DDD中文又叫领域驱动设计,是我们解决复杂业务问题时非常有效的一个手段,但其本身过于陡峭的学习曲线,也让很多初学者知难而退。
网上虽然充斥着很多关于DDD的学习资料,但大多只是偏向于基本概念的介绍,缺少一个完整的落地实践。
笔者所在的技术团队也曾做过一些战略设计,通过这些设计过程,很多同学对DDD有了更深入的了解。在战略设计后,我们识别出了很多的值对象、实体、聚合根等等元素,但仍然让大家比较困惑的是,这众多的领域元素要如何跟具体的代码对应起来呢?如果做不到代码跟领域模型的同步更迭,那么DDD对于开发的意义又是什么呢?
因此,本文致力于尽量系统且详细的描述在DDD战术落地过程中可能遇到的问题,并且尽力贴近真实的开发场景,希望对你有所帮助。
温馨提示,在继续往下阅读前,最好对DDD中的一些基本概念有一定的了解,如果还不清楚,可以在网上先搜索一些资料阅读。
1. DDD的分层架构
分层架构作为一种历史悠久的架构模式,在很多的场景中都得到了应用。
大家比较熟悉的应该就是 MVC 对应用三层架构的拆分。
MVC 这种分层是自上而下的。
随着业务越来越复杂,人们逐渐发现, MVC 架构在应对复杂的业务问题时会显得力不从心。
于是,后面逐渐演化出了六边形架构、洋葱架构、整洁架构等架构模式。这几种架构也是一种分层架构,但这种分层不是由上而下的,而是由内而外的。
我们以洋葱架构为例: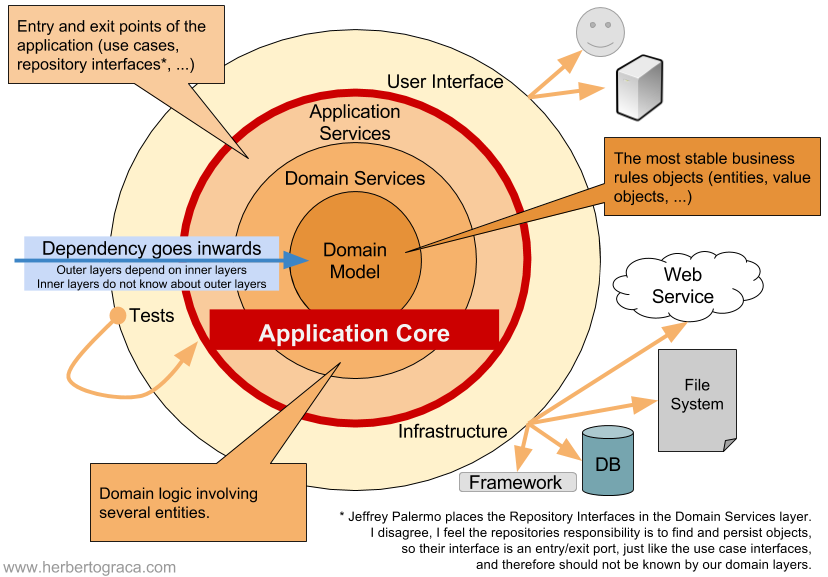
可以看到,最关键的是中心的领域模型,它包括了所有的应用逻辑与规则。在这一层中不会直接引用技术实现,这样就能够确保在技术层面的改动不会影响到领域核心。
在领域层之外又包裹了领域服务层、应用服务层,而具体的技术实现则是被置于最外层的。
这种架构的好处就在于,它屏蔽掉了应用程序在UI层、DB层、和各种中间件层的本质区别,都可以看作是数据的输入输出,然后让我们能够以一致的方式被用户、程序、自动化测试、批处理脚本等所驱动,并且,可以在与实际运行的设备和数据库相隔离的情况下开发和测试。
在 DDD 的技术实现中,就用到了这种分层方式。
下图是在 IDDD 一书中给出的一个典型的 DDD 系统所采用的分层架构: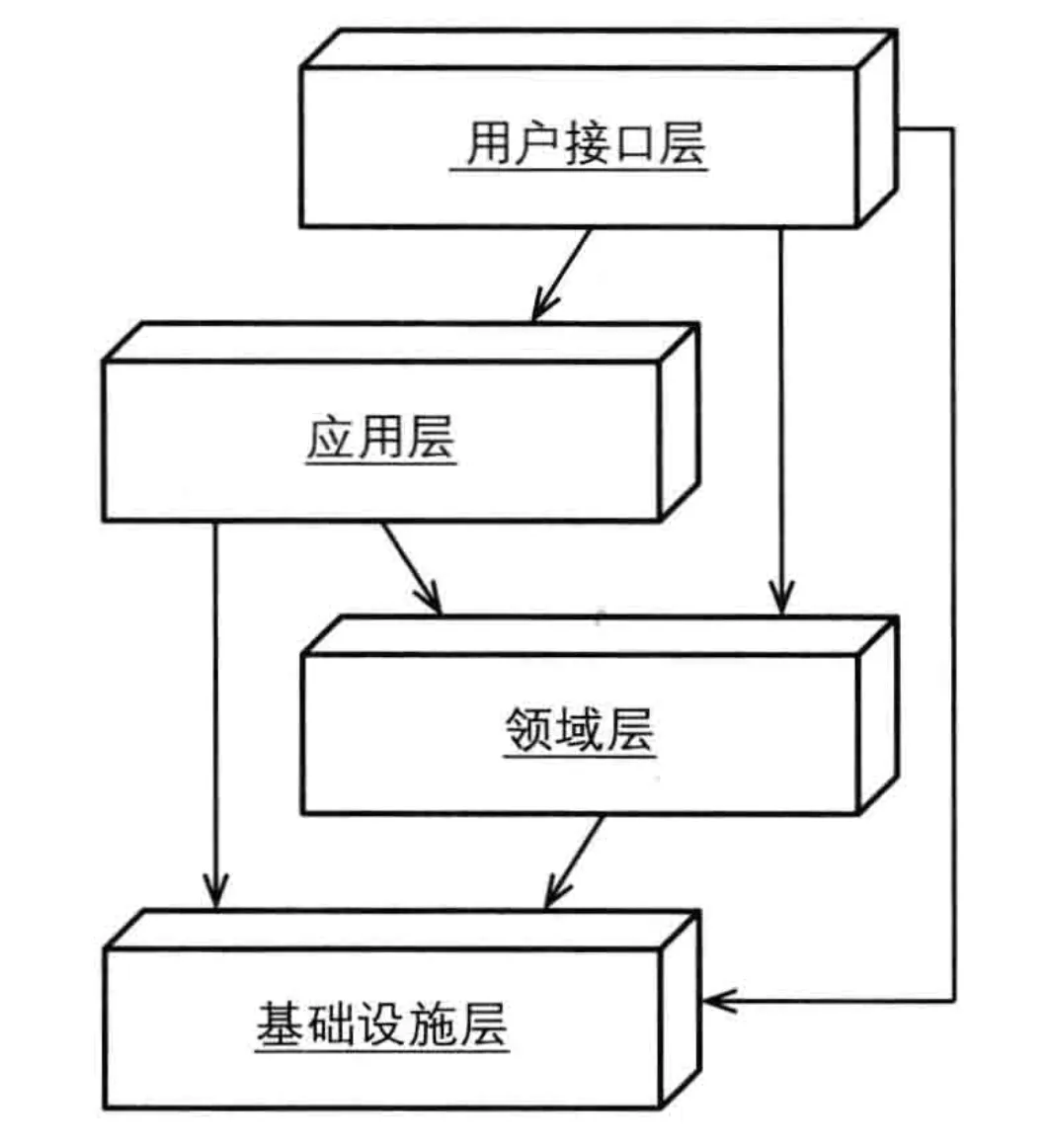
下面就对各层所表示的含义,以及该层应该做的事情做一个简单的介绍。
1、用户接口层
这一层主要负责直接面向外部用户或者系统,接收外部输入,并返回结果。
用户接口层是比较轻的一层,不含业务逻辑。可以做一些简单的入参校验,也可以记录一下访问日志,对异常进行统一的处理。同时,对返回值的封装也应当在这层完成。
2、应用层
应用层通常是用户接口层的直接使用者。
但是在应用层中并不实现真正的业务规则,而是根据实际的 use case 来协调调用领域层提供的能力。也即,应用层主要做的是编排工作。
另外,应用层还负责了事务这个比较重要的功能。
3、领域层
领域层是整个业务的核心层。
我们一般会使用充血模型来建模实际的对象。
同时,由于业务的核心价值在于其运作模式,而不是具体的技术手段或实现方式。因此,领域层的编码是不允许依赖其他外部对象的。
4、基础设施层
基础设施层是在技术上具体的实现细节,它为上面各层提供通用的技术能力。
比如我们使用了哪种数据库,数据是怎么存储的,有没有用到缓存、消息队列等,都是在这一层要实现的。
最后再来看一下代码的组织形式。
默认情况下,一个上下文对应了一个服务。我们这里以包含单个上下文的情况为例,来说明应用的目录结构:
.├── app # 应用层│ ├── assembler # 服务领域服务与 presentation DTO 的转化│ ├── cqe # 定义应用服务的 Command、Query、Event DTO│ └── order_app_service.go├── domain # 领域层│ ├── service # 放置领域服务│ ├── factory # 放置领域工厂│ ├── repo # 放置仓储│ └── entity # 放置聚合根、实体、值对象,枚举、事件的定义├── infra # 基础设施层层│ ├── cache # 本地缓存、redis等│ ├── mq # 主要是处理消息的发送│ ├── persistence # 数据库相关│ │ ├── convertor # 领域对象与 PO 之间的转化│ │ ├── dal # 对 PO 的定义和 db 的 crud 操作│ │ └── xxx_repo.go│ └── sal # 对rpc、http服务的访问,通常是对领域服务接口的实现│ └── ... # 一个文件对应领域服务里一个接口的实现├── conf # 配置文件│ └── xxx.yml├── interfaces│ ├── rpc│ └── http└── README.md
2. 领域层实现
2.1 值对象
值对象具有下面两个特点:
- 不变性,值对象在创建出来后是不应该被修改的,如果必须修改对象的某个属性,则需要整体替换成一个新的值对象;
- 无身份标识,这也是与实体相比非常重要的一个不同点。缺少了唯一标识,怎么判断两个值对象是否相等呢?就要看它们所包含的属性是否全部都是相等的了。这就好比我们在现实生活中使用现金,我们关心的只是货币的面值,是100的还是50的,而不会关心这个纸币的编号是多少。
2.1.1 实现值对象
1、比较严谨(教条)的实现方案
我们以一个描述货币价值的值对象为例,来看下代码:
// Currency 这里看作是一个枚举type Currency struct {name string}// 值对象type MonetaryValue struct {amount intcurrency Currency}func (v MonetaryValue) Amount() int {return v.amount}func NewMonetaryValue(amount int, currency Currency) (MonetaryValue, error) {if amount < 0 {return MonetaryValue{}, errors.New("amount must ge 0")}return MonetaryValue{amount: amount,currency: currency,}, nil}
在这个例子中,有这么几点需要特别注意下:
- 值对象需要使用大驼峰,也就是这个 MonetaryValue 应该是全局可见的,这样一来在领域层之外也是可以访问的;
- 值对象里的各成员应该小写,这样做有两方面的原因:
- 一方面可以避免在包外对属性值的直接修改。假设有个更新数额的操作,因为没法直接在原值上赋值,例如这样的代码
val.amount = 2也就行不通了。这么做的好处是可以避免错误的赋值导致的一些问题。 - 另一方面,在包外虽然可以对 MonetaryValue 实例化,但是因为成员不能赋值,也就强迫了使用者必须调用 NewMonetaryValue 方法,从而避免了构造出一个不符合规范的对象;
- 一方面可以避免在包外对属性值的直接修改。假设有个更新数额的操作,因为没法直接在原值上赋值,例如这样的代码
- NewMonetaryValue 是一个工厂函数,并一次性传入构建该值对象所需的所有参数,在这个函数中可以对参数进行合法性校验,这样保证了所有创建出来的对象都是合法的。
- 包外如果有对值对象内部成员进行访问的需要,可以定义一个同名的、采用大驼峰定义的方法,比如这里的 Amount 方法。
2、谨慎(最好不)持有指针、slice等类型
在一个值对象中可能持有另外的值对象,比如这里的 Currency,虽然是作为一个枚举使用,但本质上仍然是一个值对象。
当值对象中包含了其他非基本类型(例如指针、struct、slice、map等)的属性时,就要特别注意了,即使我们在值对象里没有对这类成员进行修改,但是仍然无法保证外部不会修改他们的值。
看下面的例子:
type BadDemo struct {s []string}func NewBadDemo(ss []string) BadDemo {return VOBadDemo{s: ss}}
虽然 BadDemo 在内部没有任何方法对 s 进行增删操作,但是,如果外部对 ss 进行了修改,比如 ss[0] = "abcd",同样会反应到 s 上。
这样一来也就破坏了值对象的不变性,这种破坏性,有的时候可能会给你带来不可预知的Bug,并且不是特容易发觉。
3、当需要对内部成员值进行修改,就新建一个值对象
值对象也是能够拥有一些行为的,比如上面的 MonetaryValue 可能有一个Add 方法:
func (v MonetaryValue) Add(other MonetaryValue) (MonetaryValue, error) {if v.currency != other.currency {return MonetaryValue{}, errors.New("not same currency")}return MonetaryValue{amount: v.amount + other.amount,currency: v.currency,}, nil}
这里的 Add 方法跟我们通常的实现可能不太一样,主要在于方法的返回值。
值对象因为要保证不变性,因此,我们不能直接对值对象的内部属性进行修改,而是采用了新建一个值对象的方式。
另外,Add 方法的接收者是一个值接收者,而非指针接收者,使用指针接收者的问题在于可能不小心就修改了内部属性,而造成一些隐式的错误。当然这里也可以不用这么绝对,对于大型的值对象,如果使用值接收者会带来一定的性能损耗,这个时候也可以使用指针接收者。
4、为什么要保证值对象的不变性
费了这么大劲,又是限制接收者类型,又是强调必须返回一个新的值对象,为什么呢?
