第一章 人工智能:新时代的开启
1.2人工智能 简史
横空出世:
- 1950 艾伦.图灵(Alan Turing)在论文《计算机器与智能》(Computing Machinery and Intelligence)中提出图灵测试(Turing test)
- 1951,马文.闵斯基 建立第一个神经网络机器SNARC(Stochastic Neural Analog Reinforcement Calculator)
- 1955 艾伦.纽厄尔等建立“逻辑理论家”,开创了一种被广泛应用的方法:搜索推理
1956年,美国的达特茅斯学院组织了一次讨论会,定义了人工智能学科
科技浪潮
第一次:伟大的首航 (1956-1974)
Project MAC->麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)的前身;1966,建立了第一个自然语言对话程序ELIZA
有限的计算能力,对模糊问题处理有限,70年代中期进入第一个冬天
第二次: 专家系统的兴衰(1980-1987)
专家系统逐步改变了人工智能发展的发现,开始专注于通过智能系统解决具体领域的实际问题
- 人工神经网络取得重要进展,经典论文《通过误差反向传播学习表示》,可以在神经网络的隐藏层中学习到对输入数据的有效表达,被广泛用于人工神经网络的训练
-
第三次 :厚积薄发,再造辉煌(2011-至今)
90年代后,开始专注于发展能解决具体问题的智能技术
- 在数学驱动下,数学模型和算法的发展:统计学习理论,支持向量机,概率图模型等,逐步应用于解决实际问题:安防监控,语音识别,网页搜索,购物推荐,自动化算法交易
- 大数据时代,以及计算机算力的提升。多层神经网络的深度学习被推广,在语音识别,图像分析,视频理解等诸多领域取得成功
AlphaGo,击败李世石和柯洁,点燃人工智能的热情。各国政府和商业机构纷纷规划人工智能的未来,由此迎来第三次热潮
1.3 各行各业的应用
1.4初露真容:人工智能与机器学习
什么是人工智能:
人工智能是通过机器来模拟人类认知能力的技术,核心能力是根据给定的输入做出判断或者预测
当代的人工智能普遍通过学习(Learning)来获得进行预测和判断的能力,这样的方法被称为机器学习(machine learning),称为人工智能的主流方法
从数据中学习
从一直数据中学习数据中蕴含的规律或判断规则
- 机器学习:监督学习和非监督学习
- 监督学习:有预测量的真实值通过提供反馈从而对学习过程起到了监督的作用(有具体参考结果作为评估)
-
在行动中学习
强化学习:
- 关注的不是某个判断是否准确,而是行动过程是否带来最大的收益
- 目标是获得一个策略去指导行动
- 以下几个部分
- 一组可以动态变化的状态
- 一组可以选取的动作
- 一个可以和决策主体进行交互的环境
- 回报规则。当决策主体通过行动使状态发生变化时,它会获得回报或者受到惩罚
- 强化学习从一个初始的策略开始,在学习过程中,决策主体通过行动和环境进行交互,不断获得反馈,兵根据反馈调整优化策略。持续不断的强化学习甚至获得比人类更优的决策机制
1.5小结
人工智能是研究如何通过机器来模拟人类认知能力的学科,通过人工定义或者从数据和行动中学习的方式获得预测和决策的能力。第二章 牛刀小试:察异辩花
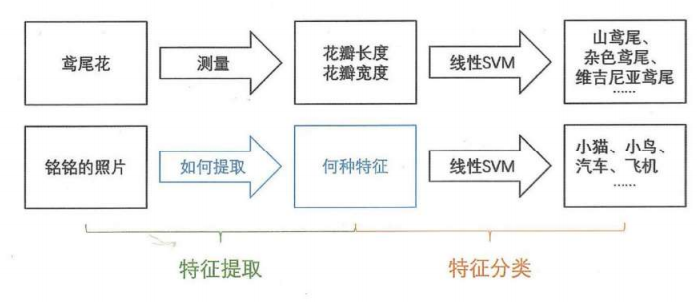
2.1 初学乍练:分类任务
分类应用
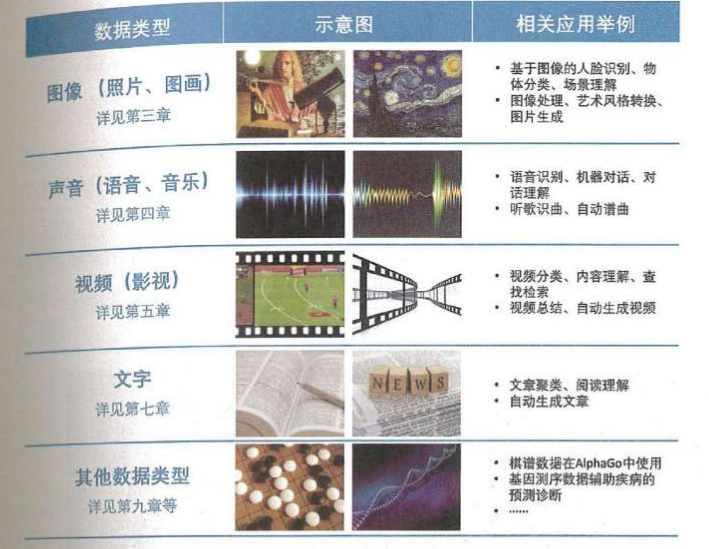
图像
人脸识别,物体识别,场景识别
图像处理,艺术风格转换,图片生成声音
语音识别,机器对话,对话理解
听歌识曲,自动谱曲视频
视频分类,内容理解,查找检索
视频总结,自动生成视频文字
文章聚类,阅读理解
自动生成文章其他数据
棋谱数据再AlphaGo中使用
基因检测数据辅助疾病预测2.2 含英咀华:提取特征
分类器:像人一样区分花朵这样的分类任务的人工智能系统
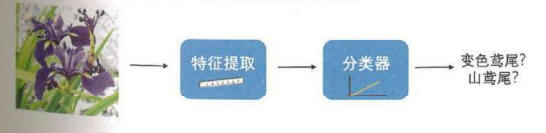

