本文,我们主要关心的是cache miss事件,那么我们只需要统计程序cache miss的次数即可。
使用perf 来检测程序执行期间由此造成的cache miss的命令是perf stat -e cache-misses ./exefilename,另外,检测cache miss事件需要取消内核指针的禁用(/proc/sys/kernel/kptr_restrict设置为0)。
1、数据合并
有两个数据A和B,访问的时候经常是一起访问的,总是会先访问A再访问B。
这样A[i]和B[i]就距离很远,如果A、B是两个长度很大的数组,那么可能A[i]和B[i]无法同时存在cache之中。
为了增加程序访问的局部性,需要将A[i]和B[i]尽量存放在一起。为此,我们可以定义一个结构体,包含A和B的元素各一个。这样的两个程序对比如下:
test.c
#define NUM 393216int main(){float a[NUM],b[NUM];int i;for(i=0;i<1000;i++)add(a,b,NUM);}int add(int *a,int *b,int num){int i=0;for(i=0;i<num;i++){*a=*a+*b;a++;b++;}}
test2.c
#define NUM 393216typedef struct{float a;float b;}Array;int main(){Array myarray[NUM];int j=0;for(j=0;j<1000;j++)add(myarray,NUM);}int add(Array *myarray,int num){int i=0;for(i=0;i<num;i++){myarray->a=myarray->a+myarray->b;myarray++;}}
注:我们设置数组大小NUM为393216,因为cache大小是3072KB,这样设定可以让A数组填满cache,方便对比。 对比二者的cache miss数量:
为了对比,之后测试了大小都为39216的情况,证明确实越大越好
NUM=393216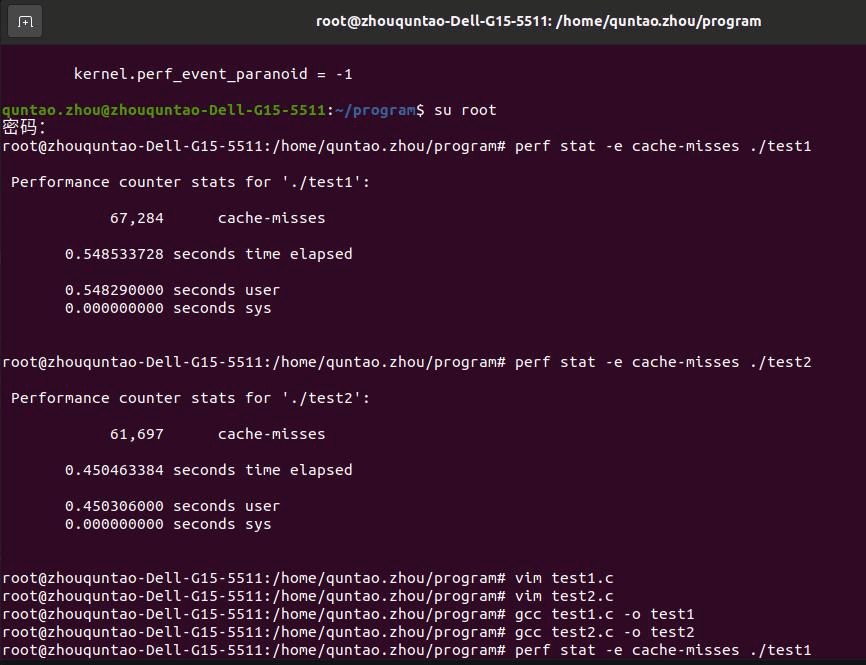 NUM=39216
NUM=39216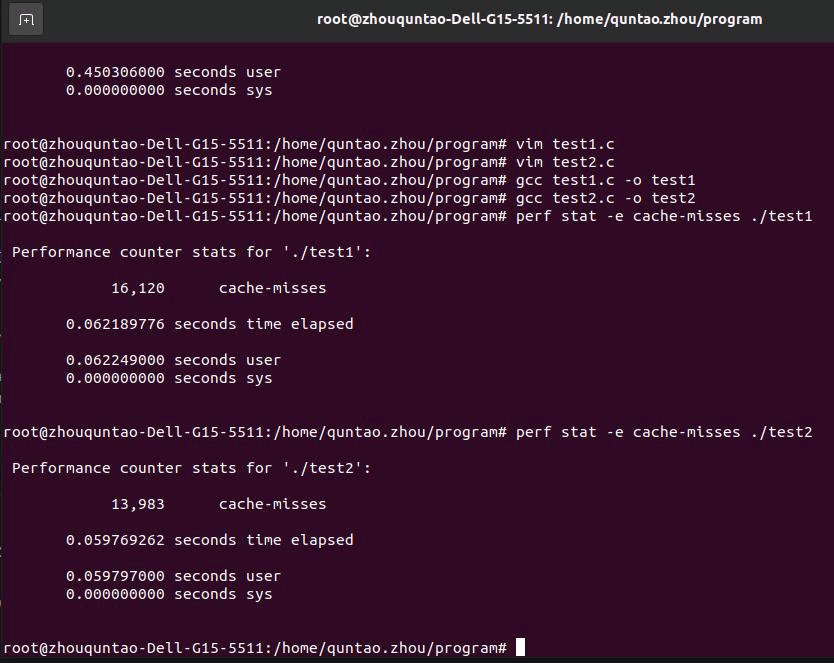
可以看到,后者的cache miss数量相对前者有一定的下降,大致优化性能20%。
进一步,可以查看触发cach-miss的函数:
test程序的结果(含-g查看函数调用):
NUM=393216
test1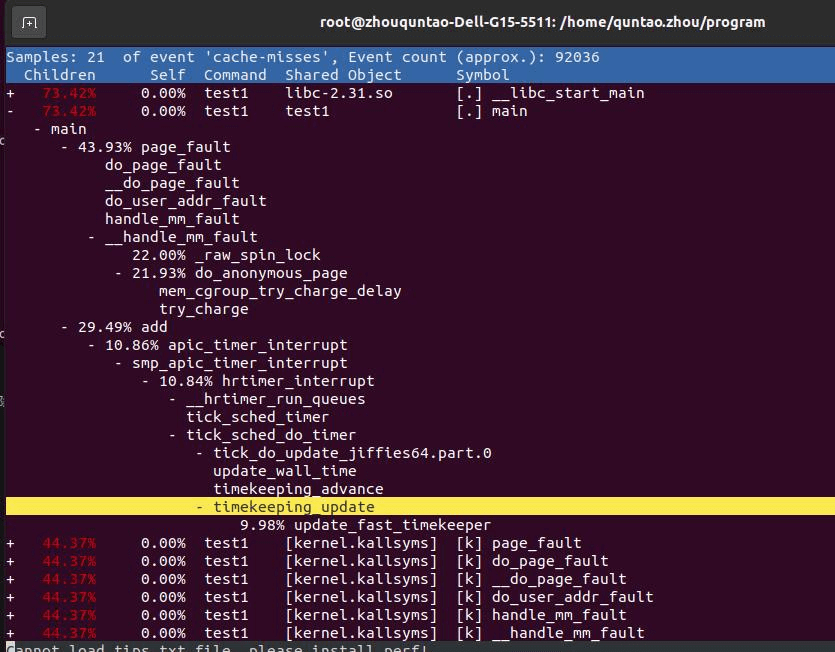 test2
test2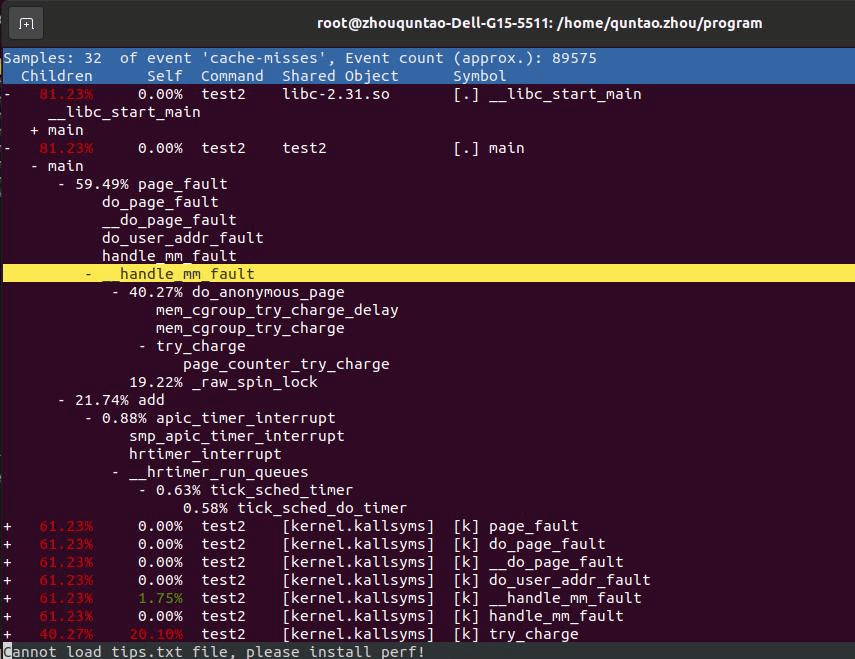 perf stat:
perf stat: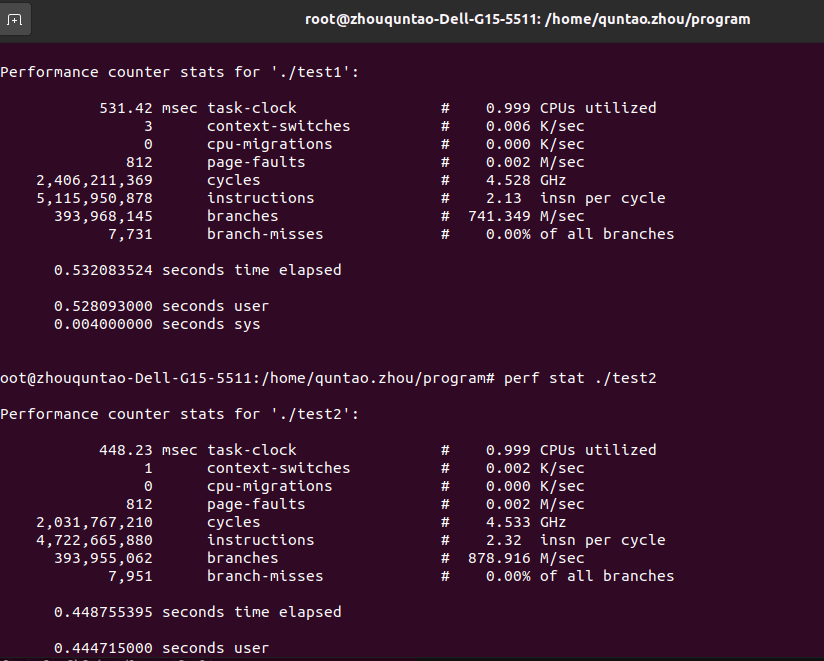
可见,page-faults次数不变, 但misses和耗时比例却上升,说明add函数的cache-misses和耗时有一定下降
2、循环交换
C语言中,对于二维数组,同一行的数据是相邻的,同一列的数据是不相邻的。
如果在循环中,让依次访问的数据尽量处在内存中相邻的位置,那么程序的局部性将会得到很大的提高。
观察下面矩阵相乘的几个函数:
test_ijk:
void Muti( double A[][NUM],double B[][NUM],double C[][NUM],int n){int i,j,k;double sum=0;for (i=0;i<n;i++)for(j=0;j<n;j++){sum=0.0;for(k=0;k<n;k++)sum+=A[i][k]*B[k][j];C[i][j]+=sum;}
test_jki:
void Muti( double A[][NUM],double B[][NUM],double C[][NUM],int n){int i,j,k;double sum=0;for (j=0;j<n;j++)for(k=0;k<n;k++){sum=B[k][j];for(i=0;i<n;i++)C[i][j]+=A[i][k]*sum;}}
test_kij:
void Muti( double A[][NUM],double B[][NUM],double C[][NUM],int n){int i,j,k;double sum=0;for (k=0;k<n;k++)for(i=0;i<n;i++){sum=A[i][k];for(j=0;j<n;j++)C[i][j]+=B[k][j]*sum;}}
考察内层循环,可以发现,不同的循环模式,导致的cache失效比例依次是kij、ijk、jki递增。
3、循环合并
在很多情况下,我们可能使用两个独立的循环来访问数组a和c。
由于数组很大,在第二个循环访问数组中元素的时候,第一个循环取进cache中的数据已经被替换出去,从而导致cache失效。
如此情况下,可以将两个循环合并在一起。
合并以后,每个数组元组在同一个循环体中被访问了两次,从而提高了程序的局部性。
实际情况下,一个程序的cache失效比例往往并不像我们从理论上预测的那么简单。
影响cache失效比例的因素主要有:数组大小,cache映射策略,二级cache大小,Victim Cache等,
同时由于cache的不同写回策略,我们也很难从理论上预估一个程序由于cache miss而导致的时间耗费。
真正在进行程序设计的时候,我们在进行理论上的分析之后,只有使用perf等性能调优工具,
才能更真实地观察到程序对cache的利用情况。
参考资料:
https://blog.csdn.net/sunshineywz/article/details/109044155

若有收获,就点个赞吧
0 人点赞
