在设计模式中,有一个结构型模式:门面模式。
门面模式提出的初衷,是为程序库、框架或者其他复杂类提供一个简单的接口,接口的功能可能比较有限,但是你真正关心的。通过这个接口,屏蔽了第三方类/系统的实现细节,使得代码的理解和维护都更容易了。
在DDD的战术实现中,同样存在着这样一个“门面”,也即应用服务。
应用服务主要的作用是连接领域模型与外部的请求调用。作为一个间接层,外部系统必须通过应用服务来访问领域模型,同时,领域服务也向外部用户屏蔽了领域细节。
应用服务如果只是对外部请求的简单转发,自然存在的意义不大。实际的情况是,领域对象定义的粒度通常会比较小,那么,在业务的某个用例上,就需要对不同的领域对象进行编排和调度。如果将这个工作交给外部系统来完成,它就需要对领域模型的细节比较了解,而这是有违最少知识原则的。
就像上面说的,作为领域模型的门面,应用服务可以大大简化外部系统的调用,同时避免领域逻辑的泄露。
同时,在一个完整的系统中,不仅仅是有领域逻辑,还需要一些支撑性的功能,比如应用的安全问题、日志记录问题、事务控制问题等等。这些问题在所有系统中都是通用的,并非特定领域的业务问题,如果将这些问题的解决放在领域层是不合理的,它们最好的归宿同样是在应用服务中。
在介绍如何实现应用服务之前,让我们先来看一下实现应用服务应该遵循哪些原则。
定位与实现原则
应用服务是领域模型的直接客户!!!
通常我们会遵循下面的几个原则来构建应用服务:
- 应用服务上的一个业务方法对应了一个业务用例,它们彼此是一一对应的关系;
- 每个业务方法都应当被封装到一个事务中,其与事务也是一一对应的;
- 在应用服务中不处理具体的业务逻辑,也不需要对参数进行业务校验,外部需要保证参数的基本合法性;
- 应用服务的定位是领域模型的门面,不应该处理一些具体的技术细节,也即不能跟具体的框架绑定在一起;
- 可以处理跟安全相关的一些操作,比如权限控制,但是更推荐将这种功能放到切面中;
总的来说,领域模型和领域服务中承载了所有的业务逻辑,而应用服务在复杂模型的基础上提供了一个统一的出口,这个出口通过协调对模型的一些操作,来实现外部的用例要求。
因此,应用层在实现上通常是很薄的一层,因为这里不涉及具体的业务逻辑和技术细节。
应用服务的实现
代码应该放于何处
从分层架构上来看,应用服务和领域模型是处于两个不同的层级的,因此,在落实到代码上时,应用服务和领域模型也应该处于不同的包下。
可以在跟 domain 包平级的地方创建一个 application 包,包中依据不同的领域,可以创建不同的 service 文件,每个 service 文件作为具体某个应用服务的载体。
这里采用 application 包名的话,虽然很直观,但是 application 这个单词有点长,在不影响对代码理解的前提下,可以使用 app 作为 application 的缩写,这样在使用时稍微简单点,直接 app.xxx 就可以了。
├── app # application│ ├── ... # 其他包,如果有的话│ ├── order_service.go│ ├── product_service.go│ └── inventory_service.go├── domain│ ├── entity│ ├── event│ ├── repository│ ├── service│ └── vo
服务的定义
通常的做法是直接定义一个结构体,而非使用独立接口模式。
在应用服务层,原则上是可以访问领域层和基础设施层的,因此这里不存在需要分离接口和实现的必要。
但是,也不推荐直接定义 func 来实现某个应用服务功能,因为在应用服务中通常需要引用 Repository 或者领域服务。
如下定义了一个 OrderApplicationService,代码放在 app.order_service.go 文件内。
其内部属性一般是对 Repository 或领域服务的引用,它们大部分(部分领域服务并不是采用的独立接口模式)是以接口的形式存在的:
package apptype OrderApplicationService struct {orderRepo repository.OrderRepository... // 对其他服务的引用等}
为了能够对 OrderApplicationService 进行实例化以及属性的依赖注入,我们同时还要提供一个构造方法:
func NewOrderApplicationService(orderRepo repository.OrderRepository, ...) *OrderApplicationService {return &OrderApplicationServce{orderRepo: orderRepo,...}}
这里仅以 repository.OrderRepository 为例来说明构造方法的参数类型。
也即,构造方法的参数类型跟结构体中的属性类型是一致的,比如属性中是一个接口,那么这里的参数类型也必须是一个接口。
严禁参数是接口的具体某个实现,使用接口形式的参数,方便我们充分利用多态的能力。
在 OrderApplicationService 里,每一个方法对应了业务中的一个用例:
// 这里先暂时忽略服务方法的入参、出参func (s *OrderApplicationServce) CreateOrder(...) ... {...}func (s *OrderApplicationServce) ChangeOrderProductCount(...) ... {...}...
