前言
你好,今天我想与你聊聊如何在Go语言中落地DDD。
DDD中文又叫领域驱动设计,是我们解决复杂业务问题时非常有效的一个手段,但其本身过于陡峭的学习曲线,也让很多初学者知难而退。
网上虽然充斥着很多关于DDD的学习资料,但大多只是偏向于基本概念的介绍,缺少一个完整的落地实践。
笔者所在的技术团队也曾做过一些战略设计,通过这些设计过程,很多同学对DDD有了更深入的了解。在战略设计后,我们识别出了很多的值对象、实体、领域事件等等元素,但仍然让大家比较困惑的是,这众多的领域元素要如何跟具体的代码对应起来呢?如果做不到代码跟领域模型的同步更迭,那么DDD对于开发的意义又是什么呢?
我第一次接触DDD应该是在2014年,这一年正好是《实现领域驱动设计》一书在国内出版,依稀还记得当时公司群里异常兴奋的讨论。从 03 年 Eric Evans 的 Domain Driven Design 到14年 Vaughn Vernon 的 Implementing DDD,整整过去了10多年的时间,业界才算有了一个真正意义上的指导DDD落地的思想。IDDD一书出版的时候,也正是Java语言大行其道的时候,再加上书中的一些代码示例也是基于Java的,这就造成了人们的认知一度认为只有Java才是最适合实践DDD的。
