
推荐书籍:
思维:
《思维简史:从丛林到宇宙》
数据处理:
《数据挖掘:概念与技术》
《Pentaho Kettle解决方案》
《精益数据分析》
《Small Data》
《利用Python进行数据分析》
商业:
《洛克菲勒留给儿子的38封信》
《商业冒险:华尔街的12个经典故事》
《从0到1:开启商业与未来的秘密》
《商业的本质》
刷题网站
- LeetCode
- Kaggel
浙江大学 ACM 的 OnlineJudge http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=1
补充
python库
Scrapy:网页爬虫
- Pandas:数据浏览与预处理
- numpy:数组运算
- scipy:高效的科学计算
- matplotlib:数据可视化工具
- scikit-learn:机器学习包
- keras/TensorFlow:深度学习框架
-
机器学习
R
C++ mlpack,Shark
Java WEKA Machine Learning Workbench
开篇词
你为什么需要数据分析能力?
数据分析的影响
通过数据分析,我们可以更好地了解用户画像,为企业做留存率、流失率等指标分析,进而精细化产品运营
- 如果你关注比特币,数据分析可以帮助你预测比特币的走势
- 面对生活中遇到的种种麻烦,数据分析也可以提供解决方案,比如信用卡反欺诈,自动屏蔽垃圾邮件等
高效的学习方法(MAS 方法)
Multi-Dimension:
想要掌握一个事物,就要从多个角度去认识它。Ask:
不懂就问,程序员大多都很羞涩,突破这一点,不懂就问最重要Sharing:
最好的学习就是分享。用自己的语言讲出来,是对知识的进一步梳理数据分析学习
第一类是基础概念
这是我们学习的基础,一定不能落下第二类是工具
这个部分可以很好地锻炼你的实操能力第三类是题库
题库的作用是帮你查漏补缺,在这个过程中,你会情不自禁地进行思考收获内容
数据和算法思维
如果你将数据视为财富,将数据分析视为获得财富的工具,那么在大数据时代,你将获得更宽广的视野用好工具
你将拥有收集数据、处理数据、得到结果的能力,它会让你在工作中游刃有余。
第一模块 数据分析基础篇
01| 数据分析全景图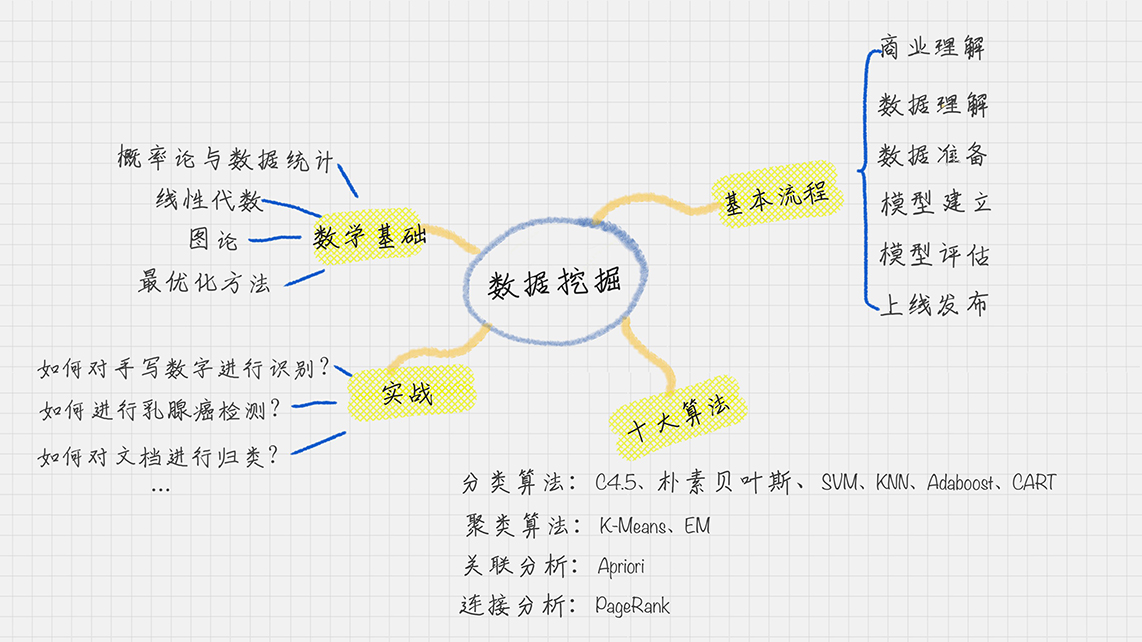
课程内容
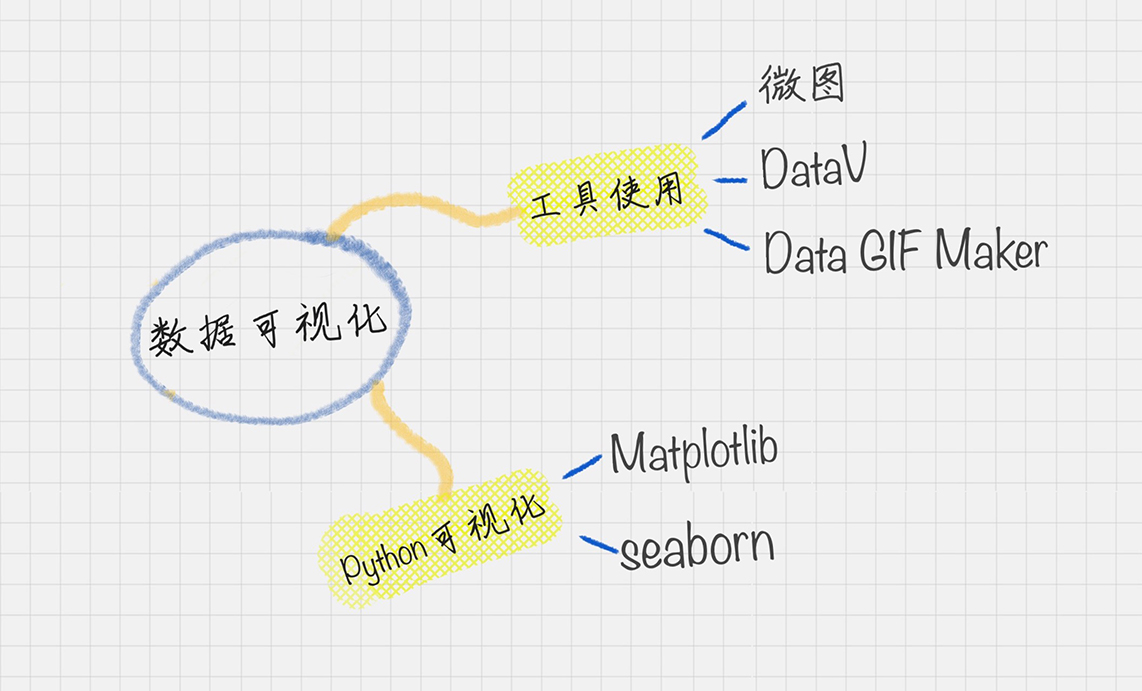
数据可视化
- 第一种:使用python: Matplotlib , Seaborn
- 第二种:使用第三方工具:微图,DataV,Data GIF Maker
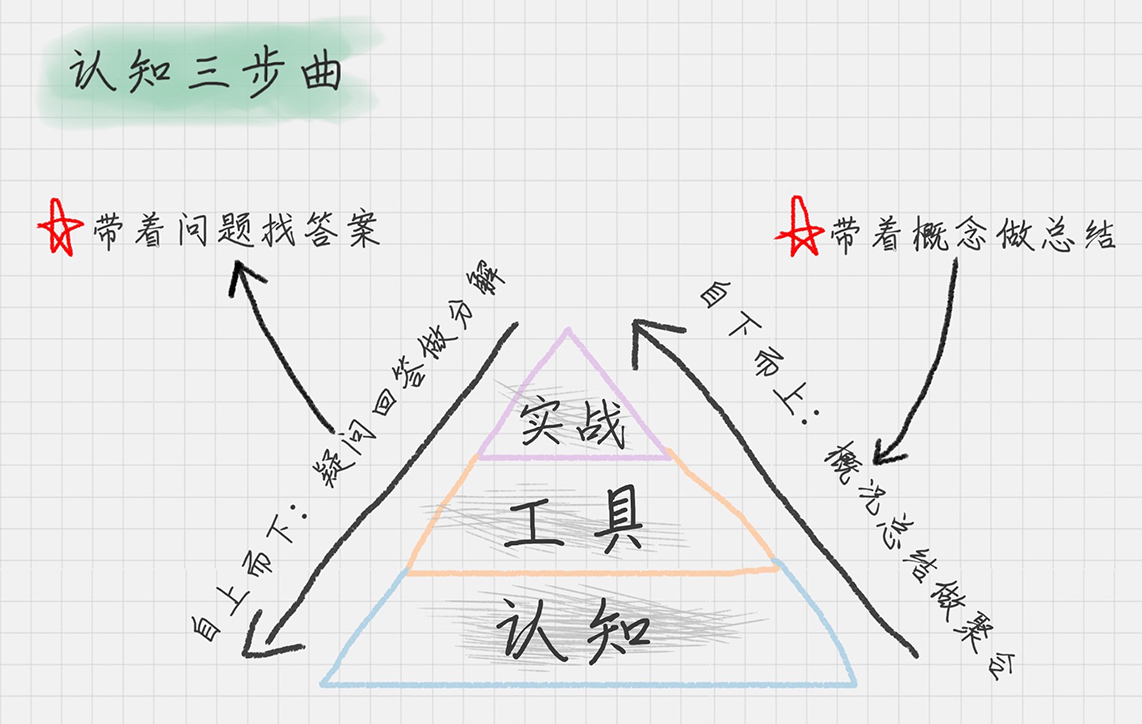
修炼指南
两条准则
- 不重复造轮子
- 工具决定效率:选择使用者最多的工具
02|数据分析学习路径
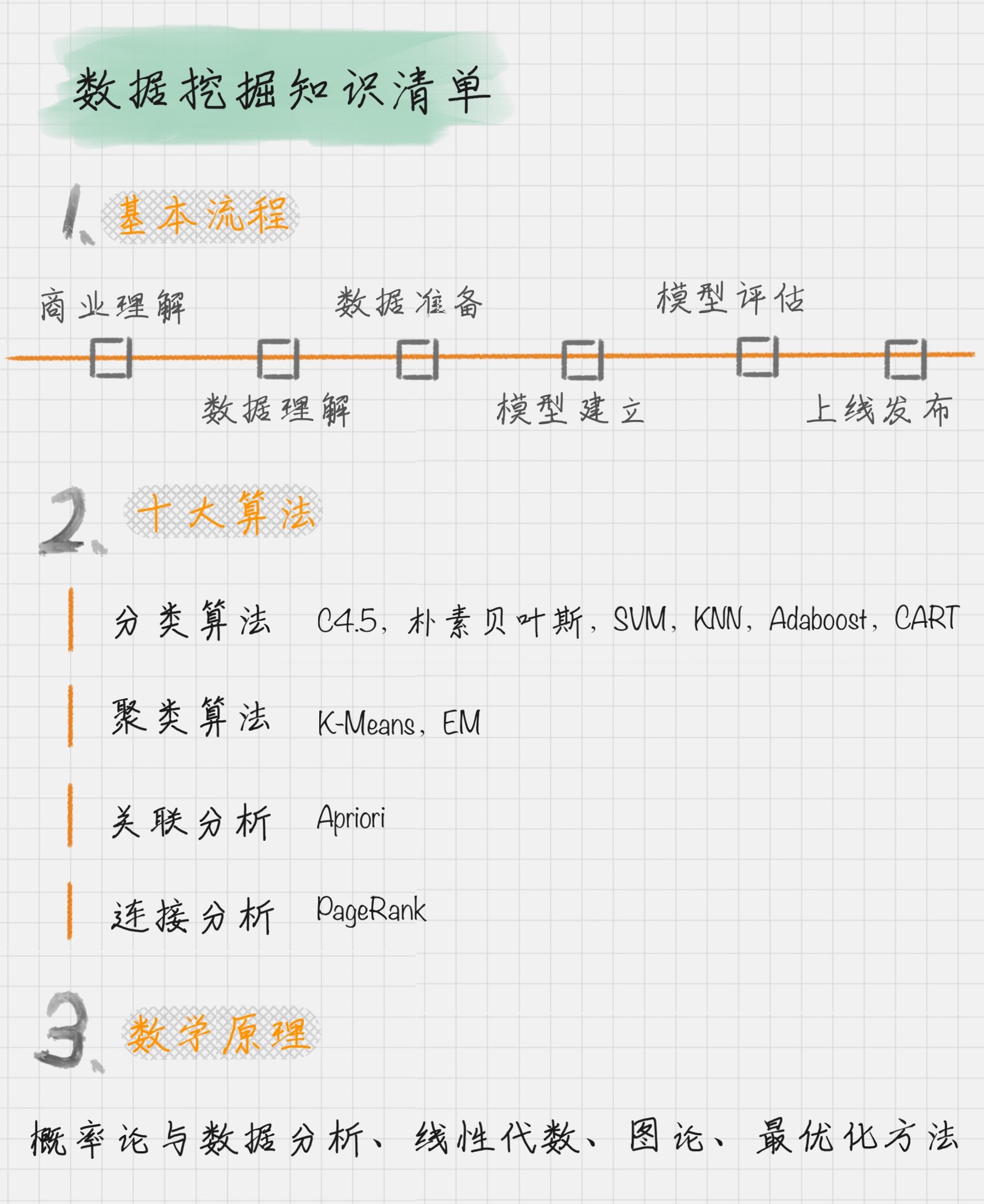
数据挖掘的基本流程
商业理解
数据挖掘不是我们的目的,我们的目的是更好地帮助业务,所以第一步我们要从商业的角度理解项目需求,在这个基础上,再对数据挖掘的目标进行定义
数据理解
尝试收集部分数据,然后对数据进行探索,包括数据描述、数据质量验证等。这有助于你对收集的数据有个初步的认知。
数据准备
开始收集数据,并对数据进行清洗、数据集成等操作,完成数据挖掘前的准备工作
模型建立
选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果
模型评估
