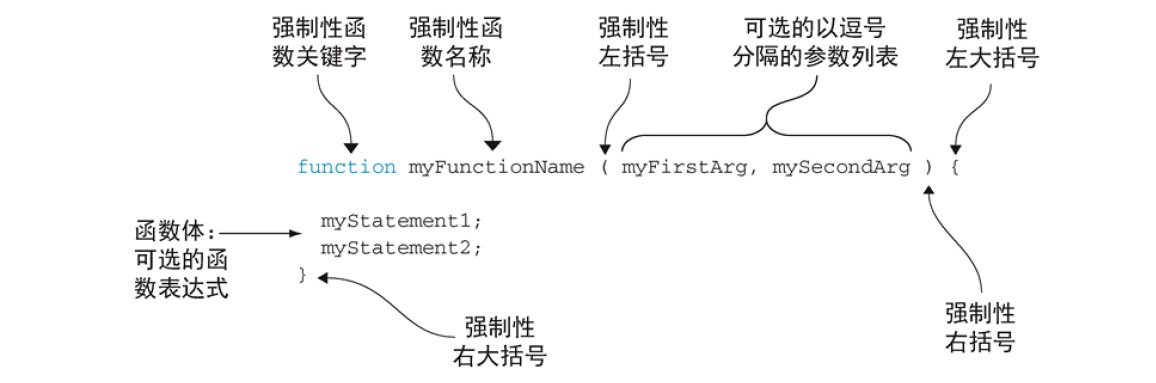
函数表达式
JavaScript中的函数是第一类对象,也就意味着它们可以通过字面创建,可以赋值给变量和属性,可以作为传递给其他函数的参数或返回值。
所以JavaScript能让我们把函数和其他表达式同等看待: ```javascript const a = 3; // 数字字面量 const a = function() {}; // 函数字面量
myFunction(4); // 数字字面量 myFunction(function(){}); // 函数字面量
**这种总是其他表达式的一部分的函数(作为赋值表达式的右值,或者作为其他函数的参数)叫做函数表达式。**函数表达式非常重要,在于它能够准确地在我们需要使用的地方定义函数,这个过程能让代码易于理解。
<a name="ZWaIe"></a>
#### 两者区别
```javascript
function myFunctionDeclaration(){ // 独立的函数声明
function innerFunction(){} // 内部函数声明
}
const myFunc = function(){}; // 函数表达式作为变量声明赋值语句中的一部分
myFunc(function(){ // 函数表达式作为一次函数调用中的参数
return function(){} // 函数表达式作为函数返回值
})
(function nameFunctionExpression(){})() // 作为函数调用的一部分,命名函数表达式会立即调用
// 函数表达式可以作为一元操作符的参数立即调用
+function(){}();
-function(){}();
!function(){}();
~function(){}();
函数声明和函数表达式除了在代码中的位置不同以外,还有一个更重要的不同点是:对于函数声明来说,函数名是强制性的,而对于函数表达式来说,函数名则完全是可选的。
函数声明必须具有函数名是因为它们是独立语句。一个函数的基本要求是它应该能够被调用,所以它必须具有一种被引用方式,于是唯一的方式就是通过它的名字。
从另一方面来看,函数变道时也是其他JavaScript表达式的一部分,所以我们也就具有调用它们的替代方案。
const doNothing = function(){};
doNothing(); // 调用函数
function doSomething(action){
action(); // 调用函数
}
立即函数
当想进行函数调用时,我们需要使用能够求值得到函数的表达式,其后跟着一堆函数调用括号,括号内包含参数。在最基本的函数调用时,我们把求值得到函数的标识符作为左值。
不过用于被括号调用的表达式不必只是一个简单的标识符,他可以是任何能够求值得到函数的表达式。例如,指定一个求值得到函数的表达式的最简单方式是使用函数表达式。就如右图所示,我们首先创建了一个函数,然后立即调用这个新创建的函数。
这种函数叫做立即调用函数表达式(IIFE),或者简写为立即函数。这一特性能够模拟JavaScript中的模块化,故可以说它是JavaScript开发中的重要理念。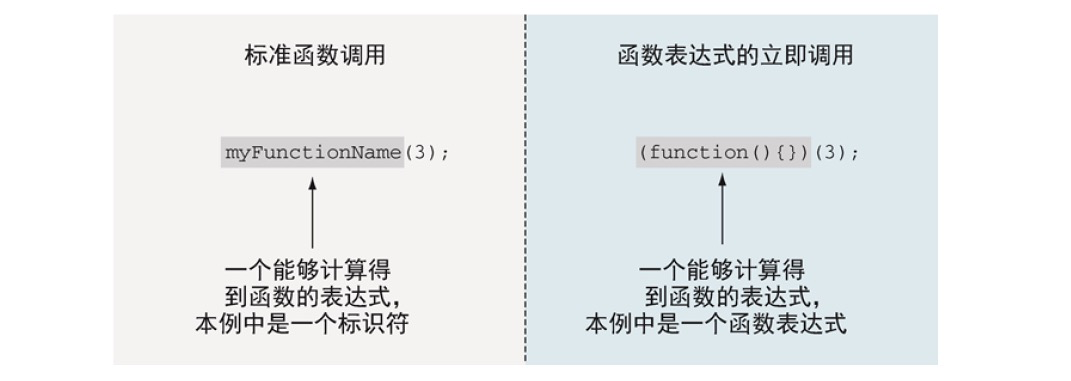
而通过使用一元操作符+,-,!和~来立即调用函数,这种做法也是用于向JavaScript指明它处理的是表达式,而不是语句。从计算机的角度来讲,注意应用一元操作符得到的结果没有存储到任何地方并不重要,只有调用IIFE才重要。
加括号的函数表达式
(function(){})()
这个立即调用的函数表达式方式中的函数表达式被包裹在一对括号内。其原因是纯语法层面的。JavaScript解析器必须能够轻易区分函数声明和函数表达式之间的区别。如果去掉包囊函数表达式的括号,把立即调用作为一个独立语句 function(){}() ,JavaScript开始解析便会结束,因为这个独立语句以function开头,那么解析器会认为它在处理一个函数声明。每个函数声明必须有一个名字,然而这里并没有,因此程序执行到这里就会报错。
还有一种相对简单的替代方案 (function(){}()) 也能达到相同效果,但是不常使用。
箭头函数
很多方式中,箭头函数是函数表达式的简化版。
let arr = [0,3,2,5,7,4,8,1];
// 函数表达式
arr.sort(function(value1,value2){
return value1 - value2;
})
// 箭头函数
arr.sort((value1,value2) => value1 - value2);
箭头函数的定义以一串可选参数名列表开头,参数名以逗号分隔。如果没有参数或者多余一个参数时,参数列表就必须包裹在括号内。但如果只有一个参数时,括号就不是必须的。参数列表之后必须跟着一个胖箭头符号,以此向我们和 JavaScript引擎指示当前处理的是箭头函数。
胖箭头操作符后面有两种可选方式。如果要创建一个简单函数,那么可以把表达式放在这里(可以是数学运算、其他的函数调用等),则该函数的返回值即为此表达式的返回值。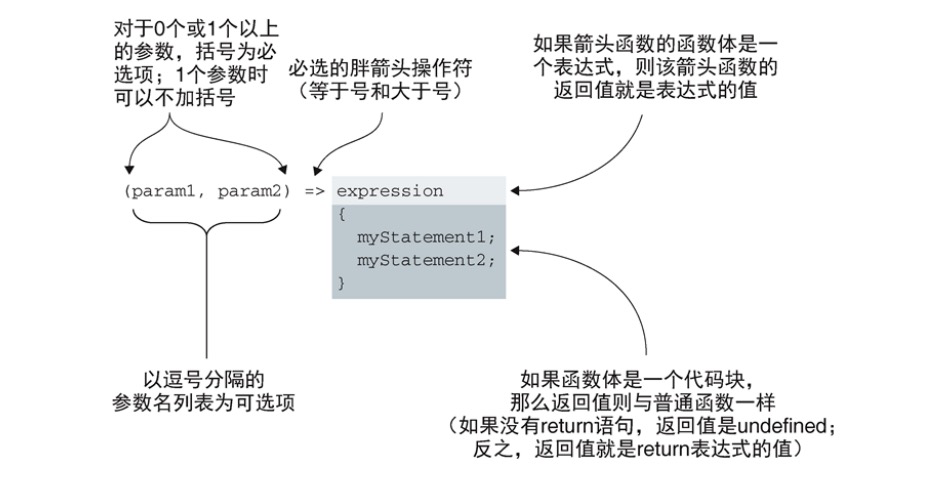
函数的实参和形参
- 形参(parameter)是我们定义函数所列举的变量;
- 实参(argument)是我们调用函数时所传递给函数的值。

剩余参数
为函数的最后一个命名参数前加上省略号(…)前缀,这个参数就变成了一个叫作剩余参数的数组,数组内包含着传入的剩余的参数。只有函数的最后一个参数才能是剩余参数。
// 返回第一个参数与余下参数最大的数相乘的值
function multiMax(first,...remainingNumbers){
const sorted = remainingNumbers.sort((a,b)=> b-a);
return first * sorted[0];
}
multiMax(3,1,3,2); // 9
本例中用 4 个参数调用了 multiMax 函数,即 multi Max(3, 1, 2, 3)。在 multiMax函数体内,第一个参数的值 3 被赋值给了第一个函数 multiMax 形参 first。由于函数的第二个参数是剩余参数,故所有的剩余参数(1,2,3)都被放在一个新的数组remainingNumbers 里。通过降序排列这个数组(可以看到为数组排序是很简单的)并取得排序后数组的第一个值即最大值。
默认参数
创建默认参数的方式是为函数的形参赋值,设置默认参数的形参应放置所有形参的后面。
可以为默认参数赋任何值,它既可以是数字或者字符串这样的原始类型,也可以是对象、数组,甚至函数这样的复杂类型。每次函数调用时都会从左到右求得参数的值,并且当对后面的默认参数赋值时可以引用前面的默认参数。
function performAction(ninja,action = "skulking"){
return ninja + " " + action;
}
performAction("Fuma") // Fuma skulking
performAction("Yagyu","sneaking") // Fuma sneaking
函数调用
隐式函数参数
除了在函数定义中显式声明的参数之外,函数调用时还会传递两个隐式的参数:arguments 和this。这些隐式参数在函数声明中没有明确定义,但会默认传递给函数并且可以在函数内正常访问。在函数内可以像其他明确定义的参数一样引用它们。
arguments参数
arguments参数是传递给函数的所有参数集合。无论是否有明确定义对应的形参,通过它我们都可以访问到函数的所有参数。
arguments对象有一个名为length的属性,表示实参的确切个数。通过数组索引的方式可以获取单个参数的值。
function whatever(a,b,c){
return [arguments.length,arguments[0]];
}
whatever(1,2,3) // [3,1]
whatever(1,2,3,4,5) // [5,1]
通过数组下标的方式还可以访问到 arguments 参数中的每个参数值。值得注意的是,这里也包括没有和函数形参相关联的剩余参数。
function whatever(a,b,c){
return [arguments.length,arguments[arguments.length-1]];
}
whatever(1,2,3) // [3,3]
whatever(1,2,3,4,5) // [5,5]