近些年来,Go语言被越来越多的公司及个人所采纳,很多人也开始了对在Go语言中落地 DDD 的尝试。但其实,DDD本身只是一种思想,就像耗子叔曾经在《从面向对象的设计模式看软件设计》一文中提到的,说起设计模式也并非就一定是OO的。因此,实践DDD其实无所谓使用什么语言,但同时我们也要看到Go与Java在语言层面的差异,一些实现细节就必须做出调整。
是否有一套切实可行的代码结构与规范来指导实际业务中的开发呢?遗憾的是,目前在网上貌似是找不不到在Go语言层面比较完整且具有实际指导意义的资料。
所以从今天开始,我会通过一系列的文章来介绍DDD如何在Go语言中落地。希望通过尽量系统且详细的描述,来降低你实践DDD的门槛,同时能够帮助你解决一些在实际开发中可能遇到的问题。最后,我还会以一个虚构的系统作为案例,通过对这个Demo的讲解,帮助你更彻底的掌握DDD的核心思想以及落地操作。
在具体的内容安排上,未来会涵盖下图中的一些主题: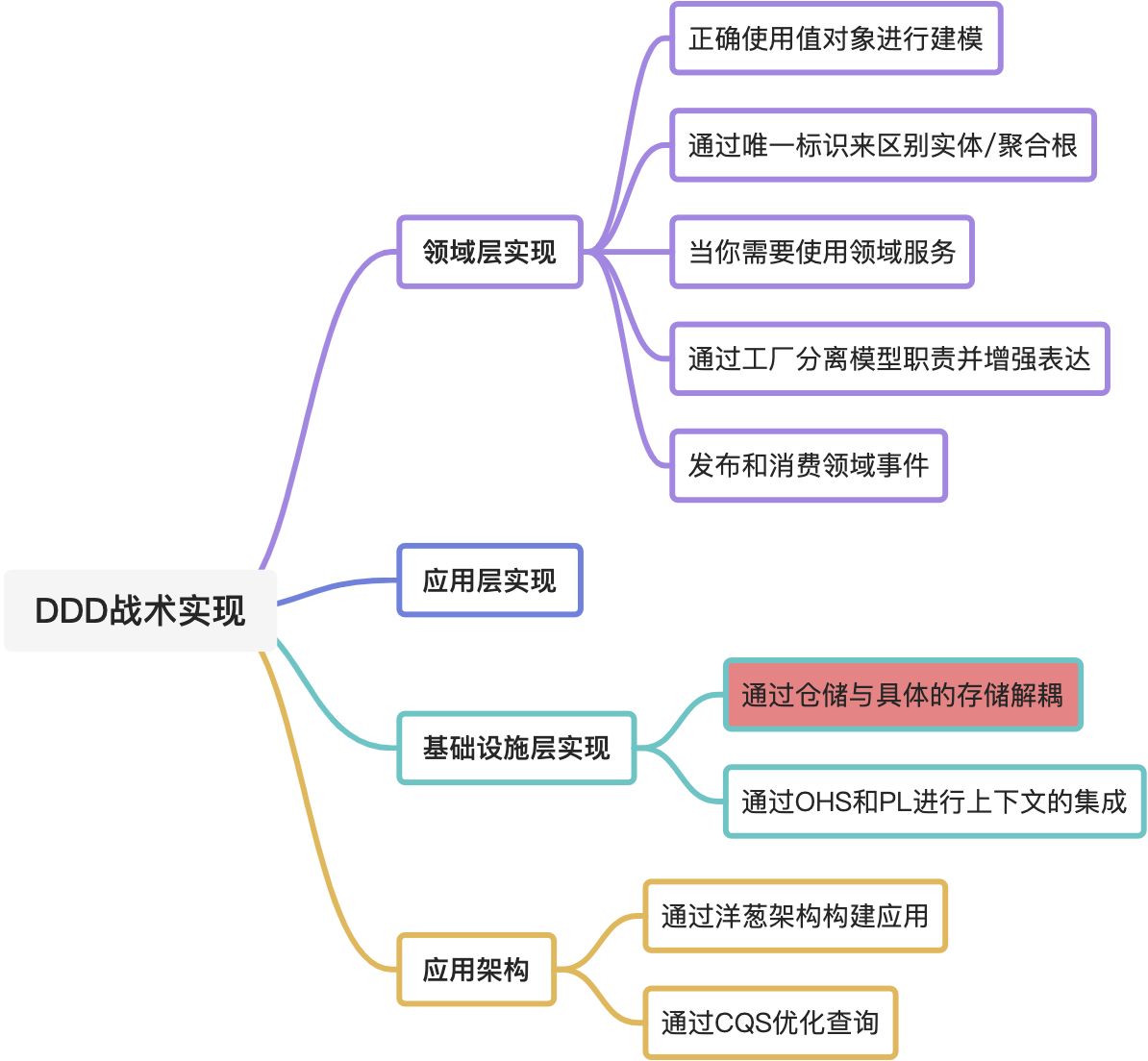
温馨提示,因为本系列文章的重点不在于对DDD相关概念的讲解以及战略建模,因此,在继续下面的阅读前,你最好对DDD有一些基本的了解,如果还不清楚,可以在网上先搜索一些资料阅读。
接下来,就让我们从最简单也是最基础的领域元素 - 值对象说起吧。
DDD In Go - 正确使用值对象进行建模
在开始正式介绍值对象之前,我们先来思考这样一个问题,什么样的代码算是好代码呢?