对模型进行评价,并检查构建模型的每个步骤,确认模型是否实现了预定的商业目标
上线发布
模型的作用是从数据中找到金矿,也就是我们所说的“知识”,获得的知识需要转化成用户可以使用的方式,呈现的形式可以是一份报告,也可以是实现一个比较复杂的、可重复的数据挖掘过程。数据挖掘结果如果是日常运营的一部分,那么后续的监控和维护就会变得重要
数据挖掘的十大算法
- 分类算法:C4.5,朴素贝叶斯(Naive Bayes),SVM,KNN,Adaboost,CART
- 聚类算法:K-Means,EM
- 关联分析:Apriori
- 连接分析:PageRank
1. C4.5
C4.5 算法是得票最高的算法,可以说是十大算法之首。C4.5 是决策树的算法,它创造性地在决策树构造过程中就进行了剪枝,并且可以处理连续的属性,也能对不完整的数据进行处理。它可以说是决策树分类中,具有里程碑式意义的算法2.朴素贝叶斯(Naive Bayes)
朴素贝叶斯模型是基于概率论的原理,它的思想是这样的:对于给出的未知物体想要进行分类,就需要求解在这个未知物体出现的条件下各个类别出现的概率,哪个最大,就认为这个未知物体属于哪个分类3.SVM
SVM 的中文叫支持向量机,英文是 Support Vector Machine,简称 SVM。SVM 在训练中建立了一个超平面的分类模型。如果你对超平面不理解,没有关系,我在后面的算法篇会给你进行介绍4. KNN
KNN 也叫 K 最近邻算法,英文是 K-Nearest Neighbor。所谓 K 近邻,就是每个样本都可以用它最接近的 K 个邻居来代表。如果一个样本,它的 K 个最接近的邻居都属于分类 A,那么这个样本也属于分类 A。5. AdaBoost
Adaboost 在训练中建立了一个联合的分类模型。boost 在英文中代表提升的意思,所以 Adaboost 是个构建分类器的提升算法。它可以让我们多个弱的分类器组成一个强的分类器,所以 Adaboost 也是一个常用的分类算法6. CART
CART 代表分类和回归树,英文是 Classification and Regression Trees。像英文一样,它构建了两棵树:一棵是分类树,另一个是回归树。和 C4.5 一样,它是一个决策树学习方法7. Apriori
Apriori 是一种挖掘关联规则(association rules)的算法,它通过挖掘频繁项集(frequent item sets)来揭示物品之间的关联关系,被广泛应用到商业挖掘和网络安全等领域中。频繁项集是指经常出现在一起的物品的集合,关联规则暗示着两种物品之间可能存在很强的关系8. K-Means
K-Means 算法是一个聚类算法。你可以这么理解,最终我想把物体划分成 K 类。假设每个类别里面,都有个“中心点”,即意见领袖,它是这个类别的核心。现在我有一个新点要归类,这时候就只要计算这个新点与 K 个中心点的距离,距离哪个中心点近,就变成了哪个类别9. EM
EM 算法也叫最大期望算法,是求参数的最大似然估计的一种方法。原理是这样的:假设我们想要评估参数 A 和参数 B,在开始状态下二者都是未知的,并且知道了 A 的信息就可以得到 B 的信息,反过来知道了 B 也就得到了 A。可以考虑首先赋予 A 某个初值,以此得到 B 的估值,然后从 B 的估值出发,重新估计 A 的取值,这个过程一直持续到收敛为止。EM 算法经常用于聚类和机器学习领域中。10. PageRank