我们考虑下面这个场景。
比如说,我们现在在开发一个多人游戏,每个人在一开始的时候都有固定的等值筹码,随着游戏的进行,你可能花费一些筹码或者赚取一些筹码。
我们在初始化筹码时,代码可能如下:
func initTokens(players []Player) {initToken := &MonentaryValue{100}for _, item := range players {item.token = initToken}}
之后 player A 通过卖出装备而赚取了更多筹码,假设说这里是按照直接修改值对象内部属性的方式来实现:
playerA.token.Add(10)
那么问题就出现了,我们虽然只给 player A 增加了筹码,但是发现所有 player 都莫名多了10筹码。
问题的原因就在于,我们共享了这个值对象,但是没有保证它的不可变性。而返回新的值对象的方式则不存在这个问题:
playerA.token = playerA.token.Add(10)
2.1.2 实现枚举
枚举通常被认为是值对象的一种特化形式,它也属于领域中的元素。
1、以值对象的形式来实现枚举
比如有一个叫 SomeStatus 的枚举,对应有两个枚举值 SomeStatusOne 和 SomeStatusTwo, 那么可以采用如下的形式来定义:
var (SomeStatusZero = SomeStatus{}SomeStatusOne = SomeStatus{1}SomeStatusTwo = SomeStatus{2})var someStatusValues = []SomeStatus{SomeStatusOne,SomeStatusTwo,}func NewSomeStatus(s int) (SomeStatus, error) {for _, item := range someStatusValues {if item.s == s {return item, nil}}return SomeStatusZero, errors.Errorf("unknown '%d' status", s)}type SomeStatus struct {s int}func (s SomeStatus) IsZero() bool {return s.s == 0}func (s SomeStatus) Int() int {return s.s}
上述代码大部分都遵循了值对象的实现方法,但是也有两点不同:
- 定义一个默认的零值,并提供了一个判断当前枚举是否为零值的方法。零值的作用是保证在使用到枚举的地方都不会有 nil 的出现,这种保证可以一定程度的避免程序 panic 的发生;
- 所有的枚举值放到一个 Slice 或 Map 中,便于在创建枚举时进行合法性校验;
可以看到,这种实现方式还是比较麻烦,但是能够很大程度的在代码层面保证程序的正确性。而且,枚举值的变动频率一般都不会太高,所以成本也仅仅是一次性的。
2、使用原始类型表示枚举
另外一种偷懒的形式类似下面这种:
type AnyStatus intconst (AnyStatusZero AnyStatus = iotaAnyStatusOneAnyStatusTwo)
跟上面值对象的形式相比,的确是简单了不少,但是最大问题在于代码的不可控性。
比如下面这样一个函数:
func UpdateStatus(s AnyStatus) {...}
UpdateStatus 方法接收一个 AnyStatus 类型的参数,之所以这里是一个 AnyStatus 类型而不是一个 int 类型,大概率是希望调用者能传递一个合法的 AnyStatus 进来,但是这一点是得不到保证的。
调用方可以传入任意一个整数值,而编译器并不会报错:
service.UpdateStatus(6) // 这行代码并不会报错
如果希望代码足够的严谨,那么在 UpdateStatus 方法内部就不得不就传入的值进行校验。这种校验逻辑也会散落到所有用到 AnyStatus 的地方。
另外,从全局来看,任何人在任何地方都可以直接调用类似这样的代码 AnyStatus(6) 来生成一个枚举值。很显然,这是一个无效的枚举值,也是一个完全不应该存在于领域的对象。
综合看上面两种方式,各有优缺,可以根据各自的情况,只要团队内做到统一即可。
2.2 实体
一个实体是一个唯一的东西,并且可以在相当长的一段时间内持续地变化。我们可以对实体做多次修改,故一个实体对象可能和它先前的状态大不相同。但是,由于它们拥有相同的身份标识(identity),它们依然是同一个实体。 —- from IDDD
2.2.1 区别于数据对象
实体有两个突出的特征:唯一的身份标识和可变性,而这两个特征同样存在于数据对象身上,因此为了避免先入为主的将数据对象等同于实体,这里先说下两者的区别和联系。
1、数据对象
数据对象一般指的是我们在 model 层定义的一些 struct,这些 struct 的属性跟数据库中某个表的列信息是保持一致的,通过 ORM 软件(我们常用的就是Gorm),可以方便的将数据库表里的一行映射成一个数据对象的实例,反之亦然。
这些对象之所以叫数据对象,主要原因在于他们只是承载了数据功能。
比如,在一个名为 User 的数据模型中,我们可以看到它包含了用户名、手机号、性别、年龄,等等。但是单从这个数据模型上是看不出它可以做什么的。
而具体能做什么、怎么做,则被放到了某个服务(通常会有个 service 层)里面,在服务中通过一些赋值操作来更新数据对象的某些属性,最后再通过 ORM 保存回数据库中。
这种模式下,数据对象因为缺少了行为,又被称为贫血模型。
从本质上来说,这种方式依然是面向过程的编程范式,本应围绕着领域模型的业务逻辑被泄露到了各个 service 中,久而久之,会使得代码越来越难以理解。
2、实体对象
而实体是 DDD 中的领域对象,它是一个富有行为的领域概念。
领域对象里的成员和数据对象里的成员可能是一致的,也可能不一致,这完全取决于你使用什么样的存储技术。
比如,在 MongoDB 这类文档型数据库中,实体模型和数据模型很可能是高度一致的,但是在传统的 MySQL 数据库中,很多时候会将一个实体模型映射成多个数据模型。
考虑在订单中要有配送地址这个场景。
如果是使用 MongoDB ,可能直接存成一个doc:
{"id": "xxx","address": {"province": "","city": "","detail": "",},...}
而在 MySQL 中,就需要将地址信息拆到另外一张表里。
除此以外,实体对象跟数据对象的本质区别还在于模型的丰富程度,实体对象是包含了丰富的领域概念的。
还是订单这个例子, Order 实体上可能还会定义一些领域方法:
type Order struct {...}func (o *Order) IsPayed() bool {...}func (o *Order) CalculateTotalPrice() {...}func (o *Order) AddItem(productId, price, count int64) error {...}func (o *Order) ChangeProductCount(productId, count int64) error {...}func (o *Order) ChangeAddress(province, city, detail string) error {...}
2.2.2 唯一标识不等同于数据库主键
说到唯一标识,我们很容易联想到数据库表里的唯一主键,认为业务的唯一标识就是表记录里的id列,其实这种理解是不太全面的。
数据表里的主键 id 在某些情况下可以作为实体的唯一标识,但两者本身属于不同的概念。
还是以 Order 实体为例,它在数据库中可能存在类似下面这样的一张表:
CREATE TABLE IF NOT EXISTS `orders`(`id` INT UNSIGNED AUTO_INCREMENT,`order_id` VARCHAR(100) NOT NULL comment '订单编号',...PRIMARY KEY ( `id` ))ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
那么,这里的 id 只是数据库表里的一个主键,而 order_id 才是 Order 这个领域实体的唯一标识。
通常情况下,业务实体与数据表里的字段不一定是一一对应的关系,我们这里只是为了说明不要将业务的唯一标识等同于数据库表中的主键。
再来看一个 Product 的例子,它的定义比较简单:
CREATE TABLE IF NOT EXISTS `products`(`id` INT UNSIGNED AUTO_INCREMENT,`name` VARCHAR(100) NOT NULL comment '产品名',`price` VARCHAR(16) NOT NULL comment '价格',`detail` TEXT NOT NULL comment '详情',PRIMARY KEY ( `id` ))ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
products 表有一个 id 列作为主键,同时,我们通常也会将这个 id 作为 Product 实体的唯一标识。
也就是说,数据库表的主键有的时候可以作为唯一标识使用,有的时候却不可以。
我们只需要记住,唯一标识和数据库结构没有关系,主键 id 是存储层面的唯一标识,而业务层面的唯一标识才是实体关心的。
2.2.3 如何表示唯一标识
比较教条的做法是无论什么情况都用一个值对象来存放实体的唯一标识。
值对象具有不变性,这也就保证了实体身份的稳定。
但在一些比较简单的情况下,可以直接使用原始类型(比如string、int)来作为唯一标识。
1、使用值对象表示唯一标识
这里考虑一个订单号生成的例子,假如我们生成订单号的规则如下:
时间戳+业务类型+下单平台+随机码(或自增码,自增码每天可清零)+支付渠道
那么,通过这样一个订单号我们可以解析出该订单下单的时间、支付的渠道等信息。
这些信息的解析跟订单号是密不可分的,这些行为和订单号本身形成了一个完整的业务概念整体,因此,这个时候将订单号编码为一个值对象是合理的。
type OrderId struct {code int64}func (i OrderId) CreateDate() time.Time {...}func (i OrderId) PaymentChannel() Channel {...}...type Order struct {Id OrderId...}
使用值对象来实现唯一标识不仅能够更好的表达业务,同时,可以一定程度上规避一些错误。
看下面的代码,我们要提供一个根据订单ID和商品ID来获取订单项信息的函数:
func findOrderItem(int64, int64)// orfunc findOrderItem(OrderId, ProductId)
第一种实现的入参都是 int64 类型,第二种是值对象类型。
对于第一种来说,调用方即使在传参时将 orderId 和 productId 搞反了,编译器也是不会报错的,而这种错误在第二种实现方式中是完全不可能发生的。
这种表示方式的唯一缺点在于代码量的增加。
在很多地方,因为必须要对原始类型与值对象类型进行转换(比如数据库里存储的订单号还是 int 类型,但是读取出来要转成领域实体,就需要转成 OrderId 类型,在实体持久化的时候还需要将 OrderId 转成 int),复杂度会有一定的增加。
2、直接使用 int64 作为唯一标识
上面提到的产品ID是一个不需要使用值对象做唯一标识的例子。
Product 实体用自增 ID 来代表唯一标识,这个 ID 除了能唯一标识一个产品外,没有其他任何与之相关的行为。
所以这里可以将其简化成一个 int64 类型。int64 也是不可变的,因此其本质上也是符合值对象的特点的。
type Product struct {Id int64 // 唯一标识...}
这种实现方式的缺点是表达能力不强,但好在足够简单。
综合来看:
- 如果是使用通用的 IdGenerator 这类的工具来生成唯一标识,其本身除了唯一标识一个实体,也没有其他的行为,这种情况下推荐直接使用原始类型就可以了;
如果唯一标识是按照一定的规则来生成的,并且围绕这个唯一标识还会有一些方法(行为),这个时候最好使用值对象来承载;
2.2.4 生成唯一标识
根据不同的场景,大体上分为下面两种生成方式:
1、用户直接传入唯一标识
这种情况依赖用户的输入,用户需要保证输入的唯一标识真的是唯一的,这通常很难。但是,在某些特殊场景下还是可以做到的。
比如在学校图书馆,管理员录入书本的场景。
我们知道每本书都有一个 ISBN 码,这个 ISBN 码就可以作为书本的唯一标识。
管理员在录入书本时,用手持设备直接扫描 ISBN 码,这个扫描到的 ISBN 码就可以认为是用户直接传入的唯一标识。
2、系统生成唯一标识
大部分情况下,我们遵循的都是这种方法。无论是上面提到的 OrderId 还是 ProductId,虽然生成的方式不同,但都可以归属到系统生成的范畴。
这里面有一种比较特殊的情况,是使用数据库的自增来生成。
这种情况特殊的点在于,实体创建好了之后,可能还没有来得及分配一个唯一标识,因为此时实体还没有进行持久化。
没有唯一标识的实体可能需要面对下面两个问题:如果需要发布领域事件,这个时候因为还没生成唯一标识,事件接收者无法知道是哪个实体发出的事件;
- 如果我们创建了多个实体,同时又需要将这些实体暂存在一个map中,因为唯一标识都是零值,会导致部分实体丢失;
解决这个问题的办法就是将唯一标识的生成提前,在实体创建好的时候,保证一定是有唯一标识的。
3、代码如何实现
通常,我们会在 Repository 接口中定义一个 NextIdentity 方法,如下:
Repository 对应的是 DDD 里的仓储概念,我们在下面的章节会介绍。
type ProductRepository interface {
NextIdentity() (int64, error)
...
}
而需要用到这个 NextIdentity 方法的地方,一般是在工厂或应用服务里。
对于应用服务,基本都需要持有一个对应的 Repository 属性,比如这样:
type ProductApplicationService struct {
productRepo repository.ProductRepository
...
}
func (s *ProductApplicationService) CreateProduct(ctx context.Context, cmd *CreateProductCmd) (int64, error) {
id, err := s.productRepo.NextIdentify(ctx)
if err != nil {
return nil, err
}
rlt := &entity.ProductAggregate{
Id: id,
...
}
...
}
而如果是在工厂里,就要展开讨论了。
如果工厂是无状态的,也可以让工厂直接持有对应 Repository 属性,实现方式跟在应用服务里类似。
如果工厂是有状态的,那么只能每次前都创建一个工厂的实例,在创建的时候将 Repository 作为参数传入:
func NewProductFactory(ctx context.Context, repo repository.ProductRepository) *OrderFactory {
return &OrderFactory{
ctx: ctx,
productRepo: repo,
}
}
type ProductFactory struct {
ctx context.Context
productRepo repository.ProductRepository
}
...
