一种典型的方法是为每个包含工件的包设置一个配置。例如,使用这种方法,调试预编译库将与发布预编译库位于不同的包中。
因此,如果有一个构建 “hello” 库的包配方,那么将有一个包含 “hello.lib” 发行版本的包和一个包含该库的调试版本的不同包 (在图中表示为“hello_d.lib”,为了清楚起见,没有必要使用不同的名称)。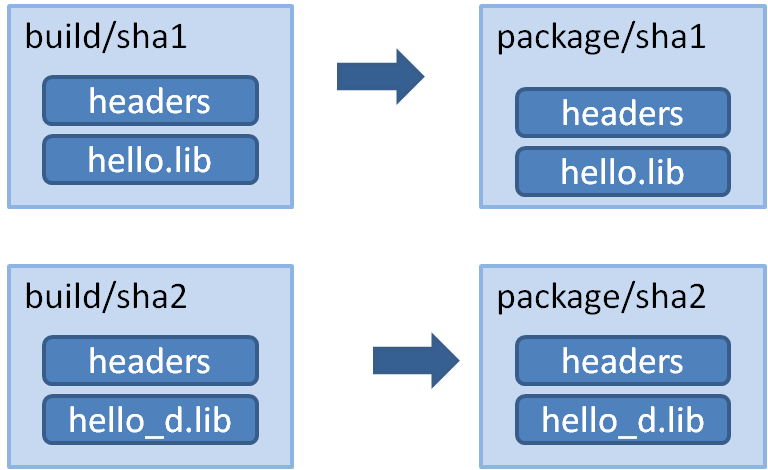
使用这种方法,package_info() 方法允许您为消费者设置适当的值,让他们知道包库名称、必要的定义和编译标志。
class HelloConan(ConanFile):settings = "os", "compiler", "build_type", "arch"def package_info(self):self.cpp_info.libs = ["mylib"]
请务必注意,它将build_type声明为设置。这意味着将为该设置的每个不同值生成不同的包。
包声明的值 (默认情况下已经定义了include、lib和bin子文件夹,因此它们定义了包的include和library路径) 被使用的生成器转换为各个构建系统的变量。也就是说,运行cmake生成器会将conanbuildinfo.cmake中的上述定义转换为以下内容:
set(CONAN_LIBS_MYPKG mylib)# ...set(CONAN_LIBS mylib ${CONAN_LIBS})
这些变量将在conan_basic_setup()宏中使用,以实际设置相关的cmake变量。
如果开发人员想要切换依赖项的配置,他们通常会切换为:
$ conan install -s build_type=Release ...# when need to debug$ conan install -s build_type=Debug ...
这切换将很快,因为所有依赖项都已在本地缓存。
此过程具有许多优点:
- 实施和维护非常容易。
- 包的大小很小,因此磁盘空间和传输速度更快,并且源构建也保持在最低限度。
- 配置的解耦可能有助于隔离与混合不同类型的工件相关的问题,并保护有价值的信息免受部署和分发错误的影响。例如,调试工件可能包含符号或源代码,这可以帮助或直接提供逆向工程的方法。因此,错误地分发调试工件可能是一个非常危险的问题。
阅读有关package_info() 更多信息。

若有收获,就点个赞吧
0 人点赞