特征提取->分类器->预测结果: 特征的质量决定改了分类器最终分类效果的好坏
特征:
- 图像:人们设计了方向梯度直方图
- 声音:梅尔频率倒谱系数
- 视频:光流直方图
- 文本:词频率-逆文档频率
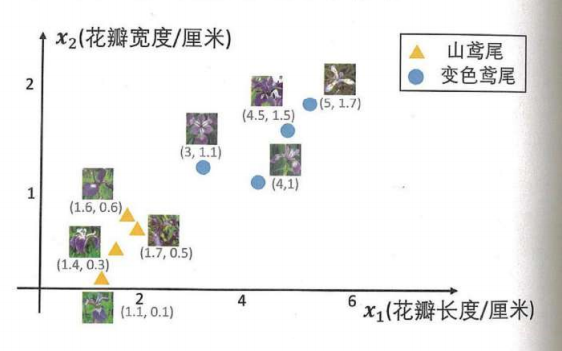
特征向量:
- 标识特征数据的一组数据
- 特征点:表示特征向量的点
- 特征空间:特征点构成的空间
-
2.3分门别类:分类器
训练分类器的步骤:
训练:从训练数据中的学习过程
数据是人工智能的支柱之一,人工智能系统的训练往往需要大量的数据- 数据训练
- 数据标注
- 测试:检验训练效果
-
训练分类器的方法(算法)
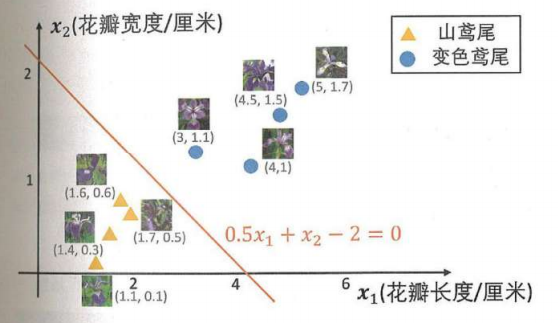
感知机:利用被误分类的训练数据调整现有分类器的参数,是的调整后的分类器判断更加准确
感知机学习算法步骤

第一步:选出初始分类器参数a1,a2,b
- 第二步:选取训练数据,如果这个数据被误分类,则按照一定规则更新参数
a1=>a1+nyx1,a2=>a2+nyx2,b=>b+nyn是学习率 - 第三步:不断重复第二步,直到训练数据中没有误分类数据为止
损失函数(预测值和真实值比较):
用来度量分类器输出错误程度的数学化表示
优化的过程,就是使得损失函数的值最小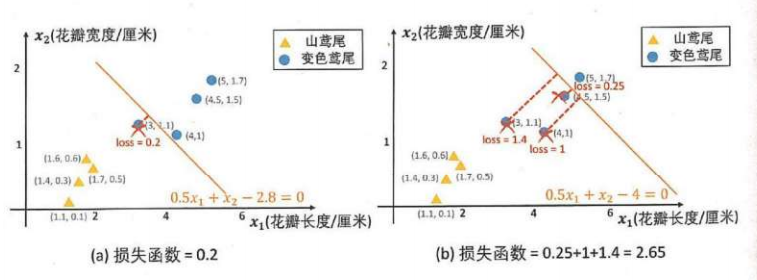
支持向量机(分类直线与数据点比较)