相信大家或多或少都接手过一些遗留的业务系统,这些系统的代码大多都能正常工作,或许运行的还是某个关键业务。在某一天,你接到了一个产品需求,经过评估,你认为只需改动很少的几行代码就可以实现。于是,你很快就完成了开发,并进行了充分的自测,你认为肯定不会出错。但不幸的是,上线后还是引发了事故。
上面的场景,相信对于很多做业务的同学都深有感触。
这种问题之所以常见,很多时候是因为我们的代码没有足够的清晰,没有很好的表达业务,看代码的人只能靠猜。比如我们定义一个注册的方法,需要用到用户名、手机号和密码,很多同学可能会将这个方法定义成这个样子: func Register(string, string, string) User。那么问题就来了,作为使用方,三个参数要按什么顺序传入呢?这也是代码不够清晰的表现。
在DDD中,值对象通过将相关联的属性组合在一起,构成了一个完整的概念整体,同时使用业务域中的统一语言,可以将一些隐性的概念显性化。正确的使用值对象进行建模,不但能够大幅的提升代码的清晰度、可读性,在一定程度上也会降低系统出错的概率。
值对象
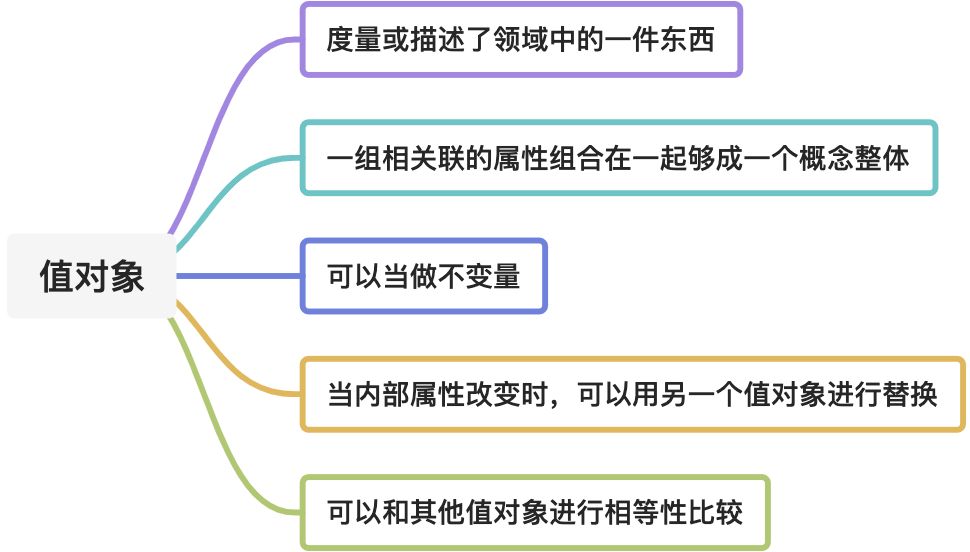
值对象本质上就是一个属性的集合,但这些属性并不是随便凑到一起的,它们通常是为了某个共同的目的或概念而存在着。
除此以外,值对象还具有下面两个显著的特点:
- 不变性,值对象在创建出来后是不应该被修改的,如果必须修改对象的某个属性,则需要整体替换成一个新的值对象;
- 无身份标识,这也是与实体相比非常重要的一个不同点。缺少了唯一标识,怎么判断两个值对象是否相等呢?就要看它们所包含的属性是否全部都是相等的了。这就好比我们在现实生活中使用现金,我们关心的只是货币的面值,是100的还是50的,而不会关心这个纸币的编号是多少。
实现值对象
比较严谨(教条)的实现方案
我们以一个描述货币价值的值对象为例,来看下代码:
// Currency 这里看作是一个枚举type Currency struct {name string}// 值对象type MonetaryValue struct {amount intcurrency Currency}func (v MonetaryValue) Amount() int {return v.amount}func NewMonetaryValue(amount int, currency Currency) (MonetaryValue, error) {if amount < 0 {return MonetaryValue{}, errors.New("amount must ge 0")}return MonetaryValue{amount: amount,currency: currency,}, nil}
在这个例子中,有这么几点需要特别注意:
- 值对象需要使用大驼峰,也就是这个 MonetaryValue 应该是全局可见的,这样一来在领域层之外也是可以访问的;
- 值对象里的各成员应该小写,这样做有两方面的原因:
- 一方面可以避免在包外对属性值的直接修改。假设有个更新数额的操作,因为没法直接在原值上赋值,例如这样的代码
val.amount = 2也就行不通了。这么做的好处是可以避免错误的赋值导致的一些问题。 - 另一方面,在包外虽然可以对 MonetaryValue 实例化,但是因为成员不能赋值,也就强迫了使用者必须调用 NewMonetaryValue 方法,从而避免了构造出一个不符合规范的对象;
- 一方面可以避免在包外对属性值的直接修改。假设有个更新数额的操作,因为没法直接在原值上赋值,例如这样的代码
- NewMonetaryValue 是一个工厂函数,并一次性传入构建该值对象所需的所有参数,在这个函数中可以对参数进行合法性校验,这样保证了所有创建出来的对象都是合法的。
- 包外如果有对值对象内部成员进行访问的需要,可以定义一个同名的、采用大驼峰定义的方法,比如这里的 Amount 方法。
这种实现方式虽然严格满足了值对象的一些要求,但是在某些情况下使用起来就不太方便了。
比如,如果我们需要对这个值对象进行json序列化与反序列化。这个时候,因为所有的成员都是未导出的,会导致 Golang 默认的 json 库直接将其忽略,这明显与我们的期望是不符的。
因此,我们在进行编码的时候,还需要充分考虑实现的成本,例如上述需要序列化的场景,直接定义成如下形式可能更合适些:
type MonetaryValue struct {
Amount int
Currency Currency
}
...