arguments参数并非数组。虽然它有length属性,而且能通过数组下标的方式访问到每一个元素。但它并非JavaScript数组,arguments对象仅是一个类数组的结构。
**
this参数:函数上下文
当调用函数时,除了显式提供的参数外,this 参数也会默认地传递给函数。this 参数是面向对象 JavaScript 编程的一个重要组成部分,代表函数调用相关联的对象。因此,通常称之为函数上下文。
函数上下文是来自面向对象语言(如 Java)的一个概念。在这些语言中,this 通常指向定义当前方法的类的实例。但在 JavaScript 中,将一个函数作为方法(method)调用仅仅是函数调用的一种方式。事实上,this 参数的指向不仅是由定义函数的方式和位置决定的,同时还严重受到函数调用方式的影响。
函数调用
我们通常可以通过四种方式调用一个函数:
- 作为一个函数(function)——
testFunction(),直接被调用; - 作为一个方法(method)——
Test.testFunction(),关联在一个对象上,实现面向对象编程; - 作为一个构造函数(constructor)——
new Test(),实例化一个新的对象; - 通过函数的apply或者call方法——
testFunction.apply(Test)或者testFunction.call(Test)```javascript function testFunction(a){}; const Test = { testFunction2:function(a){} }
// 作为函数调用 testFunction(‘test’);
// 作为Test对象的一个方法调用 Test.testFunction2(‘test’);
// 作为构造函数调用 const test = new testFunction(‘test’);
// 通过call调用 testFunction2.call(Test,’test’);
// 通过apply调用 testFunction2.apply(Test,’test’);
<a name="gP3aD"></a>
### 作为函数直接被调用
实际上,这里我们说的函数“作为一个函数”被调用是为了区别于其他的调用方式:方法、构造函数和 apply/call。如果一个函数没有作为方法、构造函数或者通过 apply 和 call调用的话,我们就称之为作为函数被直接调用。<br />通过()运算符调用一个函数,且被执行的函数表达式不是作为一个对象的属性存在时,就属于这种调用类型。
```javascript
function testFunction(){};
testFunction(); // 函数声明作为函数被调用
const testFunction function(){};
testFunction(); // 函数表达式作为函数被调用
(funciton(){})() // 会被立即调用的函数表达式,作为函数被调用
当以这种方式调用时,函数上下文(this 关键字的值)有两种可能性:在非严格模式下,它将是全局上下文(window 对象),而在严格模式下,它将是undefined。
function test1(){
return this;
}
test1(); // window
function test2(){
"use strict"
return this;
}
test2(); // undefined
作为方法被调用
当一个函数被赋值给一个对象的属性,并且通过对象属性引用的方式调用时,函数会作为对象的方法被调用。
const test = {};
test.testFunction = function(){};
test.testFunction();
当函数作为某个对象的方法被调用时,该对象会成为函数的上下文,并且在函数内部可以通过参数访问到。这也是 JavaScript 实现面向对象编程的主要方式之一。
function whatsMyContext(){
return this;
}
whatsMyContext(); // 作为函数被调用并将其上下文设置为window对象
const test = {
getMyThis:whatsMyContext
}
test.getMyThis(); // 使用test对象的方法getMyThis来调用函数,函数上下文下只能是test,这就是面向对象
将函数作为方法调用对于实现 JavaScript 面向对象编程至关重要。这样你就可以通过 this 在任何方法中引用该方法的“宿主”对象——这也是面向对象编程的一个基本概念。
作为构造函数调用
构造函数的声明和其他函数类似,通过可以使用函数声明和函数表达式很容易地构造新的对象。
function whatsMyContext(){
return this;
}
new whatsMyContext();
构造函数的强大功能
function Ninja(){
this.skulk = function(){
return this;
}
}
const ninja1 = new Ninja();
const ninja2 = new Ninja();
ninja1.skulk(); // ninja1
ninja2.skulk(); // ninja2
在这个例子中,我们创建了一个名为 Ninja 的函数作为构造函数。当通过 new 关键字调用时会创建一个空的对象实例,并将其作为函数上下文(this 参数)传递给函数。构造函数中在该对象上创建了一个名为 shulk 的属性并赋值为一个函数,使得该函数成为新创建对象的一个方法。
使用关键字 new 调用函数会触发以下几个动作:
- 创建一个新的空对象;
- 该对象作为this参数传递给构造函数,从而成为构造函数的函数上下文;
- 新构造的对象作为new运算符的返回值。
所以前面的 new whatsMyContext() 中的 whatsMyContext 不适合 作为构造函数,因为构造函数的目的是创建一个新对象,并进行初始化设置,然后将其作为构造函数的返回值。任何有悖于这两点的情况都不适合作为构造函数。
构造函数返回值
构造函数的目的是初始化新创建的对象,并且新构造的对象会作为构造函数的调用结果(通过 new 运算符)返回。
function Test(){
this.testFuction = function(){
return true;
};
return 1; // 构造函数返回一个确定的原始类型值,即数字1
}
Test(); // 1
console.log(typeof Test()); // number
const test = new Test();
console.log(typeof test); // object
console.log(typeof test.testFuction); // function
如果将Test作为一个函数调用,的确会返回1,但如果通过new关键字将其作为构造函数调用,会构造并返回一个新的test对象。
const puppet = { // 定义了全局对象
rules :false
};
function Emperor(){
this.rules = true;
return puppet; // 返回了全局的puppet对象
}
const emperor = new Emperor();
console.log(emperor === puppet); // true
console.log(emperor.rules); // false
测试结果表明,puppet对象最终作为构造函数调用的返回值,而且在构造函数中对函数上下文的操作是无效的。最终返回的将是puppet。
- 如果构造函数返回一个对象,则该对象将作为整个表达式的值返回,而传入构造函数的this将被丢弃。
- 如果构造函数返回的是非对象类型,则忽略返回值,返回新创建的对象。
使用apply和call方法调用
JavaScript 为我们提供了一种调用函数的方式,从而可以显式地指定任何对象作为函数的上下文。我们可以使用每个函数上都存在的这两种方法来完成:apply和 call。
若想使用 apply 方法调用函数,需要为其传递两个参数:作为函数上下文的对象和一个数组作为函数调用的参数。call 方法的使用方式类似,不同点在于是直接以参数列表的形式,而不再是作为数组传递。
function juggle(){
let result = 0;
for(let n = 0; n < arguments.length; n++){