到目前为止,我们还未就领域服务中某个方法具体要如何实现展开说明,接下来要讨论的内容虽然我们比较熟悉,但是争论也比较大。
服务方法的入参
每个应用服务方法的第一个参数应该是 context.Context,这一点应该没有太大的异议,因为要保持应用服务的无状态性,不能将context.Context定义为应用服务的属性。
但是后面的参数要怎么传呢?我们这里考虑的因素主要是合理性和便利性。
考虑到合理性,第一条原则便是不允许将领域模型泄露到应用层之外。
所以,这里的入参类型不能够是领域模型中的实体或值对象,否则,应用服务的调用方就要承担如何构建这样一个值对象或实体的职责,而我们是不希望领域以外的调用方去了解这些细节的。
其次,我们先考虑在参数数量较少时的传参。
在参数个数较少时,比如只有一两个(最多三个),我们可以直接将这两三参数定义在方法的参数列表中。
要注意这两三个参数的类型应该都是 Go 里的简单数据类型,类似 struct 和 map 是不行的。
因为参数个数不多,所以对于应用服务的调用者来说,其负担并不重,无论是 RPC 服务还是 HTTP 服务,都很容易从 Request 中解析出来。
当参数的数量大于三个时,对于方法的调用者来说就不那么友好了,尤其是当连续几个参数的类型一样时,很容易将它们的顺序搞错,这个时候就得特别小心。
一种常见的解决方案是使用 DTO,将除了 context.Context 以外的其他参数封装到一个DTO里,这个 DTO 进一步可以划分成 Command 和 Query,这个在后面说到 CQRS 的时候再详谈。
DTO 在严格意义上说,也是值对象,只不过是没有业务意义的值对象,也应该具有不可变性。
另外一种解决方案是直接使用 IDL 中定义的 Request。IDL 是接口定义语言的简称,一般特指 ProtoBuffer 或 Thrift,我们在 grpc 或 kitex 等 rpc 框架中会经常用到。
下面就说下这两种方式的优缺点:
| 使用独立DTO | 优点 | 因为DTO的属性都是基本类型,方便适配不同的应用服务调用者。比如在 rpc 中可能是使用 Thrift 定义的 XXRequest,在 Http中是对应的 json 字符串或者 pb,无论哪种形式,都很容易构建出所需的DTO实例。 |
|---|---|---|
| 在 DTO 中可以定义对各个属性的基本校验规则,从而将校验逻辑收敛在一处,在调用服务前能保证参数的基本合法性。 | ||
| 缺点 | 各调用方需要手动构建这样一个 DTO,这个成本大部分情况下都不算高,但是个别时候,尤其在 DTO 的结构跟 IDL 里定义的 Request 结构高度一致时,会显得比较冗余。 | |
| 频繁创建 DTO,增加了GC的负担。 | ||
| 直接使用IDL中的Request | 优点 | 在对应的服务场景下很方便,比如在IDL中定义的是RPC的接口,那么在RPC服务中使用就非常方便,不需要任何的转换。但是基本的参数校验还是要做的,也即传入应用服务的 Request 是已经校验好了的。 |
| 缺点 | 如果这个应用服务还在其他场景中使用,比如除了会在RPC服务中使用,还会应用在Http中,那么在Http中就需要构建这样一个 Request,用起来比较别扭。其根本原因是应用服务跟具体的框架进行了强绑定。 | |