PageRank 起源于论文影响力的计算方式,如果一篇文论被引入的次数越多,就代表这篇论文的影响力越强。同样 PageRank 被 Google 创造性地应用到了网页权重的计算中:当一个页面链出的页面越多,说明这个页面的“参考文献”越多,当这个页面被链入的频率越高,说明这个页面被引用的次数越高。基于这个原理,我们可以得到网站的权重划分数据挖掘的数学原理
1. 概率论与数理统计
比如条件概率、独立性的概念,以及随机变量、多维随机变量的概念。很多算法的本质都与概率论相关,所以说概率论与数理统计是数据挖掘的重要数学基础2. 线性代数
向量和矩阵是线性代数中的重要知识点,它被广泛应用到数据挖掘中,比如我们经常会把对象抽象为矩阵的表示,一幅图像就可以抽象出来是一个矩阵,我们也经常计算特征值和特征向量,用特征向量来近似代表物体的特征。这个是大数据降维的基本思路。基于矩阵的各种运算,以及基于矩阵的理论成熟,可以帮我们解决很多实际问题,比如 PCA 方法、SVD 方法,以及 MF、NMF 方法等在数据挖掘中都有广泛的应用3. 图论
社交网络的兴起,让图论的应用也越来越广。人与人的关系,可以用图论上的两个节点来进行连接,节点的度可以理解为一个人的朋友数。我们都听说过人脉的六度理论,在 Facebook 上被证明平均一个人与另一个人的连接,只需要 3.57 个人。当然图论对于网络结构的分析非常有效,同时图论也在关系挖掘和图像分割中有重要的作用4. 最优化方法
最优化方法相当于机器学习中自我学习的过程,当机器知道了目标,训练后与结果存在偏差就需要迭代调整,那么最优化就是这个调整的过程。一般来说,这个学习和迭代的过程是漫长、随机的。最优化方法的提出就是用更短的时间得到收敛,取得更好的效果。03|Python 基础语法

输入与输出
name = raw_input("What's your name?")sum = 100+100print ('hello,%s' %name)print ('sum = %d' %sum)
判断语句:if … else …
if score>= 90:print 'Excellent'else:if score < 60:print 'Fail'else:print 'Good Job'
循环语句:for … in<br />
sum = 0for number in range(11):sum = sum + numberprint sum
for 循环是一种迭代循环机制,迭代即重复相同的逻辑操作。如果规定循环的次数,我们可以使用 range 函数,它在 for 循环中比较常用。range(11) 代表从 0 到 10,不包括 11,也相当于 range(0,11),range 里面还可以增加步长,比如 range(1,11,2) 代表的是[1,3,5,7,9]。
循环语句: while
sum = 0number = 1while number < 11:sum = sum + numbernumber = number + 1print sum
数据类型:列表、元组、字典、集合
列表:[]
lists = ['a','b','c']lists.append('d')print listsprint len(lists)lists.insert(0,'mm')lists.pop()print lists
列表是 Python 中常用的数据结构,相当于数组,具有增删改查的功能,我们可以使用 len() 函数获得 lists 中元素的个数;使用 append() 在尾部添加元素,使用 insert() 在列表中插入元素,使用 pop() 删除尾部的元素。
元组 (tuple)
tuples = ('tupleA','tupleB')print tuples[0]