result += arguments[n];
}
this.result = result;
}
let test1 = {};
let test2 = {};
juggle.apply(test1,[1,2,3,4]);
juggle.call(test2,5,6,7,8);
console.log(test1.result); // 10
console.log(test2.result); // 26
解决函数上下文的问题
使用箭头函数绕过函数上下文
箭头函数相比于传统的函数声明和函数表达式,可以更优雅地创建函数。箭头函数作为回调函数还有一个更优秀的特性:箭头函数没有单独的this 值。箭头函数的 this 与声明所在的上下文的相同。
const Test = {
test1 : function(){
return this;
},
test2 : () =>{
return this;
}
}
console.log(Test.test1() === Test) // true
console.log(Test.test2() === window) // true
箭头函数在创建时确定了 this 的指向。由于 click 箭头函数是作为对象字面量的属性定义的,对象字面量在全局代码中定义,因此,箭头函数内部 this 值与全局代码的 this 值相同。
使用bind方法
函数还可访问 bind 方法创建新函数。无论使用哪种方法调用,bind 方法创建的新函数与原始函数的函数体相同,新函数被绑定到指定的对象上。
const module = {
x: 42,
getX: function() {
return this.x;
}
};
const unboundGetX = module.getX;
console.log(unboundGetX()); // expected output: undefined
const boundGetX = unboundGetX.bind(module);
console.log(boundGetX()); // expected output: 42
闭包和作用域
理解闭包
闭包允许函数访问并操作函数外部的变量。只要变量或函数存在于声明函数时的作用域内,闭包即可使函数能够访问这些变量或函数。
const outerValue = "Hello World";
function outerFunction(){
console.log(outerValue); // "Hello World"
}
outerFunction();
该函数可以“看见”并访问变量 outerValue。
因为外部变量outerValue和外部函数outerFunction都是在全局作用域中声明的,该作用域(实际上就是一个闭包)从未消失(只要应用处在运行状态)。
const outerValue = "This is the outerValue";
let later;
function outerFunction(){
const innerValue = "This is the innerValue";
function innerFunction(){
console.log(outerValue); // "This is the outerValue"
console.log(innerValue); // "This is the innerValue"
}
later = innerFunction;
}
outerFunction();
later();
当在外部函数中声明内部函数时,不仅定义了函数的声明,而且还创建了一个闭包。该闭包不仅包含了函数的声明,还包含了在函数声明时该作用域中的所有变量。当最终执行内部函数时,尽管声明时的作用域已经消失了,但是通过闭包,仍然能够访问到原始作用域。
这就是闭包。闭包创建了被定义时的作用域内的变量和函数的安全气泡,因此函数获得了执行时所需的内容。该气泡与函数本身一起包含了函数和变量。
虽然这些结构不容易被看见,存储和引用这些信息会直接影响性能。虽然闭包是非常有用的,但也不要过度使用。使用闭包时,所有的信息都会存储在内存中,直到JavaScript引擎确保这些信息不再使用(可以安全地进行垃圾回收)或页面卸载时,才会清理这些信息。
使用闭包
封装私有变量
许多编程语言使用私有变量,这些私有变量是对外部隐藏的对象属性。这是非常有用的一个特性,因为当通过其他代码访问这些变量时,我们不希望对象的实现细节对用户造成过度负荷。
遗憾的是,原生JavaScript不支持私有变量。但是通过闭包,我们可以实现很接近的、可接受的私有变量。
function Ninja(){
let feints = 0; // 在构造函数内部声明一个变量,因为所声明的变量的作用域局限于构造函数的内部,所以它是一个”私有变量“
this.getFeints = function(){ // 创建用于访问计数变量feints的方法
return feints;
};
this.feint = function(){
feints++;
}
};
const ninja1 = new Ninja();
ninja1.feint();
console.log(ninja1.feints) // undefined
console.log(ninja1.getFeints()) // 1
const ninja2 = new Ninja();
console.log(ninja2.getFeints()) // 0
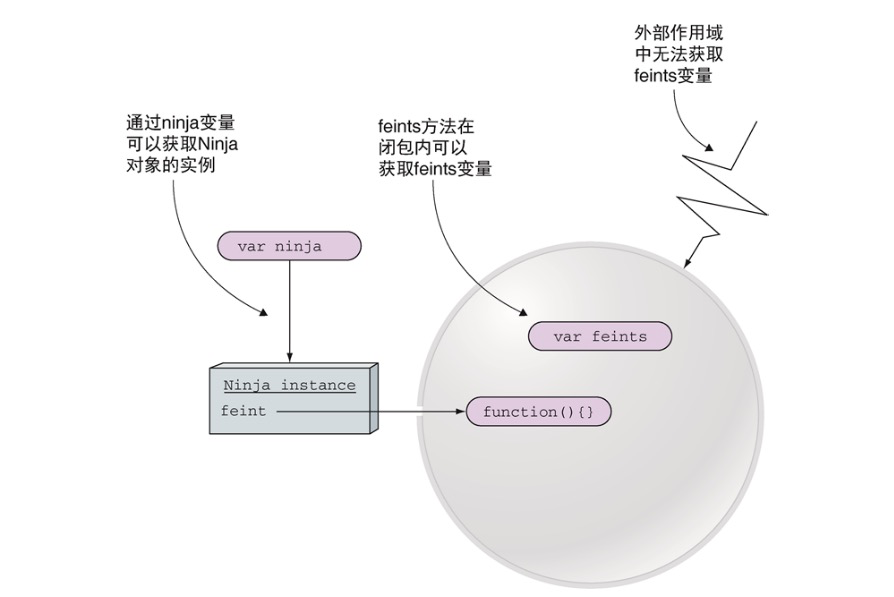
- 通过变量ninja,对象实例是可见的。
- 因为feint方法在闭包内部,因此可以访问变量feints。
- 在闭包外部,我们无法访问变量feints。
通过例子显示,我们可通过闭包内部方法获取私有变量的值,但不能直接访问私有变量。这儿有效地阻止了读私有变量不可控的修改,这与真实的面向对象语言中的私有变量一样。
回调函数
处理回调函数是另一种常见的使用闭包的情景。回调函数指的是需要在将来不确定的某一时刻事件异步调用的函数。通过,在这种回调函数中,我们经常需要频繁地访问外部数据。
<div id="box1">First Box</div>
<script>
function animateIt(elementId){
const elem = document.getElementById(elementId);
let tick = 0;
setInterval(function(){
if(tick < 100){
elem.style.left = elem.style.top = tick + "px";
tick++;
}else{
clearInterval(timer);
}
},10);
}
animateIt("box1");
</script>
通过在函数内部定义变量,并基于闭包,使得在计时器的回调函数中可以访问这些变量,每个动画都能够获得属于自己的“气泡”中的私有变量。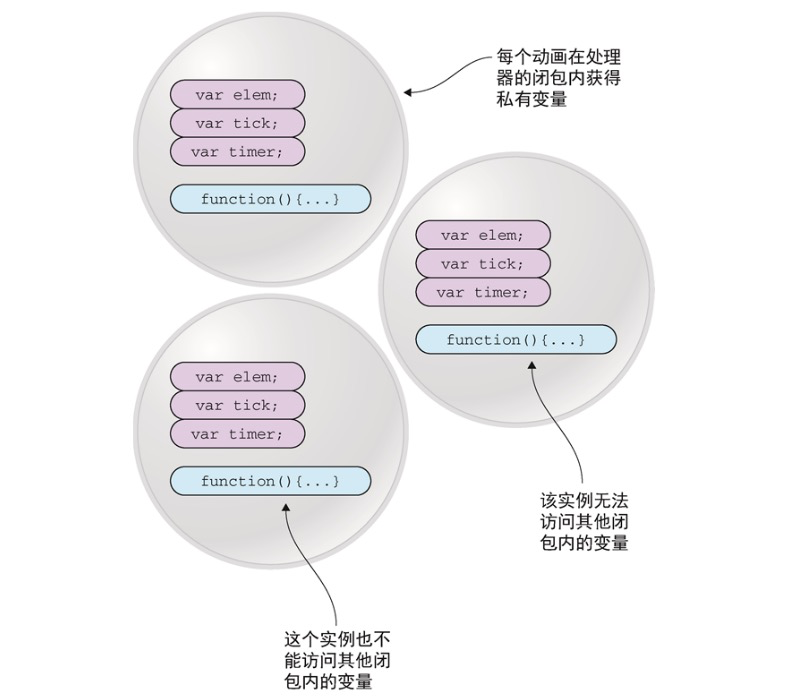
闭包与作用域是强相关的。
通过执行上下文来跟踪代码
JavaScript代码有两种类型:一种是全局代码,在所有函数外部定义;一种是函数代码,位于函数内部。JavaScript引擎执行代码时,每一条语句都处于特定的执行上下文中。
既然具有两种类型的代码,那么就有两种执行上下文:全局执行上下文和函数执行上下文。两者最重要的差别是:全局执行上下文只有一个,但JavaScript程序开始执行时就已经创建了全局上下文;而函数执行上下文是在每次调用函数时,就会创建一个新的。
JavaScript 基于单线程的执行模型:在某个特定的时刻只能执行特定的代码。
一旦发生函数调用,当前的执行上下文必须停止执行,并创建新的函数执行上下文来执行函数。当函数执行完成后,将函数执行上下文销毁,并重新回到发生调用时的执行上下文中。所以需要跟踪执行上下文——正在执行的上下文以及正在等待的上下文。最简单的跟踪方法是使用执行上下文栈(或称为调用栈)。
function skulk(ninja){
report(ninja + "skulking")
}
function report(message){
console.log(message)
}
skulk("Kuma");
skulk("Yoshi");
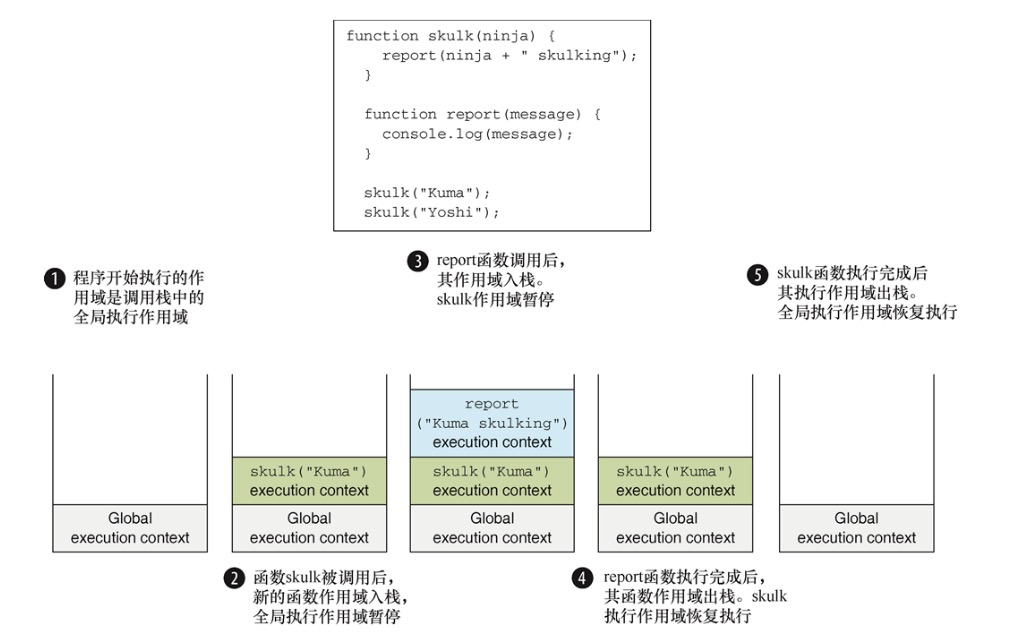
