为保证分支预测有效,应让具有相同逻条件和逻辑的运算处于同一程序块中,如:
1、调整循环层数和规模,使底层紧凑 ``` public class BranchPrediction { public static void main(String args[]) {
long start = System.currentTimeMillis(); for (int i = 0; i < 100; i++) {for (int j = 0; j <1000; j ++) {for (int k = 0; k < 10000; k++) {}}
} long end = System.currentTimeMillis(); System.out.println(“Time spent is “ + (end - start));
start = System.currentTimeMillis(); for (int i = 0; i < 10000; i++) {
for (int j = 0; j <1000; j ++) {for (int k = 0; k < 100; k++) {}}
} end = System.currentTimeMillis(); System.out.println(“Time spent is “ + (end - start) + “ms”); } }
//output Time spent in first loop is 5ms Time spent in second loop is 15ms
- 这个差异就是因为分支预测。循环本质也是利用cmp和jle这样的先比较后挑战的指令来实现的,每一次循环都有一个 cmp 和 jle 指令。每一个 jle 就意味着,要比较条件码寄存器的状态,决定是顺序执行代码,还是要跳转到另外一个地址。也就是说,在每一次循环的时候,都会有一次“分支”。- 2、调整循环逻辑顺序,使之有一定的有序性
include
include
include
int main() { // 随机产生整数,用分区函数填充,以避免出现分桶不均 const unsigned arraySize = 32768; int data[arraySize];
for (unsigned c = 0; c < arraySize; ++c)data[c] = std::rand() % 256;// !!! 排序后下面的Loop运行将更快std::sort(data, data + arraySize);// 测试部分clock_t start = clock();long long sum = 0;for (unsigned i = 0; i < 100000; ++i){// 主要计算部分,选一半元素参与计算for (unsigned c = 0; c < arraySize; ++c){if (data[c] >= 128)sum += data[c];}}double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;std::cout << elapsedTime << std::endl;std::cout << "sum = " << sum << std::endl;
}
//output
1. 取消std::sort(data, data + arraySize);的注释,即先排序后计算
10.218 sum = 312426300000
2. 注释掉std::sort(data, data + arraySize);即不排序,直接计算
29.6809 sum = 312426300000