元组 tuple 和 list 非常类似,但是 tuple 一旦初始化就不能修改。因为不能修改所以没有 append(), insert() 这样的方法,可以像访问数组一样进行访问,比如 tuples[0],但不能赋值。
字典 {dictionary}
# -*- coding: utf-8 -*#定义一个dictionaryscore = {'guanyu':95,'zhangfei':96}#添加一个元素score['zhaoyun'] = 98print score#删除一个元素score.pop('zhangfei')#查看key是否存在print 'guanyu' in score#查看一个key对应的值print score.get('guanyu')print score.get('yase',99)
字典其实就是{key, value},多次对同一个 key 放入 value,后面的值会把前面的值冲掉,同样字典也有增删改查。增加字典的元素相当于赋值,比如 score[‘zhaoyun’] = 98,删除一个元素使用 pop,查询使用 get,如果查询的值不存在,我们也可以给一个默认值,比如 score.get(‘yase’,99)。
集合:set
s = set(['a', 'b', 'c'])s.add('d')s.remove('b')print sprint 'c' in s
集合 set 和字典 dictory 类似,不过它只是 key 的集合,不存储 value。同样可以增删查,增加使用 add,删除使用 remove,查询看某个元素是否在这个集合里,使用 in。
注释:
注释在 python 中使用 #,如果注释中有中文,一般会在代码前添加 # — coding: utf-8 -。如果是多行注释,使用三个单引号,或者三个双引号,比如:
# -*- coding: utf-8 -*'''这是多行注释,用三个单引号这是多行注释,用三个单引号这是多行注释,用三个单引号'''
引用模块 / 包:import
# 导入一个模块import model_name# 导入多个模块import module_name1,module_name2# 导入包中指定模块from package_name import moudule_name# 导入包中所有模块from package_name import *
Python 语言中 import 的使用很简单,直接使用 import modulename 语句导入即可。这里 import 的本质是什么呢?import 的本质是路径搜索。import 引用可以是模块 module,或者包 package。针对 module,实际上是引用一个.py 文件。而针对 package,可以采用 from … import …的方式,这里实际上是从一个目录中引用模块,这时目录结构中必须带有一个 _init.py 文件。
函数:def
def addone(score):return score + 1print addone(99)
浙江大学 ACM 的 OnlineJudge
http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=1
问题
如果我想在 Python 中引用 scikit-learn 库该如何引用?
pip install scikit-learnimport scikit-learn
求 1+3+5+7+…+99 的求和,用 Python 该如何写?