2.2.5 聚合根
聚合是 DDD 中较为难以理解的一个概念。
很多刚刚接触 DDD 的同学,常犯的错误是设计出一个囊括天地万物的大聚合。这在战略设计阶段往往看不出什么问题,但是一旦要落实到代码层面,就会发现根本行不通。
当然,我们这里不会太多的去讲应该如何去设计聚合,这不是这篇文章的重点。
但是,我们至少要知道,设计小聚合是很重要的一条原则。
小聚合的前提是要保证聚合内的一致性条件不被破坏。这里有篇文章可以帮助大家更好的理解>>
更多的原则参考这里>>
当我们回归到小聚合的设计后,就会发现,聚合根的实现方式跟实体是非常类似的。这也是为什么本文将聚合根和实体放在一起说的原因。
还是考虑上面 Product 的例子:
type Product struct {
Id int64
Name string
Price int64
Desc string
}
假如说我们的产品模型非常简单,只有如上的四个属性。
我们是否还有必要再单独定义一个 ProductAggregate 结构体做聚合根呢?
type ProductAggregate struct {
ProductId int64
Product *Product
}
上面这个写法显然是多余的,Product 是实体,但是在聚合根里不包含其他属性时,Product 本身也可以当做聚合根来用。
同理,可以推广到稍复杂的情况。
比如在一个订单中,通常会包含总价、支付方式、订单项、地址等内容,如果我们强制区分实体和聚合根的话,可能会写出如下的代码:
type Order struct {
Id int64
Price int64
PayChannel int64
Address string
}
type OrderItem struct {
Id int64
OrderId int64
ProductId int64
ProductCount int64
}
type OrderAggregate struct {
Id int64
Order *Order
Items []*OrderItems
}
但在实际开发中,可以在 Order 中直接引用 OrderItem,这样就省去了对 OrderAggregate 的维护,Order 也变成了实体加聚合根的双重身份:
type OrderItem struct {
Id int64
OrderId int64
ProductId int64
ProductCount int64
}
type Order struct {
Id int64
Price int64
PayChannel int64
Address string
Items []*OrderItems
}
同时,我们建议所有的聚合根在命名上都加一个 Aggregate 或 Agg 的后缀,表示这是一个聚合根。
使用聚合根时,还有一个经常容易犯的错误,就是在一个聚合根中引用了另外一个聚合根。
正确的做法是通过全局唯一标识来引用外部的聚合。
原因就在于,在一个事务中,原则上只能修改一个聚合,如果不持有对其他对象的引用,也就避免了对这个对象的修改。
在你的代码里,如果一个事务必须要修改多个聚合,这个时候就要考虑聚合设计的是否合理,这种情况通常意味着聚合的一致性边界是错误的。
2.3 领域服务
领域服务最主要的功能是对多个领域对象的逻辑进行封装。
有的时候,我们会面临这样的窘境,一段逻辑无论放到单独的一个实体中,还是值对象中,都有些不太合适。
比如给某篇文章添加评论。
我们需要判断文章是否开启了评论功能,评论的用户是否被禁言,评论的内容需要进行内容审查。这个时候就需要在实体、值对象的基础之上引入领域服务。
2.3.1 什么时候需要一个领域服务
首要的一个原则是,如非必要,不要使用领域服务!!!
因为创建领域服务的成本并不高,所以很容易不管三七二十一就把业务逻辑都写到服务里面了。
这会造成实体、值对象的贫血。
要判断到底需不需要创建一个领域服务,其实就是确定哪些逻辑是不适合放到实体和值对象里的。
1、实体里需要用到资源库
定义在实体里的某个方法需要调用资源库的某个方法,那么推荐将这个逻辑提到领域服务里面。
比如在一个产品里,需要计算有多少有效的评价:
type Product struct {
...
}
func (p *Product) EffectiveEvaluations() int {
...
}
在 EffectiveEvaluations 这个方法里,我们必须先通过 EvaluationRepository 获取到产品对应的所有评价,然后对这些评价进行遍历,从中筛选出有效评价,最后返回有效评价的数量。
这种情况为什么推荐使用领域服务来实现呢?
试想如果想在 EffectiveEvaluations 方法里能够调用 Repository 服务,要么是 Product 实体持有一个 Repository 属性,要么是在 EffectiveEvaluations 方法参数中传入一个 Repository 参数。
对于持有 Repository 属性的方式,其本身就比较奇怪。我们在领域建模的时候也绝不会讨论领域模型应该有一个 Repository 属性,而且我们每次创建 Product 实例时都要将 Repository 传进来也不太现实。
第二种方式也不是太好,因为实体在整个代码框架中处于最内层,所以如果外层代码想要调用这个方法,就必须一路传递 Repository 实例,这一路所有的方法都必须带一个 Repository 参数也比较恶心。
所以,在实体中一旦用到了 Repository,最好的实现就是将其放到领域服务中。
这里的资源库只是一种具体的表现,我们其实可以进而推广到更一般的情况,即当需要与外部资源进行交互时,都可以用领域服务来实现,比如某个逻辑里需要调用 RPC。
2、多个实体之间有交互
涉及多个实体之间有交互关系的逻辑,这个时候,将逻辑放到哪个实体中都不是特别合适,因此,也需要提到一个领域服务中。
还是上面发表评价的例子,要求产品必须是开启了允许评价功能,并且用户有过购买该产品,对评价的内容还要进行算法审核,保证没有不合规的文字。这样的一段逻辑,已经不是单个某个实体的职责就可以完成了的。
3、无法放到某个实体上的逻辑
最后一种情况是某个方法没办法放于实体之上。
比如用户登录这个场景,用户在前台输入用户名和密码,如果我们将这个功能定义在实体上会怎么样呢?
type User struct {
...
}
func (u *User) LogIn(username, password string) error {
...
}
从上面的代码可以看出,如果我们想调用 LogIn 方法,必须先获取一个 User 的实例,但是当前用户还没有登录,我们当然也不知道这个 User 应该是谁。
User 在等待 LogIn,LogIn 也在等待User,如此一来,锁死了。
因此,这种情况需要把逻辑提到一个领域服务中。
最后,还是那句话,如果没有非使用领域服务不可的理由,那就不要用。
2.3.2 实现领域服务
1、领域服务代码应该放在单独一个包中
有的同学在组织代码结构的时候喜欢按照业务分包,比如在一个商城系统中,会涉及产品、订单等,如果按照业务分包就会有如下的结构:
├── domain
│ ├── product
│ └── order
与产品相关的 Entity、ValueObject 等都放到 domain.product 这个包下,与订单相关的 Entity、ValueObject 等都放到 domain.order 这个包下。
同理,产品和订单相关的领域服务也应该分别放到 domain.product 、domain.order 包下。
这种方式看上去比较美好,但实际上是有很严重问题的。
在领域服务中可能会用到多个实体,这种情况下很难保证彼此之间的引用是单向的。而且,不仅仅是领域服务存在这个问题,实体之间如果有一些通用的结构也是会导致循环依赖的。
那么,一种解决方案,是将彼此依赖的内容下沉到一个独立的包中,但是需要注意的是,这种下沉可能会让你的代码看上去特别混乱。
推荐的做法是不要按业务分包,而是按照功能分包,将业务上不同功能的代码放到对应的包里,比如这样:
├── domain
│ ├── entity # 业务所有的实体,不同的业务实体可以放到不同的go文件里
│ ├── vo # 值对象
│ ├── repository # 仓储
│ └── service # 领域服务
因为我们现在很少会开发大的单体应用,在一个服务里基本上都是单一的业务或者相关性比较强几个功能,因此,将所有的业务实体放到一个包下是可行的。
不同的实体可以再按照划分放到不同的 go 文件中。
领域服务类似,所有的领域服务代码在开始的时候可以统一放到 domain.service 下面。
有的同学可能会担心随着业务变得复杂,service 包下的 go 文件会越来越多,从而变得难以管理。
其实这个问题基本上不会发生,在本文的后面会讲到 CQRS,而领域服务的代码基本上对应的都是 Command ,所以是不会变得特别多的。
2、保持领域服务的无状态性
确定了领域服务代码放在什么地方,接下来就是如何实现的问题了。
一个很重要的原则是:要保持领域服务的无状态性。所以如果你定义了一个类似下面这样的 struct 来作为领域服务,一定是错误的:
type EvaluationService struct {
ctx context.Context
userId int64
...
}
无论是上面的 ctx 还是 userId,它们都是跟具体的某次会话或者某个用户绑定在一起的。
做到无状态最简单的方法就是使用函数,将相应的值对象、实体等领域元素以参数的形式传入,类似下面这样:
func AddEvaluation(ctx context.Context, product *Product, user *User, content string) (*Evaluation, error) {
if product.EvaluationOff() {
return nil, errors.ErrorOf("product '%d', no evaluations allowed", product.Id())
}
if user.IsBanned() {
return nil, errors.ErrorOf("user '%d' has banned", user.Id())
}
return &Evaluation{
...
}, nil
}
看起来还可以,除了稍微有那么点不太面向对象。
但是,有的时候,我们在领域服务中可能还会用到 Repository、Sal(service access layer)等服务。如果我们像下面这样定义函数,用起来就很别扭了:
func AddEvaluation(repo repository.EvaluationRepository, checker SpamChecker, product *Product, user *User, content string) {
...
}
每次调用都要传一大串参数也不是太方便。
所以就有了第二种写法:
type ProductEvaluationService struct {
// repository.EvaluationRepository 和 ContentSal 在领域层都是以接口的形式存在
// 因为在领域层不关心具体的实现
evaluationRepo repository.EvaluationRepository
spamChecker SpamChecker
}
func NewProductEvaluationService(repo repository.EvaluationRepository, checker SpamChecker) *ProductEvaluationService {
return &ProductEvaluationService{
evaluationRepo: repo,
spamChecker: checker,
}
}
func (s *ProductEvaluationService) AddEvaluation(ctx context.Context, product *Product, user *User, content string) (*Evaluation, error) {
...
}
这里有几点需要说明:
- 在 ProductEvaluationService 里持有的几个属性本身也要是无状态的;
- ProductEvaluationService 持有的属性是要定义在领域层的,因为领域层是最核心的层,所以只能是其它层引用领域层,而不能反过来;
- 我们同时提供了一个构造函数来生成一个 ProductEvaluationService 实例,构造函数的参数也是领域中定义的相关接口,利用多态,我们可以注入任意类型的实现,也方便了测试;
- ProductEvaluationService 全局只需要一个实例即可,没必要每次使用的时候就 New 一个,我们可以在程序启动的时候将相应服务注入,之后就是直接使用;
综合来看,第一种直接定义一个函数的方式虽然方便,但是适用的场景比较局限,一旦后面需要引入Repository、Sal(service access layer),代码就要大改,因此,我们总是可以使用第二种方式来定义一个领域服务。
3、通过依赖反转解耦对具体技术的直接引用
在领域服务中毕竟需要用到一些技术层面的能力,比如数据库访问,rpc调用等,这些具体的技术实现是不能放在领域层的。
这个时候,我们可以采用独立接口的形式来达到依赖反转的目的。
比如上面示例中的 SpamChecker 便是在领域层定义的一个接口,而其对应的具体实现是放到基础设施层的:
// 在 domain.service 中定义领域服务的接口
type SpamChecker interface {
Check(content string) (Spam, error)
}
在 infra.sal 中定义具体的实现:
type AiSpamChecker struct {
client rpc.AiClient
}
func (c *AiSpamChecker) Check(content string) (domain.Spam, error) {
...
}
在领域服务中,我们引用的还是 SpamChecker,只是在程序初始化的时候,会将 AiSpamChecker 注入进去。
2.4 工厂
提到工厂,很容易让人联想到工厂模式。
事实上,DDD 里的工厂跟工厂模式也有很大的关系。
在领域模型中,会充分使用工厂模式来帮助我们进行领域对象的创建,工厂的引入将领域对象自身的职责与创建的具体逻辑进行了分离,并且更好的表达了业务概念。
对工厂模式不太熟悉的同学,可以看这里,这里总结了一些常用的设计模式。
2.4.1 为什么我们需要工厂
我们思考现实中的一个场景。
比如我们去驾校学习如何开车,教练会告诉你如何发动汽车、哪个是油门、哪个是刹车。作为汽车的使用者,我们仅仅知道如何使用就好了,我想大部分人都不会去关心如何去生产一辆汽车吧。
就像汽车的生产是在工厂,而普通消费者只需要知道具体如何使用一样,在领域中,工厂同样是为了将创建复杂对象的职责和复杂对象本身的职责进行分离。
需要注意的是,工厂在这里并没有承担领域模型中的职责,它只是领域设计的一部分。
职责分离是引入工厂的首要原因,但使用工厂还会带来另外的几个好处:
- 向客户隐藏了部分创建细节,避免领域知识的泄露。
在一些比较复杂的场景下,聚合根的创建通常都要一个复杂的构造流程,比如要调用其他的服务来获取某几项数据,某几个属性可以根据一定的条件自动生成等。
这些细节被封装到工厂方法里后,一方面减轻了客户负担,另一方面客户也不再需要了解模型具体的逻辑。
- 能够确保不变条件得到满足。
复杂的领域对象通常会有一些内部约束,这些约束我们称为不变条件。
比如一个人的年龄,不可能小于0也不可能大于200,这种约束条件在工厂内部会进行检查,保证所有创建出来的对象都是能够满足业务的。
- 使用工厂能够帮助我们更好的表达通用语言,也即表述业务。
在Go中,创建一个对象比较简单,比如我们有一个命名为 Product 的结构体,Product{} 即生成了这个结构体的一个实例。
但这种方法本身是一种非常技术的东西,而这里使用工厂就将业务上的创建与技术上的创建区别开来了。
2.4.2 实现工厂
1、使用单独的 New 方法创建简单对象
在前面介绍值对象的时候,举了一个 MonentaryValue 的例子,这是一个典型的简单对象,这里我们再回顾一下 :
type MonetaryValue struct {
amount int
currency Currency
}
func NewMonetaryValue(amount int, currency Currency) (MonetaryValue, error) {
if amount < 0 {
return MonetaryValue{}, errors.New("amount must ge 0")
}
return MonetaryValue{
amount: amount,
currency: currency,
}, nil
}
这里的 NewMonetaryValue 就是一个简单的工厂方法,虽然没有什么太多的逻辑,但是通过这种写法,我们将对象的创建逻辑成功凸显了出来,使得代码可以很好的表达业务概念。
在具体实现上,要遵循下面几点:
- 方法的返回值是要创建的对象和一个error。
在对象内部可能会有一些状态约束,而我们是没法保证传入的参数一定是满足这种约束的,如果不满足,需要返回具体的错误。
无论简单对象还是复杂对象,我们都可以将这种写法作为一个标准写法来实现;
- 创建的过程应该是原子的,要保证生成的对象处于一个一致的状态。也即不能创建一个半成品出来。
类似下面的写法就是错误的:
func NewMonetaryValue(amount int, currency Currency) (MonetaryValue, error) {
rlt := MonetaryValue{
currency: currency,
}
if amount < 0 {
return rlt, errors.New("amount must ge 0")
}
rlt.amount = amount
return rlt, nil
}
- 必须对参数进行业务合规性校验,否则,所创建的对象可能处于不正确的状态,后面还会有一小节专门讲到校验;
2、使用独立的工厂创建复杂对象
类似上面的 MonetaryValue ,参数不多,虽然有一些校验逻辑,但是对外部资源没有依赖,可以自我满足,除此以外的情况,就需要一个独立的 Factory 类(struct),或者是服务了。
还是以在介绍领域服务时提到的添加评价的场景来看。
评价的内容需要通过风控系统的检查,避免出现一些不合规的字眼。
风控系统因为属于外部服务,领域模型无法直接应用,在这个例子中,我们使用了领域服务,但同时,这个领域服务也承担了工厂的职责:
type ProductEvaluationCreator struct {
...