- 除去增加clock()代码的方式,也可用perf直接对原项目分析:,找到增加耗时的原因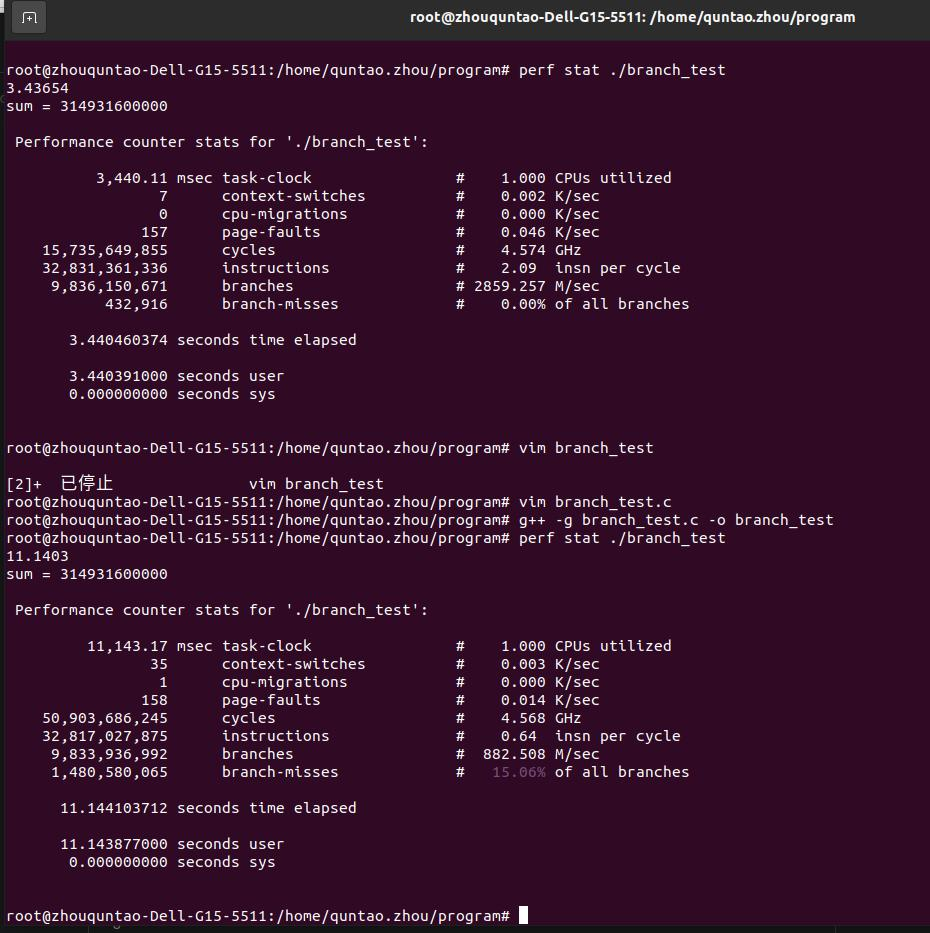- 很明显的看到产生了及其巨大的branch-misses增加,这就是耗时的主要元凶- 简单地分析一下:<br />有序数组的分支预测流程:
T = 分支命中 N = 分支没有命中
data[] = 0, 1, 2, 3, 4, … 126, 127, 128, 129, 130, … 250, 251, 252, … branch = N N N N N … N N T T T … T T T …
= NNNNNNNNNNNN ... NNNNNNNTTTTTTTTT ... TTTTTTTTTT (非常容易预测)
无序数组的分支预测流程:
data[] = 226, 185, 125, 158, 198, 144, 217, 79, 202, 118, 14, 150, 177, 182, 133, … branch = T, T, N, T, T, T, T, N, T, N, N, T, T, T, N …
= TTNTTTTNTNNTTTN ... (完全随机--无法预测)
在本例中,由于data数组元素填充的特殊性,决定了分支预测器在未排序数组迭代过程中将有50%的错误命中率,因而执行完整个sum操作将会耗时更多。- 优化:利用位运算取消分支跳转,是条件判断情况一致可预测,不会回退
|x| >> 31 = 0 # 非负数右移31为一定为0 ~(|x| >> 31) = -1 # 0取反为-1
-|x| >> 31 = -1 # 负数右移31为一定为0xffff = -1 ~(-|x| >> 31) = 0 # -1取反为0
-1 = 0xffff -1 & x = x # 以-1为mask和任何数求与,值不变
故分支可优化为: int t = (data[c] - 128) >> 31; # statement 1 sum += ~t & data[c]; # statement 2
避免移位操作版: int t=-((data[c]>=128)); # generate the mask sum += ~t & data[c]; # bitwise AND ```
- 分析:1. data[c] < 128, 则statement 1值为: 0xffff = -1, statement 2等号右侧值为: 0 & data[c] == 0;1. data[c] >= 128, 则statement 1值为: 0, statement 2等号右侧值为: ~0 & data[c] == -1 & data[c] == 0xffff & data[c] == data[c];
故上述位运算实现的sum逻辑完全等价于if-statement, 更多的位运算hack操作请参见bithacks.
若想避免移位操作,可以使用如下方式:
- 相关优化可参考:
- https://blog.csdn.net/hanzefeng/article/details/82893317?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%88%86%E6%94%AF%E9%A2%84%E6%B5%8B&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-82893317.142^v7^pc_search_result_control_group,157^v4^control&spm=1018.2226.3001.4187
- https://blog.csdn.net/edonlii/article/details/8754724
- https://blog.csdn.net/zhizhengguan/article/details/121269908

若有收获,就点个赞吧
0 人点赞