方法一:sum函数print(sum(range(1,100,2)))方法二:if迭代a = 0for i in range(1,100,2):a += iprint(a)方法三:while循环i = 1b = 0while i < 100:if i % 2 != 0 :b += ii +=1print(b)
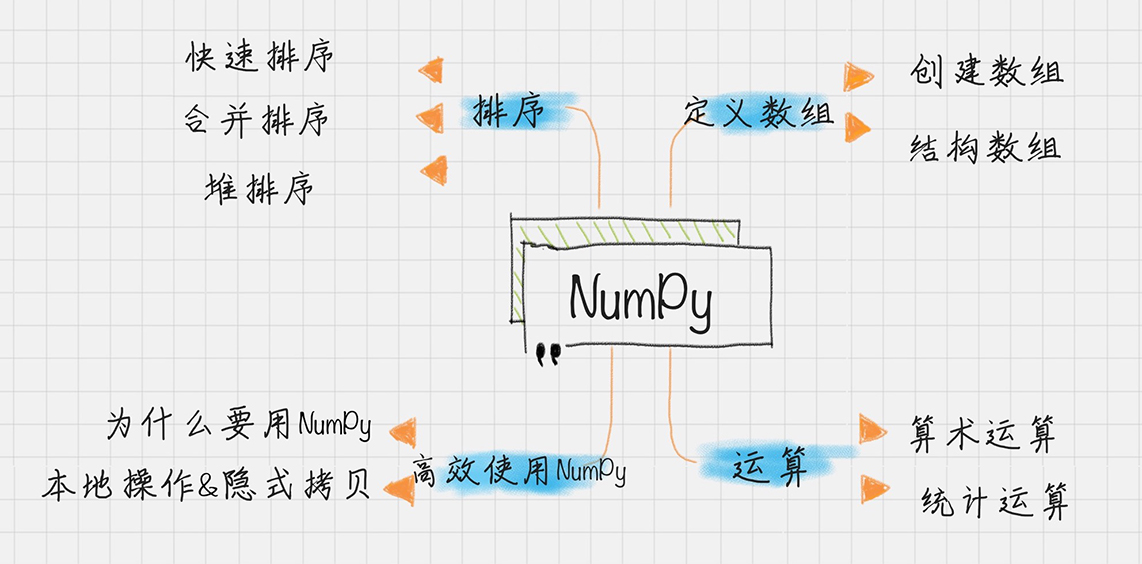
04丨Python科学计算:用NumPy快速处理数据
05丨Python科学计算:Pandas

Series 和 DataFrame 这两个核心数据结构,他们分别代表着一维的序列和二维的表结构。基于这两种数据结构,Pandas 可以对数据进行导入、清洗、处理、统计和输出。
数据结构:Series
Series 是个定长的字典序列。说是定长是因为在存储的时候,相当于两个 ndarray,这也是和字典结构最大的不同。因为在字典的结构里,元素的个数是不固定的。
Series 有两个基本属性:index 和 values。在 Series 结构中,index 默认是 0,1,2,……递增的整数序列,当然我们也可以自己来指定索引,比如 index=[‘a’, ‘b’, ‘c’, ‘d’]。
DataFrame 类型数据结构类似数据库表
它包括了行索引和列索引,我们可以将 DataFrame 看成是由相同索引的 Series 组成的字典类型。
数据导入和输出
Pandas 允许直接从 xlsx,csv 等文件中导入数据,也可以输出到 xlsx, csv 等文件,非常方便。
数据清洗
1. 删除 DataFrame 中的不必要的列或行
2. 重命名列名 columns,让列表名更容易识别
3. 去重复的值
4. 格式问题
更改数据格式
数据间的空格
大小写转换
查找空值
使用 apply 函数对数据进行清洗
数据统计
数据表合并
- 基于指定列进行连接
2. inner 内连接
3. left 左连接
4. right 右连接
5. outer 外连接
如何用 SQL 方式打开 Pandas
06 | 学数据分析要掌握哪些基本概念?