| 应用服务中的方法跟 IDL 中定义的方法并非一定是一一对应的,应用服务中的方法更多是跟用例挂钩,而 IDL 中的方法更多是为了方便调用方的使用而定义的。接口的变更频率相对更高,而模型更稳定,这个差异会导致应用服务层不稳定。 |
这里以使用DTO的形式给出示例代码:
type ChangeOrderProductCntCmd struct {UserId int64 `valid:"required~用户ID不能为空"`OrderId int64 `valid:"required~订单ID不能为空"`ProductId int64 `valid:"required~产品ID不能为空"`ProductCnt int32 `valid:"required~产品数量不能为空"`}// 之后可以这样使用cmd := &ChangeOrderProductCntCmd{... // 各属性赋值}if _, err := govalidator.ValidateStruct(cmd); err != nil {return err}// 如果是kitex服务,可以在返回Response那里解析出具体的错误func handleError(err error) (statusCode int, statusMessage string) {if err == nil {return 0, "success"}switch t := errors.Cause(err).(type) {case govalidator.Errors:return 400, parseFirstValidatorErrorMessage(t)... // 其他case分支default:return 500, "Internal Error"}}func parseFirstValidatorErrorMessage(err govalidator.Errors) string {for _, e := range err.Errors() {return e.Error()}return "数据校验错误"}
综合上面的说明,我们可以总结出如下的一些最佳实践:
- 不要使用领域模型作为参数;
- 当参数个数较少时(一般不超过3个),并且每个参数都可以使用原始类型表示,可以将参数直接定义在方法里;
- 参数大于3个或者无法用简单的原始类型表示时,优先考虑使用 DTO;
- 当 IDL 中声明的接口正好跟用例一致时,可以妥协为直接使用 IDL 的 Request;
- 如果使用 IDL 中的 Request 作为入参,注意不要将这个 Request 传播到领域层;
服务方法的出参
必须要强调的是,不要直接把领域模型作为返回参数。
其目的还是避免领域模型的泄露。
如果直接返回领域模型,那么服务的调用者就要对模型内部比较清楚,这样才能够构建出自己想要的数据。
不返回领域模型,怎么将数据传递出去呢?
一般有下面几种方法,在实现上有利有弊,具体使用何种方式,并没有强制的规定,更多是个人倾向。
最简单的情况是返回的数据比较简单,比如一些新建的方法只要返回创建成功的ID,这里直接使用原始类型就能满足要求。
而这里的挑战在于,有的时候需要返回的数据可能涉及多个领域模型的属性。我们如何在不暴露领域模型细节的基础上返回客户所需的数据呢?