谨慎(最好不)持有指针、slice等类型
在一个值对象中可能持有另外的值对象,比如这里的 Currency,虽然是作为一个枚举使用,但本质上仍然是一个值对象。
当值对象中包含了其他非基本类型(例如指针、struct、slice、map等)的属性时,就要特别注意了,即使我们在值对象里没有对这类成员进行修改,但是仍然无法保证外部不会修改他们的值。
看下面的例子:
type BadDemo struct {
s []string
}
func NewBadDemo(ss []string) BadDemo {
return VOBadDemo{
s: ss
}
}
虽然 BadDemo 在内部没有任何方法对 s 进行增删操作,但是,如果外部对 ss 进行了修改,比如 ss[0] = "abcd",同样会反应到 s 上。
这样一来也就破坏了值对象的不变性,这种破坏性,有的时候可能会给你带来不可预知的Bug,并且不是特容易发觉。
通过新建来对值对象进行修改
值对象也是能够拥有一些行为的,比如上面的 MonetaryValue 可能有一个Add 方法:
func (v MonetaryValue) Add(other MonetaryValue) (MonetaryValue, error) {
if v.currency != other.currency {
return MonetaryValue{}, errors.New("not same currency")
}
return MonetaryValue{
amount: v.amount + other.amount,
currency: v.currency,
}, nil
}
这里的 Add 方法跟我们通常的实现可能不太一样,主要在于方法的返回值。
值对象因为要保证不变性,因此,我们不能直接对值对象的内部属性进行修改,而是采用了新建一个值对象的方式。
另外,Add 方法的接收者是一个值接收者,而非指针接收者,使用指针接收者的问题在于可能不小心就修改了内部属性,而造成一些隐式的错误。当然这里也可以不用这么绝对,对于大型的值对象,如果使用值接收者会带来一定的性能损耗,这个时候也可以使用指针接收者。
为什么要保证值对象的不变性
费了这么大劲,又是限制接收者类型,又是强调必须返回一个新的值对象,为什么呢?
我们考虑下面这个场景。
比如说,我们现在在开发一个多人游戏,每个人在一开始的时候都有固定的等值筹码,随着游戏的进行,你可能花费一些筹码或者赚取一些筹码。
我们在初始化筹码时,代码可能如下:
func initTokens(players []Player) {
initToken := &MonentaryValue{100}
for _, item := range players {
item.token = initToken
}
}
之后 player A 通过卖出装备而赚取了更多筹码,假设说这里是按照直接修改值对象内部属性的方式来实现:
playerA.token.Add(10)
那么问题就出现了,我们虽然只给 player A 增加了筹码,但是发现所有 player 都莫名多了10筹码。
问题的原因就在于,我们共享了这个值对象,但是没有保证它的不可变性。而返回新的值对象的方式则不存在这个问题:
playerA.token = playerA.token.Add(10)
实现枚举
枚举通常被认为是值对象的一种特化形式,它也属于领域中的元素。
以值对象的形式来实现枚举
比如有一个叫 SomeStatus 的枚举,对应有两个枚举值 SomeStatusOne 和 SomeStatusTwo, 那么可以采用如下的形式来定义:
var (
SomeStatusZero = SomeStatus{}
SomeStatusOne = SomeStatus{1}
SomeStatusTwo = SomeStatus{2}
)
var someStatusValues = []SomeStatus{
SomeStatusOne,
SomeStatusTwo,
}
func NewSomeStatus(s int) (SomeStatus, error) {