}
func (c * ProductEvaluationCreator) CreateEvaluation(product *Product, user *User, content string) (*Evaluation, error) {
if product.OffTheSale() {
return nil, errors.ErrorOf("product '%d' no longer selling", post.Id())
}
if user.IsBanned() {
return nil, errors.ErrorOf("user '%d' has banned", user.Id())
}
spam, err := s.spamChecker.Check(content)
if err != nil {
return nil, err
}
if !spam.IsPass() {
return nil, spam.Err()
}
evaluationId, err := s.evaluationRepo.NextIdentity()
if err != nil {
return nil, err
}
return entity.NewEvaluation(evaluationId, ...), nil
}
这里唯一需要说明的是,我们已经声明了 ProductEvaluationCreator ,为什么在最后还是需要调用 entity.NewEvaluation(...)呢?
这有两方面原因:
- 领域模型的校验本身可能比较复杂,一些单属性校验、或者一些可以自我满足的校验还是要放到对象内部来实现;
- 在仓储层,将持久化的数据转化成领域对象时,是不需要校验的,我们可以认为被持久化了的数据一定是满足模型约束的,那么这个时候就需要一个轻量级的构造方法;
2.4.3 对模型进行校验
校验主要的目的是为了保证模型的正确性。
一般校验的方法是逐级校验,即,首先保证领域模型的各个属性是合法的,再保证这些属性组合起来是合法的,最后在单个领域对象合法的基础上再保证对象之间的组合是合法的。
1、单个属性的校验
对于简单对象,其内部属性比较少时,可以将对属性的校验置于工厂方法里,比如 MonetaryValue 就采用的这种方式。
对象内部属性比较多时,可以采用自封装的方式,简单来说就是为属性提供一个 setter 方法,对属性的赋值都通过 setter 方法。我们也可以将 MonetaryValue 的校验改成自封装形式: ```go type MonetaryValue struct { amount int currency Currency }
func (v *MonetaryValue) setAmount(amount int) error { if amount < 0 { return errors.New(“amount must ge 0”) } v.amount = amount return nil }
func NewMonetaryValue(amount int, currency Currency) (MonetaryValue, error) { rlt := &MonetaryValue{ currency: currency } if err := rlt.setAmount(amount); err != nil { return MonetaryValue{}, err } return *rlt, nil }
**2、对象整体的校验**<br />对领域对象的验证,推荐放到一个单独的组件或者方法里,这样就将校验逻辑从领域对象中剥离了出来。<br />另外,校验逻辑的变化速度和领域对象的变化速度是不一样的,领域对象相对更稳定,因此将校验逻辑剥离,使其单独演化,更符合 SOLID 原则。
```go
type Product struct {
...
}
// 同包下定义校验器
type ProductValidator struct {
product *Product
...
}
func (v *ProductValidator) Validate() error {
...
}
或者是就是一个简单的方法:
func ValidateProduct(product *Product) error {
...
}
具体使用哪种方式,需要具体问题具体分析。
如果直接使用函数就可以完成校验,那么就定义一个方法就可以了,单独的方法完不成可以再使用 Validator 的形式。
另外,在校验的过程中可能发现多处错误,我们这里推荐的做法是,当发现非法状态时,直接中断后续校验,立即返回当前校验错误即可。
有些校验框架会收集所有验证的结果,私以为是没必要的,因为最终返给用户的是具体的某一条错误。
最后,对 Validator/校验方法 的调用职责,就落到工厂的头上了,工厂在生成对象后,需要手动执行下校验方法。
在 Java 里可以通过构造方法和继承来帮助我们自动执行校验,但是Go没法做到这一点。
3、对象组合的校验
因为涉及到多个对象,所以这种逻辑是不会放到具体某个领域下的,那最好的地方是哪里呢?领域服务。
2.5 领域事件
2.5.1 事件的定义
领域事件作为DDD中很重要的一个概念,其表示在领域中已经发生的对业务有价值的事实。
既然是领域中的概念,所以对领域事件的定义应该放在 domain 包内,享有与值对象、实体同样的待遇:
├── domain
│ ├── entity
│ ├── event # 领域事件的定义放在这里
│ ├── repository
│ ├── service
│ └── vo
同时,在事件的命名上,应当遵循过去完成时的命名方式,比如,订单已提交:OrderCreated,订单已支付:OrderPaid,等等。
确定了位置和命名,下一个问题就是确定在事件中应该包含哪些属性?
首先,领域事件在建模时,一些通用属性是必须要有的,比如事件的id、事件产生的时间。其中,事件的id要能唯一的标识这个事件。
因为这两个属性比较重要,我们用一个接口来表示通用的领域事件:
type DomainEvent interface {
fmt.Stringer
Id() string
OccurredOn() time.Time
...
}
注意这里的 Id() string 返回的并不是某个领域实体的唯一标识,而是当前领域事件的唯一标识。
另外,领域事件的产生,一般是由于聚合状态的变更,因此,在领域事件上,还应该包含对应的聚合根id。
因为我们不太确定聚合根id的类型,所以如果将一个 AggregateId() interface{} 方法放到 DomainEvent 上是不太合适的,毕竟使用起来不太方便。
但是,我们可以针对每个聚合根定义一个对应的 Event 接口,比如对于订单,可以定义下面的订单事件接口:
type OrderEvent interface {
DomainEvent
OrderId() int64
}
对于产品,定义对应的产品事件接口:
type ProductEvent interface {
DomainEvent
ProductId() int64
}
之后,在这两个聚合根上产生的所有事件都可以通过实现对应接口的方式来定义,比如创建订单:
type OrderCreated struct {
EventId string
AggregateId int64
OrderCreatedAt time.Time
}
func (e *OrderCreated) Id() string {
return e.EventId
}
func (e *OrderCreated) OccurredOn() time.Time {
return e.ExamCreatedAt
}
func (e *OrderCreated) OrderId() int64 {
return e.AggregateId
}
func (e *OrderCreated) String() string {
// json marshal
...
}
通过不同的接口,我们也可以方便的识别出事件是来自于哪个聚合的,对于某些监听者,可能只关心某个聚合根上的事件,这就变得很有用了。
在这个示例中,所有的属性都采用了大驼峰法。
在更严格的意义上来看,事件应该是具有不变性的,毕竟已经发生了的事实是不容许更改的,因此,事件跟值对象有一定的相似性,而值对象里的属性使用的是小驼峰法,这里为何不同?
主要原因在于Go语言的特性,这是一种妥协的写法。
对于事件来说,我们大概率是需要将其序列化为json字符串,然后通过消息队列广播出去的。如果采用小驼峰法,这个序列化的操作就会变得比较麻烦,所以这里妥协使用了大驼峰法。
至此,项目中所有的领域事件看起来是具有类似下面这种继承关系的集合: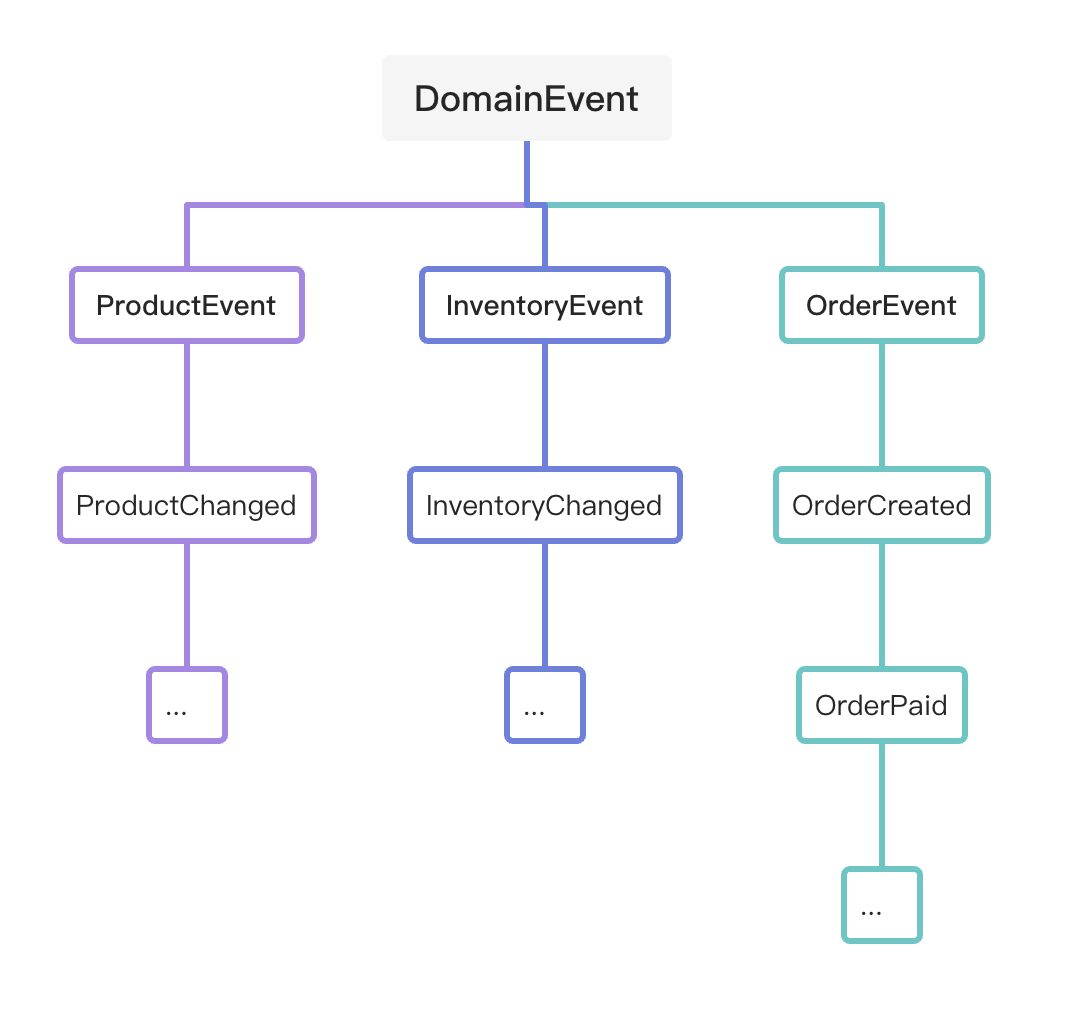
最后,在领域事件中还应该包含事件发生时的上下文信息。
例如,在一个 ProductInventoryChanged 事件中,就应该同时包含变更之前的状态和变更之后的状态:
type ProductInventoryChanged struct {
EventId string
AggregateId int64
UpdatedAt time.Time
OldValue int // 变更前状态
NewValue int // 变更后状态
}
...
2.5.2 事件的发布
领域事件一般在聚合根中生成,这里的主要问题是如何将领域层定义好的事件发布出去。
发布这个动作本身是偏技术的,所以,我们的原则还是业务逻辑能跟技术细节进行解耦。
接下来会讨论几种不同的实现方式,并给出最推荐的形式。
首先,我们定义一个发布接口:
type EventPublisher interface {
Publish(event DomainEvent) error
}
1、EventPublisher 作为参数传递给聚合根上需要发布领域事件的方法
比如在 Order 上有一个修改产品数量的方法:
type Order struct {
...
}
func (o *Order) ChangeProductCnt(productId, count int64, publisher EventPublisher) error {
... // 执行业务逻辑
// 最后调用EventPublisher进行事件的发布
publisher.Publish(OrderProductCountChanged{
OrderId: o.Id,
OccurredOn: time.Now(),
....
})
return nil
}
这种写法我们在前面谈到领域服务的时候也提到过,其最大的问题是对接口的污染,多出来的这个参数不仅给调用方带来不便,对领域的职责也是一个负担,因为其本不应该关心这些。
2、实体中不直接发布领域事件,而是返回
func (o *Order) ChangeProductCnt(productId, count int64) (*OrderProductCountChanged, error) {
... // 执行业务逻辑
// 最后直接返回需要发布的事件
return &OrderProductCountChanged{
OrderId: o.Id,
OccurredOn: time.Now(),
....
}, nil
}
如上所示,领域实体不承担发布功能,就需要提一个领域服务出来,将相应的发布逻辑放到领域服务中。
虽然这种方法也达到了发布领域事件的目的,这跟发布领域事件的业务含义有些不符,并且在领域服务中也只是完成了 publisher.Publish(event)的调用,显得有点过于重了。
在多年前人们就已经讨论过采用返回领域事件的方法,可以参考这个链接,不过现在已经不推荐使用了。
3、采用静态方法发布领域事件
为了避免在方法参数中传递 EventPublisher,人们又提出了另外一种方法,即使用静态方法。
在 Java 里,静态方法可以直接通过类来访问,比如:
public class EventPublisher {
...
public static void publish(event DomainEvent) {
...