虽然执行上下文栈(execution context stack)是 JavaScript 内部概念,但仍然可以通过 JavaScript 调试器中查看,在 JavaScript 调试器中可以看到对应的调用栈(call stack)。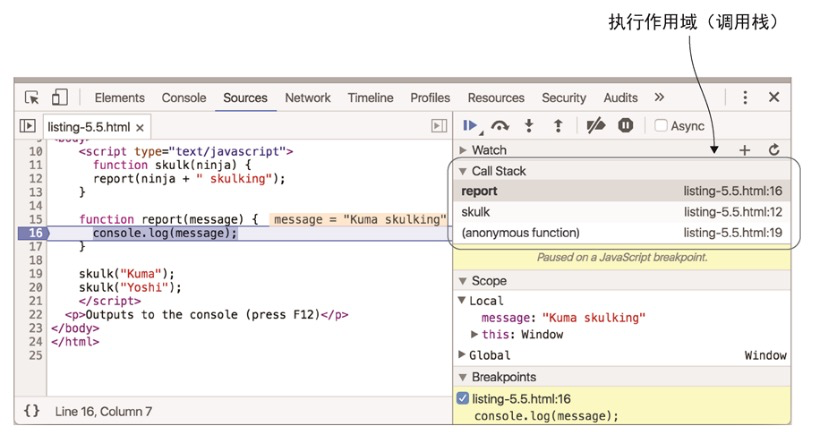
执行上下文除了可以跟踪应用程序的执行位置之外,对于标识符也是至关重要,在静态环境中通过执行上下文可以准确定位标识符实际指向的变量。
使用词法环境跟踪变量作用域
词法环境(lexical environment)是JavaScript引擎内部用来跟踪标识符与特定变量之间的映射关系。语法环境是JavaScript作用域的内部实现机制,人们通常称为作用域(scopes)。
const test = "HelloWorld";
console.log(test); // 当console.log语句访问test变量时,会进行语法环境的查询
代码嵌套
词法环境主要基于代码嵌套,通过代码嵌套可以实现代码结构包含另一代码结构。
const ninja = "Muneyoshi";
function skulk(){ // skulk函数包含在全局代码中
const action = "skulking";
function report(){ // report函数嵌套在skulk函数中
const reportNum = 3;
for(let i = 0;i < reportNum;i++){ // for循环嵌入在report函数中
console.log(ninja + " " + action + " " + i);
}
}
}
skulk();
在作用域范围内,每次执行代码时,代码结构都获得与之关联的词法环境。例如,每次调用skulk函数,都将创建新的函数词汇环境。
此外,需要着重强调的是,内部代码结构可以访问外部代码结构中定义的变量。例如,for 循环可以访问 report 函数、skulk 函数以及全局代码中的变量;report 函数可以访问 skulk 函数及全局代码中的变量;skulk 函数可以访问的额外变量但仅是全局代码中的变量。
代码嵌套与词法环境
除了跟踪局部变量、函数声明、函数的参数和词法环境外,还有必要跟踪外部(父级)词法环境。因为我们需要访问外部代码结构中的变量,如果在当前环境中无法找到某一标识符,就会对外部环境进行查找。一旦查找到匹配的变量,或是在全局环境中仍然无法查找到对应的标识符而返回错误,就会停止查找。
无论何时创建函数,都会创建一个与之相关联的词法环境,并存储在名为[[Environment]]的内部属性上(也就是说无法直接访问或操作)。两个中括号用于标志内部属性。在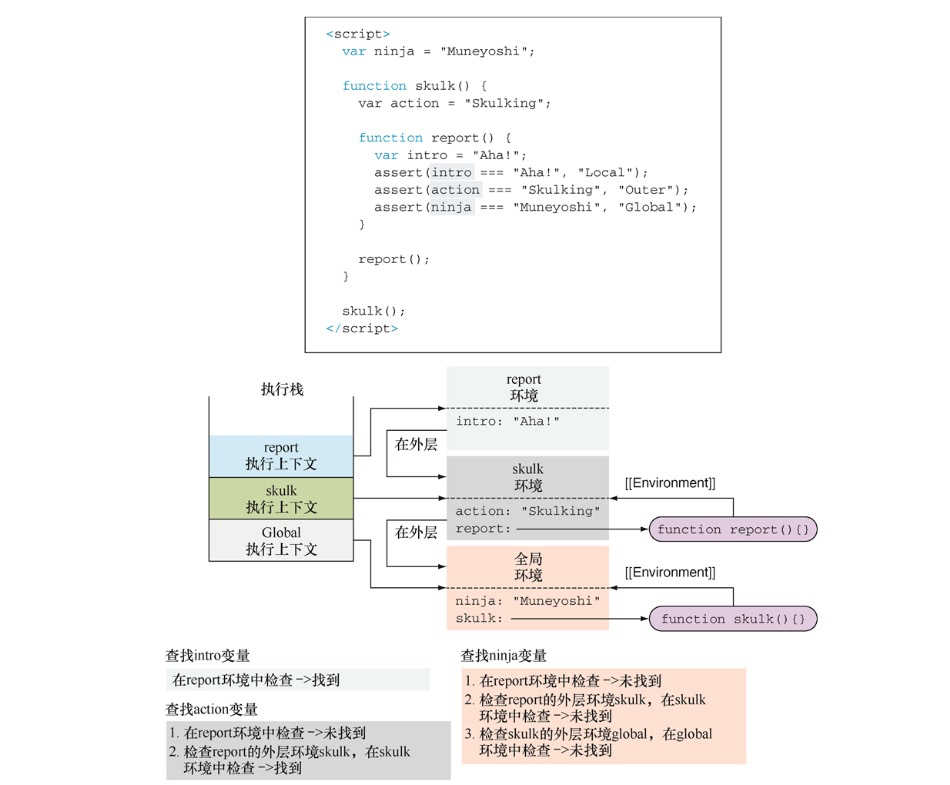
理解JavaScript的变量类型
在 JavaScript 中,我们可以通过 3 个关键字定义变量:var、let 和 const。这 3 个关键字有两点不同:可变性,与词法环境的关系。
变量可变性
如果通过变量的可变性来进行分类,那么可以将 const 放在一组,var 和 let 放在一组。通过 const 定义的变量都不可变,也就是说通过 const 声明的变量的值只能设置一次。通过 var 或 let 声明的变量的值可以变更任意次数。
const变量
通过const声明的“变量”与普通变量类似,但在声明时需要写初始值,一旦声明完成之后,其值就无法更改。const变量常用于两种目的:
- 不需要重新赋值的特殊变量。
- 指向一个固定的值,例如球队人数的最大值,可通过const变量MAX_RONIN_COUNT来表示,而不仅仅通过数字234来表示。这使得代码更加易于理解和维护。
const变量有一个重要的特征,就是我们不能将一个全新的值赋值给const变量,但是我们可以修改const变量已有的对象。**
const obj = {a:1,b:2};
obj.a = 3;
obj.c = 4;
如果const变量指向一个数组,我们可以增加该数组的长度:
const arr = [1,2,3];
arr.push(4);
arr[1] = 5;
定义变量的关键字与词法环境
定义变量的 3 个关键字——var、let 与 const,还可以通过与词法环境的关系将其进行分类(换句话说,按照作用域分类):可以将 var 分为一组,let 与 const 分为一组。
使用关键字var
当使用关键字 var 时,该变量是在距离最近的函数内部或是在全局词法环境中定义的。(注意:忽略块级作用域)这是 JavaScript 由来已久的特性,也困扰了许多从其他语言转向 JavaScript 的开发者。
var globalNinja = "Yoshi"; // 使用关键字var定义全局变量
function reportActivity(){
var functionActivity = "jumping"; // 使用关键字var定义函数内部的局部变量
for(var i = 1; i < 3 ; i++){ // 使用关键字var在for循环中定义两个变量
var forMessage = globalNinja + " " + functionActivity;
// 在for循环中可以访问块级变量,函数内的局部变量以及全局变量
console.log(forMessage); // Yoshi jumping
console.log(i); // 3
}
console.log(forMessage); // 但是在for循环外部,仍然可以访问到for循环中定义的变量
console.log(i);
}
reportActivity();
// 函数外部无法访问函数内部的局部变量
console.log(functionActivity); // undifined
console.log(forMessage); // Yoshi undifined
console.log(i); // undifined
我们首先定义全局变量 globalNinja,接着定义函数 reportActivity,在该函数中使用循环并验证变量 globalNinja 的行为。可以看出,在循环体内可以正常访问块级作用域中的变量(变量 i 与 forMessage)、函数体内的变量(functionActivity)以及全局变量(globalNinja)。
但是 JavaScript 中特殊的并使得许多从其他语言转向 JavaScript 的开发者们困惑的是,即使在块级作用域内定义的变量,在块级作用域外仍然能够被访问。这源于通过 var 声明的变量实际上总是在距离最近的函数内或全局词法环境中注册的,不关注块级作用域。
使用let与const定义具有块级作用域的变量
var 是在距离最近的函数或全局词法环境中定义变量,与 var 不同的是,let 和const 更加直接。let 和 const 直接在最近的词法环境中定义变量(可以是在块级作用域内、循环内、函数内或全局环境内)。我们可以使用let 和const 定义块级别、函数级别、全局级别的变量。
const globalNinja = "Yoshi"; // 使用关键字const定义全局变量
function reportActivity(){
const functionActivity = "jumping"; // 使用关键字var定义函数内部的局部变量
for(let i = 1; i < 3 ; i++){ // 使用关键字let/const在for循环中定义两个变量
const forMessage = globalNinja + " " + functionActivity;
// 在for循环中可以访问块级变量,函数内的局部变量以及全局变量
console.log(forMessage); // Yoshi jumping
console.log(i); // 3
}
console.log(forMessage); // 但是在for循环外部,无法访问到for循环中定义的变量
console.log(i);
}
reportActivity();
// 函数外部无法访问函数内部的局部变量
console.log(functionActivity); // undifined
console.log(forMessage); // Yoshi undifined
console.log(i); // undifined
在词法环境中注册标识符
const firstRonin = "kiyokawa";
check(firstRonin); // 在函数声明前调用
function check(ronin){