1、使用 DTO 包装要返回的数据
DTO 的缺点在于我们可能需要创建一大堆跟领域对象非常相似的结构体,并且增加了 GC 的负担。如果 IDL 中定义的 Response 跟 DTO 的结构差异不大,这个时候就更显得多余。
其次,有的时候我们也很难决定 DTO 里到底要封装哪些数据。
使用 DTO 带来的另外一个问题是,我们需要给 DTO 同时提供一个装配器,装配器负责收集多个领域模型的属性,然后构建出 DTO 实例。
当需要新增或修改DTO的属性时,除了DTO还需要修改对应的装配器。这样一来就会稍显麻烦,其本质原因是没有做到符合开闭原则。
如下展示了使用 DTO 时的实现方式,其中,cqe是 Command、Query、Event 的缩写,表示存放的是这三种类型的 DTO: ```go package cqe
type ProductDTO struct { Id int64 Name string Price int32 Inventory int32 Detail string }
package assemlber
func AssembleProductDTO(p Product, i ProductInventory) *ProductDTO { return &ProductDTO{ Id: p.Id(), Name: p.Name(), Price: p.Price(), Inventory: i.Count() Detail: p.Detail(), } }
// 在应用服务中调用 return assembler.AssembleProductDTO(productE, inventoryE)
DTO 的引入虽然增加了我们的负担,但是在多个客户端的场景下很有效,比如这个方法同时服务于HTTP、RPC、Job、Console等。<br />**2、另外一种跟 DTO 比较类似的是 DPO(领域负载对象domain payload object)**<br />还是以上面 ProductDTO 为例来看下对应 DPO 的实现:```gotype ProductDPO struct {product *Productinventory *ProductInventory}func (p *ProductDPO) Id() int64 {return p.product.Id()}func (p *ProductDPO) Name() string {return p.product.Name()}func (p *ProductDPO) Detail() string {return p.product.Detail()}func (p *ProductDPO) Price() string {return p.product.Price()}func (p *ProductDPO) Inventory() int32 {return p.inventory.Count()}
与DTO显著的区别是,DPO中包含了对所用到领域模型的引用,而非单独的属性。
需要特别特别注意的是,这些引用都是私有属性,包外无法直接访问,也就避免了模型细节的泄露。客户端需要的属性通过具体的方法提供。
不同于 DTO 将结构体的定义和组装拆分到了两个地方,在 DPO 中,当某个属性有变动时,只需要修改 DPO 自身即可。
3、调停者(强烈不推荐使用)
在该模式下,会针对每个领域模型定义一个所谓的“兴趣接口”。
领域服务不再返回具体的数据,参数也变成传入对应的“兴趣接口”,因为在实际业务中很少这么用,所以了解一下即可。
// 先定义一个接口type ProductInterest interface {InformId(int64)InformPrice(int32)}// 在实体上实现一个ProvideProductInterest方法type Product struct {...}func (p *Product) ProvideInterest(interest PostInterest) {interest.InformId(p.Id())interest.InformPrice(p.Price())}// 外部实现 ProductInterest 接口,获取感兴趣的属性...
4、直接使用IDL定义的 XXResponse