可信度:数据点离分类边界的距离
分类间隔:两个类别中离分类直线最近的点到直线的距离
支持向量:
把和阴影区域相接触的点称为支持向量
支持向量是哪些能够定义分类直线的训练数据,也是那些最难被分类的训练数据。直观的说,它们就是对求解分类任务最富有信息的数据损失函数
2.5 多分类问题

归一化(softmax):

归一化指数函数后,分类器输出的值有了更深层的含义,不仅可以告诉输出的类别,同时将只管的确信程度转变成衡量的概率2.6 大显身手:二分类在生活中的应用
人脸检测
pacs 癌症检测2.7小结
分类是事物归属到它所属类别的过程,特征和分类器是分类中的重要概念。
- 特征是事物自身的特点,提取的某方面数字或属性,可以用特征向量标识
- 分类器是从特征向量到类别的函数
- 分类过程分为:特征提取,分类器的训练以及测试应用
分类器的训练由训练算法完成:本文介绍了感知机和支持向量机。它们都有自己的损失函数,衡量分类器在训练过程中输出错误的程度
第三章 别具慧眼:识图识物
3.1 温故知新 :基于手工特征的图像分类
计算机眼中的图像:像素矩阵
矩阵(matrix)-像素(pixel)
照片的数字阵列为三阶张量(tensor),这个张量的长度与宽度就是图像的分辨率,高度为3. 三阶张量的高度称为通道(channel)数,因为彩色图像有三个通道。灰度图像可以看做高度为1张量(标量是0阶张量,向量是一阶张量,矩阵是二阶张量)
图像特征概述
让计算机通过一系列计算从数据中提取类似有没有翅膀,这样的特征极其困难

初期:手工设计各种特征
如图像的颜色,边缘(edge),纹理(texture)等基本性质,结合机器学习技术,能解决物体识别(object recognition)和物体检测(object detection)
从图像中提取特征便是对三阶张量进行运算的过程,其中非常重要的一种运算是卷积卷积运算

参与卷积的可以试向量,矩阵或三阶张量
两个向量卷积(convolution)的结果仍然是一个向量:结果是 n-m+1卷积过程(滑动-截取-计算内积)
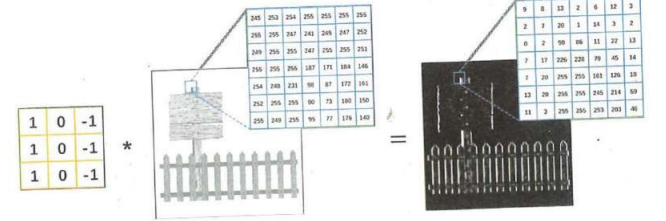
利用卷积提取图像特征
图像矩阵进行卷积运算,得到一个新的矩阵,可以将他作为原图像的一个特征卷积核:提取特征的
方向梯度直方图(histogram of oriented gradients,HOG)使用边缘检测技术和一些统计学方法,表示
 物体的轮廓
物体的轮廓首先利用卷积运算从图像中提取边缘特征
将图片划分若干区域,并对边缘特征按照方向和幅度进行统计,并形成直方图
拼接直方图,形成特征向量实验:
利用方向梯度直方图和多类支持向量机分类器,在CIFAR10数据集上完成图片分类的任务。
观察CIFAR10数据集,对不同类别图片有一个基本认识,并区分训练集和测试机
利用工具包提供的函数对图片提取方向梯度直方图,进行可视化
利用方向梯度直方图完成支持向量机分类器的训练,记录训练集上的分类正确率
利用训练好的支持向量机分类器对测试机的方向梯度直方图进行分类,记录测试集上的分类正确率3.2 另辟蹊径:基于深度神经网络的图像分类
从特征设计到特征学习
上一节 利用方向梯度直方图特征和支持向量机分类器完成图像识别,然而分类正确率并不满意。利用人工设计的图像特征,准确率已经到达瓶颈。
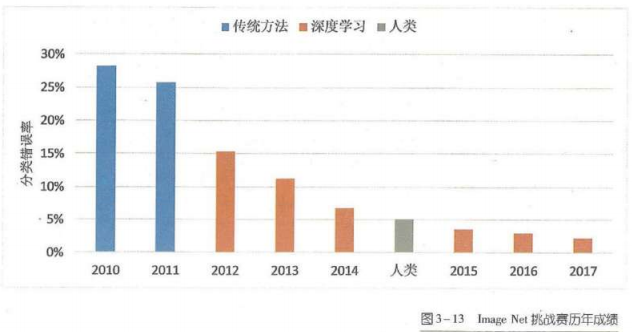
Image Net:
2012年多伦多参赛团队,利用深度神经网络,将分类错误率降低10个百分点,正确率84.7%
- 2015,微软的提出一种新的网络结构,错误率降低到4.9%
-
深度学习
深度神经网络之所以强大,因为可以自动从图像中学习有效的特征,更加智能
- 降低了人工智能系统的复杂度,将特征提取和分类集成在一起
-
深度神经网络的结构