}
}
// 使用的时候直接调用
public class Order {
public void ChangeProductCnt(...) {
... // 业务逻辑执行
event = ...
EventPublisher.publish(event)
}
}
在 Go 里虽然没有静态方法,但是我们可以通过 var eventPublisher EventPublisher 的形式来模拟类似静态方法的调用形式:
var (
eventPublisher EventPublisher
once sync.Once
)
func Init(publisher EventPublisher) {
if eventPublisher == nil {
once.Do(func() {
eventPublisher = publisher
})
}
}
之后在聚合根中直接使用:
func (o *Order) ChangeProductCnt(productId, count int64) error {
... // 业务逻辑
event := ...
eventPublisher.Publish(event)
}
我个人而言,不是太喜欢这种写法,首先在使用之前需要调用Init函数,我们可能并非每次都能清楚的记得去做这件事。
其次,这种方式虽然避免了接口的污染,但是又带来了新的问题,即,对 ChangeProductCnt 方法进行测试是困难的。
4、在实体中临时保存领域事件,在仓储中进行发布
最后一种方式是在聚合根中临时保存领域事件,有点类似上面提到的返回领域事件的方式,但是稍微做了改进。
我们在 Order 这个实体中加入一个 OrderEvent 的 slice:
type Order struct {
events []OrderEvent
...
}
func (o *Order) ChangeProductCnt(...) error {
... // 业务逻辑
o.raiseProductCountChangedEvent() // 生成exam后,调用发布事件的方法
return exam, nil
}
func (e *Order) raiseProductCountChangedEvent() {
e.RaiseEvent(&OrderProductCountChanged{
OrderId: o.Id,
...
})
}
func (o *Order) RaiseEvent(event OrderEvent) {
e.events = append(e.events, event)
}
func (o *Order) ClearEvents() {
for idx := range e.events {
e.events[idx] = nil
}
e.events = nil
}
在业务方法里通过调用 RaiseEvent 来发布对应的领域事件,发布的领域事件会暂时存放在 events 切片中。
领域对象在修改完毕后,我们需要在仓储中对其进行持久化,同时,我们也在这里对领域事件进行真正的发布,在发布完毕后,还要将领域事件清空。
type OrderRepository struct {
eventPublisher EventPublisher
...
}
func (r *OrderRepository) Save(order *Order) error {
for _, event := range order.Events() {
r.eventPublisher.Publish(event)
}
exam.ClearEvents()
// 执行持久化操作
...
}
这样实现的话,Order 实体因为不跟任何外部组件耦合,测试比较容易。
其次,EventPublisher 和 OrderRepository 都是具体的技术实现,代码也都放在 infra 包下,因此它们之间进行引用是合理的。
5、通过事件表保证原子性
到这里,大部分对事务没有特别严格要求的场景就已经得到满足了。但是对于严格要求的场景呢?如何保证消息的发布与领域对象的存储这两个流程是原子的呢?
我们首先想到的可能是使用分布式事务,但是这种方式不仅实现起来复杂,性能也不高。
在《微服务架构设计模式》一书中,提到了另外一个思路,即事件表的形式。
简单来说,在 Repository 中不再对事件直接进行发布,而是将事件同聚合根一起存储到同一个数据库里,通过数据库的本地事务即可实现这一步的原子性。
之后,利用一个异步任务来读取数据库里存储的所有未发送事件,在发送成功后将对应的事件从数据库中删除。
我们可以用代码简单表示如下:
type OrderRepository struct {
orderDal OrderDal
eventDal EventDal
}
func (r *OrderRepository) Save(order *Order) error {
if err := r.eventDal.Save(order.Events()...); err != nil {
return err
}
order.ClearEvents()
if err := r.orderDal.Save(order); err != nil {
return err
}
}
当然,这种方式也不是完美的,异步任务读取事件表并进行发送,这仍然是两个步骤,这个过程依然需要保证原子性。
貌似事情又回到了原点。
一种解决方案是将消费方做成幂等的。
异步任务读取到未发送事件时,先发送事件再标记为已发送,如果第二步出错,可以再次进行重试,因为消费方幂等,所以重试并不会带来问题。
同时,为了不给数据库带来太大的负担,定时任务的时间间隔不应设置的过小,其更多的应该是一种兜底策略。
所以,为了能够及时的将事件发布出去,我们可以在事务提交后触发这个流程,在某些框架中,通常可以在 Middleware 中进行触发操作。
3. 应用层实现
在设计模式中,有一个结构型模式:门面模式。
门面模式提出的初衷,是为程序库、框架或者其他复杂类提供一个简单的接口,接口的功能可能比较有限,但是你真正关心的。通过这个接口,屏蔽了第三方类/系统的实现细节,使得代码的理解和维护都更容易了。
在DDD的战术实现中,同样存在着这样一个“门面”,也即应用服务。
3.1 定位与实现原则
应用服务是领域模型的直接客户!!!
通常我们会遵循下面的几个原则来构建应用服务:
- 应用服务上的一个业务方法对应了一个业务用例,它们彼此是一一对应的关系;
- 每个业务方法都应当被封装到一个事务中,其与事务也是一一对应的;
- 在应用服务中不处理具体的业务逻辑,也不需要对参数进行业务校验,外部需要保证参数的基本合法性;
- 应用服务的定位是领域模型的门面,不应该处理一些具体的技术细节,也即不能跟具体的框架绑定在一起;
- 可以处理跟安全相关的一些操作,比如权限控制,但是更推荐将这种功能放到切面中;
总的来说,领域模型和领域服务中承载了所有的业务逻辑,而应用服务在复杂模型的基础上提供了一个统一的出口,这个出口通过协调对模型的一些操作,来实现外部的用例要求。
因此,应用层在实现上通常是很薄的一层,因为这里不涉及具体的业务逻辑和技术细节。
3.2 应用服务的实现
3.2.1 代码应该放于何处
从分层架构上来看,应用服务和领域模型是处于两个不同的层级的,因此,在落实到代码上时,应用服务和领域模型也应该处于不同的包下。
可以在跟 domain 包平级的地方创建一个 application 包,包中依据不同的领域,可以创建不同的 service 文件,每个 service 文件作为具体某个应用服务的载体。
这里采用 application 包名的话,虽然很直观,但是 application 这个单词有点长,在不影响对代码理解的前提下,可以使用 app 作为 application 的缩写,这样在使用时稍微简单点,直接 app.xxx 就可以了。
├── app # application
│ ├── ... # 其他包,如果有的话
│ ├── order_service.go
│ ├── product_service.go
│ └── inventory_service.go
├── domain
│ ├── entity
│ ├── event
│ ├── repository
│ ├── service
│ └── vo
3.2.2 服务的定义
通常的做法是直接定义一个结构体,而非使用独立接口模式。
在应用服务层,原则上是可以访问领域层和基础设施层的,因此这里不存在需要分离接口和实现的必要。
但是,也不推荐直接定义 func 来实现某个应用服务功能,因为在应用服务中通常需要引用 Repository 或者领域服务。
如下定义了一个 OrderApplicationService,代码放在 app.order_service.go 文件内。
其内部属性一般是对 Repository 或领域服务的引用,它们大部分(部分领域服务并不是采用的独立接口模式)是以接口的形式存在的:
package app
type OrderApplicationService struct {
orderRepo repository.OrderRepository
... // 对其他服务的引用等
}
为了能够对 OrderApplicationService 进行实例化以及属性的依赖注入,我们同时还要提供一个构造方法:
func NewOrderApplicationService(orderRepo repository.OrderRepository, ...) *OrderApplicationService {
return &OrderApplicationServce{
orderRepo: orderRepo,
...
}
}
这里仅以 repository.OrderRepository 为例来说明构造方法的参数类型。
也即,构造方法的参数类型跟结构体中的属性类型是一致的,比如属性中是一个接口,那么这里的参数类型也必须是一个接口。
严禁参数是接口的具体某个实现,使用接口形式的参数,方便我们充分利用多态的能力。
在 OrderApplicationService 里,每一个方法对应了业务中的一个用例:
// 这里先暂时忽略服务方法的入参、出参
func (s *OrderApplicationServce) CreateOrder(...) ... {
...
}
func (s *OrderApplicationServce) ChangeOrderProductCount(...) ... {
...
}
...
到目前为止,我们还未就领域服务中某个方法具体要如何实现展开说明,接下来要讨论的内容虽然我们比较熟悉,但是争论也比较大。
3.2.3 服务方法的入参
每个应用服务方法的第一个参数应该是 context.Context,这一点应该没有太大的异议,因为要保持应用服务的无状态性,不能将context.Context定义为应用服务的属性。
但是后面的参数要怎么传呢?我们这里考虑的因素主要是合理性和便利性。
考虑到合理性,第一条原则便是不允许将领域模型泄露到应用层之外。
所以,这里的入参类型不能够是领域模型中的实体或值对象,否则,应用服务的调用方(在我们的kitex服务中,一般是具体的某个handler)就要承担如何构建这样一个值对象或实体的职责,而我们是不希望领域以外的调用方去了解这些细节的。
其次,我们先考虑在参数数量较少时的传参。
在参数个数较少时,比如只有一两个(最多三个),我们可以直接将这两三参数定义在方法的参数列表中。
要注意这两三个参数的类型应该都是 Go 里的简单数据类型,类似 struct 和 map 是不行的。
因为参数个数不多,所以对于应用服务的调用者来说,其负担并不重,无论在 kitex 服务中还是http服务中,都很容易从 Request 中解析出来。
当参数的数量大于三个时,对于方法的调用者来说就不那么友好了,尤其是当连续几个参数的类型一样时,很容易将它们的顺序搞错,这个时候就得特别小心。
一种常见的解决方案是使用 DTO,将除了 context.Context 以外的其他参数封装到一个DTO里,这个 DTO 进一步可以划分成 Command 和 Query,这个在后面说到 CQRS 的时候再详谈。
DTO 在严格意义上说,也是值对象,只不过是没有业务意义的值对象,也应该具有不可变性。
另外一种解决方案是直接使用 IDL 中定义的 Request,下面就说下这两种方式的优缺点。
在一些RPC服务或者HTTP服务中,通常会通过IDL来定义接口,比如 Grpc 中使用 ProtoBuf,Kitex 中使用 thrift 等。
| 使用独立DTO | 优点 | 因为DTO的属性都是基本类型,方便适配不同类型的应用服务调用者。比如在 rpc 中是使用 thrift 定义的 XXRequest,在 Http中是对应的 json 字符串或者 pb。 |
|---|---|---|
| 在 DTO 中可以定义对各个属性的基本校验规则,将校验逻辑收敛在一处,在调用服务前能保证参数的合法性。 | ||
| 缺点 | 各调用方需要手动构建这样一个 DTO,这个成本大部分情况下都不算高,但是个别时候,尤其在 DTO 里的属性跟 IDL 定义的 Request 高度一致的时候,会显得比较冗余。 | |
| 频繁创建 DTO,增加了GC的负担。 | ||
| 直接使用IDL中的Request | 优点 | 在 rpc 服务中很方便,不需要转换,但是基本的参数校验还是要做的,也即传入应用服务的 Request 是已经校验好了的。 |
| 缺点 | 如果这个应用服务在 rpc 以外还有其他场景的调用,比如在Http中,就需要构建这样一个 Request,用起来比较别扭。其根本原因是应用服务跟具体的框架进行了强绑定。 | |
| 应用服务中的方法跟 IDL 中定义的方法并非一定是一一对应的,应用服务中的方法更多是跟用例挂钩,而 IDL 中的方法更多是为了方便调用方的使用而定义的。接口的变更频率相对更高,而模型更稳定,这个差异会导致应用服务层不稳定。 |
这里以使用DTO的形式给出示例代码:
type ChangeOrderProductCntCmd struct {
UserId int64 `valid:"required~用户ID不能为空"`
OrderId int64 `valid:"required~订单ID不能为空"`
ProductId int64 `valid:"required~产品ID不能为空"`
ProductCnt int32 `valid:"required~产品数量不能为空"`
}
// 之后可以这样使用
cmd := &ChangeOrderProductCntCmd{
... // 各属性赋值
}
if _, err := govalidator.ValidateStruct(cmd); err != nil {
return err
}
// 如果是kitex服务,可以在返回Response那里解析出具体的错误
func handleError(err error) (statusCode int, statusMessage string) {
if err == nil {
return 0, "success"
}
switch t := errors.Cause(err).(type) {
case govalidator.Errors:
return 400, parseFirstValidatorErrorMessage(t)
... // 其他case分支
default:
return 500, "Internal Error"
}
}
func parseFirstValidatorErrorMessage(err govalidator.Errors) string {
for _, e := range err.Errors() {
return e.Error()
}
return "数据校验错误"
}
综合上面的说明,我们可以总结出如下的一些最佳实践:
- 不要使用领域模型作为参数;
- 当参数个数较少时(一般不超过3个),并且每个参数都可以使用原始类型表示,可以将参数直接定义在方法里;
- 参数大于3个或者无法用简单的原始类型表示时,优先考虑使用 DTO;
- 当 IDL 中声明的接口正好跟用例一致时,可以妥协为直接使用 IDL 的 Request,比如我们在定义一些 AGW 对应的接口时,大部分时候是按照用例来的,这时就可以直接使用thrift定义的类型;
- 如果使用 IDL 中的 Request 作为入参,注意不要将这个 Request 传播到领域层;
3.2.4 服务方法的出参
必须要强调的是,不要直接把领域模型作为返回参数。
其目的还是避免领域模型的泄露。
如果直接返回领域模型,那么服务的调用者就要对模型内部比较清楚,这样才能够构建出自己想要的数据。
不返回领域模型,怎么将数据传递出去呢?