for _, item := range someStatusValues {
if item.s == s {
return item, nil
}
}
return SomeStatusZero, errors.Errorf("unknown '%d' status", s)
}
type SomeStatus struct {
s int
}
func (s SomeStatus) IsZero() bool {
return s.s == 0
}
func (s SomeStatus) Int() int {
return s.s
}
上述代码大部分都遵循了值对象的实现方法,但是也有两点不同:
- 定义一个默认的零值,并提供了一个判断当前枚举是否为零值的方法。零值的作用是保证在使用到枚举的地方都不会有 nil 的出现,这种保证可以一定程度的避免程序 panic 的发生;
- 所有的枚举值放到一个 Slice 或 Map 中,便于在创建枚举时进行合法性校验;
可以看到,这种实现方式还是比较麻烦,但是能够很大程度的在代码层面保证程序的正确性。而且,枚举值的变动频率一般都不会太高,所以成本也仅仅是一次性的。
使用原始类型表示枚举
另外一种偷懒的形式类似下面这种:
type AnyStatus int
const (
AnyStatusZero AnyStatus = iota
AnyStatusOne
AnyStatusTwo
)
跟上面值对象的形式相比,的确是简单了不少,但是最大问题在于代码的不可控性。
比如下面这样一个函数:
func UpdateStatus(s AnyStatus) {
...
}
UpdateStatus 方法接收一个 AnyStatus 类型的参数,之所以这里是一个 AnyStatus 类型而不是一个 int 类型,大概率是希望调用者能传递一个合法的 AnyStatus 进来,但是这一点是得不到保证的。
调用方可以传入任意一个整数值,而编译器并不会报错:
service.UpdateStatus(6) // 这行代码并不会报错
如果希望代码足够的严谨,那么在 UpdateStatus 方法内部就不得不就传入的值进行校验。这种校验逻辑也会散落到所有用到 AnyStatus 的地方。
另外,从全局来看,任何人在任何地方都可以直接调用类似这样的代码 AnyStatus(6) 来生成一个枚举值。很显然,这是一个无效的枚举值,也是一个完全不应该存在于领域的对象。
综合看上面两种方式,各有优缺,可以根据各自的情况,在团队内大家做到统一即可。
总结
今天,我向你介绍了值对象在Go语言中的实现方式,以及如何正确的定义枚举。
值对象这个概念并不复杂,但是在实现的过程中涉及到的细节会比较多,这也跟它自身的一些特征是分不开的。
值对象最重要的特征是不变性,我们所有的实现,都是围绕这一点展开的。也正因为这种不变性,让我们在业务中可以放心的对其进行复用。
当你在决定一个领域概念是否要建模成一个值对象时,就要考虑是否具有下面的一些特征:
在代码落地的过程中,你还要注意:
- 值对象的创建必须通过一个简单的工厂函数来实现,这样可以避免不符合业务约束的对象产生
- 对值对象的修改不能直接修改属性,需要构造一个新的值对象出来
- 值对象里的成员最好不要包含Map、Slice、指针等结构,否则值对象的不变性可能会遭到破坏
- 如果需要比较两个值对象,可以定义一个 Equals 函数,在函数里判断是否所有属性都相等
- Golang 里的一些原始类型,比如 int64、string 等,都可以看做是最简单的值对象来使用
如果说,是一砖一瓦构建起了高楼和大厦,那么,值对象就是DDD里的砖和瓦。因此,只有保证了值对象实现的正确性,才能在更高的维度去构建实体、聚合根等领域元素。
最后,留给你一个思考题。为了代码足够健壮,我们将值对象里的属性设计成了未导出的,当值对象需要持久化到数据库时,该如何做呢?从数据库中读出数据要重建值对象,又要怎么做呢?
在下一节,继续和大家聊聊如何实现实体、聚合根。

若有收获,就点个赞吧
0 人点赞