深度神经网络由多层(layer)组成,第一层图像输入,以后每一层进行特征提取,多层变换之后,神经网络就可以将原始图像变换为高层次的抽象特征
卷积层,ReLU非线性激活层,池化层,全连接层,softmax归一化指数层
Alex Net
2012,ImageNet,挑战冠军Alex Net神经网络,主体部分有五个卷积层和三个全连接层组成。
- 五个卷积层依次对图像进行变换以提取特征。
- 每个卷积层后都有一个ReLU非线性激活层完成非线性变换。
- 第一,二,五个卷积层之后连接有最大池化层,用以降低特征图的分辨率。
- 经过五个卷积层以及相连的非线性激活层与池化层后,特征图被转为4096维的特征向量。
- 再经过两次全连接层和ReLU层的变换之后,成为最终的特征向量。
在经过一个全连接层和一个softmax归一化指数层后,得到对图片所属类别的预测
卷积层(convolutional layer)
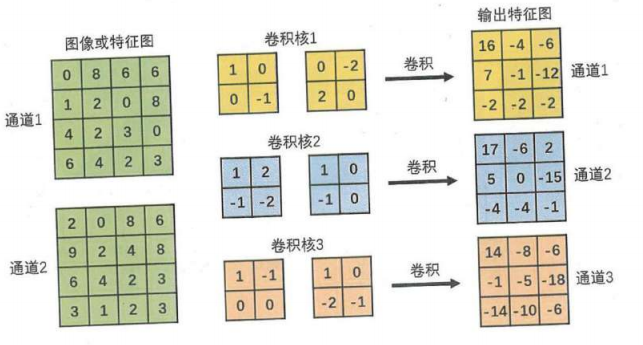
是深度神经网络在处理图像时十分常用的一种层,卷积神经网络(convolutional neural network)
对原始图像或者上一层的特征进行变换的层,全连接层(full-connected layer)
使用若干维数相同的向量与输入向量做内积操作,并将所有结果拼接成一个向量作为输出。Yk=X*Wk+bk
归一化指数层(softmax layer)
分类网络的最后一层,以一个长度和类别个数相等给的特征向量作为输入(这个特征向量通常来自一个全连接层的输出),然后输出图像属于各个类别的概率
非线性激活层(non-linear activation layer)
卷积运行和全连接层中的运算,都是线性函数,若干次运算是可以叠加称为一次运算的<br /> 如果每次线性运算后,再进行一次非线性(non-linear)运算,那么每次变换的效果就可以得以保留
常见非线性函数