百货商店利用数据预测用户购物行为属于商业智能,他们积累的顾客的消费行为习惯会存储在数据仓库中,通过对个体进行消费行为分析总结出来的规律属于数据挖掘
Business Intelligence 预测用户行为
商业智能 BI/Business Intelligence - 预测用户行为
基于数据仓库,经过数据挖掘之后,得到商业价值/商业报告(黄金)的过程。商业报告需要经过地基 DM、搬运工 ETL/Extraction-Transformation-Loading(数据抽取、转换和加载)、科学家 DM,才能得到
Data Warehouse 存储用户数据 - 金矿
将多个数据来源中的数据进行汇总、整理而得,需消除不一致性,为后续分析和挖掘做基础**
元数据/MetaData 数据元的结构化集合
描述其他数据的数据也称 中介数据。如图书的一套元数据就是:书名、作者、出版社等这个集合。方便于处理数据间的复杂关系,可定义数据的抽取和转换规则及各种信息。调度数据、获取数据都是基于元数据,方便管理数据仓库
数据元/Data Element -
最小数据单元。上面提到的书名、作者这些就是数据元
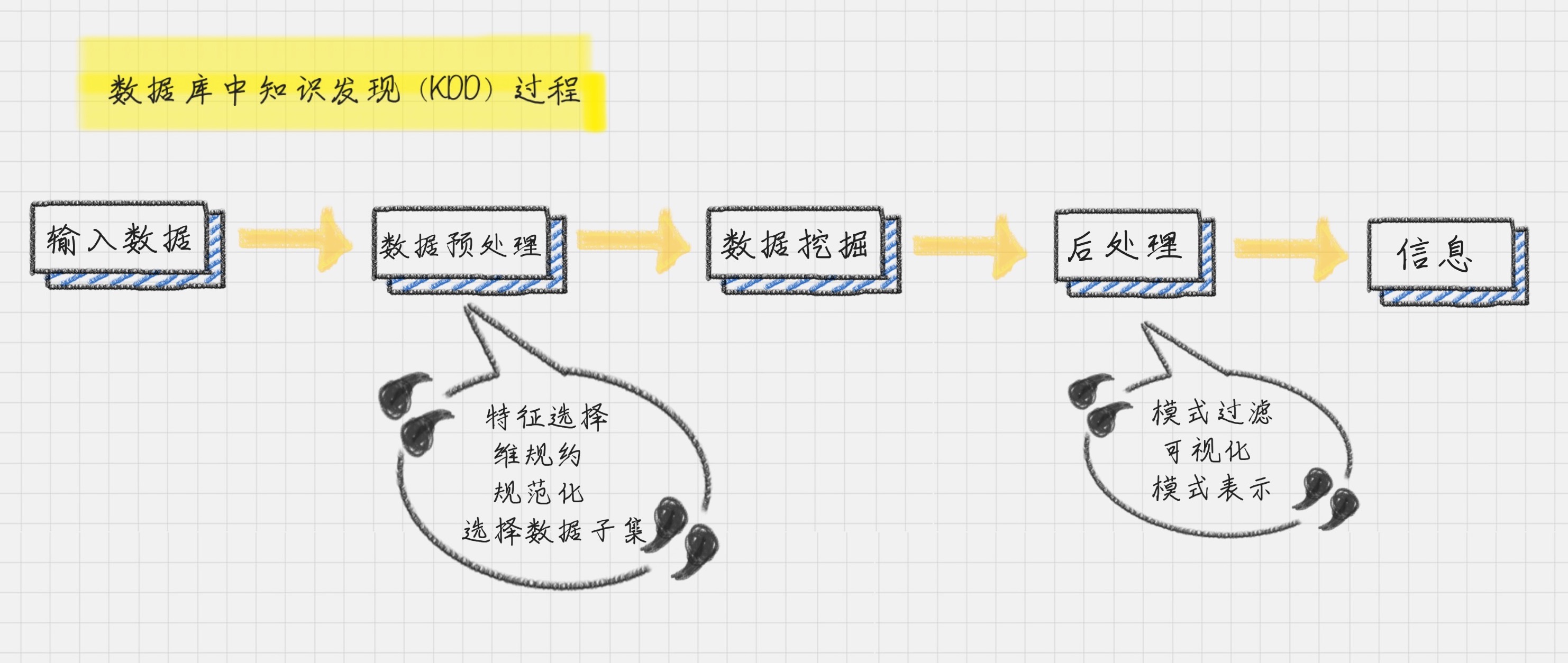
数据挖掘的流程 Knowledge Discovery in Database 简称 KDD
1. 分类
就是通过训练集得到一个分类模型,然后用这个模型可以对其他数据进行分类。这里需要说明下训练集和测试集的概念。
训练集:
训练集是用来给机器做训练的,通常是人们整理好训练数据,以及这些数据对应的分类标识。通过训练,机器就产生了自我分类的模型,然后机器就可以拿着这个分类模型,对测试集中的数据进行分类预测。
测试集
同样如果测试集中,人们已经给出了测试结果,我们就可以用测试结果来做验证,从而了解分类器在测试环境下的表现。
2. 聚类
聚类就是将数据自动聚类成几个类别,聚到一起的相似度大,不在一起的差异性大。我们往往利用聚类来做数据划分。
3. 预测
顾名思义,就是通过当前和历史数据来预测未来趋势,它可以更好地帮助我们识别机遇和风险
4. 关联分析
就是发现数据中的关联规则,它被广泛应用在购物篮分析,或事务数据分析中。比如我们开头提到的那个案例。数据挖掘要怎么完成这些任务呢?它需要将数据库中的数据经过一系列的加工计算,最终得出有用的信息。
数据预处理
1. 数据清洗
主要是为了去除重复数据,去噪声(即干扰数据)以及填充缺失值。
2. 数据集成
3. 数据变换
归一化
将属性数据按照比例缩放,这样就可以将数值落入一个特定的区间内,比如 0~1 之间
数据后处理
是将模型预测的结果进一步处理后,再导出
比如在二分类问题中,一般能得到的是 0~1 之间的概率值,此时把数据以 0.5 为界限进行四舍五入就可以实现后处理
白话数据概念 - 追女孩
- 商业智能会告诉你要追哪个?成功率多大?
- 数据仓库会告诉你存储了这几个女孩的信息,你要吗?