一般有下面几种方法,在实现上有利有弊,具体使用何种方式,并没有强制的规定,更多是个人倾向。
最简单的情况是返回的数据比较简单,比如一些新建的方法只要返回创建成功的ID,这里直接使用原始类型就能满足要求。
而这里的挑战在于,有的时候需要返回的数据可能涉及多个领域模型的属性。我们如何在不暴露领域模型细节的基础上返回。
1、使用 DTO 包装要返回的数据
DTO 的缺点在于我们可能需要创建一大堆跟领域对象非常相似的结构体,并且增加了 GC 的负担。如果 IDL 中定义的 Response 跟 DTO 的结构差异不大,这个时候就更显得多余。
其次,有的时候我们也很难决定 DTO 里到底要封装哪些数据。
使用 DTO 带来的另外一个问题是,我们需要给 DTO 同时提供一个装配器,装配器负责收集多个领域模型的属性,然后构建出 DTO 实例。
当需要新增或修改DTO的属性时,除了DTO还需要修改对应的装配器。这样一来就会稍显麻烦,其本质原因是没有做到符合开闭原则。
如下展示了使用 DTO 时的实现方式,其中,cqe是 Command、Query、Event 的缩写,表示存放的是这三种类型的 DTO: ```go package cqe
type ProductDTO struct { Id int64 Name string Price int32 Inventory int32 Detail string }
package assemlber
func AssembleProductDTO(p Product, i ProductInventory) *ProductDTO { return &ProductDTO{ Id: p.Id(), Name: p.Name(), Price: p.Price(), Inventory: i.Count() Detail: p.Detail(), } }
// 在应用服务中调用 return assembler.AssembleProductDTO(productE, inventoryE)
DTO 的引入虽然增加了我们的负担,但是在多个客户端的场景下很有效,比如这个方法同时服务于HTTP、RPC、MQ、Console等。<br />**2、另外一种跟 DTO 比较类似的是 DPO(领域负载对象domain payload object)**<br />还是以上面 ProductDTO 为例来看下对应 DPO 的实现:
```go
type ProductDPO struct {
product *Product
inventory *ProductInventory
}
func (p *ProductDPO) Id() int64 {
return p.product.Id()
}
func (p *ProductDPO) Name() string {
return p.product.Name()
}
func (p *ProductDPO) Detail() string {
return p.product.Detail()
}
func (p *ProductDPO) Price() string {
return p.product.Price()
}
func (p *ProductDPO) Inventory() int32 {
return p.inventory.Count()
}
与DTO显著的区别是,DPO中包含了对所用到领域模型的引用,而非单独的属性。
这些引用都是私有属性,包外无法直接访问,也就避免了模型细节的泄露。客户端需要的属性通过具体的方法提供。
不同于 DTO 将结构体的定义和组装拆分到了两个地方,在 DPO 中,当某个属性有变动时,只需要修改 DPO 自身即可。
3、调停者(强烈不推荐使用)
在该模式下,会针对每个领域模型定义一个“兴趣接口”。
领域服务不再返回具体的数据,参数也变成传入对应的兴趣接口,因为在实际业务中很少这么用,所以了解一下即可。
// 先定义一个接口
type ProductInterest interface {
InformId(int64)
InformPrice(int32)
}
// 在实体上实现一个ProvideProductInterest方法
type Product struct {
...
}
func (p *Product) ProvideInterest(interest PostInterest) {
interest.InformId(p.Id())
interest.InformPrice(p.Price())
}
// 外部实现 ProductInterest 接口,获取感兴趣的属性
...
4、直接使用IDL定义的 XXResponse
最后一种是最方便的,但使用的话,同样存在一定的约束条件。
即 idl 定义的接口跟用例保持一致。
其次,使用这种方式也不是没有成本的:
- 首先,我们同样需要定义一个装配器,用来将领域模型上的属性装配到 Response 上;
- 其次,因为 Response 跟具体的框架相关,所以还会涉及在出错情况下的 Response 组装,但这本不应该属于应用服务的责任,相应的解决办法是返回 nil 和对应的错误,在外层再通过错误组装成对应的 Response。
最后总结一下:
- 无论入参和出参,在参数数量很少的情况下处理起来都比较简单,也没有太多争议;
- 当参数变的复杂后,就需要判断到底使用什么方式,从我个人的经验来看,入参使用 Command + Query 形式的 DTO,出参使用 DPO ,这种组合基本上可以应对90%以上的应用场景。如果没有特别的考量,可以无脑使用这种方式。
3.3 领域事件的消费
我们在 2.5 节介绍了领域事件的定义和发布,貌似“遗漏”了事件的消费。
为何将事件的消费放到这里讲呢?
在我看来,事件不过是一种特殊的 Command,与应用层作为外部请求的入口一样,事件的消费入口同样是在应用层。
既然如此,我们就可以在 app 包下定义一个 DomainEventApp: ```go package app
type DomainEventApp struct { … }
func (s DomainEventApp) OnOrderCreated(ctx context.Context, event ddd.DomainEvent) error { if created, ok := event.(order.OrderCreated); ok { … } }
func (s DomainEventApp) OnOrderProductCountChanged(ctx context.Context, event ddd.DomainEvent) error { if created, ok := event.(order.ProductCountChanged); ok { … } }
…
DomainEventApp 里的每个方法,都是对特定某个领域事件的处理。<br />方法的参数一般是 Context 和对应监听的领域事件,而返回值只是一个error,用来标识当前处理是否成功。<br />在整个领域事件流程中,存在两种类型的消费,一种是本地消费,另一种是远程消费。<br />对于本地消费者,就需要先注册一个监听,表示其对哪类的事件感兴趣。<br />在 [DDDCore](https://github.com/zhenyu888/ddd-core) 这个库中,提供了便捷的 [RegisterSyncEventSubscriber](https://github.com/zhenyu888/ddd-core/blob/main/ddd/event.go#L79) 方法,我们可以在 DomainEventApp 实例化的时候对本地消费者进行注册:
```go
package app
func NewDomainEventApp(...) *DomainEventApp {
rlt := ddd.LoadOrStoreComponent(&DomainEventApp{}, func() interface{} {
rlt := &DomainEventApp{}
ddd.RegisterAsyncEventSubscriber("rocket_order_created", rlt.OnOrderCreated)
ddd.RegisterAsyncEventSubscriber("rocket_order_updated", rlt.OnOrderProductCountChanged)
...
return rlt
})
return rlt.(*EventAppService)
}
type EventAppService struct {
...
}
...
而对于远程消费,一般就是通过消息队列进行实现。
这里需要注意的是, 消息队列通常能够保证的是“至少一次投递”,这也就要求我们在进行消费时必须保证消费的幂等性。
幂等性消费有很多种实现方式,比较通用的办法是记录下当前已经消费了的消息的唯一id,下次再收到该类型的消息时,先根据唯一id检查是否已经消费过。
我们需要一个 handler 函数作为入口,在这个 handler 里主要的工作是对消息进行解码并进行基本校验,之后,调用 DomainEventApp 里的相关方法来完成具体的逻辑:
var domainEventApp *app.DomainEventApp
func init() {
domainEventApp = ...
}
func Handler(ctx context.Context, payload interface{}) (*events.EventResponse, error) {
event := ...
err := domainEventApp.OnOrderCreated(ctx, event)
...
}
在消费方对领域事件进行消费的同时,依然有可能进一步产生事件。
在强一致性场景下,我们依然可以采用事件表的形式。
3.4 处理事务和安全
在DDD中有一条原则:一个业务用例对应一个事务,一个事务对应一个聚合根。
一个业务用例对应了一个应用方法,所以每个应用方法原则上应该被一个事务所包围。
在 java 中通常会这样实现事务:
@Transactional
public OrderId createOrder(CreateOrderCmd cmd) {
...
}
通过 @Transactional注解,默认开启一个传播机制为 REQUIRED 的事务。
但是在 Go 中目前还没有一种很方便的对业务侵入性比较小的方案,更多的时候还是靠人工 Begin、Commit 等。
比如在 Gorm 中提供了 Transaction 方法:
db.Transaction(func(tx *gorm.DB) error {
// 在事务中执行一些 db 操作(从这里开始,您应该使用 'tx' 而不是 'db')
if err := tx.Create(&Animal{Name: "Giraffe"}).Error; err != nil {
// 返回任何错误都会回滚事务
return err
}
if err := tx.Create(&Animal{Name: "Lion"}).Error; err != nil {
return err
}
// 返回 nil 提交事务
return nil
})
这个 Transaction 方法内部也是通过调用 tx := db.Begin() 、tx.Commit()、 tx.Rollback() 等方法实现的。
同时,通过 SavePoint 还实现了对嵌套事务的支持。
但是,更多的时候,我们希望能够对事务的传播有更多的控制权,比如下面的示例:
func A(ctx context.Context, ...) {
db.Transaction(func(tx *gorm.DB) error {
... // do some thing
B(ctx) // 之后调用了 B 方法
return nil
})
}
func B(ctx context.Context) {
db.Transaction(func(tx *gorm.DB) error {
... // do some thing
return nil
})
}
当外部调用函数 A 的时候,会起一个事务,而 A 又调用了函数 B,这个时候希望 A、B 在同一个事务里。而当外部直接调用函数 B 的时候,希望 B 也能够在一个事务里。
类似这种需求,我们实现起来是比较困难的,或者不太优雅。
因此,我们在 Gorm 事务的基础上进行了扩展,引入了对事务传播机制的支持:
const (
PropagationRequired = iota // 支持当前事务,如果当前没有事务,就新建一个事务
PropagationRequiresNew // 新建事务,如果当前存在事务,把当前事务挂起,两个事务互不影响
PropagationNested // 支持当前事务,如果当前事务存在,则执行一个嵌套事务,如果当前没有事务,就新建一个事务
PropagationNever // 以非事务方式执行,如果当前存在事务,直接返回错误
)
同时,定义了 TransactionManager ,它只有一个对外的 Transaction 方法:
type TransactionManager struct {
factory DBFactory
}
func (m *TransactionManager) Transaction(ctx context.Context, bizFn func(txCtx context.Context) error, propagations ...TransactionPropagation) error {
propagation := defaultPropagation()
if len(propagations) > 0 && isPropagationSupport(propagations[0]) {
propagation = propagations[0]
}
switch propagation {
case PropagationNever:
return m.withNeverPropagation(ctx, bizFn)
case PropagationNested:
return m.withNestedPropagation(ctx, bizFn)
case PropagationRequired:
return m.withRequiredPropagation(ctx, bizFn)
case PropagationRequiresNew:
return m.withRequiresNewPropagation(ctx, bizFn)
}
panic("not support propagation")
}
有了 TransactionManager 我们再实现上面 A 调用 B 的例子就方便多了:
func A(ctx context.Context) {
manager.Transaction(ctx, func(txCtx context.Context) error {
... // repo do some thing
B(txCtx) // 这里传入了新的 Context
return nil
})
}
func B(ctx context.Context) {
manager.Transaction(ctx, func(txCtx context.Context) error {
... // repo do some thing
return nil
})
}
TransactionManager 的 Transaction 方法默认使用的是 PropagationRequired 传播机制,因此,上面的代码都没有使用可选参数,也就是说,当 B 被调用时,会判断一下当前是否在一个事务当中,如果是就复用当前事务,如果不是则新起一个事务。
如果我们希望 B 能够在一个独立的事务中,则可以这么写:
func B(ctx context.Context) {
manager.Transaction(ctx, func(txCtx context.Context) error {
... // repo do some thing
return nil
}, ddd.PropagationRequiresNew) // 这里明确指定了使用 PropagationRequiresNew 传播机制
}
这样,每次 B 被调用时就会将当前事务挂起(如果有的话),然后新起一个事务,两个事务互不干扰。
这个功能的实现在于对 context.Context 的扩展。
我们定义了 TransactionContext ,它持有了原来的 context.Context,同时也实现了 context.Context 中的几个方法。因此,TransactionContext 也可以当做 context.Context 来用:
type TransactionContext struct {
ctx context.Context
tx *gorm.DB
parent *TransactionContext
}
func (c *TransactionContext) Deadline() (deadline time.Time, ok bool) {
return c.ctx.Deadline()
}
func (c *TransactionContext) Done() <-chan struct{} {
return c.ctx.Done()
}
func (c *TransactionContext) Err() error {
return c.ctx.Err()
}
func (c *TransactionContext) Value(key interface{}) interface{} {
return c.ctx.Value(key)
}
... // 其他方法
在 Transaction 方法中,会对当前 Context 进行类型判断,如果不是 TransactionContext,则会将其包装成 TransactionContext 传递给 bizFn,在 bizFn 中如果调用到了其他函数,还会将 TransactionContext 继续传递下去。
但是,在子方法中(比如上面A调B场景下的B方法),并不会直接复用上层的 TransactionContext ,而是通过 TransactionContext 的 Session 方法生成一个新的 TransactionContext ,新旧两个 TransactionContext 是父子关系:
// 类似于 gorm.DB 中的 Session 方法
func (c *TransactionContext) Session(config *gorm.Session) *TransactionContext {
return &TransactionContext{
ctx: c.ctx,
tx: c.tx.Session(config),
parent: c,
}
}
这样实现的作用是为了在子函数中调用的 Transaction 方法不会误提交整个事务:
func (c *TransactionContext) Commit() error {
if !c.InTransaction() {
return ErrNotInTransaction
}
if c.IsRoot() { // 只有顶层的 TransactionContext 才会真正提交事务
return c.tx.Commit().Error