最后一种是最方便的,但使用的话,同样存在一定的约束条件。
即 idl 定义的接口跟用例保持一致。
其次,使用这种方式也不是没有成本的:
- 首先,我们同样需要定义一个装配器,用来将领域模型上的属性装配到 Response 上;
- 其次,因为 Response 跟具体的框架相关,所以还会涉及在出错情况下的 Response 组装,但这本不应该属于应用服务的责任,相应的解决办法是返回 nil 和对应的错误,在外层再通过错误组装成对应的 Response。
最后总结一下:
- 无论入参和出参,在参数数量很少的情况下处理起来都比较简单,也没有太多争议;
当参数变的复杂后,就需要判断到底使用什么方式,从我个人的经验来看,入参使用 Command + Query 形式的 DTO,出参使用 DPO ,这种组合基本上可以应对90%以上的应用场景。如果没有特别的考量,可以无脑使用这种方式。
处理事务和安全
在DDD中有一条原则:一个业务用例对应一个事务,一个事务对应一个聚合根。
一个业务用例对应了一个应用方法,所以每个应用方法原则上应该被一个事务所包围。
在 java 中通常会这样实现事务:@Transactionalpublic OrderId createOrder(CreateOrderCmd cmd) {...}
通过 @Transactional 注解,默认开启一个传播机制为 REQUIRED 的事务。
但是在 Go 中目前还没有一种很方便的对业务侵入性比较小的方案,更多的时候还是靠人工 Begin、Commit 等。
比如在 Gorm 中提供了 Transaction 方法:db.Transaction(func(tx *gorm.DB) error { // 在事务中执行一些 db 操作(从这里开始,您应该使用 'tx' 而不是 'db') if err := tx.Create(&Animal{Name: "Giraffe"}).Error; err != nil { // 返回任何错误都会回滚事务 return err } if err := tx.Create(&Animal{Name: "Lion"}).Error; err != nil { return err } // 返回 nil 提交事务 return nil })这个 Transaction 方法内部也是通过调用
tx := db.Begin()、tx.Commit()、tx.Rollback()等方法实现的。同时,通过 SavePoint 还实现了对嵌套事务的支持。
但是,更多的时候,我们希望能够对事务的传播有更多的控制权,比如下面的示例: ```go func A(ctx context.Context, …) { db.Transaction(func(tx *gorm.DB) error {... // do some thing B(ctx) // 之后调用了 B 方法 return nil}) }
func B(ctx context.Context) { db.Transaction(func(tx *gorm.DB) error { … // do some thing return nil }) }
当外部调用函数 A 的时候,会起一个事务,而 A 又调用了函数 B,这个时候希望 A、B 在同一个事务里。而当外部直接调用函数 B 的时候,希望 B 也能够在一个事务里。<br />类似这种需求,我们实现起来是比较困难的,或者不太优雅。<br />因此,需要在 Gorm 事务的基础上进行扩展,引入对事务传播机制的支持:
```go
const (
PropagationRequired = iota // 支持当前事务,如果当前没有事务,就新建一个事务
PropagationRequiresNew // 新建事务,如果当前存在事务,把当前事务挂起,两个事务互不影响
PropagationNested // 支持当前事务,如果当前事务存在,则执行一个嵌套事务,如果当前没有事务,就新建一个事务
PropagationNever // 以非事务方式执行,如果当前存在事务,直接返回错误
)
同时,定义一个 TransactionManager ,它只有一个对外的 Transaction 方法:
type TransactionManager struct {
factory DBFactory
}
func (m *TransactionManager) Transaction(ctx context.Context, bizFn func(txCtx context.Context) error, propagations ...TransactionPropagation) error {
propagation := defaultPropagation()
if len(propagations) > 0 && isPropagationSupport(propagations[0]) {
propagation = propagations[0]
}
switch propagation {
case PropagationNever:
return m.withNeverPropagation(ctx, bizFn)
case PropagationNested:
return m.withNestedPropagation(ctx, bizFn)
case PropagationRequired:
return m.withRequiredPropagation(ctx, bizFn)
case PropagationRequiresNew:
return m.withRequiresNewPropagation(ctx, bizFn)
}
panic("not support propagation")
}
有了 TransactionManager 我们再实现上面 A 调用 B 的例子就方便多了:
func A(ctx context.Context) {
manager.Transaction(ctx, func(txCtx context.Context) error {
... // repo do some thing
B(txCtx) // 这里传入了新的 Context
return nil
})
}
func B(ctx context.Context) {
manager.Transaction(ctx, func(txCtx context.Context) error {
... // repo do some thing
return nil
})
}
TransactionManager 的 Transaction 方法默认使用的是 PropagationRequired 传播机制,因此,上面的代码都没有使用可选参数。也就是说,当 B 被调用时,会判断一下当前是否在一个事务当中,如果是就复用当前事务,如果不是则新起一个事务。
如果我们希望 B 在任何时候都能够在一个独立的事务中,则可以这么写:
func B(ctx context.Context) {
manager.Transaction(ctx, func(txCtx context.Context) error {
... // repo do some thing
return nil
// 这里明确指定了使用 PropagationRequiresNew 传播机制
}, ddd.PropagationRequiresNew)
}
这样,每次 B 被调用时就会将当前事务挂起(如果有的话),然后新起一个事务,两个事务互不干扰。
这个功能的实现在于对 context.Context 的扩展。
我们定义了 TransactionContext ,它持有了原来的 context.Context,同时也实现了 context.Context 中的几个方法。因此,TransactionContext 也可以当做 context.Context 来用:
type TransactionContext struct {
ctx context.Context
tx *gorm.DB
parent *TransactionContext
}
func (c *TransactionContext) Deadline() (deadline time.Time, ok bool) {
return c.ctx.Deadline()
}
func (c *TransactionContext) Done() <-chan struct{} {