- 每个女孩有单独文件夹(元数据),里面有姓名生日(数据元 - 数据单元)等
- 数据挖掘会帮助你确定追哪个女孩,并且整理好套路给你用
- 分类算法:御姐还是萝莉
- 女孩太多 - 聚类算法
- 你想要女孩的闺蜜 - 关联分析算法
- 给你推荐女孩的人太多,有重复 - 数据清洗
- 为了方便记忆,把不同朋友推荐的女孩信息和成一个 - 数据集成
- 有些女孩给你的体重信息是斤有些是公斤 - 数据变换
- 最后数据可视化
07 | 用户画像:标签化就是数据的抽象能力
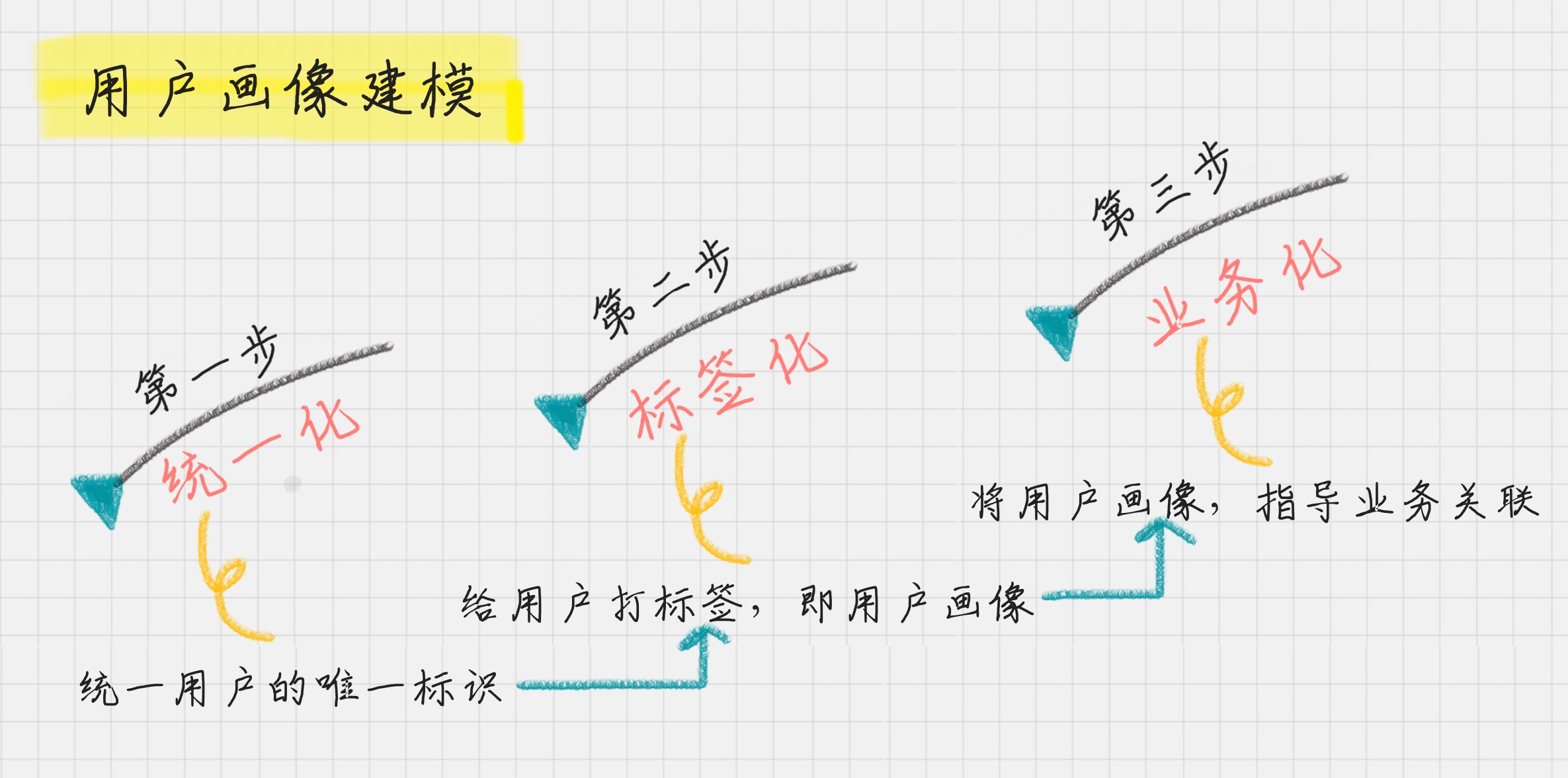
用户画像的准则
用户唯一标识是整个用户画像的核心
用户名、注册手机号、联系人手机号、邮箱、设备号、CookieID
其次,给用户打标签
- 用户标签:它包括了性别、年龄、地域、收入、学历、职业等。这些包括了用户的基础属性。
- 消费标签:消费习惯、购买意向、是否对促销敏感。这些统计分析用户的消费习惯。
- 行为标签:时间段、频次、时长、访问路径。这些是通过分析用户行为,来得到他们使用 App 的习惯。
内容分析:对用户平时浏览的内容,尤其是停留时间长、浏览次数多的内容进行分析,分析出用户对哪些内容感兴趣,比如,金融、娱乐、教育、体育、时尚、科技等