}
return nil
}
其余的几种传播机制实现原理与上面类似,就不再赘述。完整的代码可以参考这里>>
在应用服务中除了对事务进行控制,还可以承担安全的职责。
这里说的安全主要指的是 Authorization,而非 Authentication,不过,这种类型的需求,建议将其实现到某个切面中,比如在 AGW 服务中的 Handler。
4. 基础设施层实现
4.1 仓储
简单来说,仓储就是用来持久化聚合根的,但其跟我们平时使用的dal又有所不同。
dal 是对具体数据库的直接操作,是跟数据库类型强相关的,而仓储只服务于聚合根,而且其也只是在概念上规定了对聚合根的持久化,不关心具体存到哪里以及如何存的问题。
4.1.1 接口定义
仓储接口的定义是跟领域对象放在一起的,如下面的目录结构所示:
├── domain
│ ├── exam
│ │ ├── entity.go
│ │ ├── event.go
│ │ ├── repo.go # 仓储接口的定义放在这个文件里
│ │ └── vo.go
因为 domain 层原则上不能依赖任何其他层,因此,domain 下所有文件里都不应该 import 任何其他层的代码。
这也就意味着,我们在 repo.go 文件中定义的 Repository 接口的入参、出参都应当是领域层的结构体或者go里的简单类型。
其次,因为 Repo 不关心底层具体的存储到底是什么,所以我们在命名方法时,应当避免使用带有明显技术色彩的词语,比如inser、update、select、delete这种。通常建议使用save、find、remove这类更加笼统的词汇。
前面在介绍工厂方法时,提到了可以通过在仓储中定义一个 NextIdentity 方法来生成实体的唯一标识。
因此,综合上面的论述,一个 Repository 接口至少应该包含下面几个方法:
type Repository interface {
NextIdentity() (int64, error)
Save(context.Context, *Exam) error // 保存一个聚合
Find(context.Context, int64) (*Exam, error) // 通过id查找对应的聚合
FindNonNil(context.Context, int64) (*Exam, error) // 通过id查找对应的聚合,聚合不存在的话返回错误
Remove(context.Context, *Exam) error // 将一个聚合从仓储中删除
}
其中,我们没有明确区分新增和更新操作,而是只定义了一个 Save 方法。
站在 Repository 的角度来看,它的职责只是将领域模型保存起来,到底是新增还是更新是技术层面需要关心的,而不是它。
再次, FindNonNil 跟 Find 比较类似,当指定id对应的实体不存在时,Find 会返回 nil, nil,而 FindNonNil 会认为这是一个错误,error 会返回 NotFound,这在某些场景下会非常有用。
除了这几个基本接口,各个业务可以在这个基础上根据自身场景进行扩展。
4.1.2 实现仓储接口
仓储接口定义在domain层,而具体实现是定义在基础设施层的。
为了区分基础设施层不同的功能模块,可以对基础设施层进一步划分,而仓储相关的代码可以统一放到 infra.persistence 包下。
├── domain
│ └── repo
│ └── order_repo.go
├── infra
│ ├── persistence
│ │ ├── converter # 可能存在这样一个层,用来做领域模型与数据模型之间的转化
│ │ ├── dal
│ │ └── order_repo_impl.go
在上面的代码结构中,repo.OrderRepo 接口对应的实现 OrderRepository 放在 order_repo_impl.go 文件中。
dal 中放置的是具体的对数据库表的访问。
converter 这个包可能存在也可能不存在,其主要作用是对领域模型和数据模型进行互转。
当领域模型与数据模型的字段一致时,可以退化为只使用领域模型。
但是这样的话,所有模型字段必须要是大驼峰法。这个时候就要注意不要在领域之外直接修改字段值,这也是模型退化后我们需要承担的风险。
为了说明仓储的实现,我们先从最简单的情况说起。
现在我们假设 Order 这个聚合中的属性跟 orders 数据库表的字段是一一对应的。
在 OrderRepository 中需要引用到 IdGeneratorClient 和 OrderDal,具体实现如下:
package persistence
func NewOrderRepository(idGenerator *IdGeneragorClient, orderDal *OrderDal) *OrderRepository {
return &ExamRepository{
idGenerator: idGenerator,
orderDal: orderDal,
}
}
type OrderRepository struct {
idGenerator *IdGeneratorClient
orderDal *OrderDal
}
func (r *OrderRepository) NextIdentify() (int64, error) {
return r.idGenerator.Gen()
}
func (r *OrderRepository) Save(ctx context.Context, order *entity.Order) error {
return r.orderDal.Upsert(ctx, order)
}
func (r *OrderRepository) Find(ctx context.Context, id int64) (*entity.Order, error) {
return r.orderDal.SelectById(ctx, id)
}
func (r *OrderRepository) FindNonNil(ctx context.Context, id int64) (*entity.Order, error) {
rlt, err := r.Find(ctx, id)
if err != nil {
return nil ,err
}
if rlt == nil {
return nil, NotFoundErr
}
return rlt, nil
}
func (r *OrderRepository) Remove(ctx context.Context, order *entity.Order) error {
r.orderDal.SoftDelete(ctx, exam)
}
对于上面代码,有几点说明:
- Save 方法同时兼具了新增和更新功能,具体的逻辑是在 dal 中通过 Upsert 实现的;
- Dal 中方法的命名带有明显的 sql 特征;
- 在应用服务中获取某个聚合根时,通常都要判断下聚合根是否存在,我们这里提供的 FindNonNil 方法将这一个常规操作进行了封装;
- Order 是定义在领域层的聚合根,而不是数据库表的数据模型。在 Order 中的属性跟 orders 数据库表的字段是一一对应的这个假设下,我们省略了对数据模型的定义。所以,这里的 Order 是身兼数职,但其主要职责还是领域模型,只是为了代码实现上的便利,才妥协同时承担了数据模型的职责;
当上面的假设不成立时,又该怎么办呢?
比如一个 Order 中存在多个 Item,Order 存到 orders 表,Item 存到 order_items 表,通过 order_id 进行关联,其结构如下所示:
type Order struct {
Items []*OrderItem
...
}
在这种场景下,我们的问题在于,如果某次对 Order 的修改只是更改了某个 Item 的信息,我们要如何执行 Save 方法?
首先,如果我们可以接受将 Items 字段序列化为 json 字符串,在 orders 表中新增这样一个 items 字段来存储 json,这样也可以解决问题,但是当需要对 Item 进行查询时就不太方便了。
另外一种简单粗暴的方式是,不管三七二十一将 Order 中的信息都更新一遍,这样做的缺点也很明显,就是会多出很多无用的 DB 操作:
type OrderRepository struct {
idGenerator *IdGeneratorCient
orderDal *OrderDal
orderItemDal OrderItemDal
}
func (r *OrderRepository) Save(ctx context.Context, order *entity.Order) error {
orderPO := converter.OrderToPO(order)
if err != r.orderDal.Upsert(ctx, orderPO); err != nil {
return err
}
for _, item := range order.Items {
itemPO := converter.OrderItemToPO(item)
if err != r.orderItemDal.Upsert(ctx, itemPO); err != nil {
return err
}
}
return nil
}
...
在上面代码中,converter 的作用是负责领域模型与数据模型之间的转化,数据模型我们一般用 PO (Persistant Object)表示。
converter 存在的价值在于,数据模型与领域模型并非是完全一致的,converter 负责管理了彼此之间的映射关系。
对于聚合根不是特别复杂的情况,上面的实现方式虽然存在无用 DB 操作,但也还能接受。
在对聚合的设计中有一条规则是要设计小聚合,其原因也在于此。
那如果很不幸我们有一个很大的聚合,无法接受全量更新,要怎么办呢?
通常有两种方法:
- 一种是基于 Snapshot 的,当聚合根取出后,在内存中先保存一份snapshot,在聚合根写入时,将其跟snapshot做一下diff。
- 另一种是将聚合根上可以修改的属性设置成私有的,然后通过类似Setter的方法来进行赋值,这样,在setter被调用时我们就知道哪里被修改了。
业界使用较多的,包括在其他语言中,都是采用第一种 Snapshot 的形式,其实现起来相对简单,副作用较少。
4.1.3 使用Snapshot对变更进行追踪
使用 Snapshot 首先要解决的问题是这个 Snapshot 要保存在哪里?
由于在 Go 中不支持类似 Java 里的 ThreadLocal,并且在 Go 里也不是很建议使用 goroutine local storage,所以对于这个 Snapshot 的存储就不那么方便了。
一种办法是将 Snapshot 放到 Context 中,比如 context 包下有一个 WithValue 方法,但是这个方法是返回一个装饰后的 Context,我们还是无法更改全局的 Context。
因此,我们这里采用了一种妥协的做法,即将 Snapshot 置于对应的聚合根内:
type Order struct {
Id int64
Items []*OrderItem
... // 其他属性
snapshot *Order
}
func deepCopy(e *Order) *Order {
return &Order{
... // 对各属性进行深拷贝
}
}
func (e *Order) Attach() {
if e.snapshot == nil || e.snapshot.Id == e.Id {
e.snapshot = deepCopy(e)
}
}
func (e *Order) Detach() {
if e.snapshot != nil && e.snapshot.Id == e.Id {
e.snapshot = nil
}
}
type OrderDiff struct {
OrderChanged bool
RemovedItems []*OrderItem
AddedItems []*OrderItem
ModifiedItems []*OrderItem
}
func (e *Order) DetectChanges() *OrderDiff {
if e.snapshot == nil {
return nil
}
... // 其他diff逻辑
}
之后,对 Repository 的实现逻辑进行相应的修改:
type OrderRepository struct {
...
}
func (r *OrderRepository) NextIdentify() (int64, error) {
return r.idGenerator.Gen()
}
func (r *OrderRepository) Save(order *entity.Order) error {
diff := e.DetectChanges()
if diff == nil {
// diff 为空,说明当前不需要追踪变更,采用全量更新的方式
orderPO := converter.OrderToPO(order)
if err != r.orderDal.Upsert(ctx, orderPO); err != nil {
return err
}
for _, item := range order.Items {
itemPO := converter.OrderItemToPO(item)
if err != r.orderItemDal.Upsert(ctx, itemPO); err != nil {
return err
}
}
} else {
// 根据diff,只更新发生了变更的表
if diff.OrderChanged {
orderPO := converter.OrderToPO(order)
if err != r.orderDal.Upsert(ctx, orderPO); err != nil {
return err
}
}
for _, item := range diff.RemovedItems {
itemPO := converter.OrderItemToPO(item)
if err != r.orderItemDal.SoftDelete(ctx, itemPO); err != nil {
return err
}
}
for _, item := range diff.AddedItems {
itemPO := converter.OrderItemToPO(item)
if err != r.orderItemDal.Create(ctx, itemPO); err != nil {
return err
}
}
for _, item := range diff.ModifiedItems {
itemPO := converter.OrderItemToPO(item)
if err != r.orderItemDal.Update(ctx, itemPO); err != nil {
return err
}
}
}
e.Attach() // 再次调用Attach开始新一轮的追踪
return nil
}
func (r *OrderRepository) Find(id int64) (*entity.Order, error) {
order := ... // 获取Exam聚合根的流程
if order != nil {
order.Attach() // 之后调用Attach方法生成Snapshot,开始追踪
}
return order, nil
}
func (r *OrderRepository) FindNonNil(id int64) (*entity.Order, error) {
... // 同之前逻辑
}
func (r *OrderRepository) Remove(order *entity.Order) error {
... // 调用dal执行删除逻辑
order.Detach() // 删除掉 Snapshot 不再追踪
}
4.2 与其他上下文集成
在我们实际的开发中,上下文的集成无外乎两种方式, 一种是通过RPC进行集成,另一种是通过领域事件进行集成。
通过领域事件集成,也就是领域事件的发送和消费,这个我们在 2.5 小结和 3.3 小结已经做了比较详细的介绍,这里不再赘述。
接下来主要说下通过 RPC 进行集成。
我们先来看一个在 DDD 中经常用来表示集成方式的示例图: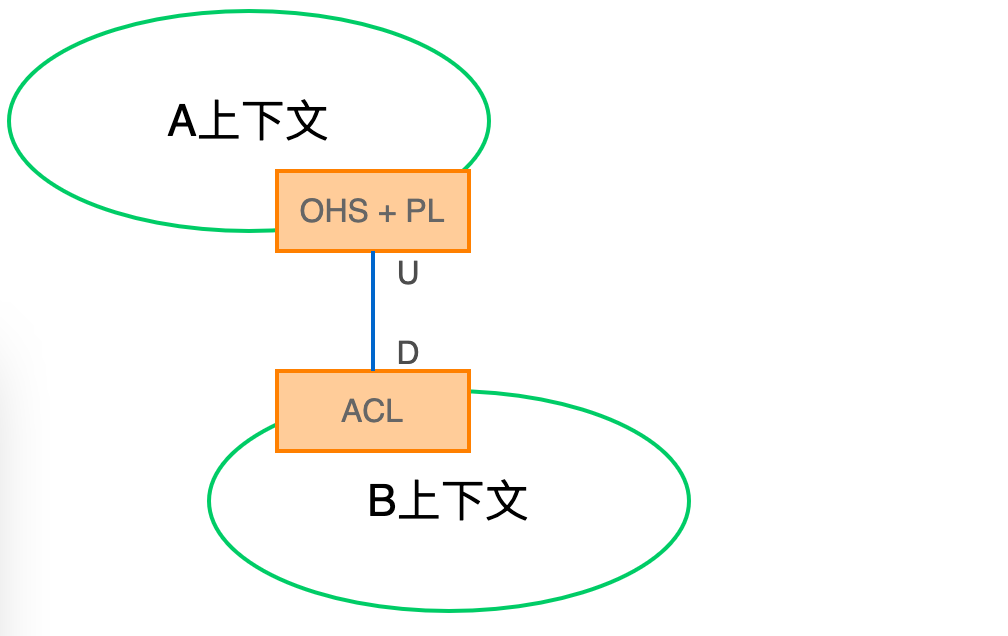
其中,被集成方(A上下文,U 是 Upstream 的缩写)采用了开放主机+发布语言的方式,而集成方(B上下文,D 是 Downstream 的缩写)则使用了防腐层的方式。
OHS(Open Host Service):开放主机服务,即定义一种协议,子系统可以通过该协议来访问你的服务。 PL(Published Language):发布语言,通常跟 OHS 一起使用,用于定义开放主机的协议。ACL(Anticorruption Layer):防腐层,一个上下文通过一些适配和转换来跟另一上下文交互。
我们平时大多数时候的开发工作都是跟 Grpc/Kitex 等RPC框架打交道的。
要开发一个服务,首先需要在 IDL 中对这个接口进行定义:服务的方法名是什么,需要传递什么参数,返回什么数据。
IDL 就是我们为系统的定义的协议。
所以,如果我们是一个服务的提供方,只要我们使用 Grpc/Kitex,那么就可以说我们是使用 OSH 和 PL 方式来进行集成的。
接下来还是以订单的例子进行说明。
在 order 服务中,有一个 OrderDetail 方法,在这个方法里需要跟 product 服务进行集成。product 中具体服务的定义如下:
QueryProductDetail(ctx context.Context, request *product.QueryProductDetailRequest, callOptions ...callopt.Option) (r *product.QueryProductDetailResponse, err error)
QueryProductInfo 服务返回了关于 Product 的全量信息,但是对于我们来说,只是想拿到产品的图片和名称,仅此而已。
可以看到,作为服务的提供方,其具有追求普适性和灵活性的特点,而服务的调用方,在使用时却想要能够集中满足特定需求的接口。
这种张力是导致在边界上出现问题的主要原因,是无法避免的,但是却是可以解决的,应对的方法就是使用防腐层。
对于集成方来说,一般采用独立接口的形式,接口的定义放在领域服务中,比如上面这个例子,可以这样定义:
package service
type ProductBaseInfoService interface {
func GetProductBaseInfo(ctx context.Context, productId int64) (*ProductBaseInfo, error)
}
在这个定义中,返回的数据应该是一个领域元素,
因为实现是跟具体的技术相关的,所以实现需要放到基础设施层,目录层级如下:
├── domain
│ ├── service
│ │ └── product_baseinfo.go
...