逻辑函数(logistic funciton)
- 双曲正切函数(hyperbolic tangent funciton)
线性整流函数(rectified linear funciton)(被广泛应用)
池化层
降低特征图的分辨率
- 最大池化层:取每一区块最大值
- 平均池化层:取每一区块平均值
-
人工神经网络的训练
训练的本质就是寻找最佳参数的过程。卷积层中所有卷积核的元素值,全连接层中所有内积运算的系数都是参数
人工智能提出了反向传播算法
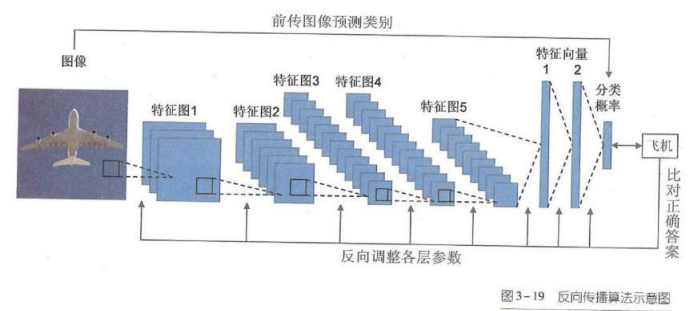
网络中,经过逐层的计算,最终得到预测的属于每一类的概率。将结果与正确答案对比,如果预测结果不够好,那么从最后一层开始,逐层调整神经网络的参数,使得网络对这个训练样本能够做出更好的预测梯度计算的链式法则(chain rule)
随机梯度下降(stochastic gradient descent)
3.3“网不厌深”深度神经网络的发展与挑战
层数越多,参数更多,效果更好
- 数据就像燃料,计算能力(GPU)
- 过拟合(overfitting)和欠拟合(under-fitting)


- 权值衰减(weight decay)
- 正则化(regularization)
- 梯度消失(gradient vanish)问题
第四章 耳听八方:析音赏乐
4.1洗耳恭听:听声的艺术

声音的数字化
从声波到mp3文件,经历了采样(sampling),量化(quantization)和编码(encoding)等步骤
频谱理解音乐
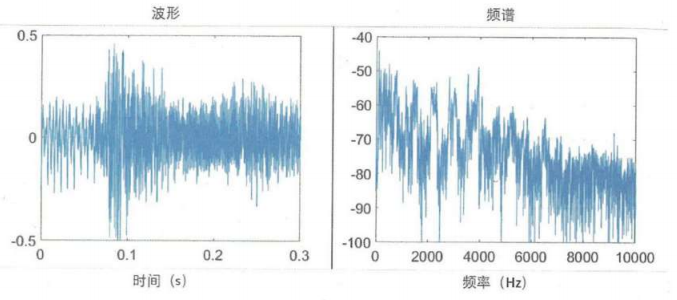
频谱横坐标是频率,总工作表是频谱幅度,是相应频率声音对应的振幅
乐音的三要素:响度、音调、音色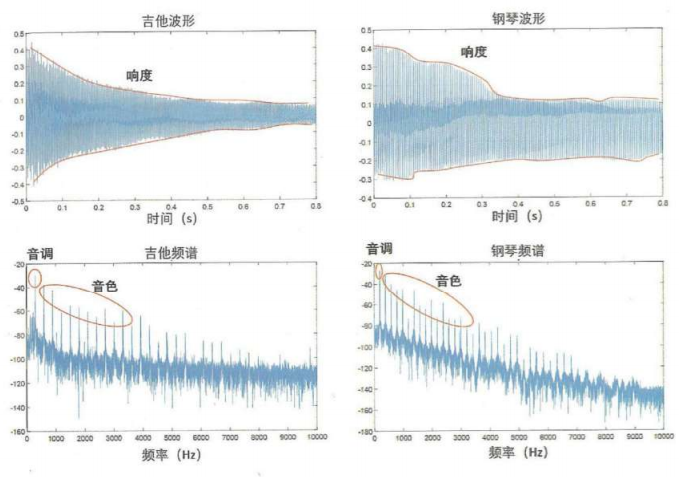
4.2 丝竹管弦:音乐风格分类
计算机“耳中”的风格
经典的声学特征:梅尔频率倒谱系数MFCC
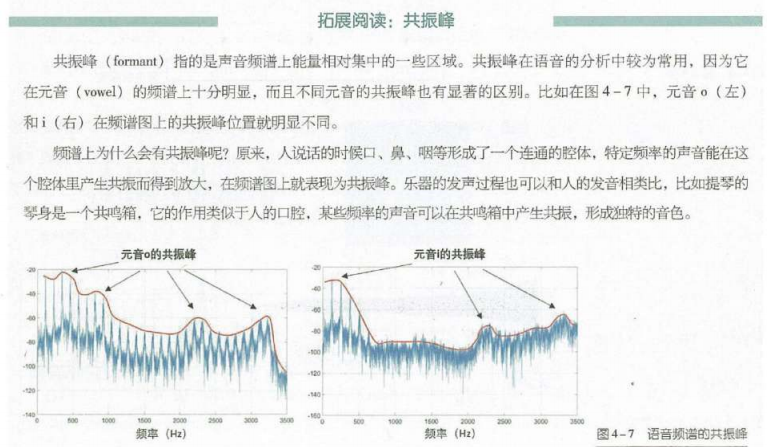
MFCC特征的维数很低,可以粗略的刻画出频谱的形状,因而可以大致描述出不同频率声音能量高低。对频谱的粗略刻画还可以表达出声音的一个重要特征—共振峰
MFCC特征提取
用梅尔频率对频谱进行处理-> 得到一组26维的特征 ->在计算它的倒谱得到13维MFCC特征
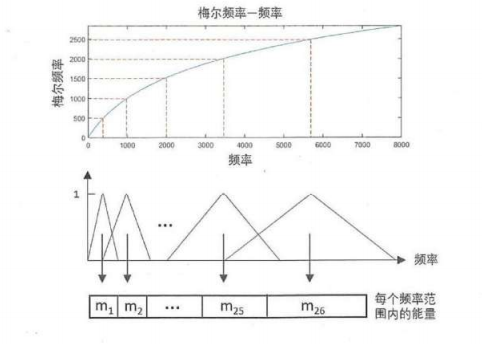
梅尔频率刻度下等长的频率区间对应到普通频率下变为不等长的区间;低频部分分辨率高,高频部分分辨率低。与人耳听觉感受相似。
深度学习方法
图像处理中使用了卷积层和池化层,提取图像特征。图像有两个空间维度,不过声音只有一个时间维度;所以特区音频特征的卷积核与处理图像的不同。
经过卷积层和赤化层,神经网络提取了比MFCC更强大的特征
对特征进行分类,通过全连接层得到一个长度与风格类型相同的数列
归一化指数层得到属于每一种风格的概率
4.3 言听计从:语音识别技术
语音识别的原理
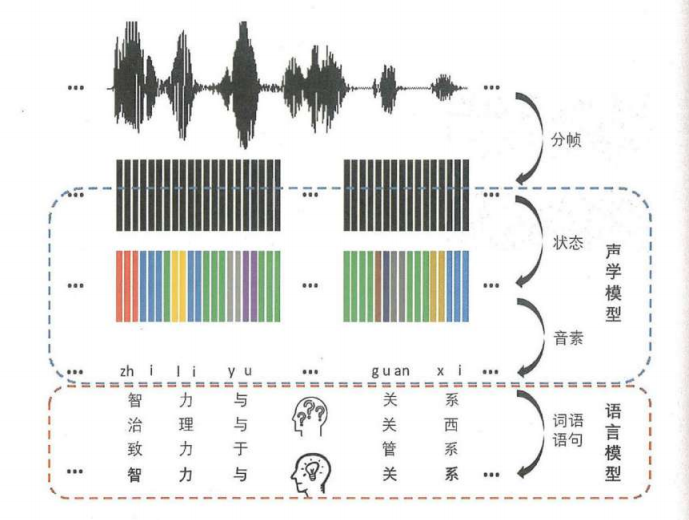
音乐风格分类秩序对一整段音频做一次分类。 语音识别需要对每一个音都进行分类,文字数量成千上万。
- 语音识别规律:汉语的声学特性:拼音
-
声学模型(acoustic model):
语言模型(language model):
4.4 听声辩曲:乐曲检索技术