console.log(ronin) // "kiyokawa"
}
JavaScript 对于在哪儿定义函数并不挑剔。在调用函数之前或之后声明函数均可。
注册标识符的过程
JavaScript代码的执行事实上是分为两个阶段进行的。
一旦创建了新的词法环境,就会执行第一阶段。在第一阶段,没有执行代码,但是JavaScript 引擎会访问并注册在当前词法环境中所声明的变量和函数。JavaScript 在第一阶段完成之后开始执行第二阶段,具体如何执行取决于变量的类型(let、var、const 和函数声明)以及环境类型(全局环境、函数环境或块级作用域)。
具体的处理过程如下:
- 如果是创建一个函数环境,那么创建形参及函数参数的默认值。如果是非函数环境,将跳过此步骤。
- 如果是创建全局或函数环境,就扫描当前代码进行函数声明(不会扫描其他函数的函数体),但是不会执行函数表达式或箭头函数。对于说找到的函数声明,将创建函数,并绑定到当前环境与函数名相同的标识符上。若该标识符已经存在,那么就该标识符的值将被重写。如果是块级作用域,将跳过此步骤。
- 扫描当前代码进行变量声明。在函数或全局环境中,查找所有当前函数以及其他函数之外通过var声明的变量,并查找所有通过let或const定义的变量。在块级环境中,仅查找当前块中通过let或const定义的变量。对于所查找的变量,若该标识符不存在,进行注册并将其初始化为undefined。若该标识符已经存在,将保留其值。

在函数声明前调用函数
JavaScript 易用性的一个典型特征,是函数的声明顺序无关紧要。在 JavaScript 中,我们可以在函数声明之前对其进行调用。
console.log(typeof fun) // function
console.log(typeof myFunExp) // undefined
console.log(typeof myArrow) // undefined
function fun(){} // 作为函数声明进行定义
var myFunExpr = function(){}; // 作为函数表达式进行定义
var myArrow = (x) => x; // 作为箭头函数进行定义
需要注意的是,这种情况仅针对函数声明有效。函数表达式与箭头函数都不在此过程中,而是在程序执行过程中执行定义的。
函数重载
console.log(typeof fun === "function") // true
var fun = 3; // 定义变量fun并赋值为数字3
console.log(typeof fun === "number") // true
function fun(){} // 函数声明
console.log(typeof fun === "number") // true
JavaScript 的这种行为是由标识符注册的结果直接导致的。在处理过程的第2步中,通过函数声明进行定义的函数在代码执行之前对函数进行创建,并赋值给对应的标识符;在第 3 步,处理变量的声明,那些在当前环境中未声明的变量,将被赋值为 undefined。在实例中,在第 2 步——注册函数声明时,由于标识符 fun 已经存在,并未被赋值为 undefined。这就是第 1 个测试 fun 是否是函数的断言执行通过的原因。之后,执行赋值语句 var fun = 3,将数字 3 赋值给标识符 fun。执行完这个赋值语句之后,fun就不再指向函数了,而是指向数字 3。
研究闭包的工作原理
使用闭包模拟私有变量
function Ninja(){
var feints = 0; // 在构造函数内部声明变量。由于该变量的作用域在构造函数内部,因此feints是一个私有变量
this.getFeints = function(){ // 访问feints的方法
return feints;
};
this.feint = function(){ // 变量feints的增值方法
feints++;
}
}
var ninja1 = new Ninja();
console.log(ninja1.feints); // undefined
ninja1.feint();
console.log(ninja1.getFeints); // 1

我们可以利用标识符原理更好地理解这种情况之下闭包的工作原理。
通过关键字new调用JavaScript构造函数。因此每次调用构造函数时,都会创建一个新的词法环境,该词法环境保持构造函数内部的局部变量。在本例中,创建了Ninja环境,保持对变量feints的跟踪。
此外,无论何时创建函数,都会保持词法环境的引用(通过内置[[Environment]]属性)。在本例中,Ninja构造函数内部,我们创建了两个函数:getFeints与feint,均有Ninja环境的引用,因为Ninja环境是这两个环境创建时所处的环境。
getFeints与feint函数是新创建的ninja的对象方法(可通过this关键字访问)。因此,可以通过Ninja构造函数外部访问getFeints与feint函数,这实际上就创建了包含feints变量的闭包。
每一个通过Ninja构造函数创建的对象实例均获得各自的方法(ninja1.getFeints与ninja2.getFeint是不同的),当调用构造函数时,各自的实例方法包含各自的变量。这些“私有变量”只能通过构造函数内定义的对象进行访问,不允许直接访问。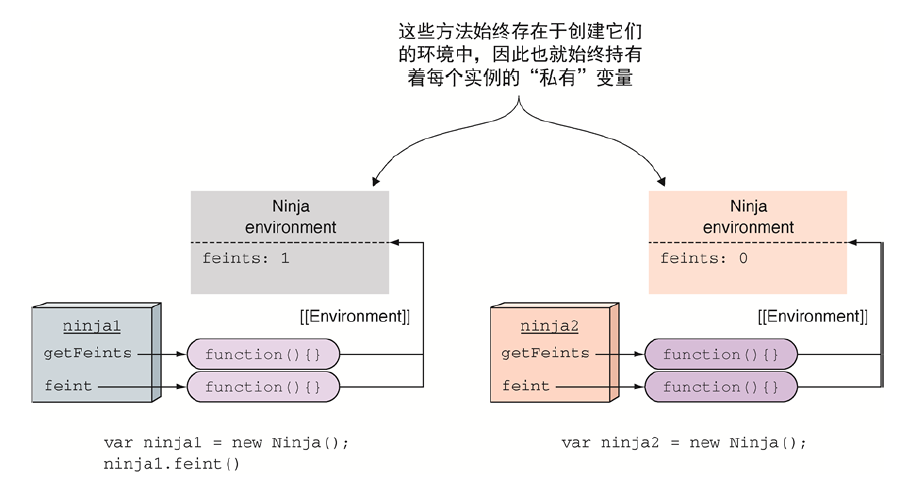
在调用ninja2.getFeints方法之前,JavaScript引擎正在执行全局代码。我们的程序处于全局执行上下文状态,是执行栈里的唯一上下文。同时,唯一活跃的词法环境是全局环境,与全局执行上下文关联。
当调用ninja2.getFeints()时,我们调用的是ninja2对象的getFeints方法。由于每次调用函数时均会创建新的执行上下文,因此创建了新的getFeints执行环境并推入执行栈。这同时引起创建新的词法环境,词法环境通常用于保持跟踪函数中定义的变量。另外getFeints词法环境包含了getFeints函数被创建所处的环境,当ninja2对象构建时,Ninja环境是活跃的。
私有变量的警告
function Ninja(){
var feints = 0; // 在构造函数内部声明变量。由于该变量的作用域在构造函数内部,因此feints是一个私有变量
this.getFeints = function(){ // 访问feints的方法
return feints;
};
this.feint = function(){ // 变量feints的增值方法
feints++;
}
}
var ninja1 = new Ninja();
console.log(ninja1.feints); // undefined
ninja1.feint();
console.log(ninja1.getFeints); // 1
var imposter = {};
imposter.getFeints = ninja1.getFeints;
console.log(imposter.getFeints) // 1
我们将ninja1的对象方法getFeints赋值给一个新的imposter对象。然后,当我们通过对象impostor的getFeints方法,可以访问得到ninja1对象的私有变量。
本例表明在JavaScript没有真正的私有对象属性,但是额可以通过闭包实现一种可接受的“私有”变量的方案。
生成器和promise
生成器(generator)是一种特殊类型的函数。但从头到尾运行标准函数时,它最多只生成一个值。然而生成器函数会在几次运行请求中暂停,因此每次运行都可能会生成一个值。
另外,对象的一个新的内置类型promise,能够帮助编写异步代码。promise对象是一个占位符,暂时替代那些尚未计算出来但未来会计算出来的值。对于多个异步操作来说,使用promise对象会非常有好处的。
使用生成器和promise编写优雅的异步代码
try{
var ninjas = syncGetJSON("ninjas.json");
var missions = syncGetJSON(ninjas[0].missionsUrl);
var missisonDetail = syncGetJSON(ninjas[0].detailsUrl);
}catch(e){
console.log(e)
}