├── infra
│ └── sal
│ └── product_baseinfo_impl.go
在具体实现上,我们用到了防腐层,如下图所示: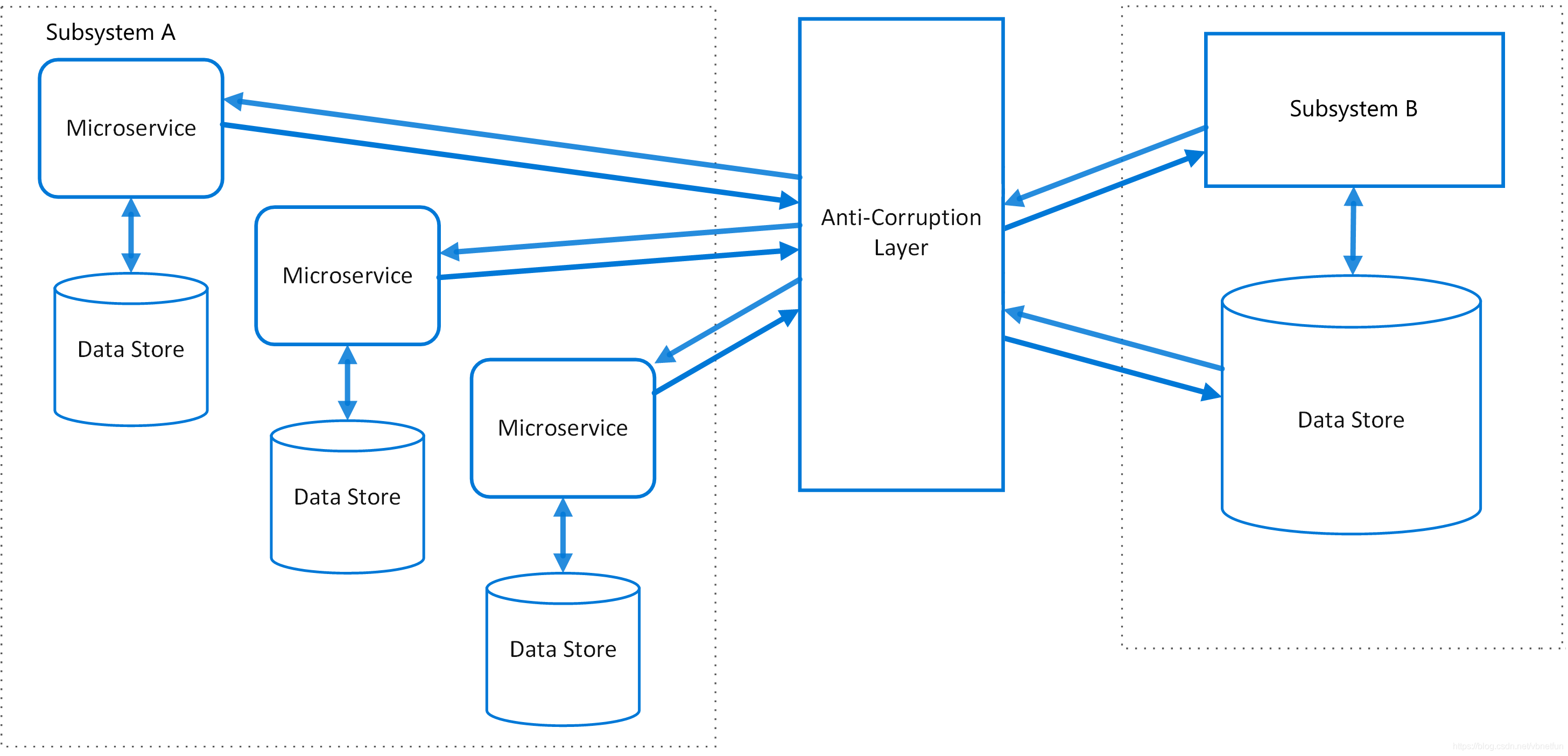
从图中可以看出,Subsystem A 和 Subsystem B 的调用关系并不是直接产生的,都要通过中间的一个ACL,ACL 除了负责执行具体的技术性调用,还将 A 和 B 的领域模型隔离开来,并承担彼此模型之间的翻译转换功能。
除此以外,还可以在 ACL 做缓存、兜底、开关等功能。
package sal
type ProductBaseInfoSal struct {}
func NewProductBaseInfoSal() *ProductBaseInfoSal {
return &ProductBaseInfoSal{}
}
func (s *ProductBaseInfoSal) GetProductBaseInfo(ctx context.Context, productId int64) (ProductBaseInfoSal, error) {
resp, err := rpc.QueryProductDetail(ctx, &paper.QueryProductDetailRequest{
ProductId: productId,
})
if err != nil || resp.Data == nil {
return ProductBaseInfo_Unknown, err
}
return transToProductBaseInfo(resp.Data), nil
}
func transToProductBaseInfo(detail *product.QueryProductDetail) QueryProductDetail {
...
}
在传统意义的防腐层实现中,会有一个适配器和一个对应的翻译器,其中适配器的作用是适配对其他上下文的调用,而翻译器则是将调用的结果转换成本地上下文中的元素。
在这里,我们为了保持代码的简单,没有特意声明这样两个对象,rpc的方法在这里起到了适配器的作用,至于翻译器,我们只是简单的提出了一个方法,在方法名上做了特殊的前缀修饰。
最后,ProductBaseInfoSal 会作为 ProductBaseInfoService 的实现类,最终被注入到应用服务中。
5. CQRS 实现
5.1 CQS 与 CQRS
CQS 和 CQRS 都表示命令与查询的分离,本质上没有太大的区别。
CQS 是在《面向对象软件架构》一书中提出来的概念,全拼是 Command Query Separation。
本书的作者 Bertrand Meyer 认为,一个方法原则上不应该既修改数据又返回数据,所以我们就有了两类方法:
- 查询:返回数据,但不修改数据,所以不会产生副作用;
- 命令:修改数据,但不返回数据;
CQRS 是对 CQS 概念的升华,因为查询端只返回数据,完全不修改数据,所以我们所有的查询不需要走领域实体,甚至没必要使用 ORM 框架,总之,我们可以通过各种手段来提升查询的效率。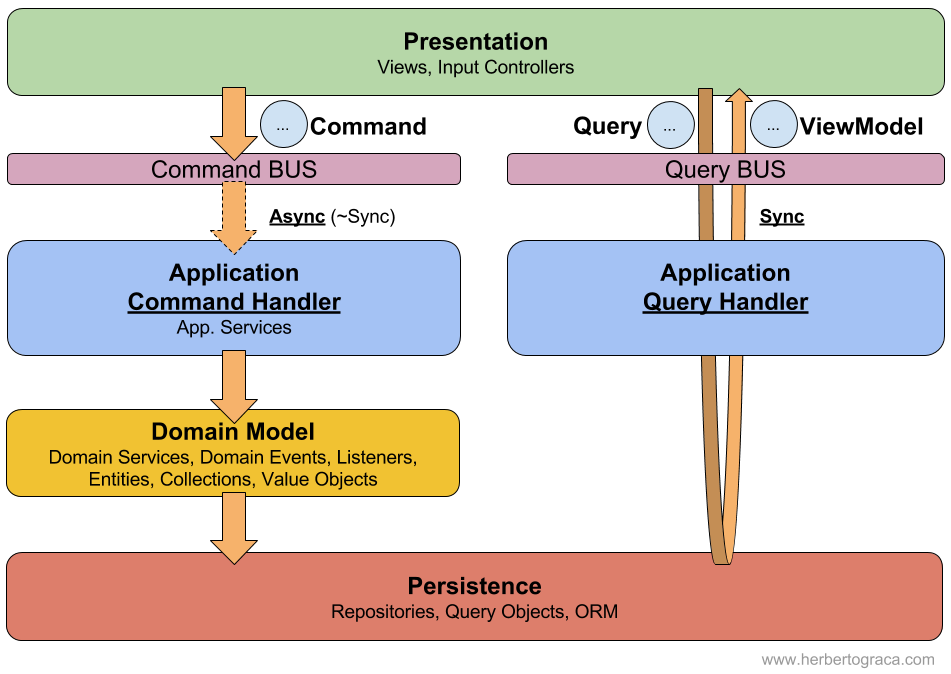
5.2 CQPS 的实现
5.2.1 共享存储+共享模型模式
这种模式是最简单的情况,一般对应的模型也相对简单,要查询的数据基本上都是模型里的属性。
比如,我们有一个库存的模型:
package entity
type InventoryAggregate struct {
Id int64
ProductId int64
Remains uint64
CreatedAt time.Time
}
要展示的数据如下:
type InventoryView struct {
Id int64
ProductId int64
Remains uint64
}
通过 assembler 来对view进行组装:
package assembler
func AssembleInventoryView(i *InventoryEntity) *InventoryView {
return &InventoryView{
Id: i.Id,
ProductId: i.ProductId,
Remains: i.Remains,
}
}
在应用服务中直接通过 Repository 获取领域模型:
func (s *InventoryService) GetInventoryView(id int64) (*InventoryView, error) {
i, err := s.inventoryRepo.Find(id)
if err != nil {
return nil, err
}
return assembler.AssembleInventoryView(i), nil
}
5.2.2 共享存储+分离模型模式
在分页查询,或者是需要多个实体聚合查询的场景,如果直接通过 Repository 获取领域模型再组装,可能会产生很多无关查询,影响效率。
这个时候,可以根据要展示的数据直接使用数据模型,或者通过 sql 只获取指定的某几个字段。
比如,我们有 Product 和 Category 两个聚合根,其中包含了大量的属性和业务逻辑,但是我们要展示的数据比较简单:
type ProductView struct {
ProductId int64
ProductName string
CategoryId int64
CategoryName string
}
这个时候就可以通过直接 sql 的形式来绕过领域模型:
func (s *ProductViewService) GetProductView(productId int64) (*ProductView, error) {
dto := &ProductView{}
s.db.Raw("SELECT product.id AS product_id, product.name AS product_name, product.cateogry_id, category.name AS category_name FROM product left join category on product.category_id = category.id where WHERE product.id = ?", productId).Scan(dto)
return dto, nil
}
5.2.3 分离存储+分离模型模式
这种情况一般都是有一个独立的查询服务,对各种数据进行聚合处理后,统一放到查询服务中。
如下所示,订单在创建后,会使用 EventPublisher 来发布相应的事件:
// 在引用服务中调用repo保存order
func (s *OrderAppService) CreateOrder(ctx context.Context, cmd *CreateOrderCmd) error {
order := ...
return s.orderRepo.Save(ctx, order)
}
// order repo 中对产生的事件进行发布
func (r *OrderDBRepo) Save(ctx context.Context, order *OrderEntity) error {
// 1. 对事件进行发布
for _, msg := range order.Events {
r.eventPuslisher.Publish(msg)
}
order.ClearEvents()
// 2. 执行db insert
orderPo := ...
orderItemPos := ...
dal.InsertOrder(ctx, orderPo)
dal.InsertOrderItems(ctx, orderItemPos)
}
在订单查询服务中,会对订单创建这个事件进行监听,当手动对应的消息时,会将订单信息存储到ES里。
func (s *EventAppService) onOrderCreated(event *OrderCreated) error {
order := s.orderService.GetOrder(event.OrderId)
products := s.productService.MGetProducts(order.ProductIds())
orderView := buildOrderView(order, products)
esClient.Save(orderView)
}
如此一来,订单数据就同时存在于 MySQL 以及 ES 中。而在查询的时候会只通过 ES。
6. 结语
以上就是笔者在实际工作中对 DDD 技术落地的一些总结和思考。
如有错误的地方欢迎指出,也期待跟大家进行交流。
7. 一些参考资料
| 参考资料 | 推荐程度 | 描述 |
|---|---|---|
| Domain-Driven Design in Go | 低 | 例子过于简单,离实际开发太远了。并且例子中有些实现不太DDD |
| Using Domain-Driven Design(DDD)in Golang | 低 | 跟上篇没有太大差别,这里还有一个对应中文版的基于DDD的golang实现 |
| How to Implement Domain-Driven Design (DDD) in Golang | 低 | |
| How to Structure DDD in Golang | 低 |

若有收获,就点个赞吧
0 人点赞