return c.ctx.Done()
}
func (c *TransactionContext) Err() error {
return c.ctx.Err()
}
func (c *TransactionContext) Value(key interface{}) interface{} {
return c.ctx.Value(key)
}
... // 其他方法
在 Transaction 方法中,会对当前 Context 进行类型判断,如果不是 TransactionContext,则会将其包装成 TransactionContext 传递给 bizFn,在 bizFn 中如果调用到了其他函数,还会将 TransactionContext 继续传递下去。
但是,在子方法中(比如上面A调B场景下的B方法),并不会直接复用上层的 TransactionContext ,而是通过 TransactionContext 的 Session 方法生成一个新的 TransactionContext ,新旧两个 TransactionContext 是父子关系:
// 类似于 gorm.DB 中的 Session 方法
func (c *TransactionContext) Session(config *gorm.Session) *TransactionContext {
return &TransactionContext{
ctx: c.ctx,
tx: c.tx.Session(config),
// parent 指向了创建它的那个 TransactionContext
parent: c,
}
}
这样实现的作用是为了在子函数中调用的 Transaction 方法不会误提交整个事务:
func (c *TransactionContext) Commit() error {
if !c.InTransaction() {
return ErrNotInTransaction
}
if c.IsRoot() { // 只有顶层的 TransactionContext 才会真正提交事务
return c.tx.Commit().Error
}
return nil
}
其余的几种传播机制实现原理与上面类似,就不再赘述。完整的代码可以参考这里>>
在应用服务中除了对事务进行控制,还可以承担安全的职责。
这里说的安全主要指的是 Authorization,而非 Authentication,不过,这种类型的需求,建议将其实现到某个切面中,比如在一些框架的 Middleware 中。
结语
今天,我为你介绍了什么是领域服务,领域服务在实现时的一些原则和最佳实践。我用脑图的形式将这些内容进行了总结: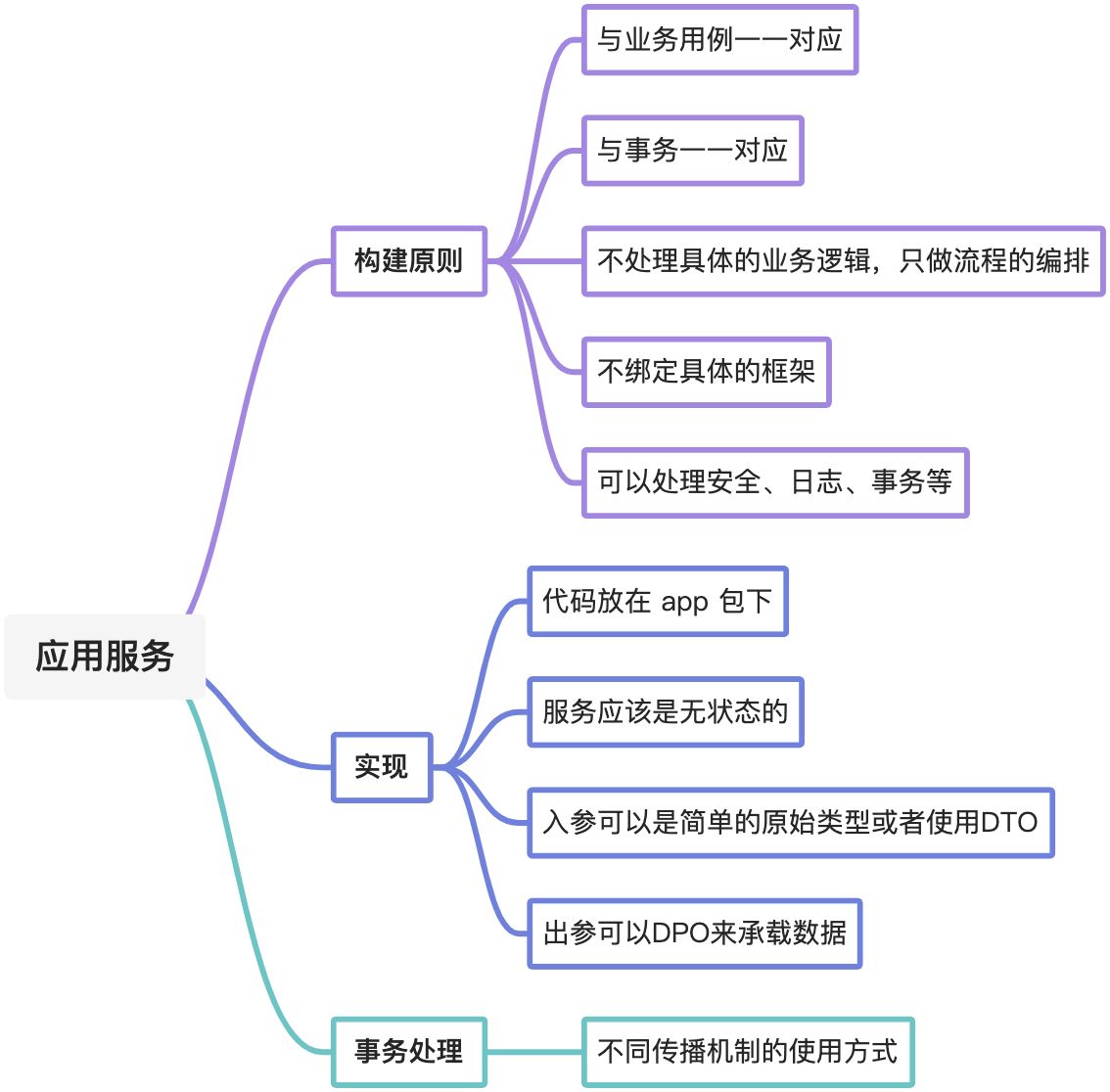
在DDD中,所有的业务逻辑都放在了领域模型中,但是这些领域模型通常是处理领域中某一方面的逻辑,在用例维度上,就需要协调不同的领域模型来完成相应的工作。
本着最少知识的原则,外部的调用者,应当对领域模型的细节了解的越少越好,而做到这一点的方式,就是在外部调用者和领域模型之间引入一个间接层,即领域服务。
在定义领域服务时,要注意里面的方法应该是用例维度的,并且不应该有业务逻辑的处理。又由于这仅仅是一个中间层,也就意味着其会对接不同的调用方,因此,在领域服务中不应该跟具体的框架进行绑定。
应用服务不属于领域模型,所以应用服务的实现不应该放在domain层,最好的方式是定义一个跟 domain 平级的 app 层。app 层还可以作为 domain 层的逻辑边界,即 domain 层的代码不应该跨过 app 层继续往外传播。这也就要求应用服务里各个方法的入参和出参都不应该包含领域模型中的对象。
最后,你还要注意对事务的使用,合理设置事务的传播机制。
对应用服务的介绍就到这里了。在下一篇文章中,让我们再来看看对领域事件的处理,由于其需要协同领域层和应用层来进行实现,因此,我们将领域事件的处理放在了后面讲解。
好了,我们下篇文章见。
延伸思考
在前面的文章中,我们介绍了领域服务,同样也是服务,你有想过它跟应用服务有什么区别吗?两者都有协调的能力,那具体是使用领域服务还是应用服务呢?
这两个问题留给你思考一下吧。

若有收获,就点个赞吧
0 人点赞