这段代码很容易理解,如果其中任何一步出了错误,catch代码块都能很轻易地捕捉。但很不幸,这样的代码有很大的问题。从服务端中获取数据是一个长时间操作,而JavaScript依赖于单线程执行模型,所以一直到长时间的操作之前,UI的渲染都会是暂停的。随后的应用都会无响应,用户会感到不满。
我们可以用回调函数解决这个问题,这样每个任务结束后都调用回调函数,从而不会导致UI暂停。
getJSON("ninjas.json",function(err,ninjas){
if(err){
console.log(err);
return;
}
getJSON(ninjas[0].missionsUrl,function(err,ninjas){
if(err){
console.log(err);
return;
}
getJSON(ninjas[0].detailsUrl,function(err,ninjas){
if(err){
console.log(err);
return;
}
})
})
})
尽管这段代码能够显著提升用户体验,但这段代码写的很散乱,其中包含大量的错误处理样板代码,这样的写法看起来很丑陋。
这时候如果引入生成器和promise,非阻塞但丑陋的回调函数就会变得优雅:
async(function*(){ // 通过在function关键字后增加一个*号可以定义生成器函数。在生成器函数中可以使用新的yield函数
try{
// promise对象都隐含在getJSON方法中
const ninjas = yield getJSON("ninjas.json");
const missions = yield getJSON(ninjas[0].missionsUrl);
const missionDescription = yield getJSON(ninjas[0].detailsUrl);
}catch(e){
console.log(e)
}
})
使用生成器函数
生成器函数几乎是一个完全崭新的函数类型,它和标准的普通函数不同。
生成器(generator)函数能生成一组值的序列,但每个值的生成都基于每次请求,并不同于标准函数那样立即生成。我们必须显示地向生成器请求一个新的值,随后生成器要么响应一个新生成的值,要么就告诉我们它之后都不会再生成新值。
每当生成器函数生成一个值,它都不会像普通函数一样停止执行。相反,生成器几乎从不挂起。随后,当对另一个值得请求到来后,生成器就会从上次离开的位置恢复执行。
function* WeaponGenerator(){ // 通过在关键字function后面添加星号*定义生成器函数
// 使用新的关键字yield生成独立的值
yield "Katana";
yield "Wakizashi";
yield "Kusarigama";
}
for(let weapon of WeaponGenerator()){ // 使用新的循环类型for-of取出生成的值序列
console.log(weapon) // "Katana" "Wakizashi" "Kusarigama"
}
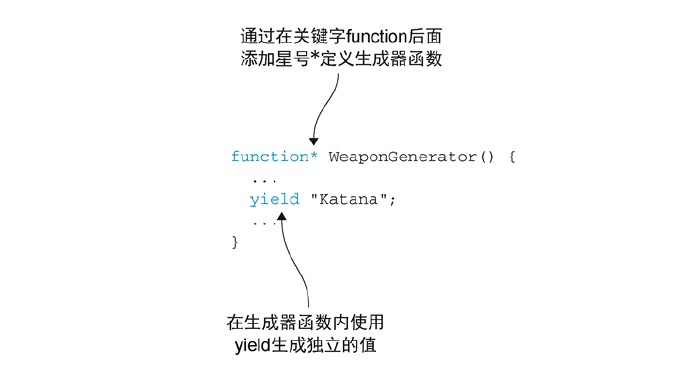
在WeaponGenerator函数的函数体中,其实并没有return语句,但是for-of循环右边能够正常得到值。这是疑问生成器函数与标准函数非常不同。调用生成器并不会执行生成器函数,相反,它会创建一个叫作迭代器(iterator)的对象。
通过迭代器对象控制生成器
调用生成器函数不一定会执行生成器函数体。通过创造迭代器对象,可以与生成器通信。
function* WeaponGenerator(){
yield "Katana";
yield "Wakizashi";
}
const weponsIterator = WeaponGenerator(); // 调用生成器得到一个迭代器,从而我们能够控制生成器的执行
const result1 = weponsIterator.next(); // 调用迭代器的next方法向生成器请求一个新值
console.log(result1) // Object { value: "Katana", done: false }
const result2 = weponsIterator.next();
console.log(result2) // Object { value: "Wakizashi", done: false }
const result3 = weponsIterator.next();
console.log(result3) // Object { value: undefined, done: true }
当调用生成器后,就会创建一个迭代器(iterator)。迭代器用于控制生成器的执行。迭代器对象暴露的最基本接口是next方法。这个方法可以用来向生成器请求一个值,从而控制生成器。
next函数调用后,生成器就开始执行代码,当代吗执行到yeild关键字时,就会生成一个中间结果(生成值序列中的一项),然后返回一个新对象,其中封装了结果值和一个指示完成的指示器。
每当生成一个当前值后,生成器就会非阻塞地挂起执行,随后耐心等待下一次值请求的到达,这就是普通函数完全不具备的强大特性。
对迭代器进行迭代
通过调用生成器得到的迭代器,暴露出一个next方法能让我们向迭代器请求一个新值。next方法返回一个携带着生成值的对象,而该对象中包含的另一个属性done也向我们指示了生成器是否还会追加生成值。
function* WeaponGenerator(){
yield "Katana";
yield "Wakizashi";
}
const weponsIterator = WeaponGenerator();
let item;
while(!(item = weponsIterator.next()).done){
console.log(item.value) // "Katana" "Wakizashi"
}
在每次迭代时,我们通过调用迭代器weponsIterator的next方法从生成器中取一个值,然后把值存放在item变量中。和所有next返回的对象一样,item变量引用的对象中包含一个属性value为生生成器返回的值,一个属性done指示生成器是否已经完成了值的生成。如果生成器中的值没有生成完毕,我就会进入下次循环迭代,反之停止循环。
这就是前面实例中for-of循环的原理。for-of不过是对迭代器进行迭代的语法糖。不同于手动调用迭代器的next方法,for-of循环同时还要查看生成器是否完成,它在后台自动做了完全相同的工作。
for(let item of WeaponGenerator()){
console.log(item);
}
把执行权交给下一个迭代器
function* WarriorGenerator(){
yield "Sun Tzu";
yield* NinjaGenerator();
yield "Genghis Khan";
}
function* NinjaGenerator(){
yield "Hattori";
yield "Yoshi";
}
for(let warrior of WarriorGenerator()){
console.log(warrior) // "Sun Tzu" "Hattori" "Yoshi" "Genghis Khan"
}
对于调用最初的迭代器来说,这一切都是透明的。for-of循环不会关系WarriorGenerator委托到另一个生成器,它只关心在done状态到来之前都一直调用next方法。
使用生成器
用生成器生成ID序列
在创建某些对象时,我们经常需要为每个对象赋一个唯一的ID值。最简单的方式是通过一个全局的计数器变量,但这是一种丑陋的写法,因为这个计数器变量很容易就会不慎淹没在代码中。而另一种方式就是用生成器。
function* IdGenerator(){
let id = 0; // 一个始终记录ID的变量,这个变量无法在生成器外部改变
while(true){ // 循环生成无限长度的ID序列
yield ++id;
}
}
const idIterator = IdGenerator();
const ninja1 = {id:idIterator.next().value};
const ninja2 = {id:idIterator.next().value};
const ninja3 = {id:idIterator.next().value};
console.log(ninja1,ninja2,ninja3) // Object { id: 1 } Object { id: 2 } Object { id: 3 }