音乐查找是模糊的,同一曲目虽然相似但不相同 ,相似度作为评判
在乐曲上按照时间顺序依次截取音乐片段长度一致的段落,相邻段落之间时间间隔可大可小,保证他们在时间上有较大的重叠,称为“窗口扫描”。4.5小结
声音的数字化
- 频谱的计算,理解音调和音色
- MFCC特征对频谱在提炼,得到更低维的特征
- 神经网络对音乐风格的分类
-
第五章 冰雪聪明:看懂视频
5.1 化静为动:从图像到视频
5.2 明察秋毫:视频行为识别
视频行为的识别应用:
人机交互领域
-
行为识别的挑战
识别的难度:拍摄距离,光照,角度以及遮挡

行为的类内差异大
- 行为定义的不明确
- 环境背景等差异大

 、
、
数据集:
UCF101:YouTube 13320个行为视频,包含101个类别;ImageNet 1400多万图片,2万个类别
行为识别的重要特征:运动
运动的刻画:光流
光流直方图
5.3 基于深度学习的视频行为识别
基于单帧的识别方法
双流卷积神经网络
长视频的梳理:时序分段网络
第六章 无师自通:分门别类
第七章 识文断字:理解文本
第八章 神来之笔:创作图画
第九章 运筹帷幄:围棋高手

若有收获,就点个赞吧
0 人点赞