我们可以从用户生命周期的三个阶段来划分业务价值,包括:获客、粘客和留客
获客:如何进行拉新,通过更精准的营销获取客户。
- 粘客:个性化推荐,搜索排序,场景运营等。
- 留客:流失率预测,分析关键节点降低流失率。
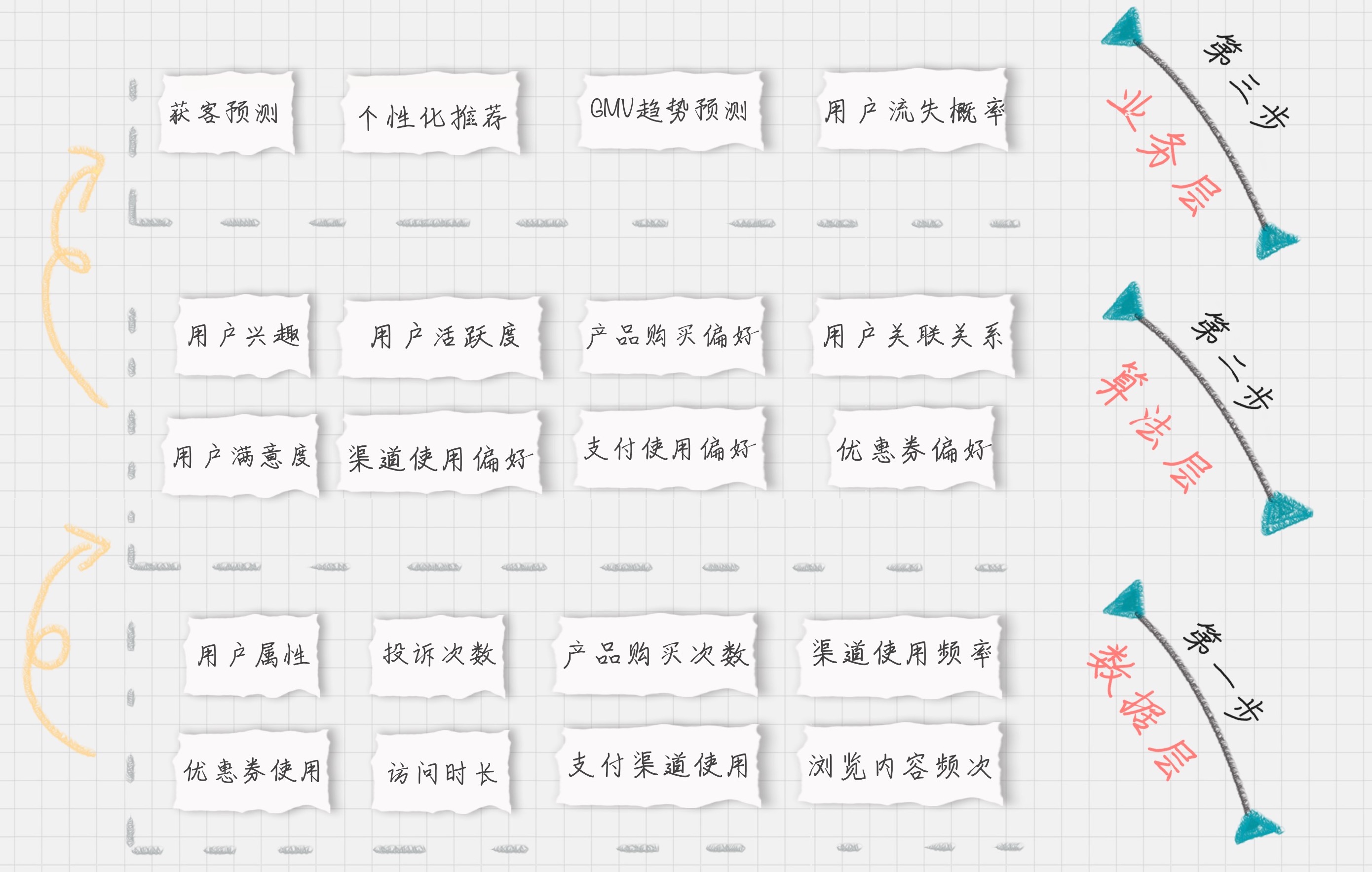
数据层 指的是用户消费行为里的标签。我们可以打上“事实标签”,作为数据客观的记录
算法层 指的是透过这些行为算出的用户建模。我们可以打上“模型标签”,作为用户画像的分类标识。
业务层 指的是获客、粘客、留客的手段。我们可以打上“预测标签”,作为业务关联的结果。
锻炼自己的抽象能力,将繁杂的事务简单化
08 | 数据采集:如何自动化采集数据?
因此我们需要考虑到,一个数据的走势,是由多个维度影响的。我们需要通过多源的数据采集,收集到尽可能多的数据维度,同时保证数据的质量,这样才能得到高质量的数据挖掘结果。
如何使用开放数据源
开放数据源可以从两个维度来考虑,一个是单位的维度,比如政府、企业、高校;一个就是行业维度,比如交通、金融、能源等领域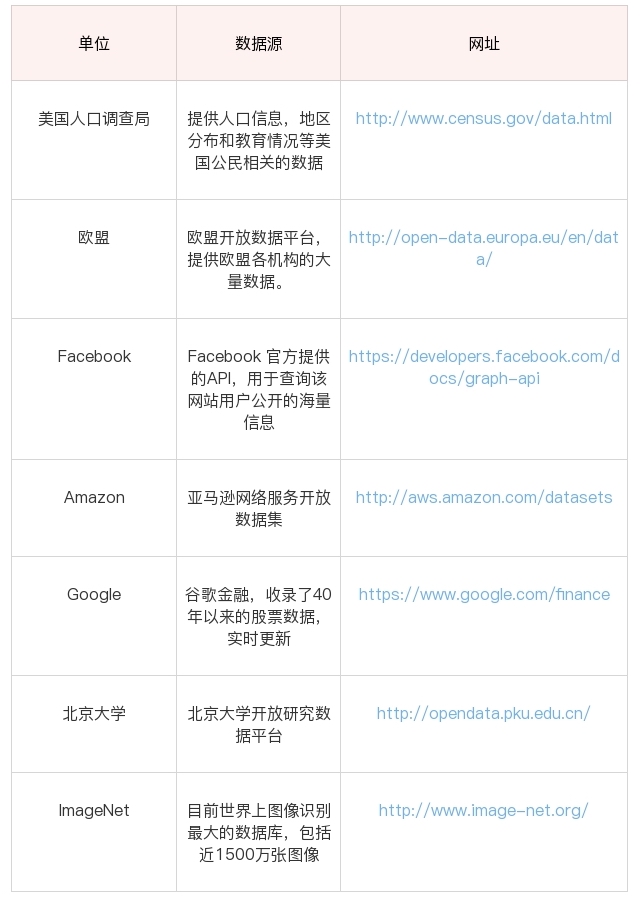

若有收获,就点个赞吧
0 人点赞