标准函数一般不应该书写无限循环的代码,但是在生成器中是没有问题的。但生成器遇到了一个yield语句,他就会一直挂起直到下次调用next方法,所以只有每次调用一次next方法,while循环才会迭代一次并返回下一个ID值。
使用迭代器遍历DOM树
网页的布局是基于DOM结构的,它是由HTML节点组成的树形结构,除了根节点的每个节点都只有一个父节点,而且可以有0个或多个孩子节点。
遍历DOM的相对简单的方式就是实现一个递归函数,在每次访问节点的时候都会被执行。
<div id="subTree">
<form>
<input type="text" />
</form>
<p>Paragraph</p>
<span>Span</span>
</div>
<script>
fuction traverseDom(element,callback){ // 利用回调函数处理当前节点
callback(element);
element = element.firstElementChild;
// 遍历每个子树
while(element){
traverseDOM(element,callback);
element = element.nextElementSibling;
}
}
const subTree = document.getElementById("subTree");
traverseDom(subTree,function(element){
console.log(element.nodeName); // DIV FORM INPUT P SPAN
})
</script>
现在我们可以通过生成器来实现它。
function* DomTraversal(element){
yield element;
element = element.firstElementChild;
while(element){
yield* DomTraversal(element);
element = element.nextElementSibling;
}
}
const subTree = document.getElementById("subTree");
for(let element of DomTraversal(subTree)){
console.log(element.nodeName); // DIV FORM INPUT P SPAN
}
与生成器交互
作为生成器函数参数发送值
function* NinjaGenerator(action){
const imposter = yield ("hattori " + action); // 产生一个值的同时,生成器会返回一个中间计算结果。通过带有参数的调用迭代器next方法,我们可以将数据传递会生成器
console.log(imposter === "Hanzo") // 传递回的值为yield表达式的返回值,因此imposter的值为Hanzo
yield("Yoshi (" + imposter + ") " + action);
}
const ninjaIterator = NinjaGenerator("skulk");
const result1 = ninjaIterator.next();
console.log(result1); // Object { value: "hattori skulk", done: false }
const result2 = ninjaIterator.next("Hanzo");
console.log(result2); // Object { value: "Yoshi (Hanzo) skulk", done: false }
使用next方法向生成器发送值
除了在第一次调用生成器的时候向生成器提供数据,我们还能通过next方法向生成器传入参数。这个过程中,我们把生成器函数从挂起状态恢复到了执行状态。在当前挂起的生成器中,生成器把这个传入的值用于整个yield表达式。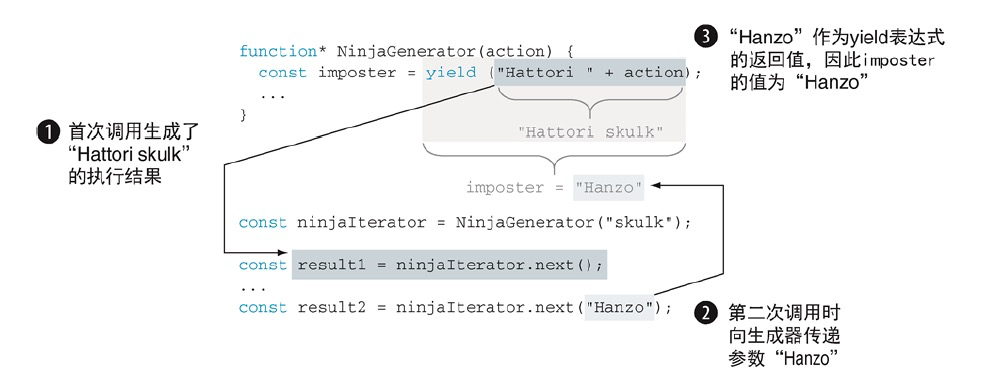
抛出异常
function* NinjaGenerator(){
try{
yield "Hettori";
}catch(e){
console.log(e === "Catch It"); // 捕获异常并检测接受的异常是否符合预期
}
}
const ninjaIterator = NinjaGenerator();
const result = ninjaIterator.next();
console.log(result.value); // "Hettori"
// 向生成器抛出一个异常
ninjaIterator.throw("Catch It") // true
探索生成器内部构造
当我们调用一个生成器不会实际执行它。相反的,它创建了一个新的迭代器,通过该迭代器我们才能从生成器中请求值。在生成器生成(或让渡)了一个值后,生成器会挂起执行并等待下一个请求的到来。在某个方面来说,生成器的工作更像是一个小程序,一个在状态中运动的状态机。
- 挂起开始——创建了一个生成器后,它最先以这种状态开始。其中的代码都未执行。
- 执行——生成器中的代码已执行。执行要么是刚开始,要么是从上次挂起的时候继续的。但生成器对应的迭代器调用了next方法,并且当前存在可执行的代码时,生成器都转移到了这个状态。
- 挂起让渡——当生成器在执行过程中遇到一个yield表达式,它会创建一个包含着返回值的新对象,随后再挂起执行。生成器在这个状态暂停并等待继续执行。
- 完毕——在生成器执行期间,如果代码执行到return语句或者全部代码执行完毕,生成器就就进入状态。
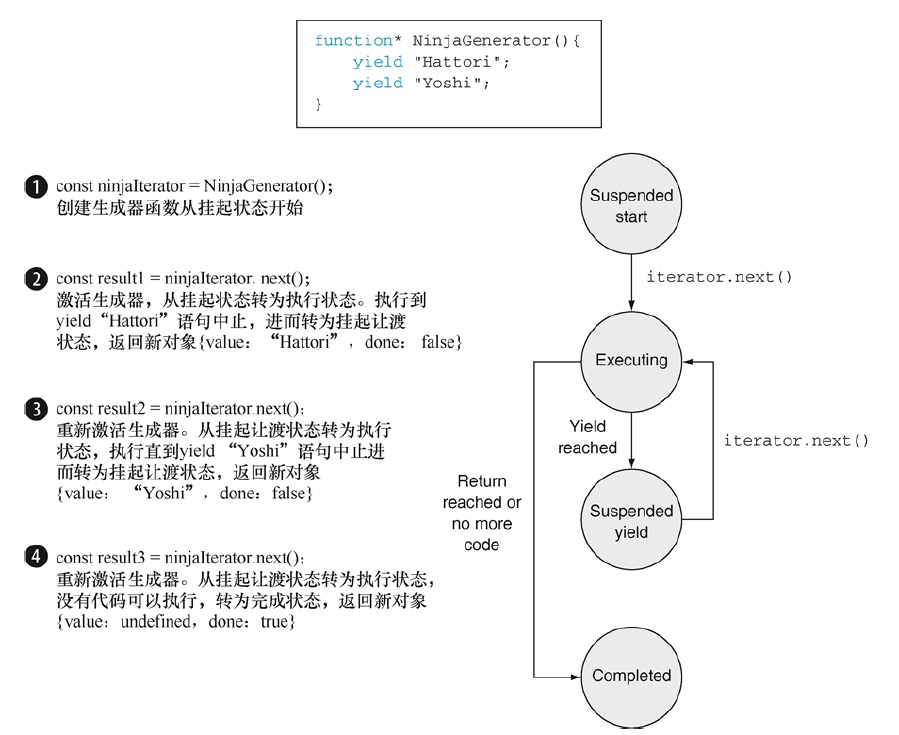
通过执行上下文跟踪生成器函数
function* NinjaGenerator(action){
yield "Hattori " + action;
return "Yoshi " + action;
}
const ninjaIterator = NinjaGenerator("skulk");
const result1 = ninjaIterator.next(); // Hattori skulk
const result2 = ninjaIterator.next(); // Yoshi skulk
这里我们对生成器进行了重用,其生成了两个值:Hattori skulk和Yoshi skulk。
当调用NinjaGenerator函数之前应用程序的状态时,正在执行的是全局代码,故执行上下文栈仅仅包含全局执行上下文,该上下文引用了当前标识符所在的全局环境。而NinjaGenerator则仅仅应用了一个函数,此时其他标识符的值都是undefined。
当调用NinjaGenerator函数的时候,控制流则进入了生成器,正如进入任何其他函数一样,当前将会创建一个新的函数环境上下文NinjaGenerator,并将该上下文入栈。而生成器比较特殊,它不会执行任何函数代码。取而代之则生成一个新的迭代器再从中返回。通过在代码中用ninjaIterator可以用来引用这个迭代器。由于迭代器用来控制生成器的执行的,故而迭代器中保存着一个在它创建位置处的执行上下文。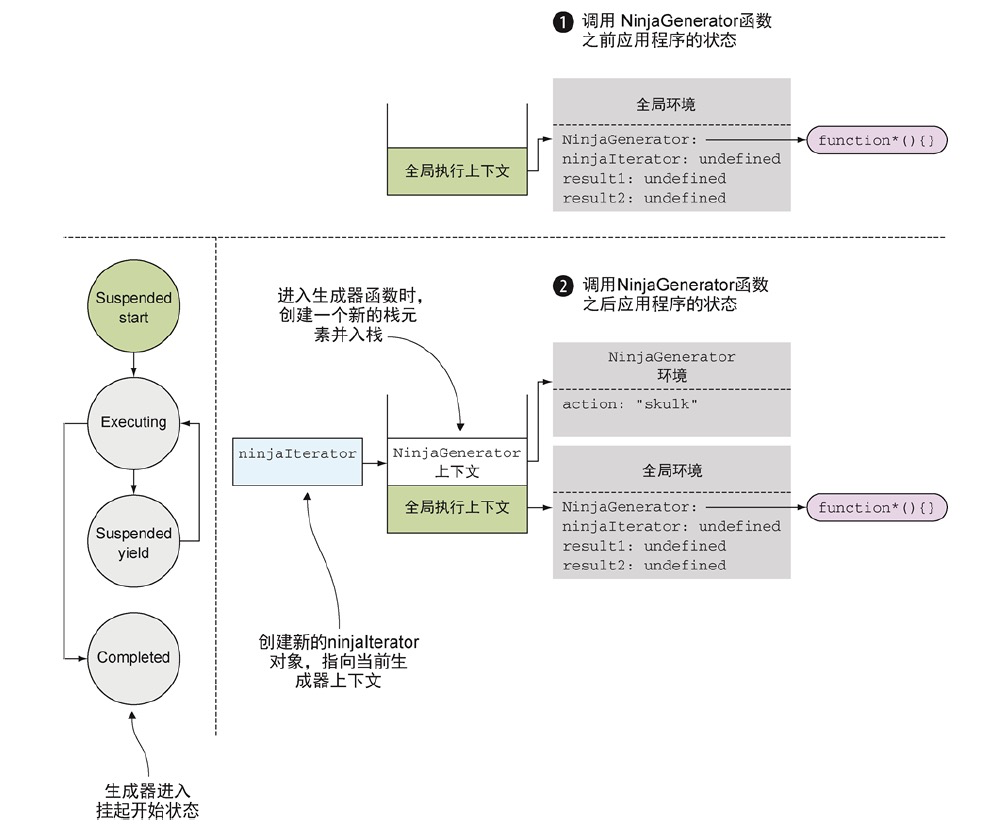
当程序从生成器中执行完毕后,发生了一个有趣的现象。一般情况下,当程序从一个标准函数返回后,对应的执行环境上下文会从栈中弹出,并被完整地销毁。但在生成器中不是这样的。
相对应的NinjaGenerator会从栈中弹出,但由于ninjaIterator还保存着对它的引用,所以它不会被销毁。我们可以把它看作一种类似闭包的事物。在闭包中,为了在闭包创建的时候保证变量都可用,所以函数会对创造它的环境持有一个引用。以这种方式,我们能保证只要函数还存在,环境及变量就都存在着。
生成器从另一个角度看,还需要恢复执行。由于所有的函数的执行都被执行上下文所控制,故而迭代器保持了一个对当前执行环境的引用,保证只要迭代器还需要它的时候它都存在。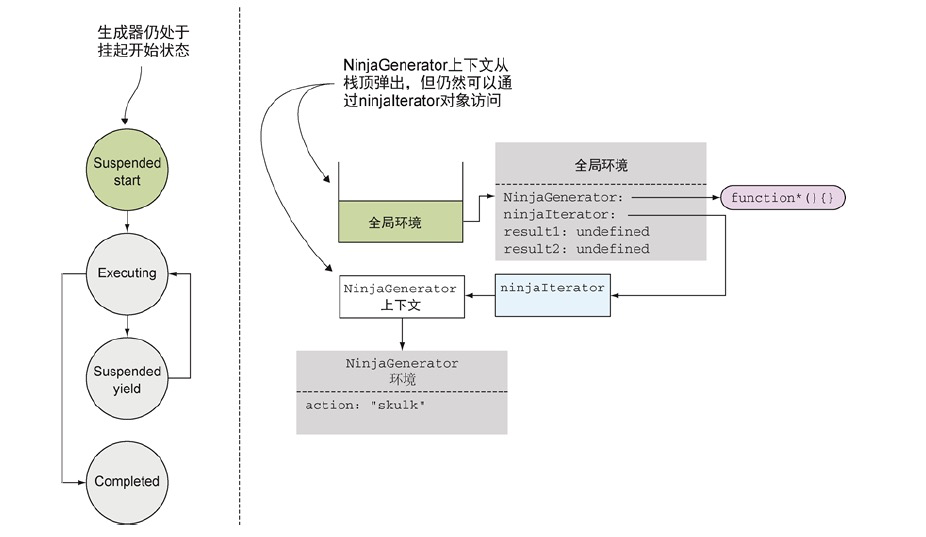
当调用迭代器的next方法时,如果只是一个普通的函数调用,这个语句会创建一个新的next()的执行环境上下文,并放入栈中。但是生成器不是这样的,它会重新激活对应的执行上下文。在这个例子中,是NinjaGenerator上下文,并把该上下文放入栈的顶部,从它上次离开的地方继续执行。
标准函数仅仅会被重复调用,每次调用都会创建一个新的执行环境上下文。相比之下,生成器的执行环境上下文则会暂时挂起并在将来恢复。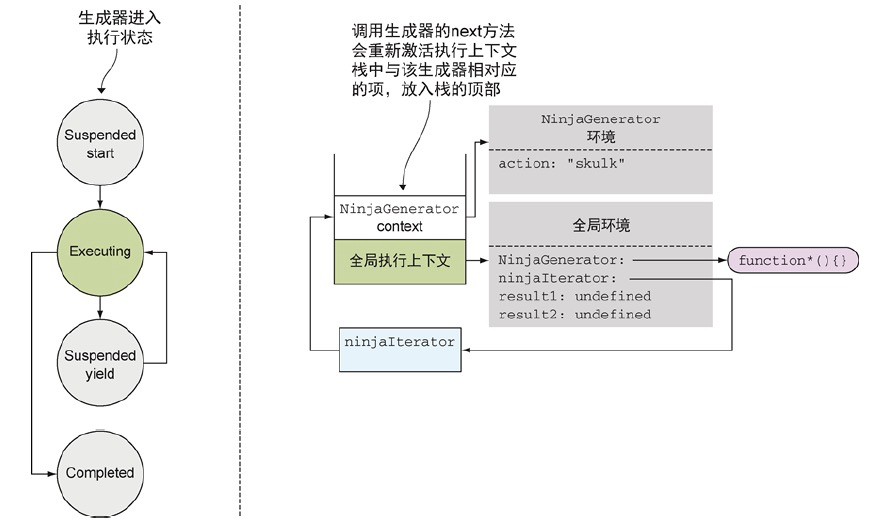
在我们例子中,由于第一次调用next方法,而生成器之前并没执行过,所以生成器开始执行并进入执行状态。当生成器执行到 yield "Hattori "+ action 的时候,生成器运行得到的表达式的结果为Hattori skulk,然后执行中又遇到了yield关键字。
这种情况表面了Hattori skulk是该生成器的第一个中间值。所以需要挂起生成器的执行并返回该值。从应用状态的角度来看,NinjaGenerator上下文离开了调用栈,但由于ninjaIterator还持有着对它的引用,故而它并未被销毁。现在生成器挂起了,又在非阻塞的情况下移动到了挂起让渡状态。持续在全局代码中恢复执行,并将生产出的值存入变量result1。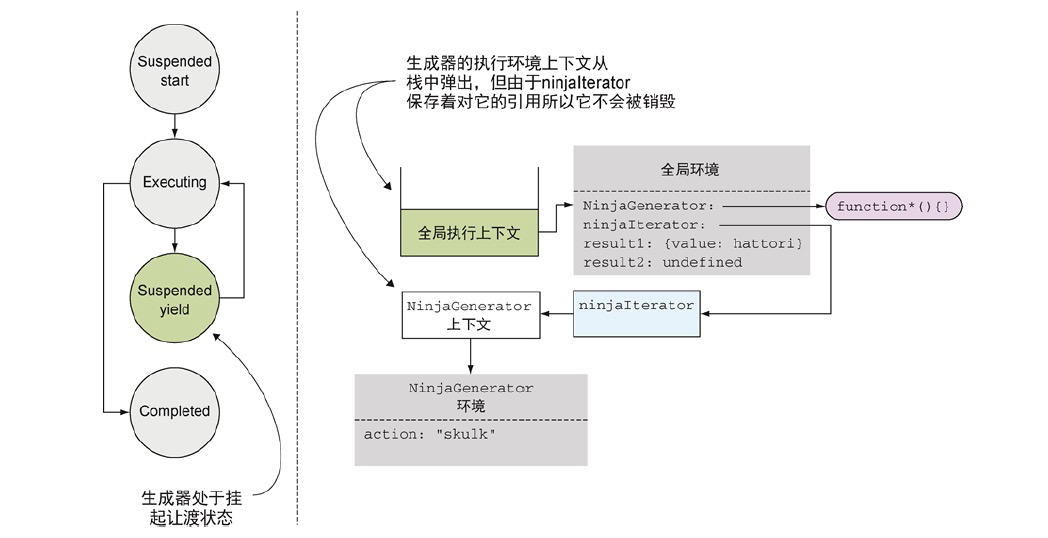
当遇到另一个迭代器调用时,代码继续执行:
const result2 = ninjaIterator.next();
- 生成器处于挂起让渡状态。
- 生成器的执行环境上下文从栈中弹出,但由于ninjaIterator保存着对它的引用所以它不会被销毁。
**
当生成器没再遇到yield表达式,而是遇到了一个return语句。这个语句会返回值Yoshi skulk并结束生成器的执行,随之生成器进入结束状态。
使用Promise
promise对象是对我们现在尚未得到但将来会得到值得占位符;它是对我们最终能够得到异步计算结果的一个保证。如果我们兑现了我们的承诺,那结果会得到一个值。如果发生了问题,结果这是一个错误,一个为什么不能交付的理由。
使用promise的一个最佳例子是从服务器获取数据:我们要承诺最终会拿到数据,但其实总有可能发生错误。
const ninjaPromise = new Promise((resolve,reject)=>{ // 通过内置Promise构造函数可以创建一个promise对象,需要向构造函数传入两个函数参数:resolve和reject
// 通过调用resolve函数,一个promise将被成功兑现
resolve("Hettori");
// 通过调用reject则promise被拒绝
// reject("An error resolving a promise")
})
ninjaPromise.then(ninja => { // 在一个promise对象上使用then方法后可以传入两个回调函数,promise对象成功会调用第一个回调函数
console.log(ninja) // "Hettori"
},err =>{ // 出现错误则调用第二个回调函数
console.log(err)
})
深入研究promise
promise对象用于作为异步任务结果的占位符。它代表了我们暂时还没获得当在未来有希望获得的值。基于这点原因,在一个promise对象的整个生命周期中,它会经历多种状态。
一个promise对象从等待(pending)状态开始,此时我们对承诺的值一无所知。因此一个等待状态的promise对象也称为未实现(unresolved)的promise。在程序执行的过程中,如果promise的resolve函数被调用,promise就会进入完成(fulfilled)状态,在该状态下我们能够成功获得承诺的值。
另一方面,如果promise的reject函数被调用,或者如果一个未处理的异常在promise调用的过程中发生了,promise就会进入到拒绝状态,尽管在该状态下我们无法获取承诺的值,但至少我们知道了原因。一旦某个promise进入到完成态或者拒绝态,它的状态都不能再切换。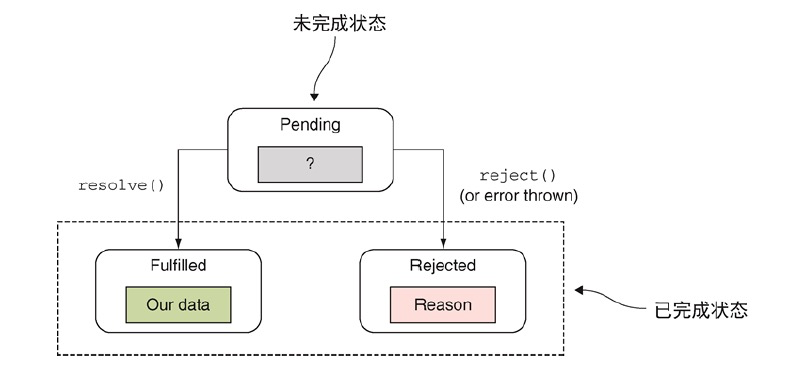
console.log("At code start");
const ninjaDelayedPromise = new Promise((resolve,reject)=>{
console.log("ninjaDelayedPromise executor");
setTimeout(()=>{
console.log("Resolve ninjaDelayedPromise");
resolve("Hattori");
},500)
})
ninjaDelayedPromise.then(ninja =>{
console.log(ninja);
})
const ninjaImmediatePromise = new Promise((resolve,reject)=>{
console.log("ninjaImmediatePromise executor.Immediate resolve.")
resolve("Yoshi");
})
ninjaImmediatePromise.then(ninja =>{
console.log(ninja);
})
console.log('At code end')
/*
* At code start
* ninjaDelayedPromise executor
* ninjaImmediatePromise executor.Immediate resolve.
* At code end
* Yoshi
* Resolve ninjaDelayedPromise
* Hattori
*/
拒绝promise
拒绝一个promise有两种方式:
- 显式拒绝:即在一个promise的执行函数中调用传入的reject方法;
- 隐式拒绝:正处理一个promise的过程中抛出了一个异常。 ```javascript / 显式拒绝 / const promise = new Promise((resolve,reject)=>{ reject(“Explicitly reject a promise”) // 可以通过调用传入的reject函数显式拒绝该promise })
promise.then( res => console.log(res), err => console.log(err) // 如果promise被拒绝了,则第二个回调函数将会被调用 )
promise .then(res => console.log(res)) .catch(err => console.log(err)) // 我们可以对catch方法进行链式调用,并将其传入回调函数error中,最终的结束条件相同
```javascript
/* 隐式拒绝 */
const promise = new Promise((resolve,reject)=>{
a++; // 如果在处理promise时出现未处理的异常,则会被隐式地拒绝
})
promise
.then(res => console.log(res))
.catch(err => console.log(err)) // 如果发生了异常,第二个回调函数error将被调用
链式调用promise
promise的链式调用可以解决处理一连串相互关联步骤导致的金字塔噩梦,嵌套太深形成难以维护的回调函数序列。
getJSON("data/ninjas.json")
.then(ninjas => getJson(ninjas[0].missionsUrl))
.then(missions => getJson(missions[0].detailsUrl))
.then(mission => console.log(mission))
.catch(err => console.log(err))
等待多个promise
对于等待多个独立的异步任务,promise也能显著地减少代码量。Promise.all 方法接收一个promises数组,并创建一个新的promise对象,当所有的promises均成功时,该promise为成功状态;反之,若其中任一promise失败,则该promise为失败状态。
Promise.all([getJSON("data/ninjas.json"),
getJSON("data/mapInfo.json"),
getJSON("data/plan.json"),]).then(res =>{
const [ninjas,mapInfo,plan] = res;
console.log(ninjas,mapInfo,plan)
}).catch(err => console.log(err))

若有收获,就点个赞吧
0 人点赞
